こんにちは、Habr!
いくつかの歌詞今日、2015年3月21日、私は戦いの半分を行うことにしましたが、OOMの処理方法を理解し始め、一般的にヒープダンプを選択する方法を学ぶ方法についての記事を書き始めました(私はそれらを単なるダンプと呼びます。スピーチを簡単にするために、可能な限り英国主義を避けようとします)。
この記事を書く予定だった「仕事」の量は1日ではないように思えるので、その記事はその数週間後に表示されるはずです。
この記事では、Javaでのダンプの処理方法、OOMの発生理由を理解する方法、またはOOMの発生理由に近づける方法、ダンプを分析するツール、ヒップを監視するツール(1つ、はい)、一般的な開発のためにこの問題を掘り下げてみます。 JVisualVM(そのためのプラグインとOQLコンソールを検討します)、Eclipse Memory Analyzing Toolなどのツールを研究しています。
彼はたくさん書いたが、私はすべてがビジネス上にあることを願っています:)
背景
最初に、OOMの発生方法を理解する必要があります。 これは誰にも知られていません。
アプリケーションの占有RAMには上限があると想像してください。 ギガバイトのRAMにします。
スレッドのいずれかでOOMが発生するということは、この特定のスレッドがすべての空きメモリを「消去」することを意味するものではなく、OOMに至ったコードそのものがこれを責めることを意味するものでもありません。
いくつかのスレッドが何かに従事し、メモリを消費し、「もう少しして、私は破裂します」状態に「それを取得」し、実行を完了して一時停止したときの状況は非常に正常です。 そしてこの時点で、他のスレッドが小さな作業のためにメモリをさらに要求することを決定しました。もちろん、ガベージコレクタは膨らみましたが、メモリ内のガベージは見つかりませんでした。 この場合、OOMは、スタックトレースがアプリケーションクラッシュの間違った犯人を示しているときに、問題の原因に関係しないだけで発生します。
別のオプションがあります。 約1週間、2つのアプリケーションの動作を改善して、不安定な動作を止める方法を模索してきました。 そして、私はそれらを整理するのに1、2週間を費やしました。 私はこれらの問題に対処しただけではなかったので、合計で、数週間の期間が1ヶ月半続きました。
