はじめに
今日、多くの音声認識方法があります。 最も一般的な形式では、ほとんどの方法は、信号の署名(指紋)を構築するためのアルゴリズム(できるだけコンパクトで、同時に属性セットのトラックを最も正確に記述する)、データベースでの検索のためのアルゴリズム、および偽陽性を遮断するためのアルゴリズムで構成されます。
セカンドスクリーンアプリケーションを構築するためのテクノロジを選択するという課題に直面しました。

さらに、既知の精度特性に基づく認識アルゴリズムの比較は、これらの特性がさまざまなテストデータおよびさまざまな第1種のエラー(偽陽性)で得られたため、かなりarbitrary意的です。 また、タスクのコンテキストに基づいて、現代のモバイルデバイスのマイクパラメーターによる歪みを伴う、空気のオーディオ信号の認識に関するアルゴリズムの有効性に興味がありました。
オープンソースには要件を満たす比較データが見つからなかったため、オーディオストリームと歪みの特性を考慮して、音声認識アルゴリズムの独自の研究を実施することにしました。 候補者として、J。HaitsmaとA. Wangを選択しました。 両方とも広く知られており、ウィンドウフーリエ変換を使用して得られた時間周波数特性の分析に基づいています。
署名作成方法の説明
[1]でJaap HaitsmaとTon Kalkerによって提案されたオーディオ信号署名構築スキームを図1に示します。表1は、アルゴリズムの各段階で得られた画像を示しています。
|
| 図1-Jaap HaitsmaとTon Kalkerの署名作成図 |
信号スペクトログラムは、31/32のオーバーラップでハンウィンドウを使用して作成されます。 たとえば、ウィンドウサイズが0.37秒の場合、時間軸に沿ったスペクトログラムのサンプリングステップは11.6 msです。 次のステップで、アルゴリズムは周波数軸をメルスケールの33個のサブバンドに分割し、各瞬間について、サブバンドの総エネルギーを計算します。 結果の一時的なエネルギー分布は、次の式に従ってエンコードされます。
どこで
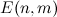
-エネルギー
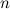
サブフレームフレーム

。
表1-署名Jaap HaitsmaとTon Kalkerを構築する主な段階
| 信号スニペット |
| オリジナル | 歪んだ |
| スペクトログラムの構築 |
| |
| サブバンド上のエネルギー分布の計算 |
| |
| エネルギー分布コーディング |
| |
したがって、11.6 msの各信号間隔は32ビットワードで記述されます。 実験的研究[1]に示されているように、多くのタイプの歪み認識に対する信頼性と耐性を確保するには、256ワードで十分です。これは3秒のクエリに相当します。
Avery Li-Chun Wang [2]によって提案された認識アプローチは、スペクトログラムの振幅のピークと、星座と呼ばれるペアの関係に基づいています。
このアプローチを実装する際の主な難点は、歪みに強いピークの検索アルゴリズムです。 [3、4]では、関連するテクニックの例が示されています。 スペクトログラムの多くの局所的最大値の中から、最大エネルギーを持つピークが選択されます。 さらに、トラックの記述がノイズに耐えるためには、周波数と時間の多様性を確保する必要があります。 このために、さまざまなぼかしおよびしきい値クリッピング技術が使用されます[3、4]。 原則として、オーディオトラックのスペクトログラムは時間軸に沿ってフレームに分割され、各フレームは特定の数のピークによって特徴付けられます。 このように密度を制限することにより、最大の生存確率でピークを残すことができ、同時にスペクトルの時間変化を詳細に記述することができます。 例として、表2はアルゴリズムの主要な段階で得られた画像を示しています。
表2-A. Wangによって提案された署名を作成する主な段階
| 信号スニペット |
| オリジナル | 歪んだ |
| スペクトログラムの構築 |
| |
| ピーク検索 |
| |
| ペアリングピーク |
| |
検索プロセスを高速化するために、ピークはペアで結合されます。各ピークは、特定のターゲットゾーン内の時間軸に沿って右側にある他の多くのピークに関連付けられます。 加速係数は、次の方程式によって概算されます。
どこで
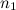
そして
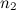
-ピークとそのペアをそれぞれエンコードするために必要なビット数。
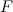
-参照に関連するピークの数(分岐係数)。
さらに、ハッシュの一意性の増加は、その生存の確率の低下を伴います。これはおよそ次のように推定されます:
どこで
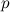
-スペクトログラムのピークの生存確率。
したがって、ピーク密度と分岐係数の値を見つける必要があります
検索速度と信号認識の確率の間の妥協点を提供します。
信号シグネチャは、2つのコンポーネントで構成されます。ペアのハッシュと、時間軸に沿った変位のコードです。 ペアをエンコードするために必要なビットの最小数は、式によって決定されます。
どこで
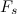
-信号のサンプリングレート。
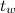
、
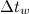
-スペクトログラムの作成に使用されるウィンドウのサイズとステップ。

