今日のデータセンターでのデスクトップとクライアントPCの集中化は、ITコミュニティで議論の対象になりつつあり、このアプローチは大規模な組織にとって特に興味深いものです。 この点で最もホットなテクノロジーの1つはVDIです。 VDIを使用すると、クライアント環境のサービスを一元化し、アプリケーションの展開、セットアップと構成を簡素化し、セキュリティ要件への準拠を更新および監視できます。
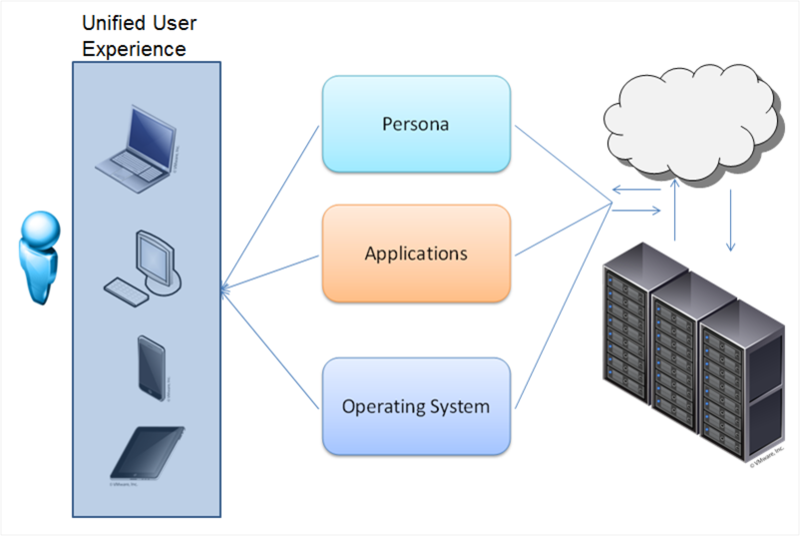
VDIは、ユーザーのデスクトップをハードウェアからバインド解除します。 永続的な仮想デスクトップと(最も一般的なオプション)柔軟な仮想マシンの両方を展開できます。 仮想マシンには、ユーザー認証中にベースOSに展開されるアプリケーションと設定の個々のセットが含まれます。 システムを終了すると、OSは「クリーン」な状態に戻り、変更やマルウェアを削除します。
システム管理者にとって非常に便利です。管理性、セキュリティ、高所での信頼性、アプリケーションはすべてのPCではなく単一のセンターで更新できます。 