こんにちは、ハラジテリ!
この投稿では、地理空間インデックス、つまり、
R *ツリーなどのデータ構造と、最初のプロジェクトの実装方法について説明します。
それでは始めましょう。 卒業後すぐに、私は車のGPS監視サービスを提供するオフィスを持っている教師から申し出を受けましたが、それを受け入れました。 ここにある! 最後に、本当に興味深いプロジェクト! 私の喜びと熱意には限界がありませんでした。 私に与えられた最初のタスクには、次の文言がありました。
マイレージ、車の使用済み燃料などに関するレポートに加えて、ベクトルマップが表示され、これらの同じ車の位置がリアルタイムで表示され、車の動きの履歴やあらゆる種類のグッズが表示されるデスクトップアプリケーションがあります。 現在、これらはすべて正しくなく、非効率的に機能しています。 誰もそれを正しく実装する方法を知りません。 書き換える必要がある
...
私の手には、160,000行分のアプリケーションのソースコードが渡されました。 ドキュメントなし、何もない。 情報の唯一の情報源は、これらのまさに教師であり、「Vasyaの要請でn * xを削除しました」という計画のソースコード内のまれなコメントでした。 このプロジェクトは10年以上前に行われ、オフィスは非常に忠実で柔軟で、文書化されていないあらゆる種類のウィッシュリストとホイッスルをほぼすぐに顧客の要求に迅速に対応します。 ものすごい過失! しかし、そのようなプロジェクトは、他人のコードを解析するスキルを高めるのに役立ちます。
まあ、タスクが設定された、仕事のための材料がありました。 コードをざっと調べ、質問をして、当時の現状を少し明らかにしました。
- マップは、これらのポイントへのリンクを持つポイントとオブジェクトの配列です
- 画面領域にヒットするオブジェクトは、徹底的な検索によって決定されます。
- オブジェクトを表示するかどうかは、画面上のオブジェクトのサイズを計算することにより「オンザフライ」で決定されました(1ピクセルサイズの家の表示にシステムリソースを費やすことは意味がありません)
小さいサイズの地図(都市、地区)の描画は許容範囲でした。 合計数百万のポイントで構成される数十万のベクトルオブジェクトを含む地域\国のサイズのマップを読み込むときに何が起こったのか、想像できます。 グーグルでこのトピックに関する多くの資料を読んで、すべてを「正しく実行する」ための2つのオプションを自分で特定しました。
- マップの領域全体を固定サイズの正方形に分割し、ジョイントに当たるオブジェクトを分割し、各オブジェクトに正方形のインデックスを割り当て、データを並べ替えて、必要なオブジェクトを外出先で計算します。
- Rツリーを使用します。
少し考えてから、最初のオプションを捨てました 特定の数のスケールレベルに取り付けて、それぞれのグリッドを構築する必要があります。 2番目のオプションには、無制限のスケーリングという利点があり、一般的にはより普遍的であると思われました。 車輪を再発明しないために、Delphiで既存のライブラリを検索することにしました。 プロジェクトはそれに書かれていました。 ライブラリが見つからなかったため、自分でインデックス作成を実装することにしました。
Rツリーとは何ですか? この構造は、空間データにインデックスを付けるためにアントニングットマンによって提案されたもので、バランスの取れたツリーであり、経験的観察に基づいて開発されました。 ツリーは、スペースを多くのネストされた長方形に分割します。 各ツリーノードには、最小(
