Webサイトの高可用性-ホスティングプロバイダーとサイト開発者間のコラボレーション。 高可用性の主な目標は、計画的および計画外のダウンタイムを最小限に抑えることです。
高可用性は、プロジェクトを安全なクラウドに配置するだけではありません。 本当にアクセスしやすいサイトは複数のクラウドリージョンで動作するはずであり、クラウドリージョンの1つがアクセス不能になったとしても、ユーザーは変更に気付かないはずです。 Webサイト開発者は、緊急時にもWebサイトが動作することを確認する必要があります。 高可用性システムは複製されます。プロバイダーに障害が発生した場合、サイトは利用可能になります。 ユーザーのレプリケーションが失敗した場合、サイトにもアクセスできる必要があります。 サーバー上で開発者に対して作業を実行するか再起動する必要がある場合、ユーザーはこれに気付かないでください。

このシリーズの記事では、サイトのさまざまなサブシステムの高可用性を編成する方法を検討します。 多くのタスクには異なる解決策があります。 著者は、最良のソリューションがここに提示されているとは主張していませんが、実際に機能的でテスト済みです。 しかし、アクセシビリティ実験の分野は広大です。
今日は、クラウドのリージョン間での静的サイトの同期を検討します。一方のサーバー上のファイルの変更は、他方のサーバーにも反映されるはずです。 また、この場合に適用可能ないくつかのDNS Aレコードを使用して、サイトのユーザーを代替サーバーにリダイレクトする最も簡単な方法も検討します。
Lsyncd
Lsyncd (Live Syncing Daemon)は、高可用性クラスターで使用するサーバーデータのタイムリーなインタラクティブミラーリングのためのアプリケーションです。 Lsyncdは、同期トラフィックの少ないシステムに特に適しています。 アプリケーションは、構成で定義された期間、Linux
inotifyカーネルサブシステムを介してデータ変更に関する情報を収集し、変更のミラーリングを開始します(デフォルトではrsyncを使用しますが、他のオプションがあります)。 デフォルトでは、lsyncdはバックグラウンドでデーモンとして起動し、
syslogを使用してアクションを記録します。 テストの目的で、デモンストレーションなしでアプリケーションを実行して、デバッグのために端末で何が起こっているかを確認できます。
Lsyncdは、個別のファイルシステムまたはブロックデバイスを使用せず、ローカルファイルシステムのパフォーマンスに大きな影響を与えません。
Rsync + SSHオプションを使用すると、場所をリモートサーバーに転送する代わりに、ファイルを宛先ディレクトリに直接転送できます。
Webサーバーファイルのジオレプリケーションのインストールと構成
InfoboxCloudのさまざまな地域にアクセスする
モスクワとアムステルダムで2つのInfoboxCloudサブスクリプションを注文して、地理的に分散したソリューションを作成します。
サブスクリプションを単一のユーザーアカウントに関連付けるには、次の手順を実行する必要があります。
1.
http://infoboxcloud.ruにアクセスし、任意の地域(たとえば、アムステルダム)で
クラウドインフラストラクチャを
注文します。 次に、
コントロールパネルに移動して
、以下に示すように、別の地域(モスクワなど)でクラウドを注文します。

注文後、コントロールパネルを終了して、再度ログインします。 これで、コントロールパネルの右上隅で作業が行われる地域を選択できます。
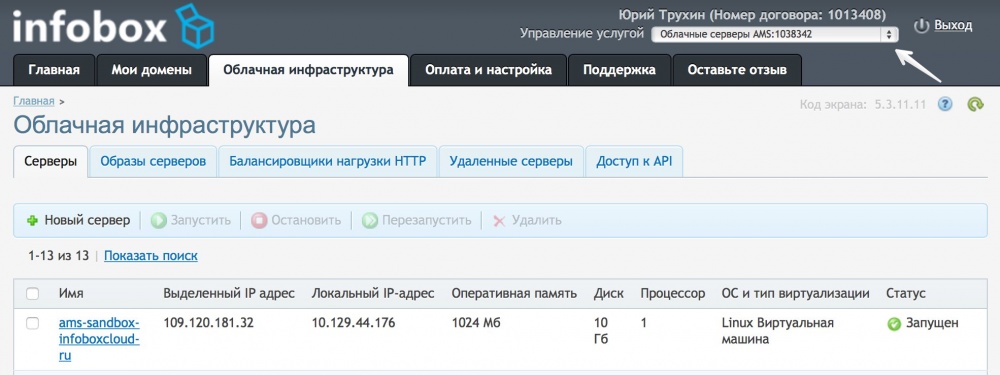
2つのサーバーを作成します。1つはモスクワに、もう1つはアムステルダムにあります。