Officeパッケージ、データベースインターフェイス、インターネットブラウザー、その他の要求のないグラフィックアプリケーションは、どのサーバー(よく知られている1Cターミナルクライアント)でも実行できます。
しかし、より深刻なグラフィックステーションを仮想化する場合はどうでしょうか。
ここでは、グラフィックスサブシステムの仮想化なしでは実行できません。
3つの作業オプションがあります。
- GPUパススルー:1:VMに1つの専用GPU
- 共有GPU:ソフトウェア仮想化GPU
- 仮想GPU:ハードウェアの仮想化(HW&SW)
もっと詳しく考えてみましょう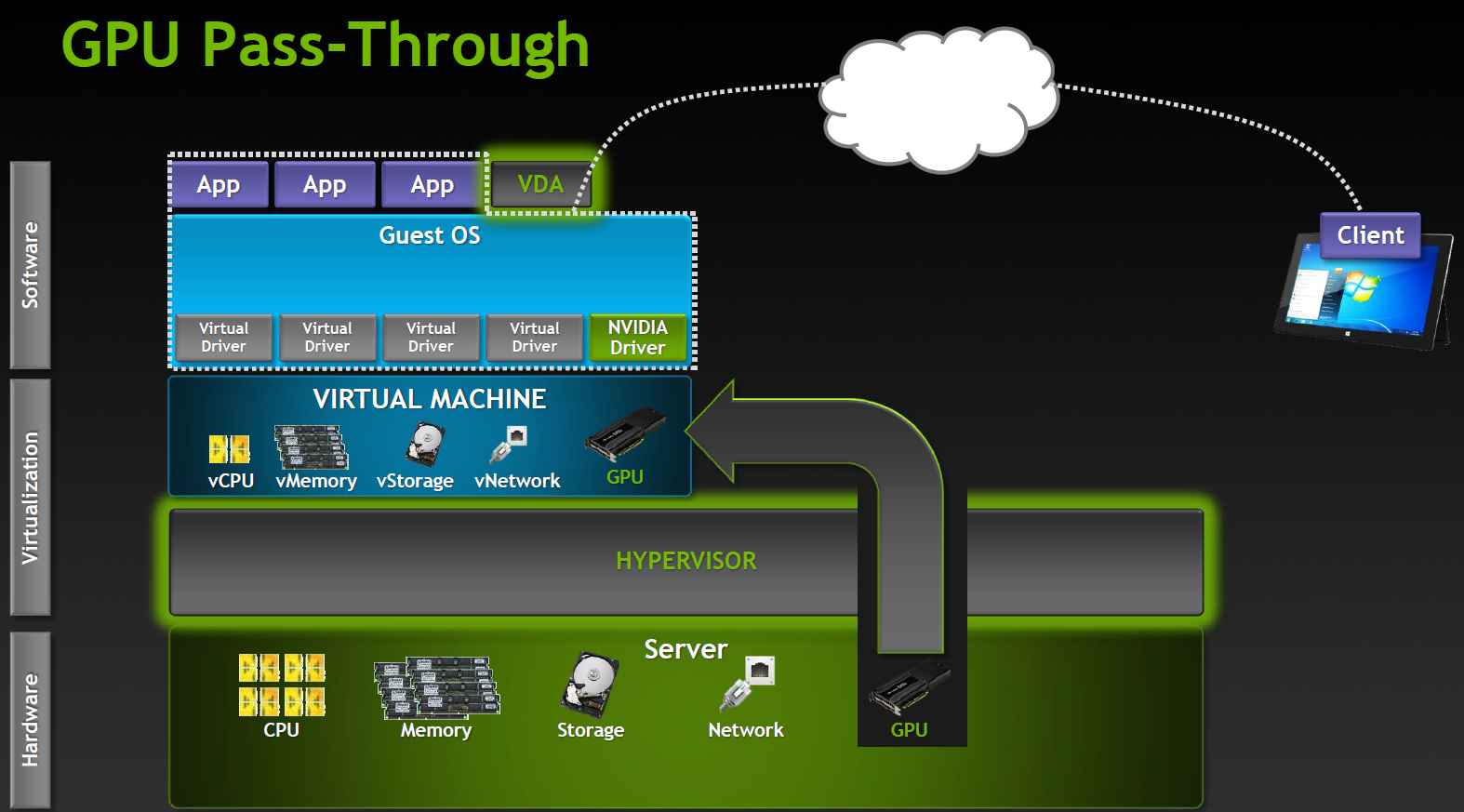 専用GPU
専用GPUCitrix XenDesktop 7 VDI配信およびvDGAを使用したVMware Horizon View(5.3以降)でサポートされる最も生産的な操作モード。 完全に動作するNVIDIA CUDA、DirectX 9,10,11、OpenGL 4.4。 