見つかったものから:サードパーティのライブラリ、そしてもちろん、ストアドプロシージャコールに含まれていないものもあります。
1つのアプリケーションでは、症状は次のとおりでした。サービスの負荷に応じて、1日または2日で落ちます。 メモリの状態を監視すると、アプリケーションが徐々に「サイズ」を増やしていき、ある時点で単純に横たわっていることが明らかになりました。
別のアプリケーションでは、もう少し面白いです。 長い間うまく動作するか、リブートしてから10分後に応答が停止するか、突然落ちて空きメモリがすべてゴブリングする可能性があります(これを見ると既にわかります)。 そして、バージョンを更新した後、Tomcatのバージョンが7から8に変更され、JREの場合、金曜日の1つ(2週間以上前に正常に機能していた)が突然、それを認めるのは恥ずべきことを始めました。 :)
ダンプは両方のストーリーで非常に有用であることが判明しました。おかげで、JVisualVM(JVVMと呼びます)、Eclipse Memory Analyzing Tool(MAT)、OQL(正しく調理する方法がわからないかもしれません) MATですが、JVVMでのOQL実装と友達になりやすくなりました。
ダンプをダウンロードするには、空きRAMも必要です。 そのボリュームは、開かれているダンプのサイズに見合ったものでなければなりません。
開始する
だから、私はゆっくりとカードを明らかにし始め、私はJVVMから始めます。
このツールとjstatdおよびjmxを使用すると、サーバー上のアプリケーションの寿命をリモートで監視できます。ヒープ、プロセッサ、PermGen、スレッドとクラスの数、スレッドアクティビティ、プロファイリングが可能です。
JVVMも拡張可能であり、MBeanの監視と対話、ヒープの詳細の監視、アプリケーションの長期監視の実施、頭の中での保持など、より多くのものを許可するプラグインをインストールすることで、この機会を活用しました監視タブ時間で提供されるよりもメトリック期間。
これは、インストールされたプラグインのセットのようです。
Visual GC(VGC)を使用すると、ヒップ関連のメトリックを表示できます。
