Intel Atom上のMini-ITXマザーボードをなんとかしてランダムに管理し、すぐに思いついた「静かなホームサーバー!..」(電源はラップトップ+受動冷却を備えたはんだ付けプロセッサに適しています)。 考えた-完了!
ケース、メモリ、1台の2.5 HDD(数か月以内にミラー用に同じものを用意する予定)、およびインターネットをローカルネットワークに配布するための2つ目のネットワークカードを購入しました。今では、ほとんどのサーバーに(当時の)新しいDebian Squeezeがあります。
私はこのサーバーに何が欲しいのか考え始めました、そして私はすべてを少し絞ろうとする人々のカテゴリーから来たので、ウェブ、メール、ジャバーサーバー(白い静的があります)を上げることに決めました「そしてもう少し」急流ロッキングチェアを年中無休で手に入れましょう。
ゲートウェイ上のトレントクライアントである1つのBUTがなければ、すべてがうまくいきます。
ゲートウェイ上のトレントクライアントに向かうトレントトラフィックがインターネットチャネル全体を詰まらせ 、ローカルネットワークデバイスに鼻を残してしまうので、多くの妄想に聞こえます。 しかし、結論に急がないでください。そのようなナンセンスは生命に対する権利を持っています。 さらに、ロッキングチェアが同じサーバー上の他のサービスと平和的に共存し、ローカルネットワーククライアントに干渉しない実用的なソリューションが見つかりました。 しかし、まず最初に...
1.ちょっとした理論
「着信トラフィックをシェーピングすることは意味がありません。なぜなら、 彼はすでに到着しています。つまり、彼はあなたのチャンネルの幅全体に、より高い配信者(プロバイダーなど)から参加しています。」 この声明は真実ですが、部分的には 説明が必要:
TCP / IPのコンテキストで
TCP接続の場合、「
スロースタート 」があります。 これは、ホスト間のパケットが最大速度ですぐに送信を開始しないことを意味します。 代わりに、パケット受信の確認と損失の存在の結果に基づいて、速度(速度)が徐々に増加/減少します。 つまり、パケット送信速度は「変動」し、ホスト間のチャネル帯域幅に調整されます。
この動作を考慮すると、ホスト間のどこかで人為的にtcp接続のパケットの速度を下げることができ、それによりホストに伝送速度を下げる必要性を課すことができます。
しかし、udpパッケージの場合、すべてがやや悲しくなります。 送信側は、パケットの損失または通過時間を考慮せずに単に「スロー」します(UDP-アフリカUDPにもあります:すべての結果を伴う非保証配信...)。 そして、これにはすでに次のような問題があります:udp-trafficがプロバイダーによって保証された帯域全体を使い果たした場合、パケットは単純にドロップし始め、どのようなパケットがインターネットサービスプロバイダーに残されますが、送信側は引き続き送信しますそのようなトラフィックがあります。
悲しい はい、しかし、それほど急ではなく、24/7で動作する自宅の唯一のコンピューターに急流ロッキングチェアを運転するという考えを放棄しました。そのため、急流クライアントは、すぐに配信のすべてのコンテンツをダウンロードしないように要求します私のすべてを1つのスレッドで)。 代わりに、サイズが16キロバイトから4メガバイトまで変化するいくつかのチャンクに対して要求が送信されます。 配布のダウンロードされた部分を遅延させることにより、当社側が他の部分をダウンロードする要求の頻度を減らすことができ、その結果、torrentクライアントが消費するチャネル幅を減らすことができます。
したがって、提供側にパケットの送信速度を強制的に下げることができる場合、プロバイダーによって割り当てられた最大値から消費する幅がより合理的に使用されます。
Linuxルーターを通過するパケットのコンテキストで
GNU / Linuxネットワークスタックを介してパケットを渡すための完全なスキームは次のとおりです。
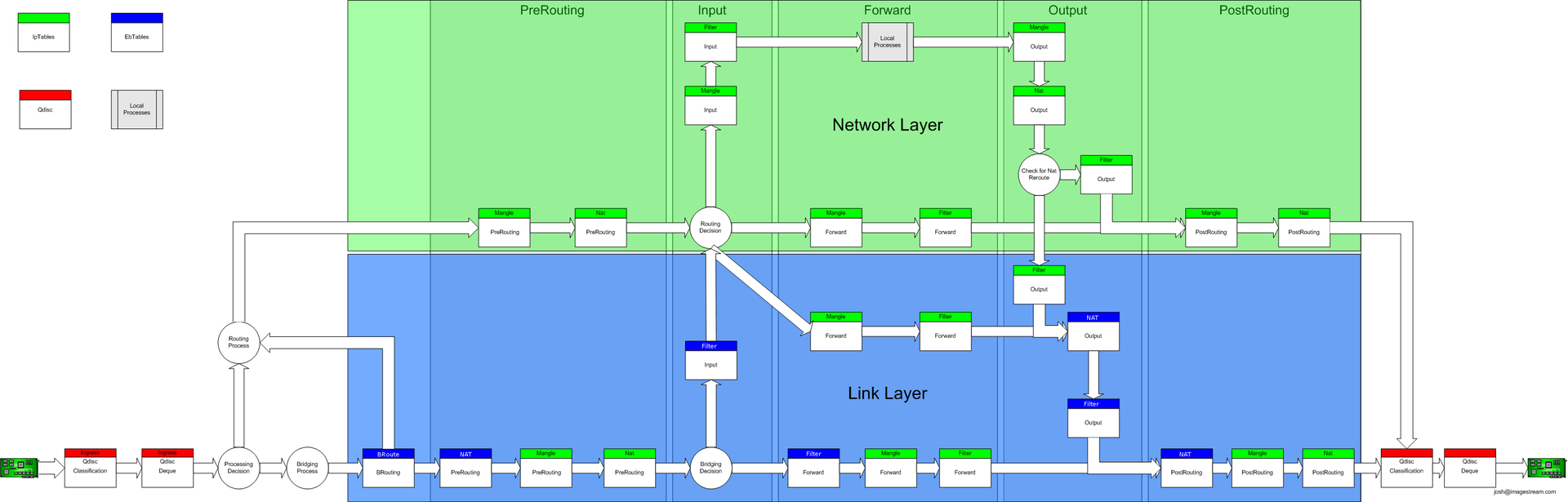
簡単にするために、パケットがインターネットの広大な領域からLinuxルーターの背後にあるデバイスにルーティングされ、このパケットが既にプロバイダーの機器を離れている状況を見てみましょう。 次のポイントはWANインターフェイスです。
強力なIptablesを手に入れる前に、パッケージはイングレスの分野を通過し、すでにこの分野で保証された最大速度を記述するクラスを「ハングアップ」することができますが、このqdiscには2つの重要な制限があります:
- このディシプリンに追加されたクラスには子クラスを含めることはできません。つまり、親からの子クラスによる未使用の幅の借用は失敗します。
- IPに基づいてローカルネットワークに向かうクラスを「分散」する可能性はありません。 まだNATに到達していません。
一般に、イングレスディシプリンは、本格的なダイナミックシェーピングには適していません。
入力後、パケットはIptablesに送信され、そこでフィルタリング/ NAT /ラベリング/ ...が行われます。その後、パケットはLANインターフェイスのegres規律に送信されます。
次の事実に注意を喚起したいと思います。
- Linuxルーター内のパケットのパス全体に1つの入力規則と1つの出力規則のみがあります。ingress-パケットが飛び込むインターフェース上、egress-パケットを解放するインターフェース上。
- ルータに直接宛てられたパケットは、(ifbデバイスでのトリックなしで)出力規則に到達することはありません。
そして今、あなたは着信トラフィックのシェーピングに関するステートメントを再定式化することができます:
GNU / Linuxでは、デバイスの発信インターフェース上で着信トラフィックを正しくシェーピングしますが、このデバイスは個人のニーズのためにトラフィックを消費すべきではありませんが、これは、シェーパーでクラスを形成するときに考慮する必要があります)。2.制限を回避します
すでにわかったように、トラフィックのシェーピングは、出力の分野でより正確です。 ルータを通過するパケットの方向に関して、発信インターフェイス上で。 これは、ルーター自体でトレントクライアントを実行すると、クライアント向けのパッケージが出口規則に決して入らず、それらを「遅延」できないことを意味します。
インターネットをローカルネットワークに配信するルーターで、それで消費されるチャネル幅に厳しい制限なしでトレントクライアントを起動することを実現しました-風水を使わないで、ローカルネットワークに行くかのようにこのトラフィックを形成する方法を考えました、つまり 最初は「与える」インターフェースに送信されますが、最終的にはトレントクライアント自体に送信されるため、これらはすべて同じ鉄の中で発生しますか?