他のすべてのコンポーネント(プロセッサ、メモリ、ドライブ、ネットワークアダプター)は仮想化され、ハイパーバイザーインスタンス間で共有されますが、1つのGPUは1つのGPUのままです。 各仮想マシンは、パフォーマンスを実質的に低下させることなくGPUを取得します。
明らかな制限は、そのような仮想マシンの数がシステムで使用可能なグラフィックスカードの数によって制限されることです。
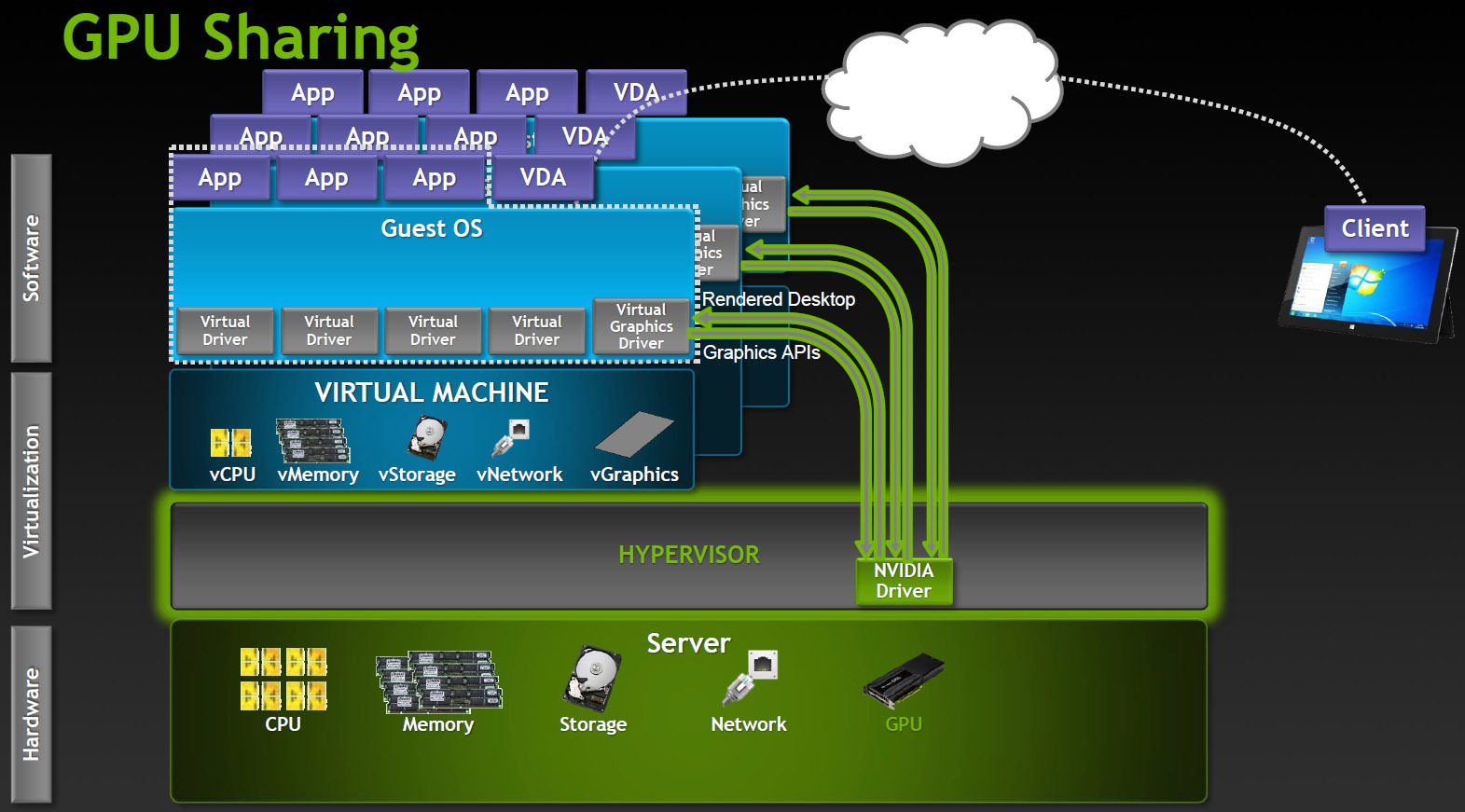 共有GPU
共有GPUMicrosoft RemoteFX、VMware vSGAを搭載しています。 このオプションはVDIソフトウェアの機能に依存しており、仮想マシンは専用アダプターで動作するようです。サーバーGPUも単一ホストで動作すると考えていますが、これは実際には抽象化レベルです。 ハイパーバイザーはAPI呼び出しをインターセプトし、すべてのコマンド、レンダリングリクエストなどを翻訳してからグラフィックドライバーに送信し、ホストマシンは仮想カードドライバーで動作します。
