こんにちは、Habr。 CUDAプラットフォームで比較的簡単な実装と高性能を備えた並列ソートが必要になると思いました。 これはバブルソートです。 猫の下には説明とコードがあり、役に立つかもしれません(またはそうでないかもしれません...)。 すぐに、提示されたプログラムはGPUとCPUのパフォーマンスの比較におけるベンチマークであることを言わなければなりません。 読者を気にしない場合は、コンパイルして、計算結果をこの記事のコメントに入れてください。 これは科学用ではありません。 ただ面白い=)
少し思い出させてください
バブルソート方法の本質は、要素をペアワイズで比較し、ソートの方向に応じて特定の条件が満たされた場合に要素を置き換えることです。 シングルスレッドモードでのアルゴリズムの反復を以下に示します。整数の増加する配列を降順で並べ替えます(各行は現在の配列の状態です)-これは表1です。
表2は、マルチスレッドモードでのバブルによる並べ替えの繰り返しを示しています。これは非常に簡単に実装されます。一つなど したがって、配列全体が「ポップアップ」し始め、計算時間が大幅に短縮されます。
利益
すでに実行されたアクションの数から、並列ソートの方が速いことがわかります。 ただし、常にそうとは限りません。小さなサイズの配列では、データ転送に問題がないため、シングルスレッドモードの方が高速です。 ここでいくつかのテスト計算を行いましたが、結果は次のとおりです。
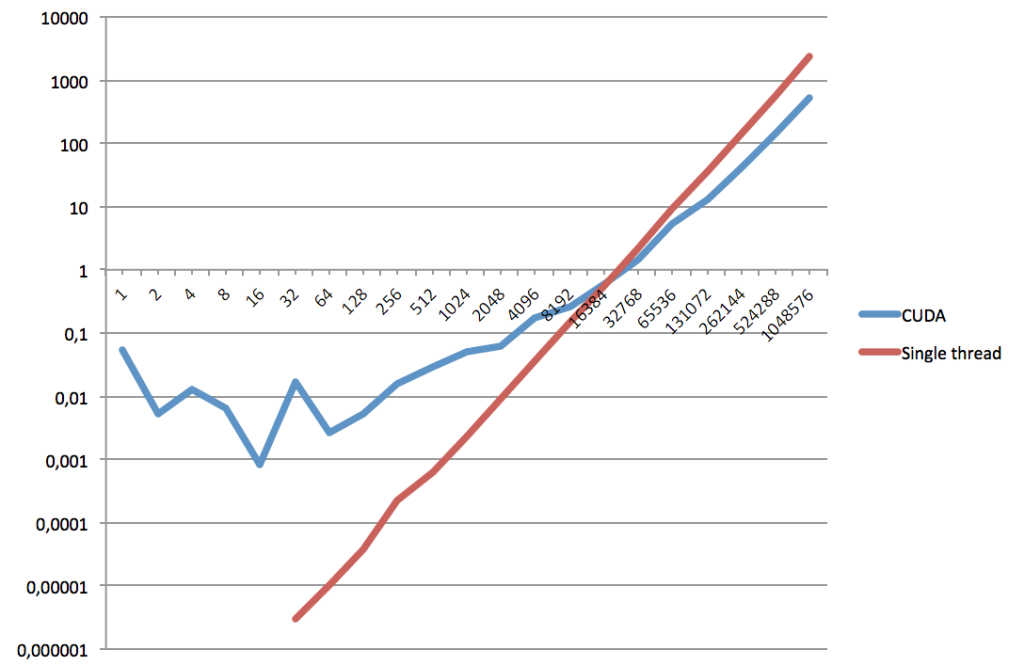
横軸は要素の数、縦軸は秒単位の実行時間です。
実装
CUDA C言語の実装コードを提供します。CUDAC言語には、CUDAとCPU(シングルスレッドモード)でSECURITY SECURITYソートを実行するコードが含まれています。 実際、これは、ビデオカードとプロセスでスマートソートがどのように機能するかについてのコンピューターのベンチマークです。 このプログラムの一部は、CUDAプラットフォーム上のビデオカードの並べ替え機能です。これは、基本的なcopy'n'pastを使用して、傑作の健康に使用できます。 コードは表の下に表示されます。
コンパイル方法???
