ソフトウェアを開発するとき、興味深いタスクがしばしば発生します。 これらの1つ:ユーザーの地理座標での作業。 何百万人ものユーザーがサービスを使用し、RDBMSへのリクエストが頻繁に発生する場合、アルゴリズムの選択が重要な役割を果たします。 多数のリクエストを最適に処理し、猫の下で説明されている次の地理的位置を探す方法について。
最近傍検索タスク
Pushwooshプッシュ通知
サービスの開発プロセスでは、かなりよく知られているタスクが発生しました。 多くのジオフェンスがあります。 ジオフェンスは地理座標によって設定されます。 ユーザーがそのようなジオフェンスの1つ(たとえば、スナックバー)を通過すると、プッシュ通知を受信する必要があります(「いらっしゃい、20%割引でサインアップしてください)」。 簡単にするために、すべてのジオフェンスの半径が同じであると想定しています。 多数のジオフェンスと多数のユーザー
(5億人!)がいる状況では、常に移動しています-最寄りのジオフェンスの検索は可能な限り迅速に実行する必要があります。 英語文学では、このタスクは
最近傍探索として知られて
います 。 一見、この問題を解決するには、ユーザーから各ジオフェンスまでの距離を計算する必要があり、このアルゴリズムの複雑さは線形O(n)です(nはジオフェンスの数)。
しかし、O(log n)の対数でこの問題を解決しましょう!地理座標
単純な緯度と経度から始めましょう。 地球の表面上の点の位置を示すには、次を使用できます。
- 緯度-北から南へ。 0は赤道です。 -90〜90度で変化します。
- 経度(longitude)-西から東へ。 0-子午線ゼロ(グリニッジ)。 -180から180度まで変化します。
xは経度、yは緯度であることに注意する必要があります(Googleマップ、Yandex.Maps、および他のすべてのサービスは最初の経度を示します)。
地理座標は空間に変換できます-ちょうど点(x、y、z)。 詳細に興味がある人は誰でも
ウィキペディアを見ることができます。
精度は小数点以下の桁数によって決まります。
| 学位 | 距離 |
|---|
| 1 | 111キロ |
| 0.1 | 11.1キロ |
| 0.01 | 1.11 km |
| 0.001 | 111メートル |
| 0.0001 | 11.1 m |
| 0.00001 | 1.11 m |
| 0.000001 | 11.1センチ |
1メートルまでの精度が必要な場合は、小数点以下5桁を格納する必要があります。
ジオハッシュ
数百万人が使用するサービスがあり、地理座標を保存するとします。 この場合の明らかなアプローチは、テーブルに緯度/経度の2つのフィールドを入力することです。 8バイトを占有する倍精度(float8)を使用できます。 その結果、1人のユーザーの座標を保存するには16バイトが必要です。
しかし、
ジオハッシュと呼ばれる別のアプローチがあります。 アイデアはシンプルです。 緯度と経度は数値にエンコードされ、その後base-32でエンコードされます。 マップは4x8マトリックスに分割され、各セルには記号(英数字)が割り当てられます。
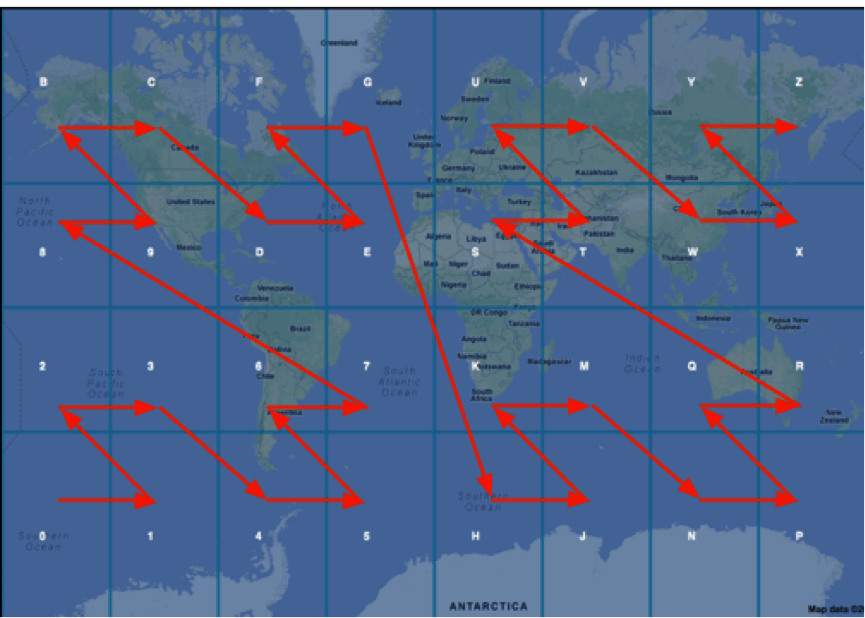
精度を高めるために、各セルは小さなセルに分割され、シンボルはコードに追加されます(正確には数値であり、その後base-32でエンコードされます)。
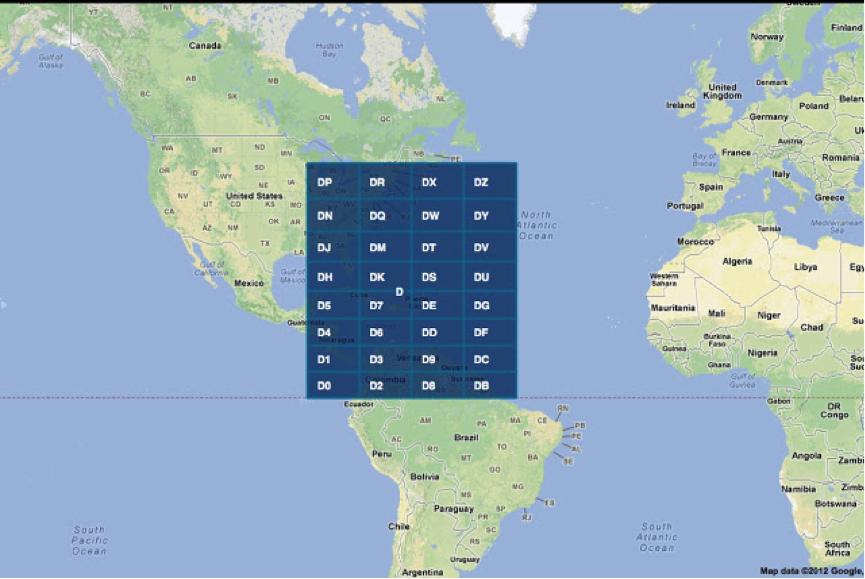
パーティション化は、必要な精度で実行できます。 このようなコードは各ポイントに固有です。
構築アルゴリズムの詳細については説明しません
。Wikipediaで読むことができます。 彼の考えは
算術コーディングに似ています。 このコードはリバーシブルです。 多くのテクノロジーには、例えば
MongoDBなどのジオハッシュを操作するためのメソッドが既に組み込まれています。
例:座標57.64911、10.40744は、u4pruydqqvj(11文字)でエンコードされます。 必要な精度が低い場合、コードは少なくなります。
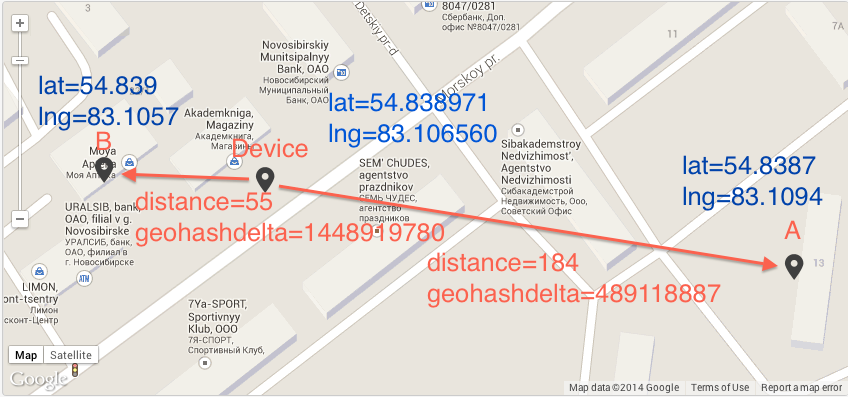
このコードの特徴は、通常、近くのポイントに同じプレフィックスが付いていることです。 また、ジオハッシュ間の差を計算して、2つのポイントの近接度を判断できます。 しかし、残念ながら、このアルゴリズムは正確ではありません。これは前の画像からはっきりと見ることができます。 コード7および8のセルは、セル2および8よりも離れています。