多くの場合、共有GPUは非常に合理的なソリューションです。 アプリケーションが複雑すぎない場合、かなりの数のユーザーが同時に作業できます。 一方、APIの変換には多くのリソースが費やされており、アプリケーションとの互換性を保証することは不可能です。 特に、VDI製品の開発時に存在していたよりも新しいバージョンのAPIを使用するアプリケーションでは。
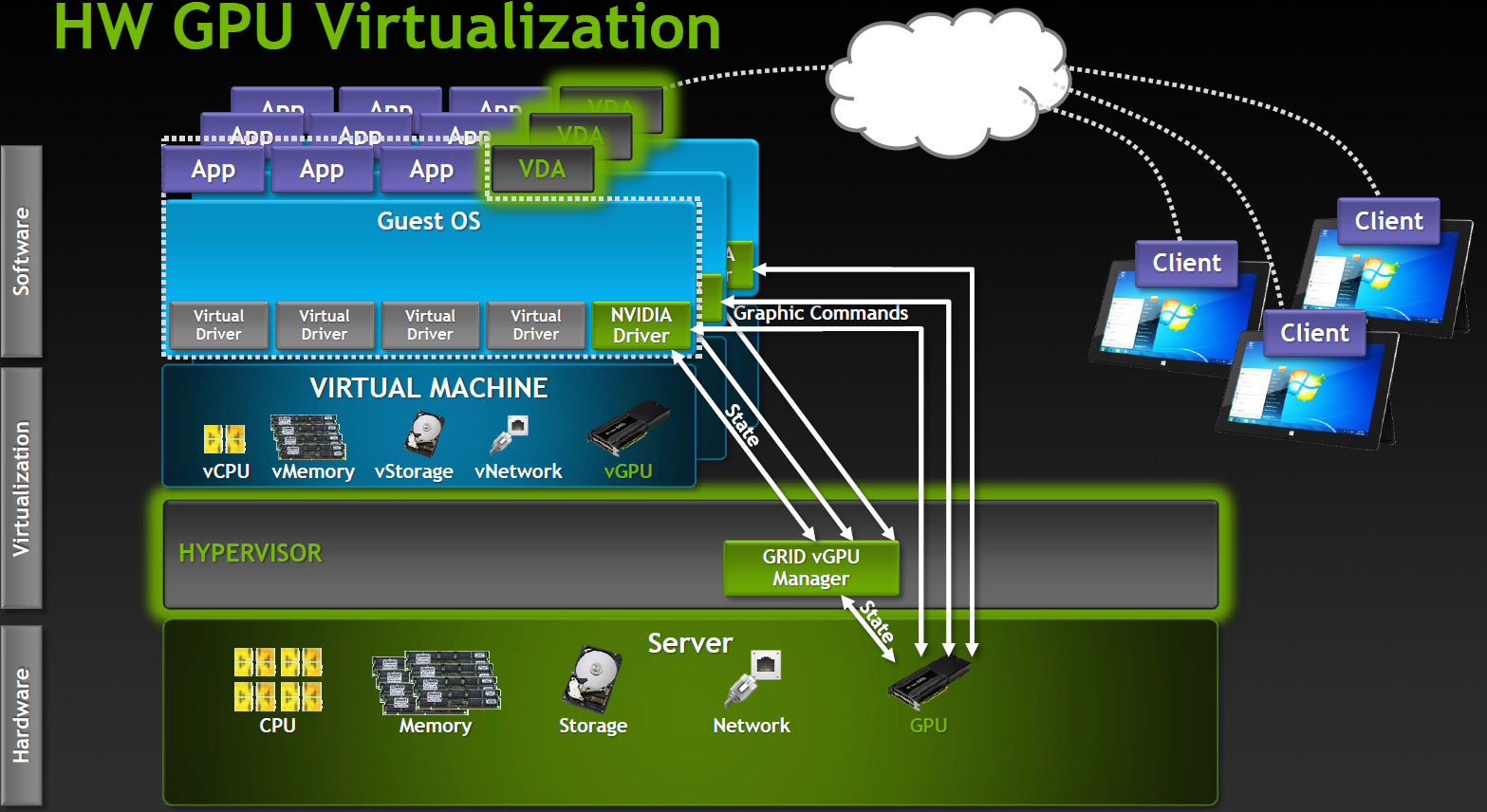 仮想GPU
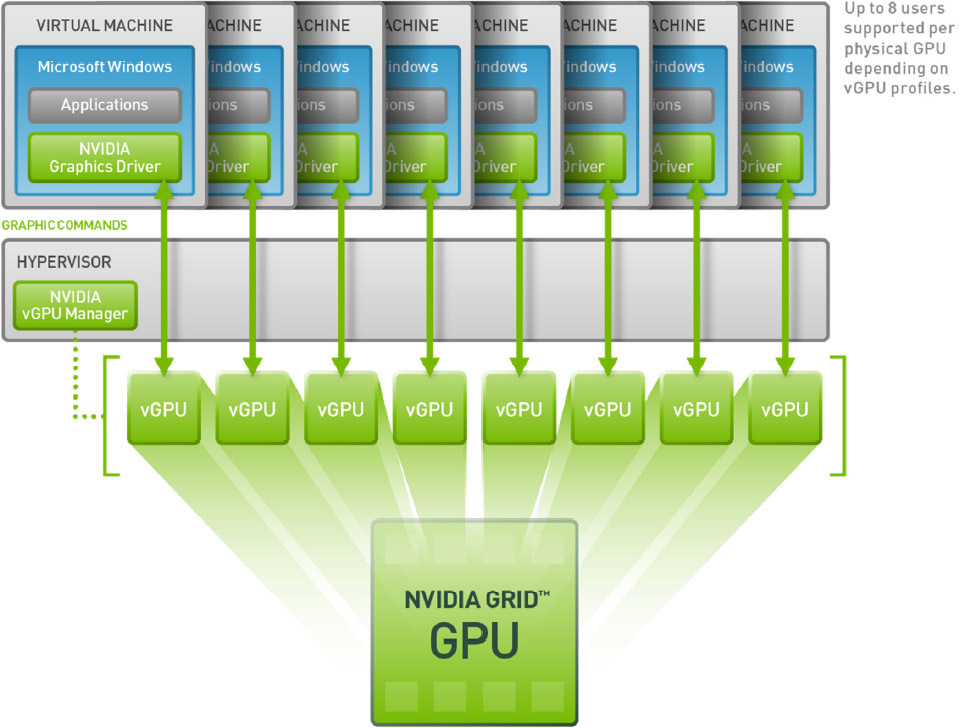
仮想GPUユーザー間でGPUを共有するための最も高度なオプションは、現在Citrix製品でのみサポートされています。
どのように機能しますか? vGPUを備えたVDI環境では、各仮想マシンは、各仮想マシンで使用可能な専用のvGPUドライバーを備えたハイパーバイザーを介して実行されます。 各vGPUドライバーはコマンドを送信し、専用チャンネルを使用して1つの物理GPUを制御します。
処理されたフレームは、ユーザーに送信するために、ドライバーによって仮想マシンに返されます。