この私たちのJavaの構成要素の詳細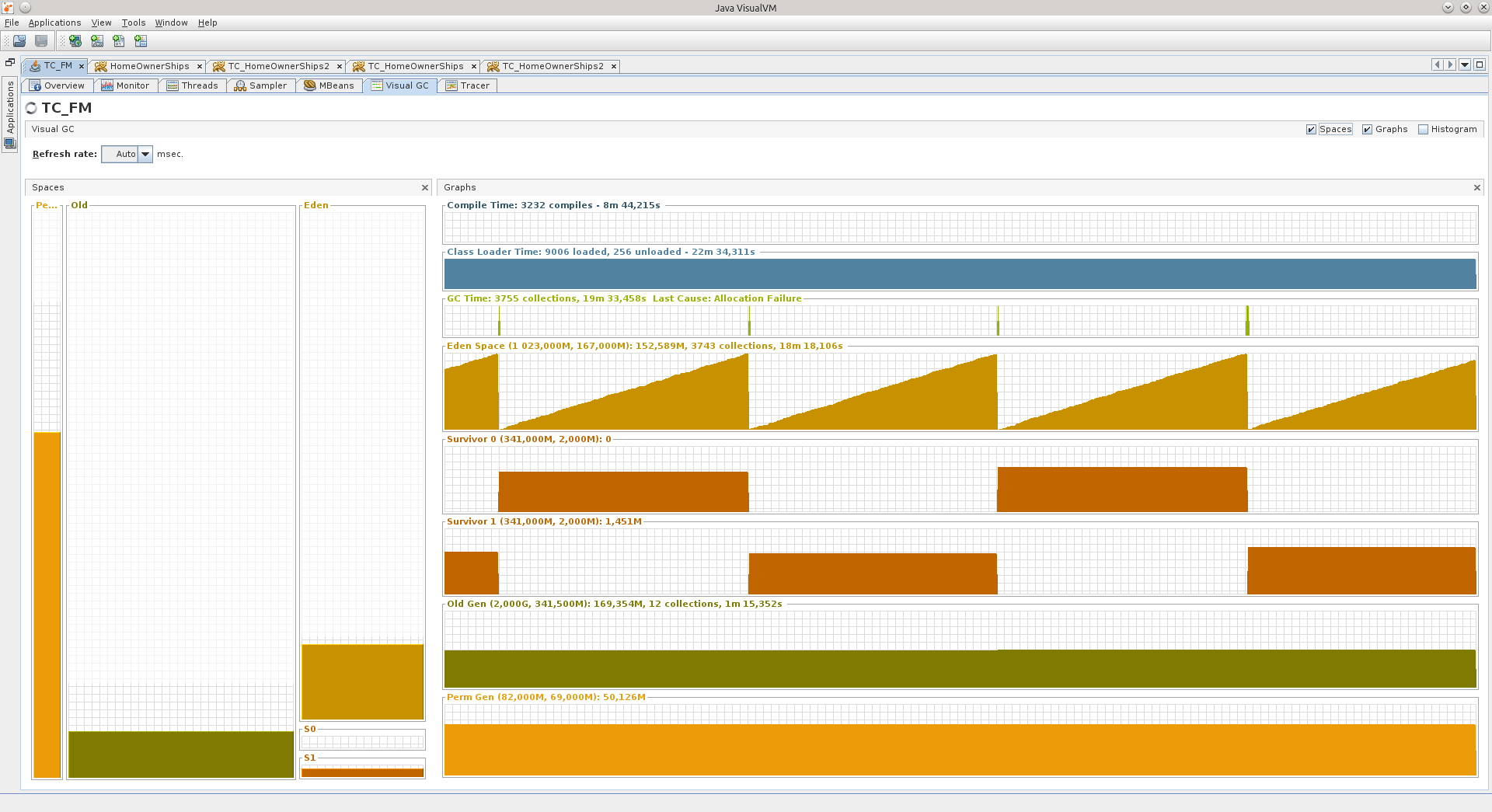
2つの異なるアプリケーションの動作を示すVGCタブの2つのスクリーンショットを次に示します。
左側には、Perm Gen、Old Gen、Survivor 0、Survivor 1、Eden Spaceなどのヒップセクションがあります。
これらのコンポーネントはすべて、オブジェクトが追加されるRAMの領域です。
PermGen-Permanent Generationは、Javaクラスの説明といくつかの追加データを格納するために設計されたJVMのメモリ領域です。
Old Genは、Survivorエリアの場所から場所へのいくつかのシフトを生き残ったかなり古いオブジェクトのメモリエリアであり、別の輸血の時点で、「古い」オブジェクトのエリアに分類されます。
サバイバー0と1は、Eden Spaceでオブジェクトを作成した後、そのクリーニングを生き残った、つまり、Eden Spaceがガベージコレクター(GC)によってクリーニングされた時点でゴミにならなかったオブジェクトを含む領域です。 Eden Spaceのクリーニングを開始するたびに、現在アクティブなSurvivorのオブジェクトがパッシブに転送され、さらに新しいオブジェクトが追加されます。その後、Survivorsのステータスが変更され、パッシブがアクティブになり、アクティブがパッシブになります。
Eden Spaceは、新しいオブジェクトが生成されるメモリ領域です。 この領域に十分なメモリがない場合、GCサイクルが開始されます。
これらの各領域は、アプリケーション中に仮想マシン自体でサイズを調整できます。
たとえば、-Xmxを2ギガバイトに指定した場合、これは2ギガバイトすべてがすぐに占有されることを意味しません(もちろん、メモリを積極的に消費する何かをすぐに開始しない限り)。 仮想マシンは最初に自身をチェックしようとします。
3番目のスクリーンショットは、週末には使用されないアプリケーションの非アクティブな段階を示しています。Edenは均等に成長し、Survivorsは定期的にシフトし、Oldは実質的に成長しません。 アプリケーションは90時間以上動作し、原則として、JVMはアプリケーションがそれほど必要としないと考えており、約540 MBです。