さて、このためには、NVIDIAのWebサイトからCUDAのドライバーをダウンロードし、インストールし、Nvidia Toolkitをダウンロードし、Nvidia SDKをインストールし、インストールする必要があります。 幸いなことに、すべてがすでに1つのパッケージに含まれています。 要望があればCUDAをインストールする方法を書きますが、初心者の方には幸運を祈っています。
すべての準備が整い、nvidia CUDAがコンピューターで動作するようになったら、main.cuファイル(またはそこで呼び出されたもの)をコンパイルして、プログラムを実行し、結果を取得して、ここに配置します。
ワット、それは今のところ、読んでくれてありがとう。 じゃあね
PSアルゴリズムを高速化する方法を教えていただければ幸いです=)
表1:シングルソートバブルソート
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 1 | 0 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 1 | 2 | 0 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 1 | 2 | 3 | 0 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 1 | 2 | 3 | 4 | 0 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 1 | 2 | 3 | 4 | 5 | 0 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 1 | 2 | 3 | 4 | 5 | 6 | 0 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 0 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 0 | 9 | 10 | 11 | 12 | 13 | 14 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 0 | 10 | 11 | 12 | 13 | 14 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 0 | 11 | 12 | 13 | 14 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 0 | 12 | 13 | 14 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 0 | 13 | 14 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 0 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 0 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 2 | 1 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 0 |
| 2 | 3 | 1 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 0 |
| 2 | 3 | 4 | 1 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 0 |
| 2 | 3 | 4 | 5 | 1 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 0 |
| 2 | 3 | 4 | 5 | 6 | 1 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 0 |
| 2 | 3 | 4 | 5 | 6 | 7 | 1 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 0 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 1 | 9 | 10 | 11 | 12 | 13 | 14 | 0 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 1 | 10 | 11 | 12 | 13 | 14 | 0 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 1 | 11 | 12 | 13 | 14 | 0 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 1 | 12 | 13 | 14 | 0 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 1 | 13 | 14 | 0 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 1 | 14 | 0 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 1 |
| 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 3 | 2 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 1 | 0 |
| 3 | 4 | 2 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 1 | 0 |
| 3 | 4 | 5 | 2 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 1 | 0 |
| 3 | 4 | 5 | 6 | 2 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 1 | 0 |
| 3 | 4 | 5 | 6 | 7 | 2 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 1 | 0 |
| 3 | 4 | 5 | 6 | 7 | 8 | 2 | 9 | 10 | 11 | 12 | 13 | 14 | 1 | 0 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 | 2 | 10 | 11 | 12 | 13 | 14 | 1 | 0 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 2 | 11 | 12 | 13 | 14 | 1 | 0 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 2 | 12 | 13 | 14 | 1 | 0 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 2 | 13 | 14 | 1 | 0 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 2 | 14 | 1 | 0 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 2 | 1 | 0 |
| 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 4 | 3 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 2 | 1 | 0 |
| 4 | 5 | 3 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 2 | 1 | 0 |
| 4 | 5 | 6 | 3 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 2 | 1 | 0 |
| 4 | 5 | 6 | 7 | 3 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 2 | 1 | 0 |
| 4 | 5 | 6 | 7 | 8 | 3 | 9 | 10 | 11 | 12 | 13 | 14 | 2 | 1 | 0 |
| 4 | 5 | 6 | 7 | 8 | 9 | 3 | 10 | 11 | 12 | 13 | 14 | 2 | 1 | 0 |
| 4 | 5 | 6 | 7 | 8 | 9 | 10 | 3 | 11 | 12 | 13 | 14 | 2 | 1 | 0 |
| 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 3 | 12 | 13 | 14 | 2 | 1 | 0 |
| 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 3 | 13 | 14 | 2 | 1 | 0 |
| 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 3 | 14 | 2 | 1 | 0 |
| 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 3 | 2 | 1 | 0 |
| 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 1 | 0 |
