良い一日。
そのような問題に直面しました。 1C 8.2には処理があり、自動モードで大量のデータを詰め込む必要があります。 データのヒープはデータベース、アーキテクチャにあり、データベースを1Cに接続したり、テーブルを再フォーマットしたりすることはできませんでした。 唯一の方法は、仮想プリンタでテーブルを印刷することであるように思われ、そこからダンスを始めました。
したがって、* .xps形式のドキュメントがあります。これは、思いやりのある仮想プリンターによって提供されました。
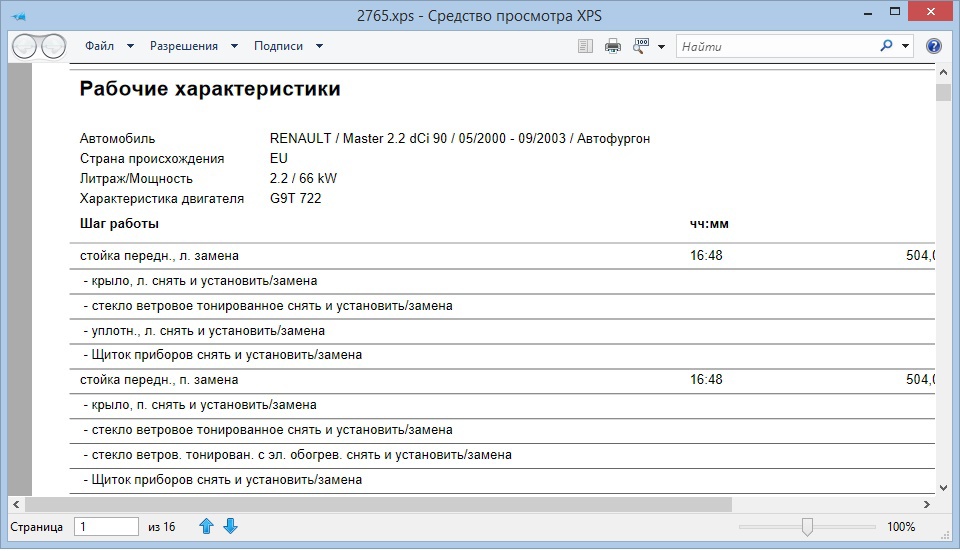
実際、これらすべてから、作品自体の行、パートタイムの仕事の行(「-」記号で始まる)、および各作品の時間規範の列だけが必要です。 最初は、XPS形式はグラフィックだと思っていたので、結果のファイルを任意のOCRプログラムに格納し、そこでテーブルを認識して、Excel形式でデータを保存する必要がありました。 最初はそうでしたが、大きな欠点があります:
-XPSを変換するときのプロセスの自動化はありません-> 1C。
-OCRプログラムはテキスト認識を台無しにする可能性があります。
-変換プロセスには時間がかかります。
そのため、XPS形式を直接扱う必要がありました。
実際のところ、XPS形式は通常のZIPファイルです。 そこにあるすべての情報はXML形式です。 写真は、写真、テキストテキストです。 しかし、テキストが必要です...
内部には次の写真があります。
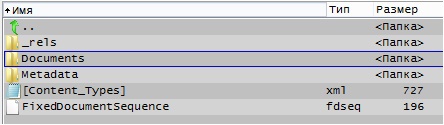
各フォルダの詳細と内容については説明しません。すべてがそこにあるので、興味があれば自分で登ることができます。 私は特に1つのファイルのみに興味があります。
.. \ Documents \ 1 \ FixedDocument.fdoc
このファイルのリストは次のとおりです。
<?xml version="1.0" encoding="UTF-8" ?> - <FixedDocument xmlns="http://schemas.microsoft.com/xps/2005/06"> <PageContent Source="/Documents/1/Pages/1.fpage" /> <PageContent Source="/Documents/1/Pages/2.fpage" /> <PageContent Source="/Documents/1/Pages/3.fpage" /> <PageContent Source="/Documents/1/Pages/4.fpage" /> </FixedDocument>
ご覧のとおり、ドキュメントのページファイルへのパスは次のとおりです。
すべて1Cコードで作成します。
() = .; = (); . = ; . = "XPS |*.xps"; .() = ..(); = 0 - 1 (.[], .); (); ; ;
最初に、ファイルの内容を一時フォルダーに解凍します。
(, ) = (, , ""); = (, ".xps", ""); ( + ); = Zip(); .( + , ZIP.); .();
これで、ファイルディレクトリにすべての作業の可能性があります。 上記のように、ページを含むファイルのリストに興味があります。 リストをテーブルにリロードします。 通常のXMLと同様に、このファイルを使用します。
= XML; .( + + "\Documents\1\FixedDocument.fdoc"); .(); .(); .() .(); (.) ..(); ... = .; ; ; .();
それだけです。ファイルのリストがあります。 次に、ファイル自体に進みます。 ページファイル自体はテキストですが、スペルルールはXMLではありません。 構造はブロックです。 ブロックは、テキスト情報とグラフィック情報を別々に書き込みます。 すべてのブロックには、ページ上の位置を示すX軸とY軸の座標があります。 テキストブロックとその座標、およびその情報にのみ興味があります。
ブロックには開始点と終了点があり、開始点と終了点がどこにあるのかを理解するために:</>
各ブロックでは、最初の単語はその名前です。 テキストブロックには名前があります:グリフ
ブロックの例を次に示します。
<Glyphs Fill="#ff000000" FontUri="/Documents/1/Resources/Fonts/DD1ED91D-300C-4E84-BACC-6412D0EB3F5F.odttf" FontRenderingEmSize="13.2795" StyleSimulations="None" OriginX="971.84" OriginY="59.68" Indices="19,55;26;17;19;21,55;17;21;19;20,55;24" UnicodeString="07.02.2015" />
私はここのオプションにのみ興味があります:
-列を定義するためのOriginX。
-文字列に含まれるものの値自体としてのUnicodeString。
通常のテキストファイルとして読む必要があります。 テキストブロックはすべて1行で書き込まれます。 1Cでは、翻訳文字までの行を読むことができます:
= (, .UTF8); = .(); <> = (); ...
そして、パラメータの結果の文字列をチェックし、それがGlyphsで始まる場合は、検証と分析のために取得し、そうでない場合は、次のものを読み取ります。
文字列を文字ごとに分析し、構造に書き換える必要があります。
() , ; = ""; = ""; = """"; = ; (, "UnicodeString") > 0 = (, "UnicodeString") + 15 () = (, , 1); <> """" = + ; .("", ); ; ; = (, "OriginX") + 9 () = (, , 1); <> = + ; .("", ()); ; ; ; ; ;
実際、この機能を実行することにより、分析のためのすべてが揃っています。 パラメーターの名前、その座標、パラメーターの値。 ブロックは、XPSで上から下、左から右にテキストを表示します。 列は、X座標、パラメーターの名前、必要な情報と必要でない情報を分析することで決定できます。 さらに、どのようにすべてが1Cディレクトリに入ったかについては説明しません。 最も重要なことは、「グラフィック」ファイルから必要な情報をすばやく抽出する方法についての回答を得たことです。