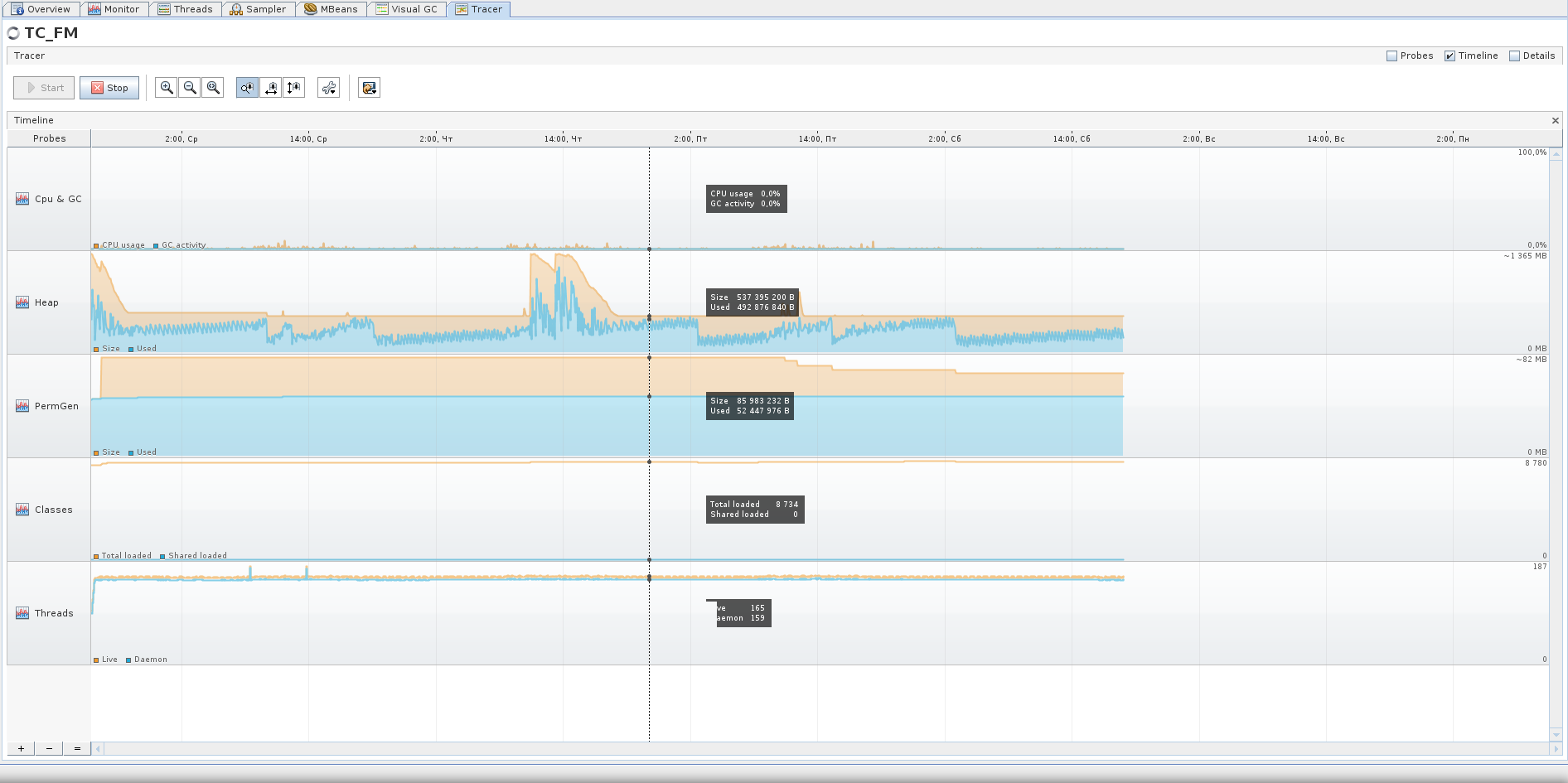
仮想マシンがヒップ用にさらに多くのメモリを割り当てるピーク状況もありますが、これらは他の「考慮されない」ものであると思います。これについては以下で詳しく説明します。または、たとえば、仮想マシンがEdenにより多くのメモリを割り当てている場合がありますそのため、その中のオブジェクトは、次のクリーニングサイクルの前にゴミになる時間があります。
次のスクリーンショットで赤でマークした領域は、一部のオブジェクトがメモリからより早く削除されるためにガベージになる時間がなく、まだオールドになっている場合に、オールドの増加です。 青い領域は例外です。 あなたは赤い領域の上に櫛を見ることができます-これはエデンの振る舞いです。
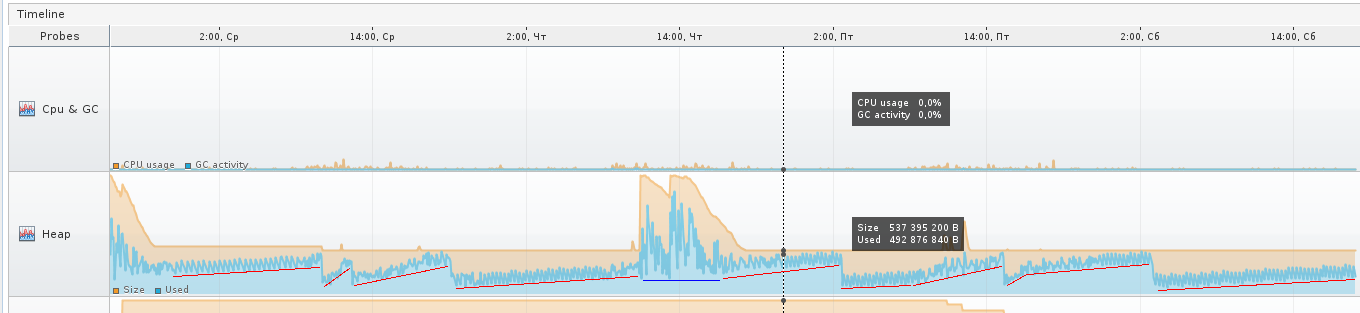
青いセクションの過程で、仮想マシンは最も可能性が高いと判断したのは、Edenエリアのサイズを大きくする必要があるためです。トレーサーを拡大すると、GCが「離れ」を停止し、以前のような小さな振動がなく、振動が遅くなり、珍しい。
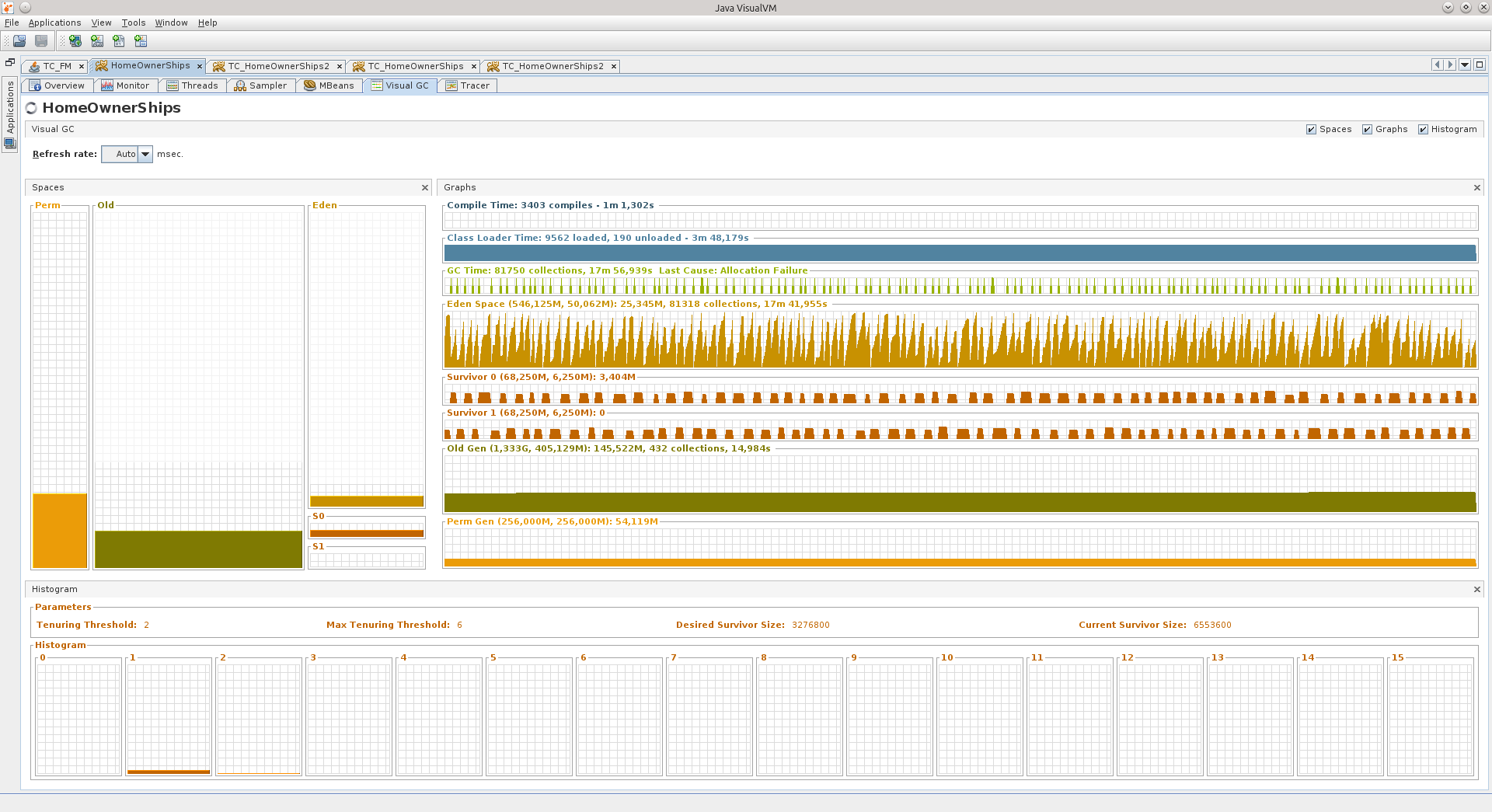
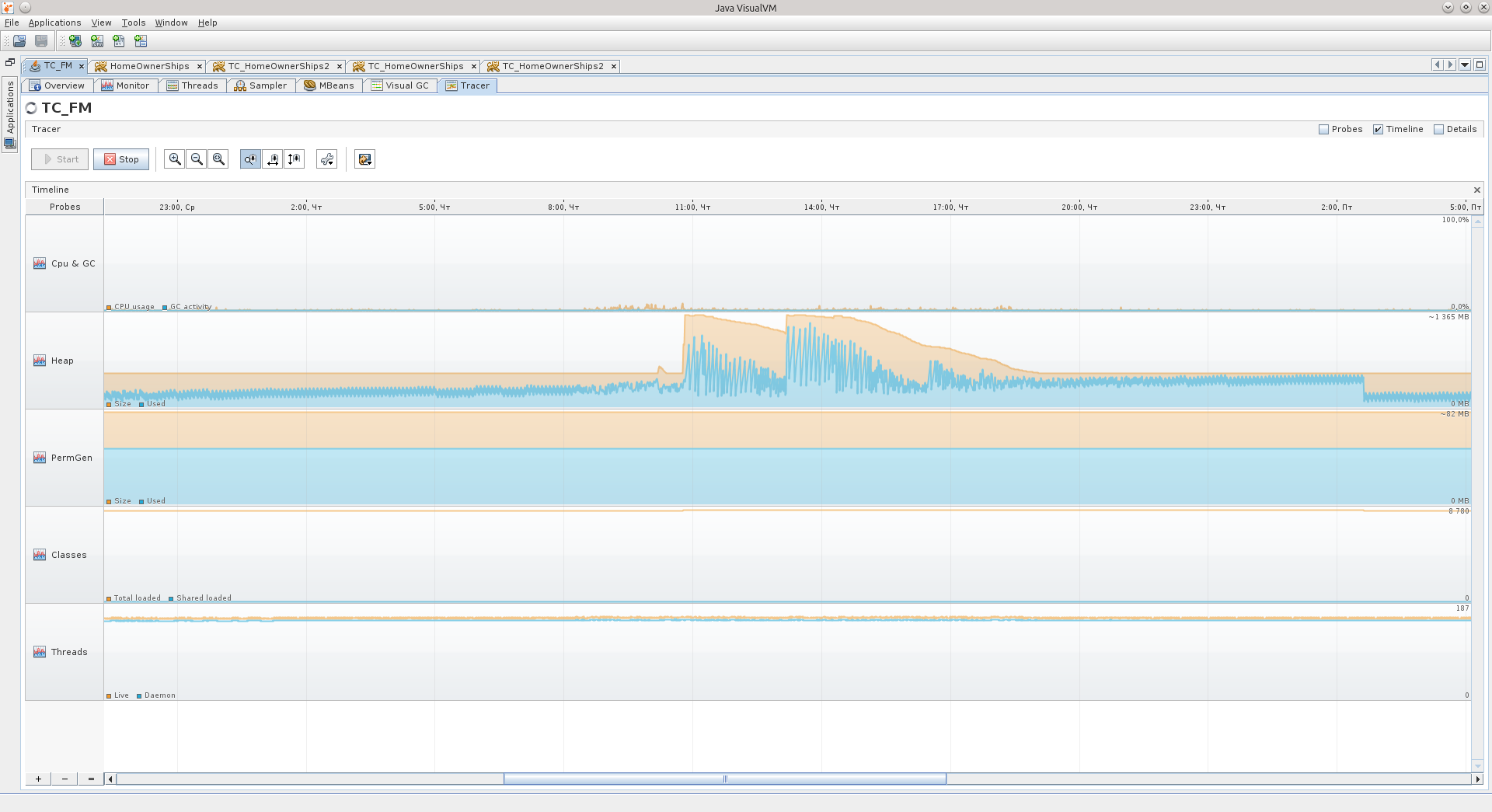
2番目のアプリケーションに移りましょう。
その中で、エデンは、スパイクを備えたアリーナであるMortal Kombatのあるレベルを思い出させます。 そのように思えた...そして、GCスケジュールはNFS Hot Pursuitからの急上昇ですが、これらはまだ横ばいです。
エリア名の右側の数字は次のことを示しています。
1)Edenのサイズは50メガバイトであり、グラフの最後に描かれているものは、現時点での最後の値は25メガバイトです。 合計で、最大546メガバイトまで拡張できます。
2)Oldは最大1.333ギガバイトまで成長できますが、現在は405 MBを占有し、145.5 MBで詰まっています。
また、サバイバーエリアとパーマジェネレーション用。
比較のために-これは、2番目のアプリケーションの75時間のトレーサーチャートです。ここから結論を引き出すことができると思います。 たとえば、このアプリケーションのアクティブフェーズは営業日の午前8時30分から午後5時30分までであり、週末でも機能することを確認します:)

アプリケーションで突然古い領域が一杯になったことを確認した場合、オーバーフローするまで待ってみてください。ほとんどの場合、すでにゴミでいっぱいです。
ガベージは、他のオブジェクトからアクティブに参照されないオブジェクト、またはそのようなオブジェクトの複合体全体です(たとえば、相互接続されたオブジェクトのある種の「クラウド」は、リンクのセットがこの「クラウド」内ではなく、この「クラウド」内の1つのオブジェクトは「外部」を参照しません)。
これは、グーグル検索中に股関節の構造について学んだことを簡単に語ったものです。
背景
そのため、2つのことが同時に起こりました。
1)金曜日のいずれかで新しいライブラリ/ tomkets / javaに切り替えた後、私が長い間実行していたアプリケーションは、投稿されてから2週間後に突然非常にひどく動作し始めました。
2)彼らは私にリファクタリングプロジェクトを提供しましたが、これもしばらくの間はうまく動作しませんでした。
これらのイベントが発生した正確な順序はもう覚えていませんが、「ブラックフライデー」の後、ブラックボックスにならないように、最終的にメモリダンプをより詳細に処理することにしました。 私はすでにいくつかの詳細を忘れることができることを警告します。
最初のケースでは、症状は次のとおりでした:リクエストの処理に関与するすべてのフローが保存され、データベースへの接続は11のみであり、使用されているとは言わず、データベースはrecvスリープ状態にある、つまりそれらが待機していると言いました使用を開始します。
再起動後、アプリケーションは復活しましたが、長く生きることはできませんでした。同じ金曜日の夕方に最も長く生きましたが、稼働日の終了後に再び落ちました。 画像は常に同じでした。データベースへの11の接続と、1つだけが何かをしているようです。
ちなみに、メモリは最小限でした。 OOMが理由の検索に私を導いたとは言えませんが、理由の検索で得られた知識により、OOMとの積極的な戦いを始めることができました。
JVVMでダンプを開いたとき、それから何かを理解することは困難でした。
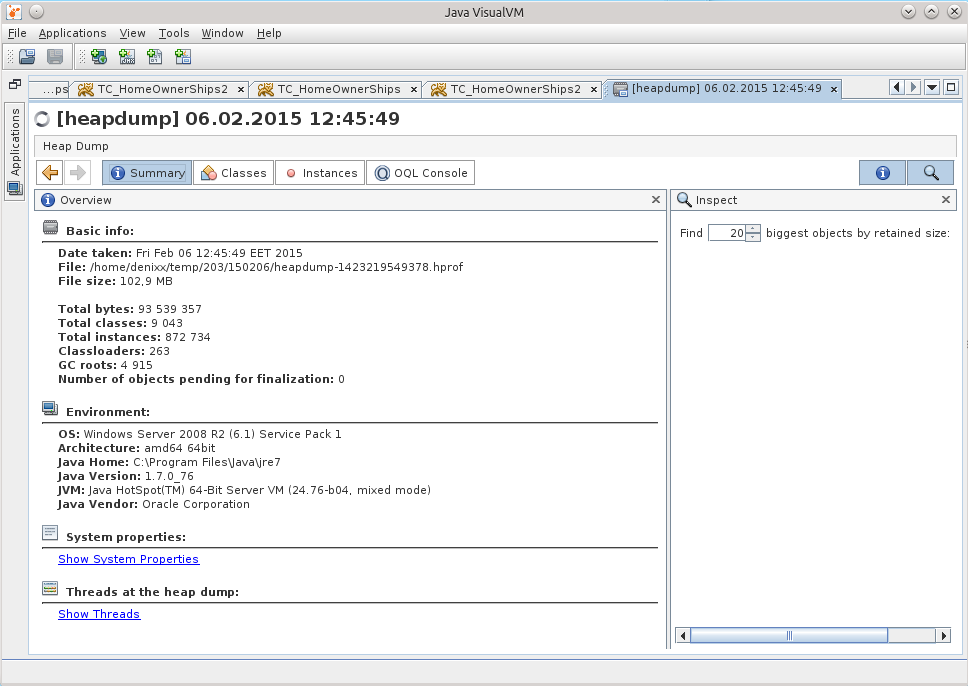