この動作モードは、最新世代のNVIDIA GPU-Keplerで可能になりました。 Keplerには、仮想ホストアドレスを物理システムアドレスに変換するメモリ管理ユニット(MMU)があります。 各プロセスは独自の仮想アドレススペースで動作し、MMUは物理アドレスを共有するため、リソースの交差や闘争はありません。
カードのアバター ラインナップ
ラインナップ | グリッドK1 | グリッドK2 |
| GPUの数 | 4 xエントリーKepler GPU | 2 xハイエンドKepler GPU |
| 合計NVIDIA CUDAコア | 768 | 3072 |
| 総メモリサイズ | 16 GB DDR3 | 8 GB GDDR5 |
VDIの種類ただし、特性で分割するだけでは不十分で、GRIDではvGPU仮想プロファイルに分割できます。
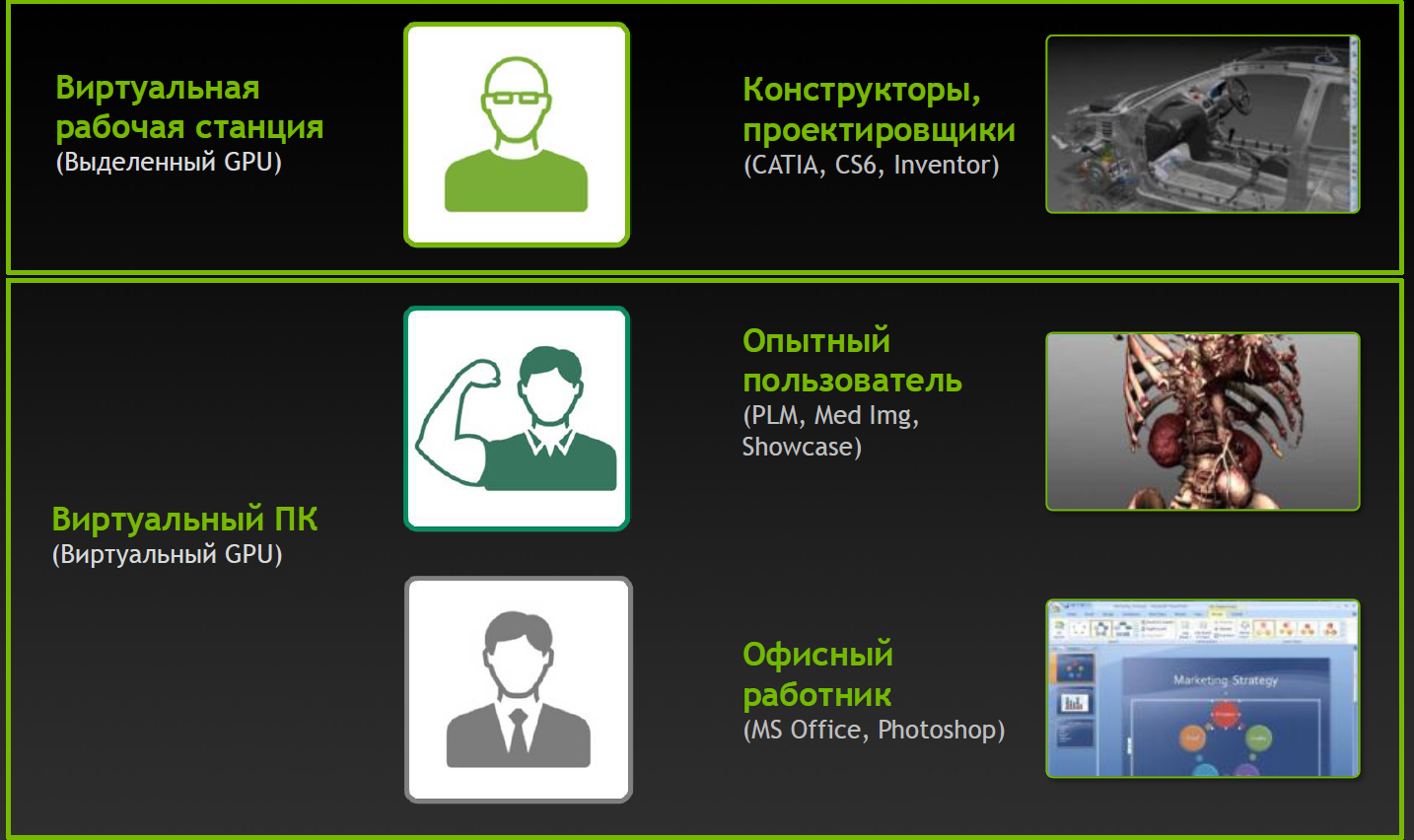 ユーザータイプビジョン
ユーザータイプビジョン| 地図 | GPU番号 | 仮想GPU | ユーザータイプ | メモリサイズ(MB) | 仮想スクリーンの数 | 最大解像度 | GPU /カードあたりのvGPUの最大数 |
| グリッドK2 | 2 | グリッドK260Q | デザイナー/デザイナー | 2048 | 4 | 2560x1600 | 2/4 |
| グリッドK2 | 2 | グリッドK240Q | 中級デザイナー/デザイナー | 1024 | 2 | 2560x1600 | 4/8 |
| グリッドK2 | 2 | グリッドK200 | 会社員 | 256 | 2 | 1920x1200 | 8/16 |
| グリッドK1 | 4 | グリッドK140Q | デザイナー/エントリーレベルデザイナー | 1024 | 2 | 2560x1600 | 4/16 |
| グリッドK1 | 4 | グリッドK100 | 会社員 | 256 | 2 | 1920x1200 | 8/32 |
プロファイルとアプリケーションQインデックス付きのプロファイルは、Quadroシリーズカードと同様に、多くのプロフェッショナルアプリケーション(Autodesk Inventor 2014やPTC Creoなど)で認定されています。
 完全な仮想幸福!