minCount )および最大(
maxCount )のオブジェクト数があります。 ツリー構築アルゴリズムを正しく動作させるには、
2 <=
minCount <=
maxCount / 2であることが必要です。 各オブジェクトには、独自の境界矩形
-MBR (最小境界矩形)があります。 MBRノードは、子ノード\オブジェクトの長方形を記述する長方形です。
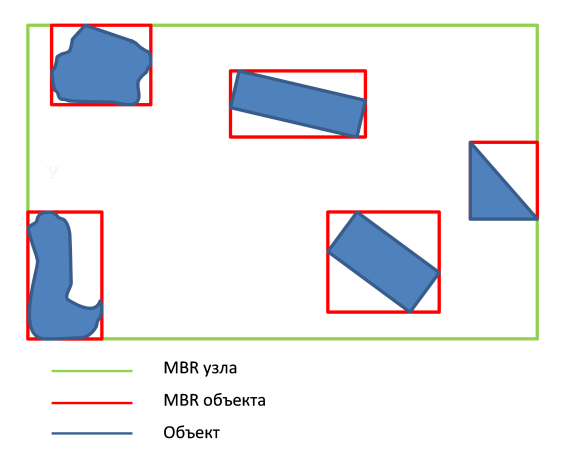
ツリーは、オブジェクトを交互に挿入することで構築されます。 ノードがオーバーフローすると、ノードが分割され、必要に応じてすべての親ノードが分割されます。 特定のデータ構造に対する検索クエリの有効性は、いくつかの基準に依存します。
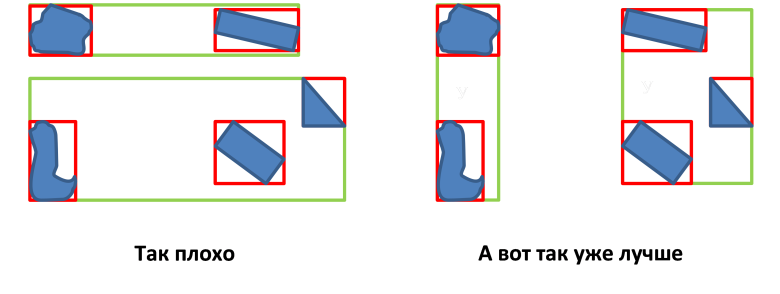
- MBRノードの領域を最小化する(オブジェクト間の空きスペースを最小化する);
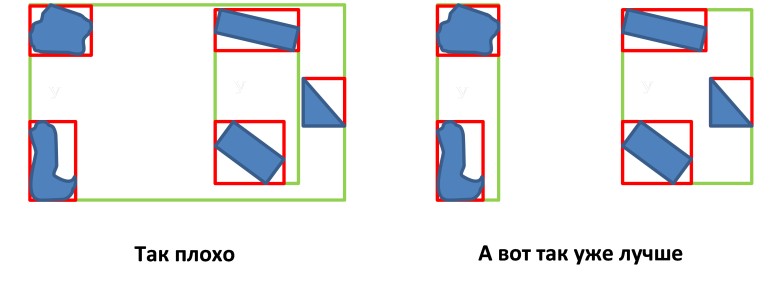
- MBRノードの重複領域の面積の最小化。
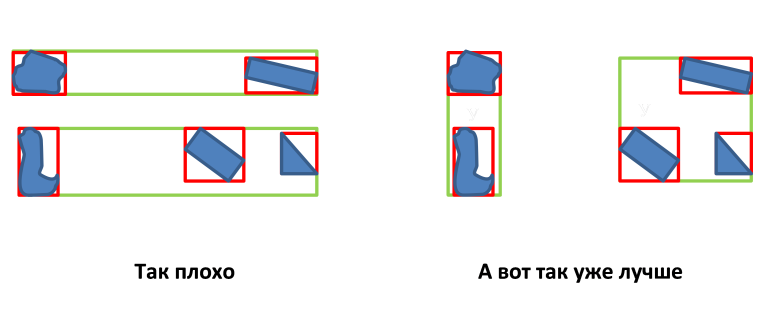
- MBRノードの境界線を最小化します。
Rツリーにはさまざまなタイプがあり、最終ノードの選択と混雑したノードの分割のみが異なります。
なぜR * -treeを選択したのですか? Antonin Gutmann(R-trees)が私の主観的な評価で提案した古典的なアプローチは、実際のプロジェクトでの使用にはまったく不適切です。 例として、ドイツの郵便局用に構築された
Wikipediaの資料、すなわちRツリーを引用します。
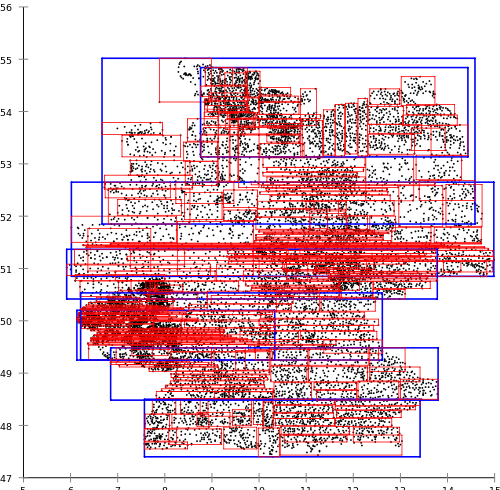
同時に、Norbert Beckmann、Hans-Peter Kriegel、Ralph Schneider、およびBernhard Seegerによって提案されたR *ツリーアルゴリズムは、次の結果をもたらします。
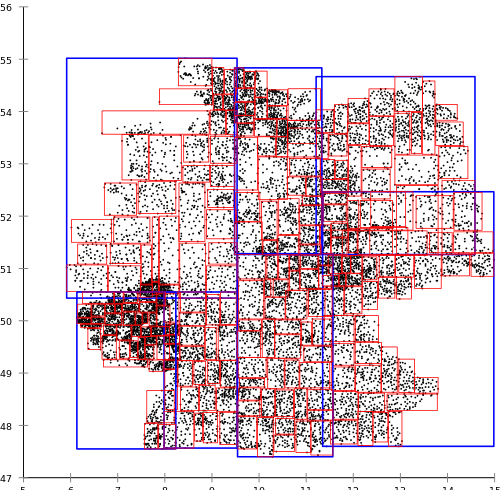
R * -treeは、作成するのにより多くのリソースを消費しますが、通常のR-treeよりも検索クエリの結果が優れています。
挿入がどのように発生するかを検討してください。ブランチ(サブツリー)/ノードを選択するアルゴリズムと、ノードがいっぱいになったときにノードを分割するアルゴリズムが含まれています。
サブツリー選択アルゴリズム(chooseSubtree)
1.ルートノードとしてNを設定します
2. Nがエンドノードの場合、Nを返します
3.その他
4. Nの子ノードが最終ノード(リーフ)である場合、
5. MBRが挿入時のオーバーラップの最小増加を必要とする子ノードNを選択します
オブジェクトからノード
6.オーバーラップの増加が最小のノードが複数ある場合は、それらからノードを選択します
面積の最小の増加が必要です
7.面積の増加が最小のノードが複数ある場合は、それらからノードを選択します
最小面積で
8.それ以外の場合
9. MBRで面積の増加が最小である子ノードNを選択します
10.面積の増加が最小のノードが複数ある場合は、面積が最小のノードを選択します