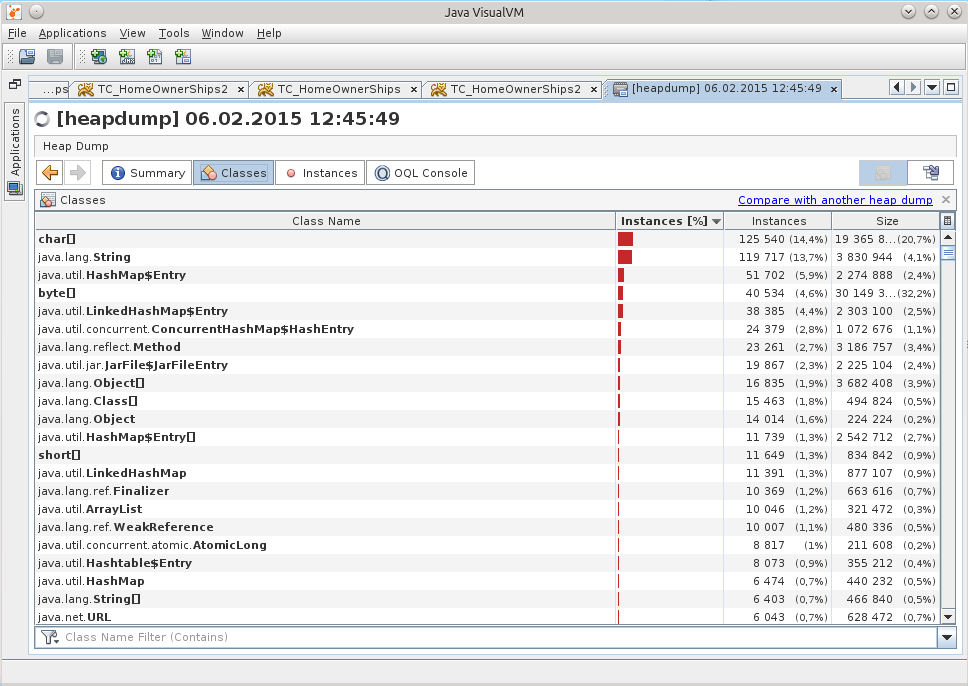
潜在意識は、その理由は基地での作業のどこかにあると示唆しました。
クラスを検索すると、メモリにはすでに29個のDataSourceがありますが、7個しか存在しないはずです。
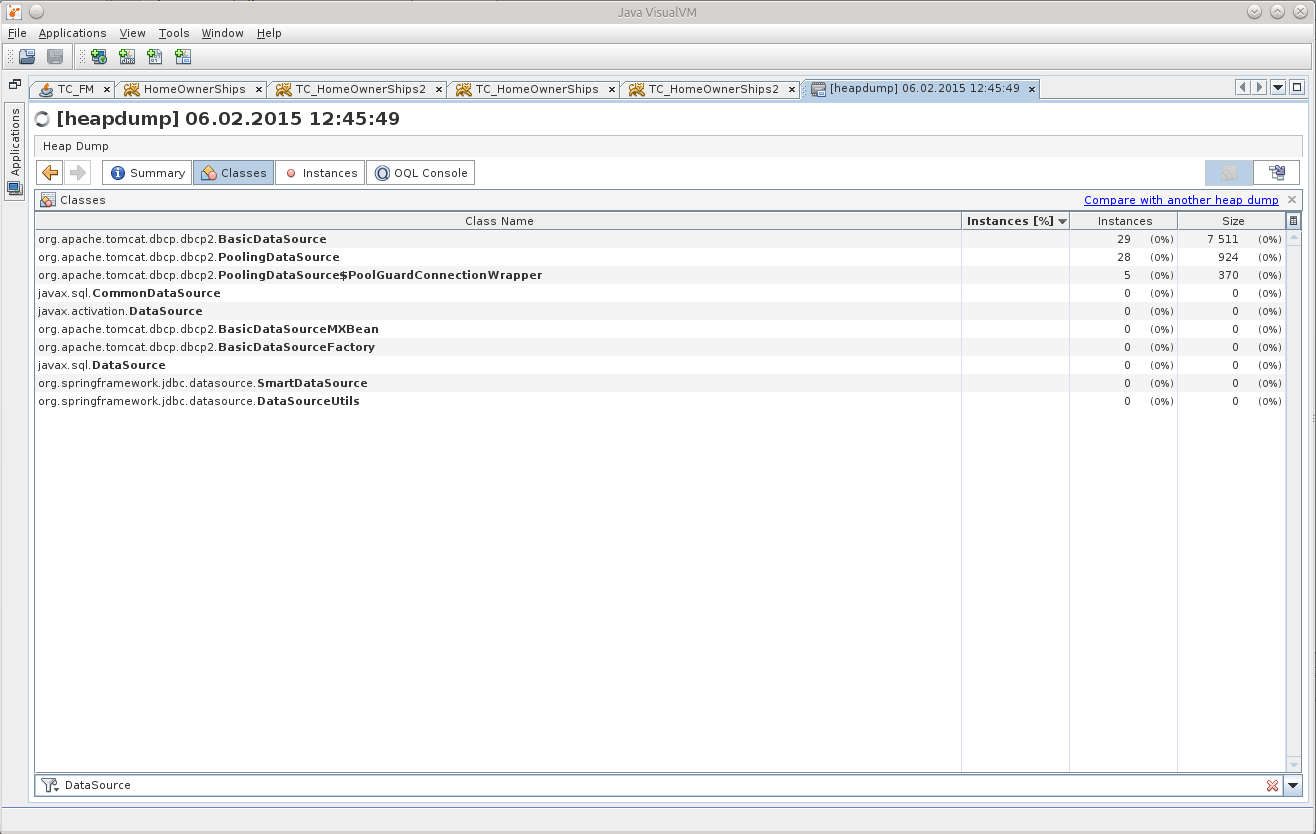
これは、私が人を押しのけ、もつれを解き始めることができるポイントを与えてくれました。
Oql
ビューアーでビューアーに座る時間はありませんでしたが、ついにOQLコンソールタブに注意が向けられました。ここが真実の瞬間だと思いました。それを最大限に使い始めるか、これをすべて忘れます。
もちろん、始める前にGoogleに質問があり、彼はJVVMでOQLを使用するための虎の巻を親切に提供してくれました:
http ://visualvm.java.net/oqlhelp.html
最初は、大量の圧縮された情報にがっかりしましたが、Googleを使用した後、次のOQLクエリが表示されました。
select {instance: x, uri: x.url.toString(), connPool: x.connectionPool} from org.apache.tomcat.dbcp.dbcp2.BasicDataSource x where x.url != null && x.url.toString() == "jdbc:sybase:Tds::/"
これはすでに修正され、補足されています。このリクエストの最終バージョンです:)
結果はスクリーンショットで見ることができます:
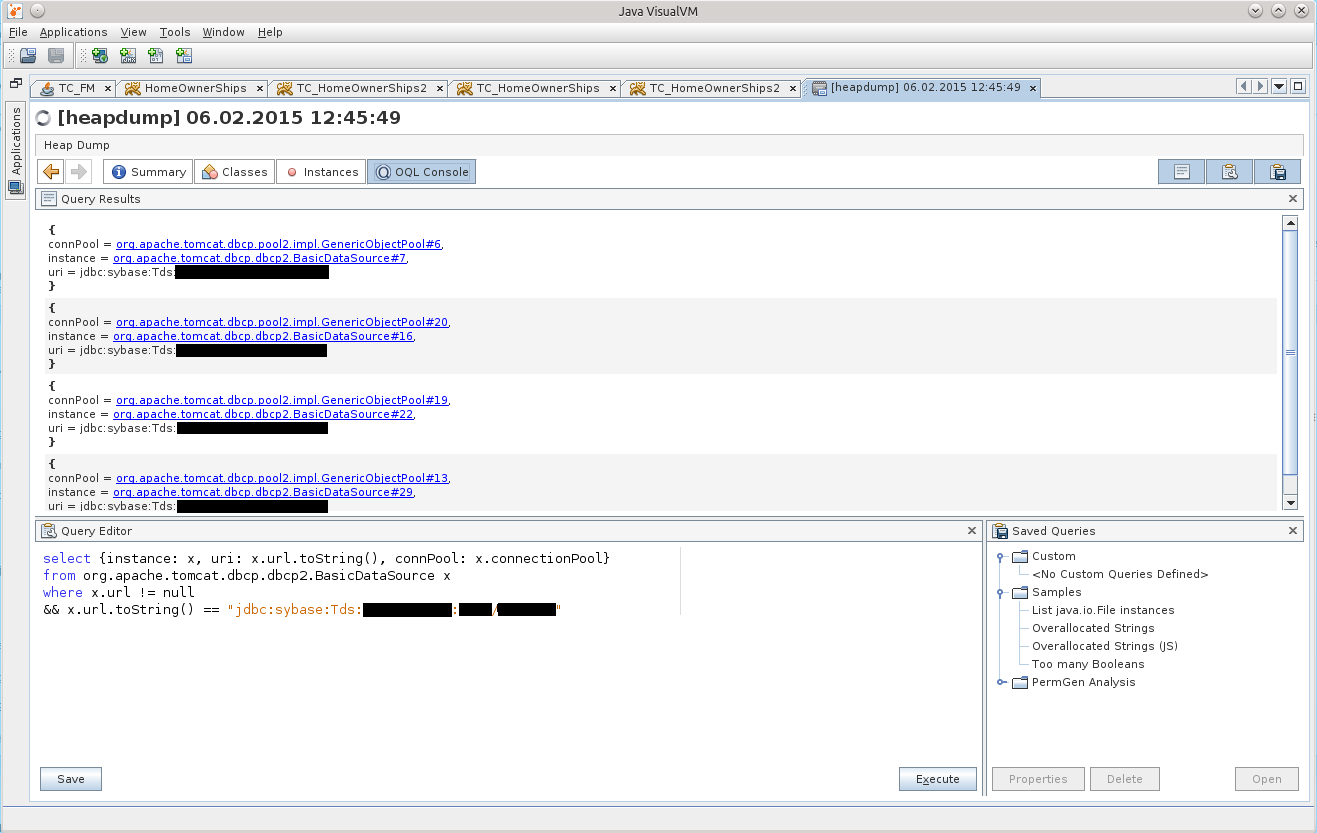
BasicDataSource#7をクリックした後、[インスタンス]タブで目的のオブジェクトに移動します。
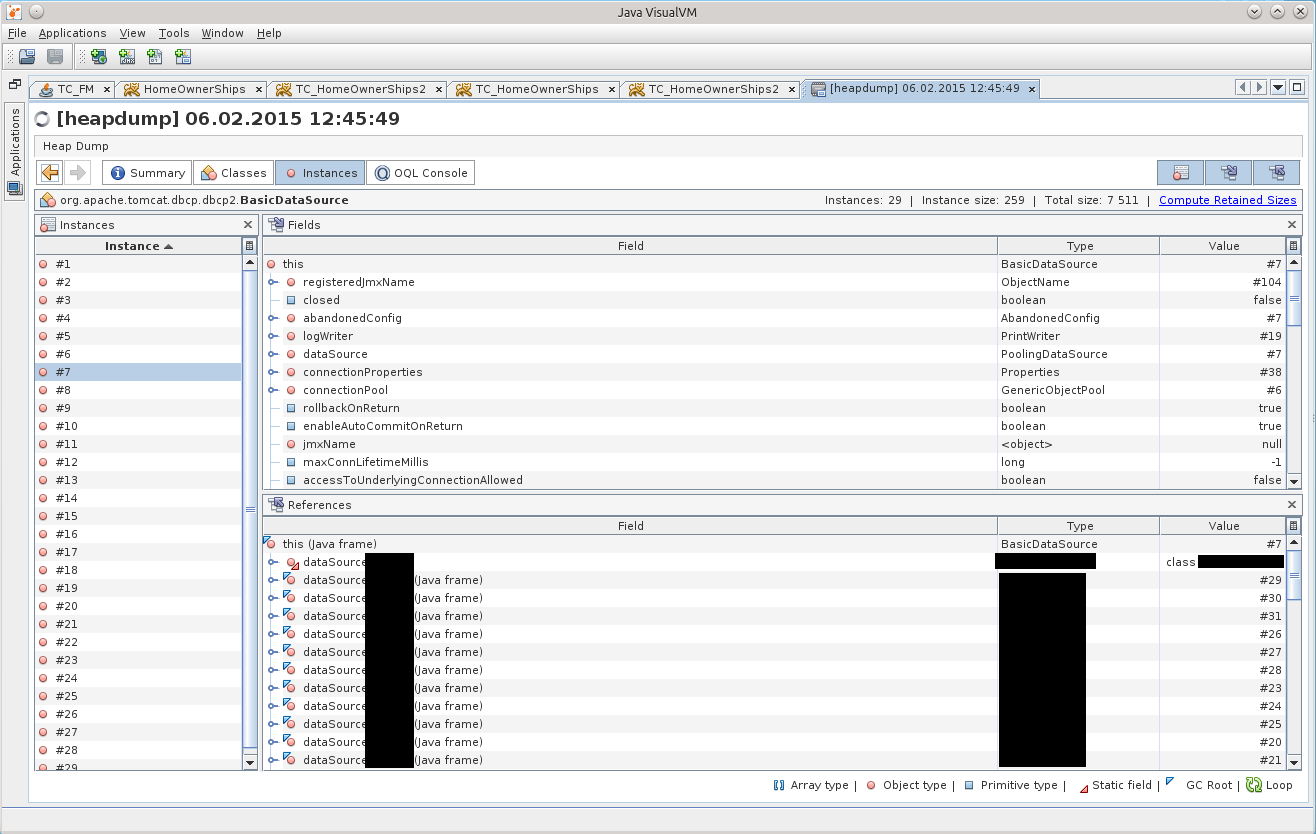
しばらくして、/ conf / context.xmlファイルのtomketのResourceタグで指定された構成に矛盾があることがわかりました。 実際、ダンプでは、maxTotalパラメーターの値は8ですが、maxActiveを20に設定しています...
