
しばらく前、私は知識を更新し、グラフについて何かを読むことにしました。 「もちろん、Habréには良い記事があるはずです!」と思い、私は正しかった。 記事があり、それらの多くがあります。 しかし、それらはほとんど次のように見えます:
one 、
two 、
three 。 完全に理解可能な言語で書かれているにもかかわらず、これらの記事から何かを理解することが完全に不可能である理由を1回試してみてください。 写真なし! しかし、写真なしでグラフを調べる方法は? まさか。
Habrの新参者は、「どうして-写真がないの? habrastorage.orgがあります!」 はい、あります。 しかし、彼はいつもそこにいるとは限らず、自動的に写真が彼に注がれ
、2013年7月に始まり
ました 。 それ以前は、写真はどこでもホストされていました-あらゆる種類の過激派、画像ハック、さらにはドロップボックスでも、人々は素朴に何かを広めようとしました。 その結果、Habréには2006年から2013年までの写真のない記事がたくさんあります。
それを修正しましょう!
計画
最初に直面するタスクは次のとおりです。
- Habrの登場から前述の投稿188436にすべての記事をダウンロードします。これは、habrastorage.orgでの写真の強制的な再アップロードの開始をおおまかに示しています。
- 記事のテキストで、Habré、Giktayms、Megamind、Habrastorajにないすべての写真へのリンクを検索します
- これらのイメージの可用性を確認します(GETは必要ありません。戻りコードとコンテンツのタイプを確認するHEADリクエストで十分です)
- アクセスできない写真のリストをファイルにエクスポートする
実装
一般的に、レイジーのみがHabrをまだ解析していませんが、レイジーではありません。 特にPython +リクエストには次のように書かれているため:
クラウド内の仮想マシンにコードをアップロードし、開始して、2日以内に戻ります(もちろん、それを複数のスレッドに解析できました-よくある質問のどこかで、Habrは毎秒2回以上ボットでプルしないように頼みました)。
結果
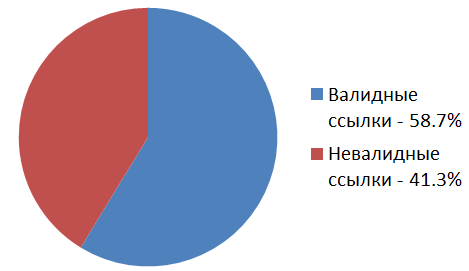
合計で、「ハブラストラーの到来前」の記事では、
157601個の画像が「左」の画像ホスティング
サイトに投稿されました。 これらのうち、
92549リンクはまだ有効であり、
65052リンクは存在しません。
わかりました、Habréの記事には65052のアクセスできないイメージへのリンクがあります。 それをどうしますか? もちろん、それらを
archive.orgキャッシュから取得します! 彼はそのために考えられました!
Webアーカイブ内の画像の可用性は、簡単なリクエストで確認できます。
http://archive.org/wayback/available?url=%image_url%
たとえば、記事
habrahabr.ru/post/63982にない画像
img513.imageshack.us/img513/3580/pic1e.jpgへのリンクは、
http://web.archive.org/web/20131103061340/http://からアクセスでき
ます。 img513.imageshack.us/img513/3580/pic1e.jpgただし、1つの不幸があります。 オンラインアーカイブは、キャッシュされた画像へのリンクがあると主張することがありますが、実際にはありません。 一般的に嘘。 つまり キャッシュされた画像へのすべてのリンクを確認する必要があります。 まあ、何も
チェックしないで
ください 。
いっぱい、走って、半日待ちます。
結果
Habréの記事の元のリンクで使用できなくなった
写真の13863枚は、Webアーカイブで使用できました。
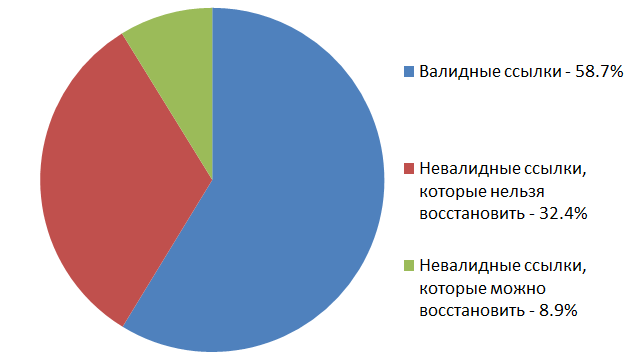
この実験全体により、「病院内の平均気温」は良好でした。ランダムホスティング用にアップロードされた写真は、今後2〜9年で約58%生き残る可能性があります。 また、
archive.orgは有用なものであり、時には役立つこともわかっていますが、Habréの画像への壊れたリンクを復元する可能性は21.3%です。
記事の最初の部分の結論
したがって、今では画像への
有効なリンクがまだある
配列と 、壊れたリンクとWebアーカイブ内の利用可能な画像への対応するリンクがある
2番目の配列があります。 この時点で、Habr管理者にこのデータを取得し、4行のコードを記述してhabrastorage.orgにすべてリロードし、既存の記事のリンクを更新するように依頼できますが、それを行うかどうかはわかりません。 そして、私は通常の形で記事を読みたいです! そして、私たちは私たち自身の道を行きます。 もちろん、「Webアーカイブから直接記事を読む!」と言うこともできますが、これはどういうわけかあまり有益ではなく、このデータ収集はすべてどうなるでしょう。
2番目の衝動は、Chromeの拡張機能を作成し、悪いリンクを良いリンクに置き換えたいという願望かもしれませんが、いくつかの理由でこれを行いたくありません。
- Habréには、Chromeの拡張機能の作成に関する記事が既に100件ありました。
- 拡張機能は現在、市場に必ず配置されているようです
- Firefoxは別の拡張機能を作成する必要がありますが、IEでは何をすべきか明確ではありません(BHOを作成しますか?Brrrrr!)。 それに加えて、あらゆる種類のOpera、Vivaldi、Safari、Yandex.browsers、およびその他の動物園。
- これが携帯電話やタブレットからの読み取りにどのように役立つかは完全に理解できません。
したがって、私たちは他の方法で、上記のすべての問題を解決する何かを書きます。 いったい何? そして、あなたは
次の記事からこれについて学びます。
PS 2番目の記事で使用した方法はHabréの写真とは関係がないため、2つの記事へ
の論理的な分離が読みやすさのために追加されました。
UPD。 コメントで正しくプロンプトが表示されているように-チェックしてリダイレクトする必要があります。 スクリプトは修正され(
百科事典のおかげで)、再度実行されます。 その結果、画像への別の有効な10,683のリンクが受信されました。 新しいデータを含むファイルはGitHubにアップロードされます(記事のリンクを参照)。