完全な仮想幸福!NVIDIAは、追加の品種について考えなかった場合、それ自体に忠実ではありません。 オンデマンドのゲームサービス(Gaming-as-a-Service、GaaS)が人気を集めており、仮想化とユーザー間でGPUを分割することで優れたボーナスを得ることができます。
| 商品名 | グリッドK340 | グリッドK520 |
| 対象市場 | 高密度ゲーミング | 高性能ゲーミング |
| 同時#ユーザー1 | 4-24 | 2–16 |
| ドライバーサポート | グリッドゲーム | グリッドゲーム |
| 合計GPU | 4 GK107 GPU | 2 GK104 GPU |
| NVIDIA CUDAコアの合計 | 1536(384 / GPU) | 3072(1536 / GPU) |
| GPUコアクロック | 950 MHz | 800 MHz |
| メモリサイズ | 4 GB GDDR5(1 GB / GPU) | 8 GB GDDR5(4 GB / GPU) |
| 最大出力 | 225 W | 225 W |
クラウドでのゲームの種類仮想化のパフォーマンスへの影響サーバー構成:Intel Xeon CPU E5-2670 2.6GHz、デュアルソケット(16物理CPU、32 vCPU with HT)
メモリ384GB
XenServer 6.2 Tech Preview Build 74074c
仮想マシンの構成:VM Vcpu:4仮想CPU
メモリー:11GB
XenDesktop 7.1 RTM HDX 3D Pro
AutoCAD 2014