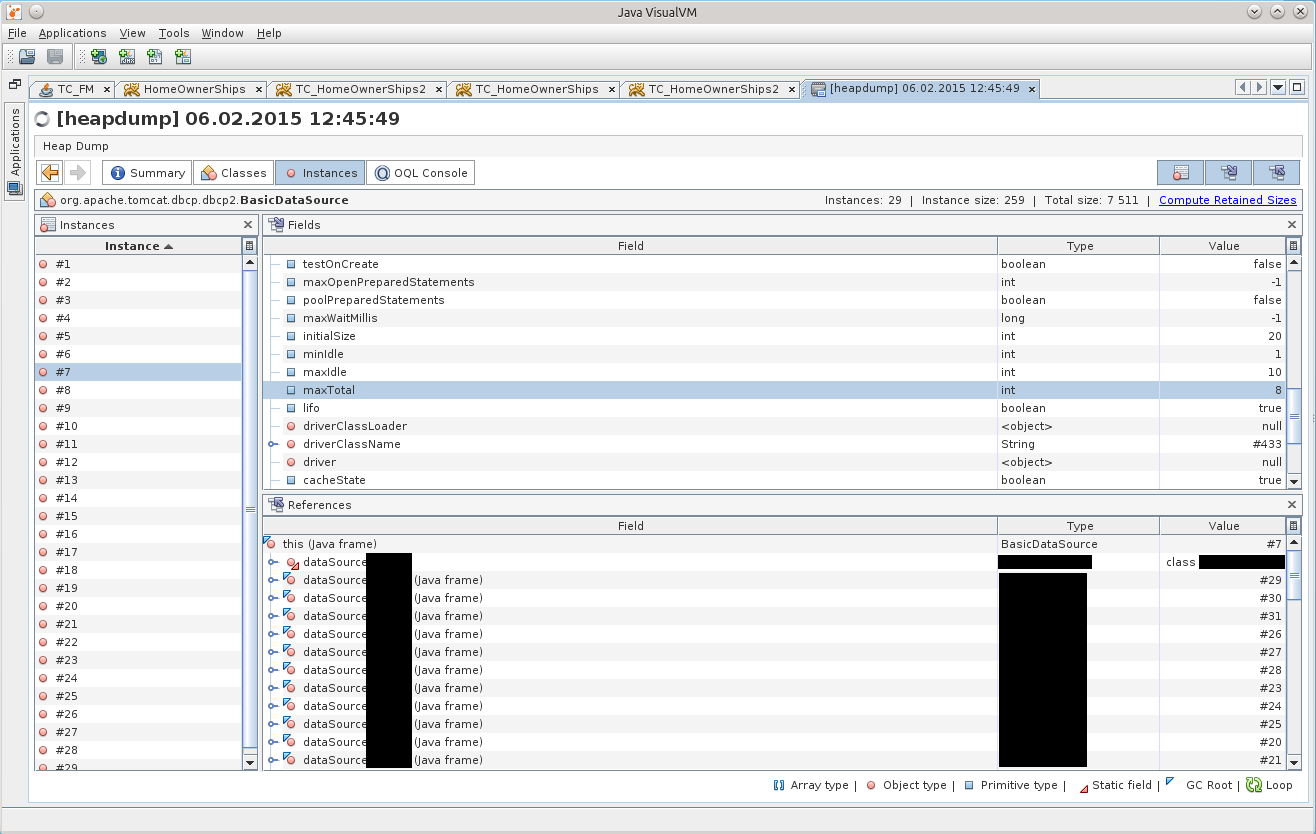
この2週間、アプリケーションが間違った接続プール構成で生きていたことが、私に伝わり始めました!
簡潔にするために、Tomcatを使用し、DBCPを接続プールとして使用する場合、DBCPバージョン1.4は7番目のボリュームで使用され、DBCP 2.0は8番目のボリュームで使用されます。オプション! そして、一般的なmaxTotalについては、サイトのメインページに書かれています:)
http://commons.apache.org/proper/commons-dbcp/「ユーザーは、Commons Pool 2で使用される新しい名前に合わせるために、一部の構成オプション(maxActiveからmaxTotalなど)の名前が変更されていることにも注意する必要があります。」
理由
彼はとにかくそれらを呼び出し、落ち着いて、それを理解することにしました。
判明したように、BasicDataSourceFactoryクラスは単純にこのリソースを受け取り、必要なパラメーターがあるかどうかを確認して、生成されたBasicDataSourceオブジェクトにそれらをピックアップし、興味のないものをすべて完全に無視します。
おかしなパラメーターmaxActive => maxTotal、maxWait => maxWaitMillis、removeAbandoned => removeAbandonedOnBorrow&removeAbandonedOnMaintenanceの名前が変更されました。
デフォルトでは、前述のようにmaxTotalは8です。 removeAbandonedOnBorrow、removeAbandonedOnMaintenance = false、maxWaitMillisは永久に待機するように設定されています。
プールは、最小数の接続で構成されていることが判明しました。 空き接続が終了すると、アプリケーションは接続が解放されるのを静かに待ちます。 そして、沈黙は「放棄された」接続に関するログのすべてを終了します-
プログラマーの嫌いなコードが接続を取得する場所をすぐに示すことができますが、作業の終了時にそれを返しません。
これは現在、モザイク全体が急速に開発されたものであり、この知識はより長く抽出されています。
「そのようなものであってはならない」と私は決定し、パッチ(
https://issues.apache.org/jira/browse/DBCP-435をガッシングし 、
http: //svn.apache.org/viewvc/commons/proper/に置きました
dbcp / tags / DBCP_2_1 / src / main / java / org / apache / commons / dbcp2 / BasicDataSourceFactory.java?view = markup )、パッチが受け入れられ、DBCPバージョン2.1に入力されました。 Tomcat 8がDBCPバージョンを2.1+にアップグレードする場合、多くの秘密がリソース構成について管理者に明らかにされると思います:)
この事件に関して、もう1つ詳細を説明する必要がありました。ダンプ内の地獄は既に7個ではなく29 DataSource'ovでした。 答えは、7 * 4 = 28 + 1 = 29の平凡な算術にあります。
リソースをtomketの/conf/context.xmlファイルにドロップできない理由の詳細/ webappsフォルダー内の各サブフォルダーに対して、独自のコピー/conf/context.xmlが生成されます。つまり、存在するリソースの数にアプリケーションの数を掛けて、ソケットのメモリーで生成されるプールの総数を取得する必要があります。 「この場合はどうすればよいですか」という質問に対する答えは次のとおりです。すべてのリソース宣言を/conf/context.xmlからGlobalNamingResourcesタグ内の/conf/server.xmlファイルに移動する必要があります。 ここで、デフォルトでResource name = "UserDatabase"の1つを見つけて、その下にプールを配置できます。 次に、ResourceLinkタグを使用する必要があります。これは、アプリケーションのプロジェクト内の/META-INF/context.xmlファイル内に配置することが望ましいです。これは、いわゆる「アプリごとのコンテキスト」、つまり、次の目的でのみ使用できるコンポーネントの宣言を含むコンテキストですデプロイ可能なアプリケーション。 ResourceLinkの場合、名前とグローバルパラメーターに同じ値を含めることができます。
例:
<ResourceLink name="jdbc/MyDB" global="jdbc/MyDB" type="javax.sql.DataSource"/>
このリンクは、「jdbc / MyDB」という名前のグローバルに宣言されたデータソースから取得し、リソースはアプリケーションで使用可能になります。
ResourceLinkは(必須ではありませんが)/conf/context.xmlに配置できますが、この場合、メモリ内にDataSourceのコピーがそれほど多くない場合でも、すべてのアプリケーションはグローバルに宣言されたリソースにアクセスできます。
詳細については、GlobalNamingResources-
http ://tomcat.apache.org/tomcat-7.0-doc/config/globalresources.html#Environment_Entries、ResourceLink-http://tomcat.apache.org/tomcat-7.0-docをご覧ください。
/config/globalresources.html#Resource_Links 、このページを表示することもできます:
tomcat.apache.org/tomcat-7.0-doc/config/context.htmlTC8の場合、同じページ:
http ://tomcat.apache.org/tomcat-8.0-doc/config/globalresources.htmlおよび
http://tomcat.apache.org/tomcat-8.0-doc/config/context.html その後、すべてが明らかになりました。11の接続は、1つのアクティブなDataSourceで8つの接続(maxTotal = 8)が使用され、3つの未使用のDataSourceコピーで別のminIdle = 1が使用されたためです。
その金曜日、私たちはTomcat 7にロールバックしました。Tomcat7はその横にあり、処分されるのを待っていました。
さらに、TC7で既にremoveAbandonedとlogAbandonedのおかげで接続リークが発見されました。 DBCPは喜んでcatalina.logログファイルに報告しました。
"org.apache.tomcat.dbcp.dbcp.AbandonedTrace$AbandonedObjectException: DBCP object created 2015-02-10 09:34:20 by the following code was never closed: at org.apache.tomcat.dbcp.dbcp.AbandonedTrace.setStackTrace(AbandonedTrace.java:139) at org.apache.tomcat.dbcp.dbcp.AbandonedObjectPool.borrowObject(AbandonedObjectPool.java:81) at org.apache.tomcat.dbcp.dbcp.PoolingDataSource.getConnection(PoolingDataSource.java:106) at org.apache.tomcat.dbcp.dbcp.BasicDataSource.getConnection(BasicDataSource.java:1044) at ...getConnection(.java:100500) at ...(.java:100800) at ...2(.java:100700) at ...1(.java:100600) ..."