オペレーティングシステムとして、CentOS 7を選択します。この記事では説明していますが、必要に応じて別のLinuxオペレーティングシステムを使用できます。 ただし、設定は異なる場合があります。 任意の
タイプの仮想化を使用して選択できます。 特定のシナリオの違いは、「OSカーネル管理を有効にする」をチェック
しない場合、サーバーのメモリ自動スケーリングを使用できるため、リソースをより効率的に使用できることです。 そして、それを
置くと 、inotifyカーネルサブシステムを構成できます。これは、高負荷で役立ちます(
構成例 )が、通常の小規模サイトでは意味がありません。 各サーバーを作成するときは、外部ネットワークからサーバーにアクセスできるように、必ずパブリックIPアドレスを1つ追加してください。

サーバーを作成すると、アクセスデータがメールで送信されます。
DNSセットアップ
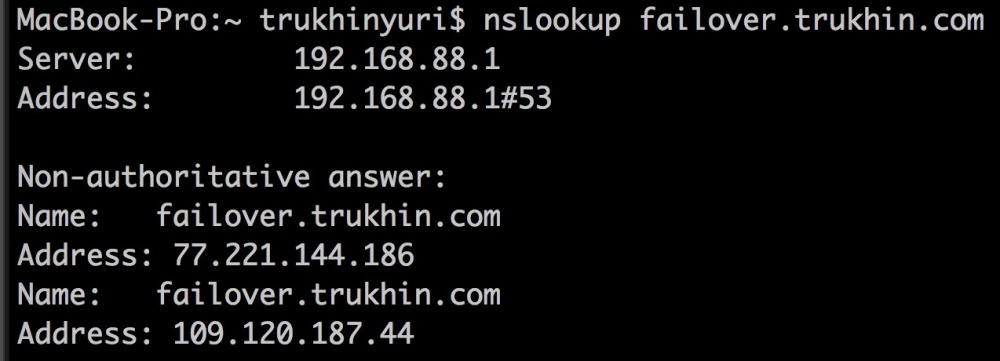
サイトにアクセスしやすいメインドメインの場合、モスクワのサーバーとアムステルダムのサーバーを指す
2つの DNS Aレコードを作成します。 この場合、サイトは
failover.trukhin.comになり
ます 。
Aレコードがサーバーを指す必要があるサービスサブドメインを作成します。 たとえば、
failovermsk.trukhin.comは
モスクワのサーバーを指し、
failoverams.trukhin.comは
アムステルダムのサーバーを指します。 サーバーに障害が発生した場合にバックアップサーバーから別のレプリカを展開し、サブドメインをそこにリダイレクトするために、サーバーごとに個別のサブドメインが必要です。
サーバー構成
両方のサーバーで次の手順を実行する必要があります。SSHを介して両方のサーバーに接続します。 各サーバーにApacheをインストールし、起動して自動ロードに追加します。
yum -y update && yum install -y httpd && systemctl start httpd.service && systemctl enable httpd.service
各サーバーの/ var / www / htmlディレクトリに
index.htmlファイルを作成し、各サーバーのブラウザーでページが正しく開くことを確認します。
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> Hi </title> </head> <body> Hello, World! </body> </html>
lsyncdが機能するには、各サーバーへのアクセスが相互にキーで許可されている必要があります。
SSHキーを生成します(質問の場合は単にEnterを押します):
ssh-keygen
モスクワのサーバーから、アムステルダムのサーバーにキーを追加します。
ssh-copy-id root@failoverams.trukhin.com
アムステルダムのサーバーから、モスクワのサーバーにキーを追加します。
ssh-copy-id root@failovermsk.trukhin.com
次に、モスクワのサーバー(root@failovermsk.trukhin.com)からアムステルダムのサーバー(root@failoverams.trukhin.com)に接続します。 パスワードを要求しないでください。 接続するときは、yesと答えます。
lsyncdをインストールして構成する
両方のサーバーで次の手順を実行する必要があります。CentOS 7に
lsyncdをインストールするには、次のコマンドでEPELリポジトリを追加します。
rpm -ivh http://mirror.yandex.ru/epel/7/x86_64/e/epel-release-7-5.noarch.rpm
次に、lsyncdをインストールします。
yum install lsyncd
ログと一時的なlsyncdファイルを保存するディレクトリを作成します。
mkdir -p /var/log/lsyncd && mkdir -p /var/www/temp
/etc/lsyncd.confにlsyncd設定ファイルを作成します
settings { logfile = "/var/log/lsyncd/lsyncd.log", statusFile = "/var/log/lsyncd/lsyncd.status", nodaemon = false } sync { default.rsyncssh, source="/var/www/html", host="failovermsk.trukhin.com", targetdir="/var/www/html", rsync = { archive=true, compress=true, temp_dir="/var/www/temp", update=true, links=true, times=true, protect_args=true }, delay=3, ssh = { port = 22 } }
ホスト:
failovermsk.trukhin.comを、別の地域のサーバーのみに向けられたサブドメインに置き換えます。
ソースは、現在のサーバー上のフォルダーを示します。
targetdirは、リモートサーバー上のフォルダーを指定します。
遅延パラメーターは、サーバー上の変更の同期が実行される期間です。 この値は実験的に選択され、デフォルト値は10です。すべてのlsyncdパラメーターは
公式ドキュメントに記載されてい
ます 。
デバッグするには、パラメーター
nodaemon = trueを設定し、変更を保存します。
サーバーの1つにファイル
を作成
します 。
touch /var/www/test
lsyncdを手動で実行して、すべてが正しく同期されていることを確認します。
lsyncd /etc/lsyncd.conf