11. Nを選択したノードに設定します。
12.手順2から繰り返します。
ノード分割アルゴリズム(splitNode)
分割オプションを見つけるために、R *-ツリーは次の方法を使用します。ノードは、左右の境界に沿った各座標軸に沿ってソートされます。 ソートされたバージョンごとに、ノードは2つのグループに分割されるため、
k =
[1 ...(maxCount-2 * minCount + 2)]の場合、最初のグループには
(minCount-1)+ k番目のノードが残ります。 そのような分布ごとに、次の指標が計算されます。
- エリア:エリア=エリア(最初のグループのMBR)+エリア(2番目のグループのMBR)
- 境界:マージン=マージン(最初のグループのMBR)+マージン(2番目のグループのMBR)
- オーバーラップ:オーバーラップ=エリア(最初のグループのMBR second 2番目のグループのMBR)
最適な分布は、次のアルゴリズムによって決定されます。
1. chooseSplitAxisを呼び出して、分布が発生する軸を決定します。
2. chooseSplitIndexを呼び出して、選択した軸上の最適な分布を決定します
3.オブジェクトを2つのノードに割り当てます
chooseSplitAxis
1.各軸について
2.ノードを左、次にMBRの右境界線で並べ替えます。
上記のようにノードを配布し、S-各配布のすべての境界の合計を計算します。
3. Sが最小の軸を選択します。
chooseSplitIndex
1.選択した軸に沿って、最小オーバーラップパラメーターを持つ分布を選択します
2.最小オーバーラップパラメーターを持つ分布が複数ある場合は、分布を選択します
最小面積で。
実際には挿入自体(insertObject)
1. chooseSubStreeを呼び出し、ルートノードを引数として渡してNノードを決定し、
オブジェクトEの挿入が発生する場所
2. Nのオブジェクトの数がmaxCountより小さい場合、
3. EをNに挿入します
4. Nおよびそのすべての親ノードのMBRを更新します
5.それ以外の場合、NおよびEに対してsplitNodeを呼び出します。
記事の R *ツリーの著者は、この構造の最高のパフォーマンスは
minCount =
maxCount *
40%で達成されると主張しています。
以上です。 私たちのツリーは構築されており、特定のエリアで適切なオブジェクトを見つけることは難しくありません。
特定のエリアでオブジェクトを見つけるためのアルゴリズム(findObjectsInArea)
1.現在のノードNが有限の場合、
2.ノードNの各子オブジェクトEについて、決定します
3. Eが検索領域と交差する場合、検索結果RにEを追加します。
4.それ以外の場合
5.ノードNの各子ノードnについて、決定します
6. nが検索領域と交差する場合、nに対してfindObjectsInAreaを呼び出します
次に、単に
findObjectsInAreaを呼び出して、ルートノードと検索領域を渡します。
基本的なアルゴリズムの動作をより明確に示すために、コードを見てみましょう。
実装後は、ベクターマップオブジェクトをレイヤーに分割し、これらのレイヤーを表示される最大スケールに設定し、各レイヤーのR *ツリーを構築するだけでした。結果はビデオで見ることができます: