最近、私たちのプロジェクトでは、コード品質の監視を設定する必要がありました。 コードの品質は主観的な概念ですが、かなり前に、少し定量的な分析を行うことを可能にする多くのメトリックが発明されました。 たとえば、循環的複雑度または保守性インデックス。 これらの種類の指標の測定は、JavaやC ++などの言語では一般的ですが、Pythonコミュニティでは、誰かがそれについて考えることはまれです。 幸いなことに、
キセノンを含むすばらしい
ラドンがあり、上記のメトリックや他のメトリックを迅速かつ
正確に計算します。 もちろん、プロフェッショナルなエンタープライズツールだけでは十分ではありませんが、必要なものはすべて揃っています。
メトリックの計算に加えて、依存関係を分析することも役立ちます。 プロジェクトでアーキテクチャが宣言されている場合、個々のパーツ間に特定のリンクが存在する必要があります。 最も一般的な例:アプリケーションは、APIを提供するライブラリを中心に構築されており、このAPIをバイパスする手段を講じることは非常に望ましくありません。 言い換えれば、libcがあるときにカーネルをioctlするのは良くありません。 Pythonの場合、モジュール間の依存関係グラフを作成するパッケージがいくつかあり、
snakefoodが最も成功したように思えました。
依存関係分析に加えて、特にプロジェクトに「グラインダーで角を切る」ことが好きな後輩や他の人が含まれる場合、コピーアンドペーストを決定することも同様に有用です。 これについては、実際に記事で説明します。
クローン
科学は確かにPythonの商用コピーペースト検出ツールを知っていますが、主な選択基準は無料でした。
cloneiggerにもたらされた検索エンジンの最初のリンク。 この素晴らしいパッケージ
peter_bulychevをありがとう 。
6年前の
記事では、
プレゼンテーションを見ることができます。これにはアルゴリズムの説明が含まれており、それを改めて説明する意味はありません。 適用された観点から最も重要なこと:pip install cloneigger、トリプルサポートなし、3年は更新されていません
、githubにフォークがあります。 さて、大丈夫! 2.7.8では正常に動作しますが、私のプロジェクトはまだ6番目で完全に飽和しています。
Diggerは、実験プロジェクトのルートへのオプションとパスが入力に渡される同じ名前のコンソールユーティリティです。 --cpd-outputを渡すと、
CPDスキームを使用して機械可読XMLを吐き出すことができます。 これにより、JenkinsのViolations Pluginが幸せになります。
非表示のテキスト「メッセンジャーを撃たないで」動作する言語のリストを見ると、不正がすぐに目を引きます。PHPにはあらゆる種類がありますが 、Pythonにはありません! そして、多くのツールで。 したがって、コミュニティに関する記事の冒頭の発言。
また、clonediggerには、「選択したディレクトリをスキャンしない」(--ignore-dir)という優れた機能
があります
。これにより
、テストでgovnokodの分析からサードパーティのコード
を除外でき
ます 。 確かに、それは明確に実装されています:
def walk(dirname): for dirpath, dirs, files in os.walk(file_name): dirs[:] = (not options.ignore_dirs and dirs) or [d for d in dirs if d not in options.ignore_dirs] ...
説明:名前は相対パスから除外されません。 たとえば、「ext」を渡すと、「root / ext」、「root / foo / bar / ext」、および「root / tests / ext」の両方を一度に除外します。これを実現するには時間がかかり、さらにソースに入ります。
そのため、目的のオプションを使用してディガーが完了すると、見つかったクローンとともにXMLが表示されます。 構造は次のようなものです。
<pmd-cpd> <duplication lines="13" tokens="40"> <file line="853" path="tornado/auth.py"/> <file line="735" path="tornado/auth.py"/> <codefragment> <![CDATA[ def _on_friendfeed_request(self, future, response): if response.error: future.set_exception(AuthError( "Error response %s fetching %s" % (response.error, response.request.url))) return future.set_result(escape.json_decode(response.body)) def _oauth_consumer_token(self): self.require_setting("friendfeed_consumer_key", "FriendFeed OAuth") self.require_setting("friendfeed_consumer_secret", "FriendFeed OAuth") return dict( key=self.settings["friendfeed_consumer_key"], secret=self.settings["friendfeed_consumer_secret"]) ]]> </codefragment> </duplication> <duplication> ... </pmd-cpd>
CIのクローンのリストをいつでも取得できるのは素晴らしいことですが、おそらく監視には不十分です。 プロジェクトマネージャーが災害の規模について意見を述べることができるという悪名高い絵はありません。
可視化
プロジェクトモジュールで相互コピーペーストの値を表示する
スクリプトを公開し
ます 。 入力ファイル名は、clonediggerからのXMLと作成されたイメージの2つのファイルです。 依存関係:matplotlib、scipy、xmltodict、cairo。 仕事のアルゴリズム:
- cpdの解析
- モジュール間のクローン値のマトリックスを構築する
- 逆行列(つまり、ファイル間の距離の行列)によるクラスターモジュール
- 見つかったモジュールの順序を元のマトリックスに適用します
- matplotlibで描くのは長く退屈です
解析
with open(sys.argv[1], 'r') as fin: data = xmltodict.parse(fin.read())
解析は基本的に、私のお気に入りのxmltodictによって1行で実行されます。SAXはなく、xmlの知識もありません。XDocumentよりも簡単です。 xmltodictが同じレベルで複数の同一のタグを検出した場合、配列を作成し、名前の先頭にあるネストされた「@」要素と属性が異なります。 もちろん、これは最速の方法ではなく、最も一般的な方法ではありませんが、この場合は100%動作します。
クローンマトリックス
次に、一意のパスのリストを取得し、インデックスを作成します。
files = list(sorted(set.union({dup['file'][i]['@path'] for dup in data['pmd-cpd']['duplication'] for i in (0, 1)}))) findex = {f: i for i, f in enumerate(files)}
解析されたツリーを実行して、三角形の行列を構築します。そのセルは、見つかったクローンの合計行数です。
mat = numpy.zeros((len(files), len(files))) for dup in data['pmd-cpd']['duplication']: mat[tuple(findex[dup['file'][i]['@path']] for i in (0, 1))] += \ int(dup['@lines'])