| 5 | 4 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 3 | 2 | 1 | 0 |
| 5 | 6 | 4 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 3 | 2 | 1 | 0 |
| 5 | 6 | 7 | 4 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 3 | 2 | 1 | 0 |
| 5 | 6 | 7 | 8 | 4 | 9 | 10 | 11 | 12 | 13 | 14 | 3 | 2 | 1 | 0 |
| 5 | 6 | 7 | 8 | 9 | 4 | 10 | 11 | 12 | 13 | 14 | 3 | 2 | 1 | 0 |
| 5 | 6 | 7 | 8 | 9 | 10 | 4 | 11 | 12 | 13 | 14 | 3 | 2 | 1 | 0 |
| 5 | 6 | 7 | 8 | 9 | 10 | 11 | 4 | 12 | 13 | 14 | 3 | 2 | 1 | 0 |
| 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 4 | 13 | 14 | 3 | 2 | 1 | 0 |
| 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 4 | 14 | 3 | 2 | 1 | 0 |
| 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 4 | 3 | 2 | 1 | 0 |
| 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 2 | 1 | 0 |
| 6 | 5 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 4 | 3 | 2 | 1 | 0 |
| 6 | 7 | 5 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 4 | 3 | 2 | 1 | 0 |
| 6 | 7 | 8 | 5 | 9 | 10 | 11 | 12 | 13 | 14 | 4 | 3 | 2 | 1 | 0 |
| 6 | 7 | 8 | 9 | 5 | 10 | 11 | 12 | 13 | 14 | 4 | 3 | 2 | 1 | 0 |
| 6 | 7 | 8 | 9 | 10 | 5 | 11 | 12 | 13 | 14 | 4 | 3 | 2 | 1 | 0 |
| 6 | 7 | 8 | 9 | 10 | 11 | 5 | 12 | 13 | 14 | 4 | 3 | 2 | 1 | 0 |
| 6 | 7 | 8 | 9 | 10 | 11 | 12 | 5 | 13 | 14 | 4 | 3 | 2 | 1 | 0 |
| 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 5 | 14 | 4 | 3 | 2 | 1 | 0 |
| 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 5 | 4 | 3 | 2 | 1 | 0 |
| 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 3 | 2 | 1 | 0 |
| 7 | 6 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 5 | 4 | 3 | 2 | 1 | 0 |
| 7 | 8 | 6 | 9 | 10 | 11 | 12 | 13 | 14 | 5 | 4 | 3 | 2 | 1 | 0 |
| 7 | 8 | 9 | 6 | 10 | 11 | 12 | 13 | 14 | 5 | 4 | 3 | 2 | 1 | 0 |
| 7 | 8 | 9 | 10 | 6 | 11 | 12 | 13 | 14 | 5 | 4 | 3 | 2 | 1 | 0 |
| 7 | 8 | 9 | 10 | 11 | 6 | 12 | 13 | 14 | 5 | 4 | 3 | 2 | 1 | 0 |
| 7 | 8 | 9 | 10 | 11 | 12 | 6 | 13 | 14 | 5 | 4 | 3 | 2 | 1 | 0 |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 | 6 | 14 | 5 | 4 | 3 | 2 | 1 | 0 |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 4 | 3 | 2 | 1 | 0 |
| 8 | 7 | 9 | 10 | 11 | 12 | 13 | 14 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 8 | 9 | 7 | 10 | 11 | 12 | 13 | 14 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 8 | 9 | 10 | 7 | 11 | 12 | 13 | 14 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 8 | 9 | 10 | 11 | 7 | 12 | 13 | 14 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 8 | 9 | 10 | 11 | 12 | 7 | 13 | 14 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 8 | 9 | 10 | 11 | 12 | 13 | 7 | 14 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 | 5 | 4 | 3 | 2 | 1 | 0 |
| 9 | 8 | 10 | 11 | 12 | 13 | 14 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 9 | 10 | 8 | 11 | 12 | 13 | 14 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 9 | 10 | 11 | 8 | 12 | 13 | 14 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 9 | 10 | 11 | 12 | 8 | 13 | 14 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 9 | 10 | 11 | 12 | 13 | 8 | 14 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 9 | 10 | 11 | 12 | 13 | 14 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 9 | 10 | 11 | 12 | 13 | 14 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 10 | 9 | 11 | 12 | 13 | 14 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 10 | 11 | 9 | 12 | 13 | 14 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 10 | 11 | 12 | 9 | 13 | 14 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 10 | 11 | 12 | 13 | 9 | 14 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 10 | 11 | 12 | 13 | 14 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 10 | 11 | 12 | 13 | 14 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 11 | 10 | 12 | 13 | 14 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 11 | 12 | 10 | 13 | 14 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 11 | 12 | 13 | 10 | 14 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 11 | 12 | 13 | 14 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 11 | 12 | 13 | 14 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 12 | 11 | 13 | 14 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 12 | 13 | 11 | 14 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 12 | 13 | 14 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 12 | 13 | 14 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 13 | 12 | 14 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 13 | 14 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 13 | 14 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