すべてがうまくいけば-/ var / www / htmlフォルダー内の別の地域のサーバーで、作成されたテストファイルが表示されます。

ここで
/etc/lsyncd.confにnodaemon = falseを返します。 lsyncdをスタートアップに追加し、サービスを開始します。
systemctl start lsyncd.service systemctl enable lsyncd.service
再起動後にデータが複製されることを確認してください。
双方向レプリケーション
レプリケーションを反対方向で機能させるには、別のリージョンのサーバーで同じ設定を行いますが、lsyncd構成ファイルで最初のサーバーのアドレスを指定します。 データが逆方向に複製されていることを確認します。 lsyncd構成では、双方向の同期に必要な一時ディレクトリ
temp_dirが既に指定されています。
mysqlではマスターとマスターのレプリケーションを使用することは推奨されておらず、そのようなデータベースを使用しているときに最初のサーバーで障害が発生した場合、2番目の作業サーバーから3番目のサーバーへのレプリケーションを構成する
必要があるため 、
2方向のレプリケーションは必ずしも必要ではありません。 これは、クラウド用のバックアップサーバーテンプレートを事前に準備する場合にのみ行われます。これについては、後続の記事で説明します。 現在、ファイルのみを使用しており、静的サイトでは双方向のレプリケーションが非常に適切です。
サイトの可用性を確認する
私たちのウェブサイトに行きましょう:

両方のサーバーが利用可能です。
次に、モスクワのサーバーの電源を切ります。

私たちのサイトが利用可能です:

モスクワでサーバーをオンにし、アムステルダムでオフにします。

私たちのサイトが利用可能です:

なぜ機能するのですか?
いくつかのAレコードが存在する場合、最新のブラウザは最初に1つのIPアドレスにアクセスしようとし、使用できない場合は別のIPアドレスにアクセスしようとします。 したがって、少なくとも1つのサーバーが使用可能な場合、サイトは機能します。
より複雑な形式のこのアプローチは、大規模なサイトで長い間使用されており、多くのバックアップサーバーがそれらのために作成されています。 たとえば、Googleには11個あります。

おわりに
この記事では、データベースなしで静的サイトのジオレプリケーションを構成する方法について説明しました。 後続の記事では、データベースを複製し、より複雑なサイトに高可用性を提供する方法について説明します。
記事に間違いを見つけた場合、著者は喜んで修正します。 PMに連絡するか、それについて
電子メールを送信してください。 Habréにコメントを残せない場合は、
InfoboxCloudコミュニティでコメントを書いてください。
成功しました!