ベンチマークCADALYST C2012
NVIDIAドライバー:vGPUマネージャー:331.24
ゲストドライバー:331.82
測定手順は簡単です。仮想マシンでCADALYSTテストを実行し、新しい仮想マシンを追加するときのパフォーマンスを比較しました。
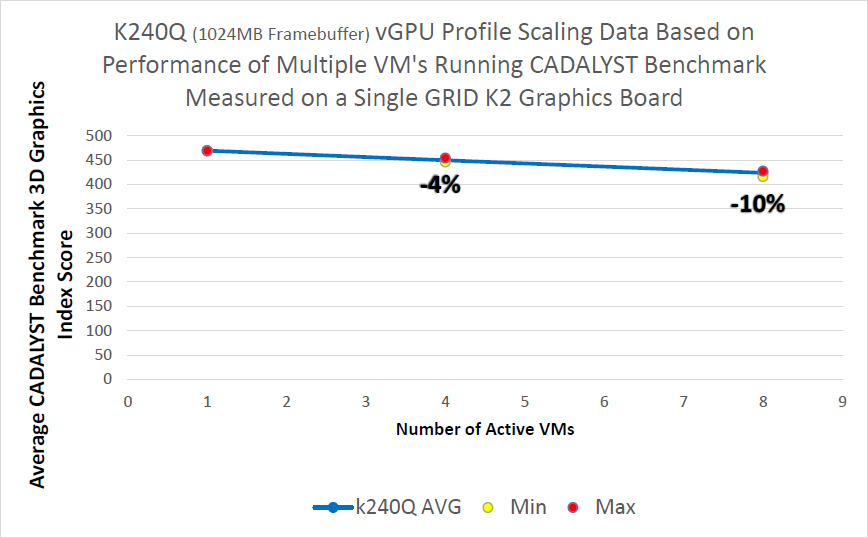
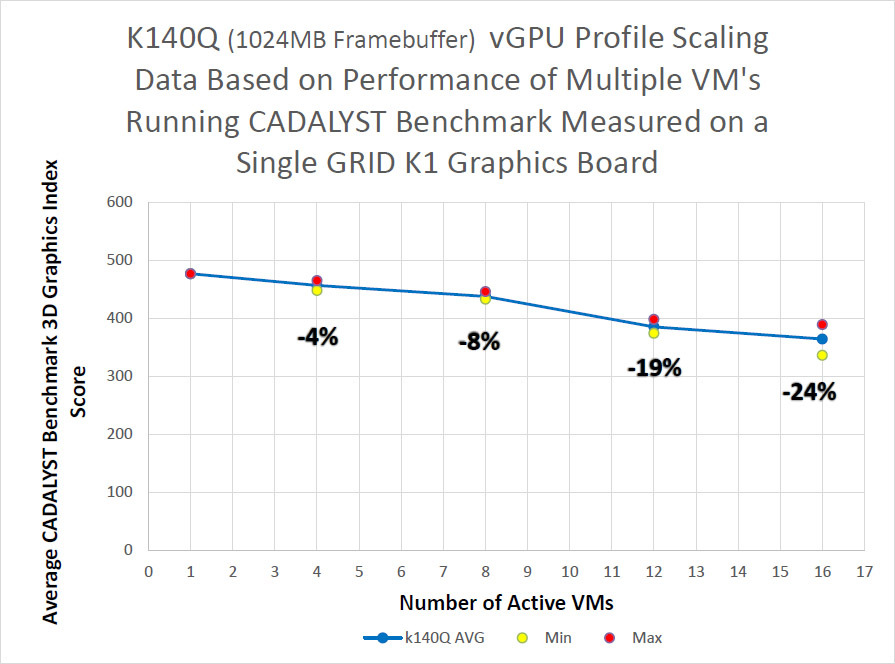

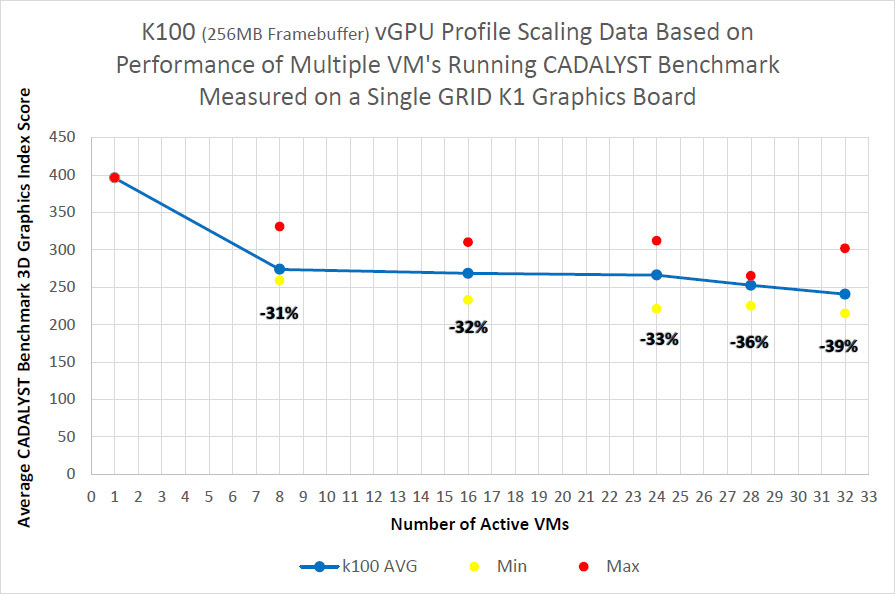
結果からわかるように、古いK2モデルと認定プロファイルでは、8台の仮想マシンを起動するとドロップが約10%になり、K1モデルではドロップが強くなりますが、仮想マシンは2倍になります。
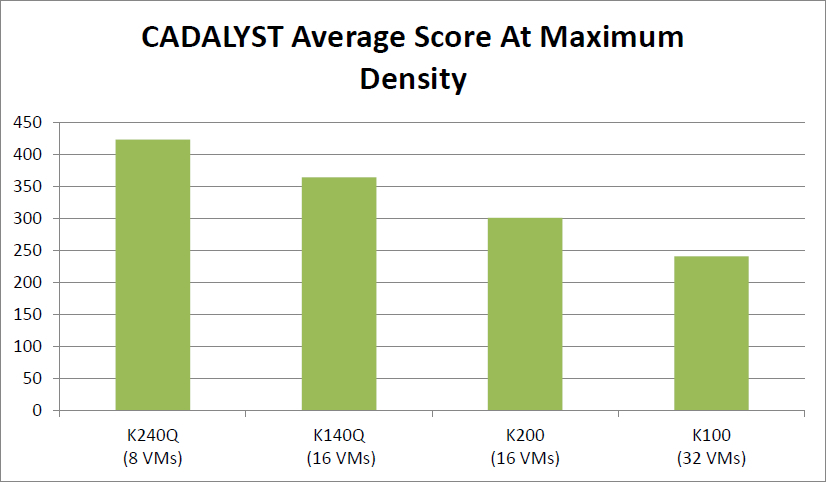
仮想マシンの最大数を持つカードの絶対的な結果:
 カードを置く場所は?
カードを置く場所は?4枚のIntel Xeon PhiまたはGPGPUカードをインストールするように設計された
Hyperion RS225 G4モデルを導入しました。

2つのXeon E5-2600 v2プロセッサ、最大1テラバイトのRAM、ハードドライブ用の4つのシート、高速ネットワークおよび一対の標準ギガビットネットワークコネクタに接続するためのInfiniBand FDRまたは40Gイーサネット。
サーバーへのカードのインストール:


サーバー内のマップ:


また、さまざまな状況に対応する典型的なソリューションもいくつかあります。