表2:マルチスレッドモードでのバブルソート
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 1 | 0 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 1 | 2 | 0 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 2 | 1 | 3 | 0 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 2 | 3 | 1 | 4 | 0 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 3 | 2 | 4 | 1 | 5 | 0 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 3 | 4 | 2 | 5 | 1 | 6 | 0 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 4 | 3 | 5 | 2 | 6 | 1 | 7 | 0 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 4 | 5 | 3 | 6 | 2 | 7 | 1 | 8 | 0 | 9 | 10 | 11 | 12 | 13 | 14 |
| 5 | 4 | 6 | 3 | 7 | 2 | 8 | 1 | 9 | 0 | 10 | 11 | 12 | 13 | 14 |
| 5 | 6 | 4 | 7 | 3 | 8 | 2 | 9 | 1 | 10 | 0 | 11 | 12 | 13 | 14 |
| 6 | 5 | 7 | 4 | 8 | 3 | 9 | 2 | 10 | 1 | 11 | 0 | 12 | 13 | 14 |
| 6 | 7 | 5 | 8 | 4 | 9 | 3 | 10 | 2 | 11 | 1 | 12 | 0 | 13 | 14 |
| 7 | 6 | 8 | 5 | 9 | 4 | 10 | 3 | 11 | 2 | 12 | 1 | 13 | 0 | 14 |
| 7 | 8 | 6 | 9 | 5 | 10 | 4 | 11 | 3 | 12 | 2 | 13 | 1 | 14 | 0 |
| 8 | 7 | 9 | 6 | 10 | 5 | 11 | 4 | 12 | 3 | 13 | 2 | 14 | 1 | 0 |
| 8 | 9 | 7 | 10 | 6 | 11 | 5 | 12 | 4 | 13 | 3 | 14 | 2 | 1 | 0 |
| 9 | 8 | 10 | 7 | 11 | 6 | 12 | 5 | 13 | 4 | 14 | 3 | 2 | 1 | 0 |
| 9 | 10 | 8 | 11 | 7 | 12 | 6 | 13 | 5 | 14 | 4 | 3 | 2 | 1 | 0 |
| 10 | 9 | 11 | 8 | 12 | 7 | 13 | 6 | 14 | 5 | 4 | 3 | 2 | 1 | 0 |
| 10 | 11 | 9 | 12 | 8 | 13 | 7 | 14 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 11 | 10 | 12 | 9 | 13 | 8 | 14 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 11 | 12 | 10 | 13 | 9 | 14 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 12 | 11 | 13 | 10 | 14 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 12 | 13 | 11 | 14 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 13 | 12 | 14 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 13 | 14 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 14 | 13 | 12 | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
コード:
#include <stdio.h> #include <time.h> __global__ void bubbleMove(int *array_device, int N, int step){ int idx = blockDim.x * blockIdx.x + threadIdx.x; if (idx<(N-1)) { if (step-2>=idx){ if (array_device[idx]<array_device[idx+1]){ int buffer = array_device[idx]; array_device[idx]=array_device[idx+1]; array_device[idx+1] = buffer; } } } } void bubleSortCUDA(int *array_host,int N, int blockSize){ int *array_device; cudaMalloc((void **)&array_device, N * sizeof(int)); for (int i = 0; i < N; i++) array_host[i]=i; cudaMemcpy(array_device,array_host,N*sizeof(int),cudaMemcpyHostToDevice); int nblocks = N / blockSize+1; for (int step = 0; step <= N+N; step++) { bubbleMove<<<nblocks,blockSize>>>(array_device,N,step); cudaThreadSynchronize(); } cudaMemcpy(array_host,array_device,N*sizeof(int),cudaMemcpyDeviceToHost); cudaFree(array_device); } void bubleSortCPU(int *array_host, int N){ for (int i = 0; i < N; i++){ for (int j = 0; j < Ni-1; j++) { if (array_host[j]<array_host[j+1]){ int buffer = array_host[j]; array_host[j]=array_host[j+1]; array_host[j+1] = buffer; } } } } int checkArray(int *array_host, int N){ int good=1; for (int i = 0; i < N-1; i++) if (array_host[i]<array_host[i+1]) {good=0; printf("i=%da=%d\n", i,array_host[i] );} return good; } float measureCUDA(int N,int blockSize){ int *array_host = (int *)malloc(N * sizeof(int)); for (int i = 0; i < N; i++) array_host[i]=i; clock_t start = clock(); bubleSortCUDA(array_host,N,blockSize); clock_t end = clock(); if (checkArray(array_host,N)==1){ free(array_host); return (float)(end - start) / CLOCKS_PER_SEC; } else { free(array_host); return -1; } } float measureCPU(int N) { int *array_host = (int *)malloc(N * sizeof(int)); for (int i = 0; i < N; i++) array_host[i]=i; clock_t start = clock(); bubleSortCPU(array_host,N); clock_t end = clock(); if (checkArray(array_host,N)==1){ free(array_host); return (float)(end - start) / CLOCKS_PER_SEC; } else { free(array_host); return -1; } } int main(int argc, char const *argv[]) { for (int i = 1; i < 10000000; i*=2) printf("%d %f\t%f\n",i, measureCUDA(i,256),measureCPU (i )); return 0; }