例として、ジオハッシュが間違った結果を与える画像を示します(geohashdelta-base32なしのジオハッシュの違い)
問題の精度を無視できる場合は、テーブルにジオハッシュフィールドを作成し、それにインデックスを追加して対数を検索できます。
完全検索
ストアドプロシージャを書くことができます
create or replace function gc_dist(_lat1 float8, _lon1 float8, _lat2 float8, _lon2 float8) returns float8 as $$ DECLARE radian CONSTANT float8 := PI()/360; BEGIN return ACOS(SIN($1*radian) * SIN($3*radian) + COS($1*radian) * COS($3*radian) * COS($4*radian-$2*radian)) * 6371; END; $$ LANGUAGE plpgsql;
彼女を使う
explain SELECT *, gc_dist(54.838971, 83.106560, lat, lng) AS pdist FROM geozones WHERE applicationid = 3890 ORDER BY pdist ASC LIMIT 10;
ただし、最終的にはSeqスキャンが行われますが、これはあまり快適ではありません。
Limit (cost=634.72..634.75 rows=10 width=69) -> Sort (cost=634.72..639.72 rows=2001 width=69) Sort Key: (gc_dist(54.838971::double precision, 83.10656::double precision, (lat)::double precision, (lng)::double precision)) -> Seq Scan on geozones (cost=0.00..591.48 rows=2001 width=69)
KdツリーとRツリー
精度が無視できない場合の対処方法 このための特別な
Kdツリーデータ構造が既にあります。 緯度と経度を(x、y、z)に変換して、それらの上にツリーを構築し、平均して対数を求めてツリーを検索できます。
Postgis
PostGISは、PostgreSQL RDBMSの地理的機能の処理を大幅に拡張する拡張機能です。
この問題を解決するために、3次元座標系SRID 4326(
WGS 84 )を使用します。 この座標系は、地球の重心に対する座標を決定し、誤差は2 cm未満です。
ubuntuのようなシステムを使用している場合は、PostGISをパッケージからインストールできます(PostgreSQL 9.1の場合):
sudo apt-get install python-software-properties; sudo apt-add-repository ppa:ubuntugis/ppa; sudo apt-get update; sudo apt-get install postgresql-9.1-postgis;
そして、必要な拡張機能を接続します。
CREATE EXTENSION postgis; CREATE EXTENSION btree_gist;
\ dxを使用すると、インストールされているすべての拡張機能を確認できます。
ロケーションフィールドのインデックスリレーションを作成します
CREATE TABLE geozones_test ( uid SERIAL PRIMARY KEY, lat DOUBLE PRECISION NOT NULL CHECK(lat > -90 and lat <= 90), lng DOUBLE PRECISION NOT NULL CHECK(lng > -180 and lng <= 180), location GEOMETRY(POINT, 4326) NOT NULL
次に、最も近いジオフェンスを検索するには、次のクエリを使用できます