、

-したがって、ペアのピーク間の時間軸および周波数軸に沿った最大許容距離。

-最も近い整数を取得します。
実験結果
使用分野に基づいて、上記で検討された認識アプローチの比較は、合計2000分のテレビ放送の音声トラックに基づいて行われました。 テスト信号として、テレビで再生され、環境の外来ノイズ特性の存在下で信号ソースから異なる距離にあるiPhone 4、Nexus 7、Samsung GT3100モバイルデバイスで記録された元のトラックの記録を使用しました。 テストモノ信号のサンプリング周波数は8 kHz、振幅エンコードは16ビットでした。 これらのうち、4秒間で2,000個のテストクエリが生成されました。
J. Haitsmaシグネチャを使用する場合、検索はブルートフォースメソッドを使用して実行されました。これは、ハミングメトリックに基づいてデータベース内の各フラグメントとクエリを直接比較する方法です。 要求は、ビットごとの比較により、その署名と見つかったフラグメントの署名が65%以上一致した場合に見つかったと見なされます。
署名は王の原則に基づいて構築され、ハンウィンドウサイズは64ミリ秒、シフトは32ミリ秒でした。 スペクトログラムのピークを検索する独自のバージョンが実装されました。これは、プロトタイプと比較して、空気のオーディオ信号を認識するのに適していました[3]。 持続時間が4秒のフラグメントは、平均で200ピークで特徴付けられ、1000ペアで記述されました。 決定を下すために、データベースで利用可能な各回答オプションのスコアグラフ上のピークの一意性の概念の形式化を使用しました。 スコアが一意である場合、リクエストは認識されたとみなされました。
表3に、得られた認識アルゴリズムの精度結果を示します。 元のトラックとその中のリクエストオフセットが正しく識別された場合、オーディオフラグメントは正しく認識されたと見なされます。
表3-認識アルゴリズムの精度の比較
| アルゴリズム | モバイル機器 |
| iPhone 4 | Nexus 7 | サムスンGT3100 |
| fp 、% | fn 、% | fp 、% | fn 、% | fp 、% | fn 、% |
| J.ハイツマ、T。カルカー | 0.6 | 8 | 0.6 | 10 | 0.5 | 9 |
| A.ワンの原則に基づく | 0.6 | 20 | 0.6 | 25 | 0.6 | 24 |
| 注: fp-第1種のエラー(誤検知)。 fn-第2種のエラー(偽陰性)。 |
おわりに
J. Haitsmaアルゴリズムは、統合アプローチを使用して、周波数サブバンドにわたるエネルギーの分布、時間の変化をエンコードする差分アプローチ、およびハミング距離に基づくシグネチャの比較を記述します。 このすべてにより、この方法は歪みに対して潜在的に耐性があります。 同時に、スペクトログラムのピークの一致ペアの割合は1%から3%の範囲であり、これはノイズ耐性に最良の影響を与えず、認識確率の損失につながります。
ただし、J。Haitsma署名の可能性を最大限に活用するには、ブルートフォースメソッドを使用してデータベース内のクエリ検索を実行する必要があります。 Radeon R9 290Xグラフィックスカード上のGPUのアルゴリズムの実装により、0.6秒で2048クエリの並列検索が可能になります。 libeventライブラリを使用して作成されたサーバーは、1900 rpsの負荷に耐えることができ、平均応答時間は0.8 sです。 同時に、産業用ビデオカードは高価であり、通常のカードは少なくとも3ユニットのサイズを持つ標準のATXケースにインストールする必要があります。 そのようなケースの1つでは、2枚のカードを配置することに成功しました。 同時に、A。Wangの原理に基づく認識サーバーの実装は、Xeonマシンで、CPU E5-2660 v2 @ 2.20GHz / 32Gbは、平均応答時間8ミリ秒で2500 rpsの負荷に耐えることができます。
アルゴリズムのより最適な実装を取得する可能性を排除するものではなく、結果は絶対性を主張するのではなく評価として扱う必要があることに注意してください。
参照資料
- Jaap Haitsma、Ton Kalker「非常に堅牢なオーディオフィンガープリントシステム」
- エイブリィリーチュンワン 「強力なオーディオ検索アルゴリズム」
- D.エリス 「堅牢なランドマークベースのオーディオフィンガープリント」
- E.クロフト 「Yandexがマイクから音楽を認識する方法」