最初は仮想化に目を向け始めましたが、ハードウェアが弱すぎて準仮想マシンを持ち上げることができず、ハードウェア仮想化ではできなかったため、問題は悪化しました。 しかし、Endlessの広がりを長々と歩き回るだけで、すべての記事に適したソリューションが見つかりました
-OpenVZ 。
openvzカーネルをインストールすると、共同ホストの分離に加えて、ホストシステムでvenetインターフェイスを取得し、L3レベルで動作し(L2ではvethデバイスを使用できます)、その前にコンテナーに飛んでいるすべてのipトラフィックがvenetに行きます、つまり 発信インターフェイスを取得します。 医者が注文したもの!
ホストにVZコンテナーを展開し、トレントクライアントと他のサービスをホストに拡散すると、次のようなスキームが得られました。
WAN-世界を覗く物理インターフェイス
VENET-コンテナに向かうすべてのトラフィックが通過する仮想L3インターフェイス(サブネット192.168.254.0/24)
LAN-ローカルネットワークを見る物理インターフェース(サブネット192.168.0.0/24)
トラフィックの
動的シェーピングに参加できる
インターフェイスが
1つだけであることを除いて、ほぼ準備完了です。 この場所で疑問が生じるかもしれないと感じて、私はより詳細に説明しようとします。
私の世界へのチャンネル幅は100 Mb / sであり、絶対に予想通り、次のように利己的な目的ではなく可能な限りそれを使用したかったのです。
- 一定期間、トレントクライアント(BitTorrentコンテナー)によって外部から何かだけがプルされた場合、利用可能な帯域全体を彼に与える必要があります。
- トレントクライアントのダウンロード中に、コンテナのローカルネットワークまたはサブネットから何かがhttpを介してダウンロード/監視を開始する場合、トレントトラフィックは、たとえば32Kb / sにクランプされる必要があり、残りの幅はhttpで指定される必要があります
- 最も重要なのは、LANインターフェースの背後またはVENETインターフェースの背後にあるサブネットに関係なく、すべてのデバイスがチャネル幅全体を使用できることです。
いいですね。 そして、2番目のポイントのhttp-trafficを使用した例が要件のごく一部であることを考慮すると、「急流が実行され、pingが実行され、youtubeが見える」というidilllを達成することで達成できます。
要件のポイント3に関連する問題を回避する方法を考え始めました。なぜなら、他のネットワークネットワークから未使用の幅を借りることができないからです。2つのインターフェイスで動的シェーピングを実現できない場合、すべてのトラフィックcをラップした後、ifbデバイスでシェーピングします出口はLANとVENETを制御します。
3.原因のために!
ボンネットの下を見る前に、私が自分で選んだトラフィック分類の原理についていくつかの言葉で説明したいと思います。
- パケットの優先度を決定するとき、それらは次の役割を果たします。プロトコルとポート番号。
- すべての未分類のトラフィックを最大に「加速」することはできません。 (急流トラフィックの場合)借りた帯域をより高い優先度のクラスに与えることは非常に消極的です。 つまり より重要なパケットを絞るために隙間を残しました。
それでは、始めましょう。
パラメータを決定し、規律をクリアし、ifbデバイスをロードします そして最後のコード:トラフィックを出力分野venet0およびeth1インターフェースからifbデバイスにリダイレクトします 以上です。 私が提示した解決策が誰かを助け、誰かがそれを改善するように私を押し進めると信じたいです。