SELECT *, ST_Distance(location::geography, 'SRID=4326;POINT(83.106560 54.838971)'::geography)/1000 as dist_km FROM geozones_test ORDER BY location <-> 'SRID=4326;POINT(83.106560 54.838971)' limit 10;
ここで、<->は距離演算子です。 距離を計算し、次の10個のジオフェンスを見つけました!
やめて! 結局、このクエリはテーブル内のすべてのレコードを調べて、各ジオフェンスO(n)までの距離を計算する必要があります。
EXPLAIN ANALYZEリクエストを見てみましょう
EXPLAIN ANALYZE SELECT *, ST_Distance(location::geography, 'SRID=4326;POINT(83.106560 54.838971)'::geography)/1000 as dist_km FROM geozones_test ORDER BY location <-> 'SRID=4326;POINT(83.106560 54.838971)' limit 10; Limit (cost=0.00..40.36 rows=10 width=227) (actual time=0.236..0.510 rows=10 loops=1) -> Index Scan using geozones_test_location_idx on geozones_test (cost=0.00..43460.37 rows=10768 width=227) (actual time=0.235..0.506 rows=10 loops=1) Order By: (location <-> '0101000020E6100000F4C308E1D1C654406EA5D766636B4B40'::geometry) Total runtime: 0.579 ms
インデックススキャン! 魔法はどこですか?彼女はGiSTインデックスに登録されています。
PostgreSQLは3種類のインデックスをサポートしています。
- Bツリー -データを1つの軸に沿ってソートできる場合に使用します。 例:数字、文字、日付。 GISデータは、合理的な方法で単一軸に沿って並べ替えることはできません((0,0)または(0,1)または(1,0)?)。したがって、Bツリーはそれらをインデックス化するのに役立ちません。 Bツリーは、演算子<、<=、=、> =、>などで動作します。
- ハッシュ -等価比較でのみ機能します。 また、このインデックスは先行書き込みログではありません。つまり、バックアップからのインデックスは増加しません。
- GINインデックスは、配列など、複数のキーを含む値を処理できる「逆」インデックスです。
- GiSTインデックス (一般化された検索ツリー)は、多くの異なるインデックス戦略を実装できる一種のインフラストラクチャです。 GiSTインデックスは、データを片側のオブジェクト(片側のもの)、交差するオブジェクト(重なり合うもの)、内側のオブジェクト(内側にあるもの)に分割し、GISデータを含む多くのタイプのデータに使用できます。
PostGISによって実装されたGiSTインデックスは、検索時に
距離演算子 <->をサポートします。 また、このインデックスは合成できます!
この機能は、PostGISを使用せずに
btree-gistインデックスを使用して実装できますが、PostGISは緯度と経度をWGS 84に変換する便利な方法を提供します。
参照:
[1]
postgresql.ru.net/postgis/ch04_6.htmlリクエストの興味深い例
[2]使いやすさへの賞賛
boundlessgeo.com/2011/09/indexed-nearest-neighbour-search-in-postgis[3]このアプローチは緯度/経度だけでなく、道路やその他の興味深いオブジェクトにも使用できるというプレゼンテーション
www.hagander.net/talks/Find%20your%20neighbours.pdf[4] KNN GIst-index
開発者のプレゼンテーションwww.sai.msu.su/~megera/postgres/talks/pgcon-2010-1.pdfPS
Postgresバージョン> = 9.1
PostGISバージョン> = 2.0