三角行列に同じものを追加しますが、転置して、本格的な行列を作成します。
mat += mat.transpose()
クラスタリング
マトリックスをすぐに描画すると、どのファイルグループが相互にコピーするかが明確になりません。 シングルペアの場合、すべてが明確になりますが、クローンには、たとえば、低品質のリファクタリングのために、一度に多くのモジュールに自分自身をドラッグする下劣な能力があります。 したがって、最初にファイル間の類似性によってファイルをグループ化し、正方形のペアになっていない領域を形成することをお勧めします。 厳密に言えば、モジュールAがモジュールBに類似し、BがCに類似している場合、これはAがCに類似していることを意味するものではありません(関係は推移的ではありません)。
ゼロで割ることが不可能であることを忘れずに、距離行列をクローニング行列の逆行列として構築し、次にクラスタリングします。
mat[mat == 0] = 0.001 order = leaves_list(linkage(1 / mat))
だから私はscipyが大好きです! 1行ですが、どれだけ内部にありますか! ところで、リンケージの代わりに、
利用可能な別の方法を試すことができ
ます 。 そうそう、クラスタリングは階層的でなければなりません(たとえば、
この記事をご覧ください)。 ファイルを整理します(leaves_list関数)。 自分で再生したい場合は、樹形図を使用して結果の階層を表示すると便利です。
見つかった順序をファイル名とマトリックスに適用します。
mat = mat[numpy.ix_(order, order)] files = [files[i] for i in order]
芸術
私は科学的な視覚化の専門家ではなく、古き良き
スタックオーバーフロー駆動開発を使用してひざの上でコードを収集しました。 まず、赤と白のグラデーションでパレットを選択します。
cdict = {'red': ((0.0, 1.0, 1.0), (1.0, 1.0, 1.0)), 'green': ((0.0, 1.0, 1.0), (1.0, 0.0, 0.0)), 'blue': ((0.0, 1.0, 1.0), (1.0, 0.0, 0.0))} reds = LinearSegmentedColormap('Reds', cdict)
matplotlib.cmコレクションから他のものを選択できます。 次に、シェイプと軸を作成し、ファイルで長時間磨きます:
fig = pyplot.figure() ax = fig.add_subplot(111) ax.pcolor(mat, cmap=reds)
ご覧のとおり、ファイル名はパスなしで基本的なものになっています。 そうしないと、分岐プロジェクトの場合、描画領域に収まりません。 OK、残りはほとんどありません:適切なサイズを設定し、実際にレンダリングします:
fig_size = 16 * len(files) / 55 fig.set_size_inches(fig_size, fig_size) pyplot.savefig(sys.argv[2], bbox_inches='tight', transparent=False, dpi=100, pad_inches=0.1)
ファイル名がくっつかないように、サイズは目で選択されます。 ファイル形式は拡張子によって自動的に決定されます。少なくともcairoはpngとsvgをサポートしています。
テスト中
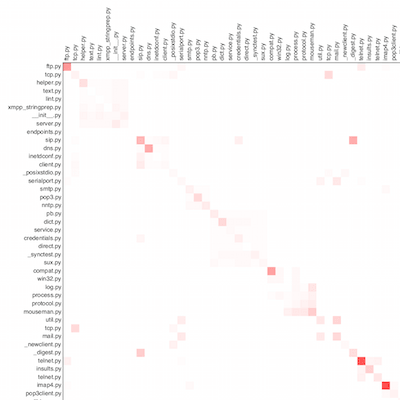
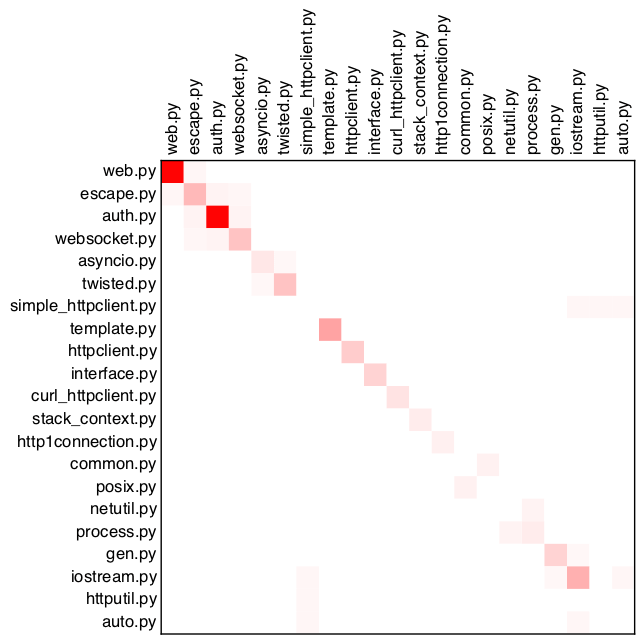
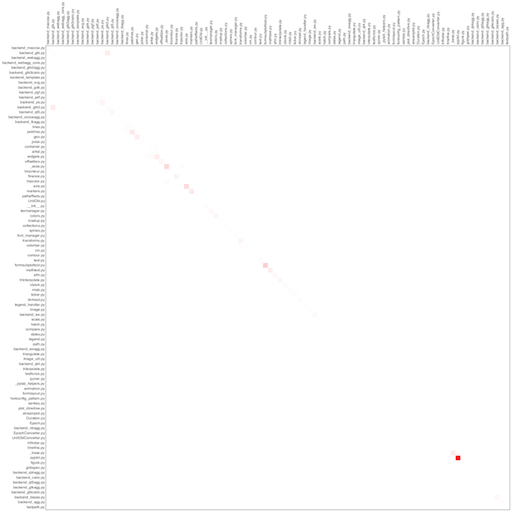
デモンストレーションのために、tornado、matplotlib、およびtwistedの3つのオープンソースプロジェクトを取りました。 テストは分析から除外されました。 ちなみに、KDPVはツイストの左上隅です。
竜巻
matplotlib
ねじれた
ご覧のとおり、すべてのプロジェクトはメインの対角線、つまり ほとんどの場合、ファイルは自分自身をコピーします。 おそらくこれは言語の機能によるものであり、おそらくマクロの欠如によるものです。 それにもかかわらず、明るい赤い点は細心の注意に値し、リファクタリングの候補です-私たち自身のプロジェクトによって証明されました。
ご意見をお寄せいただきありがとうございます。