この悪いメソッドであるBad Methodには、署名に接続conがありますが、内部に「con = getConnection();」コンストラクトがあり、つまずきのブロックになりました。 SuperClassが呼び出されることはめったにないので、彼らはそれほど長い間注意を払いませんでした。 さらに、私が理解しているように、営業日中は電話がかかってこなかったので、何かがぶら下がっていても他の人は気にしませんでした。 ツサムユパトニツァでは星だけが収束し、顧客部門の長は何かを見る必要がありました:)
付録2
「イベント番号2」については、リファクタリング用のアプリケーションを提供してくれ、すぐにサーバーでクラッシュすることになりました。
ダンプはすでに私に届いており、私もそれらを選択しようとすることにしました。
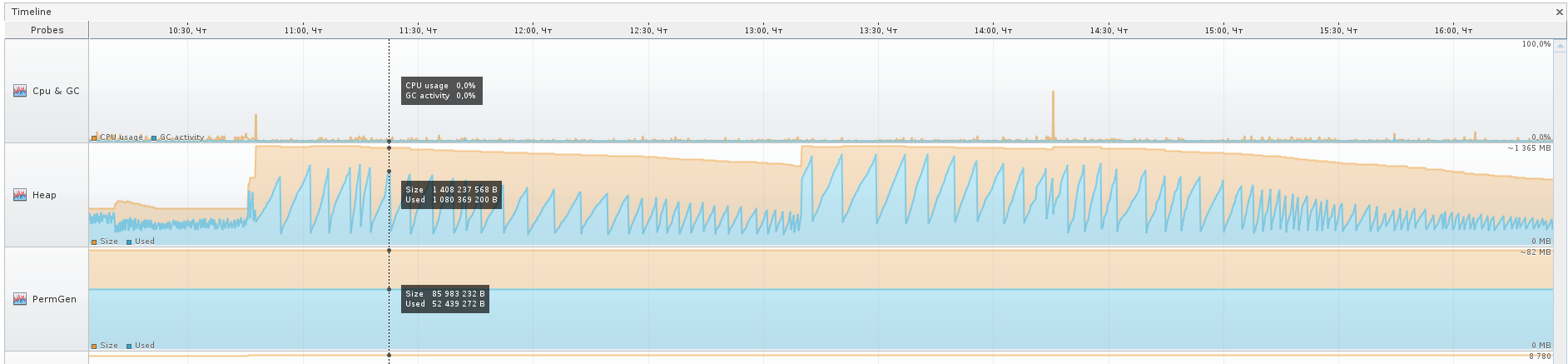
JVVMでダンプを開き、「少し元気づけました」:
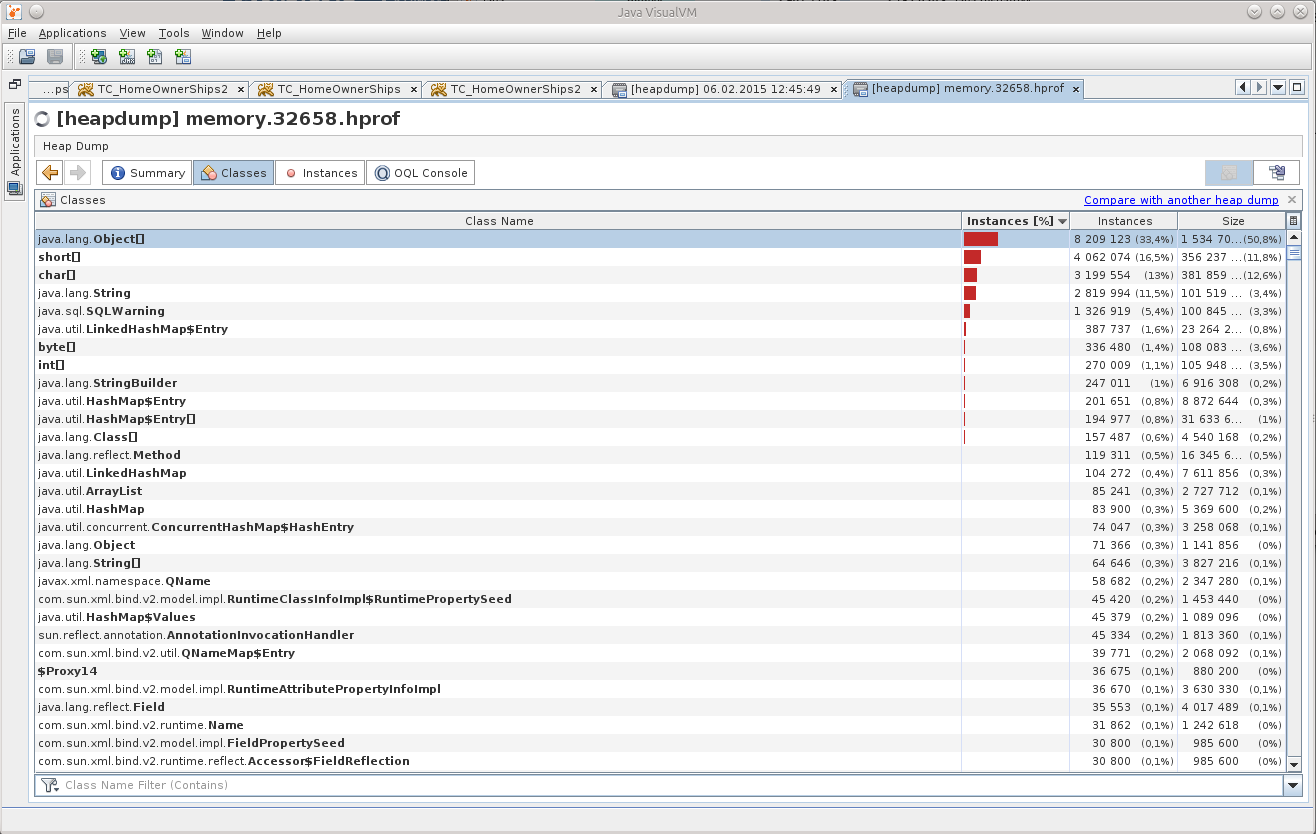
Object []から何が理解できますか?
(もちろん、経験のある人はすでにその理由を見ましたよね?)
だから、「まあ、本当に、誰もこれをやったことがない。確かに既製のツールがあるからだ!」 だから私はStackOverflowでこの質問に出くわしました:
http ://stackoverflow.com/questions/2064427/recommendations-for-a-heap-analysis-tool-for-java
提案されたオプションを確認した後、私はMATに立ち寄ることに決めました。少なくとも何かを試さなければなりませんでした。これはオープンプロジェクトであり、他のアイテムよりも多くの票があります。
Eclipseメモリ分析ツール
だから、マット。
Eclipseの最新バージョンをダウンロードして、MATをインストールすることをお勧めします。MATの独立したバージョンの動作が悪く、ダイアログが表示され、フィールドに内容が表示されないためです。 たぶん誰かがコメントで彼に欠けていることを教えてくれるかもしれませんが、EclipseにMATをインストールすることで問題を解決しました。
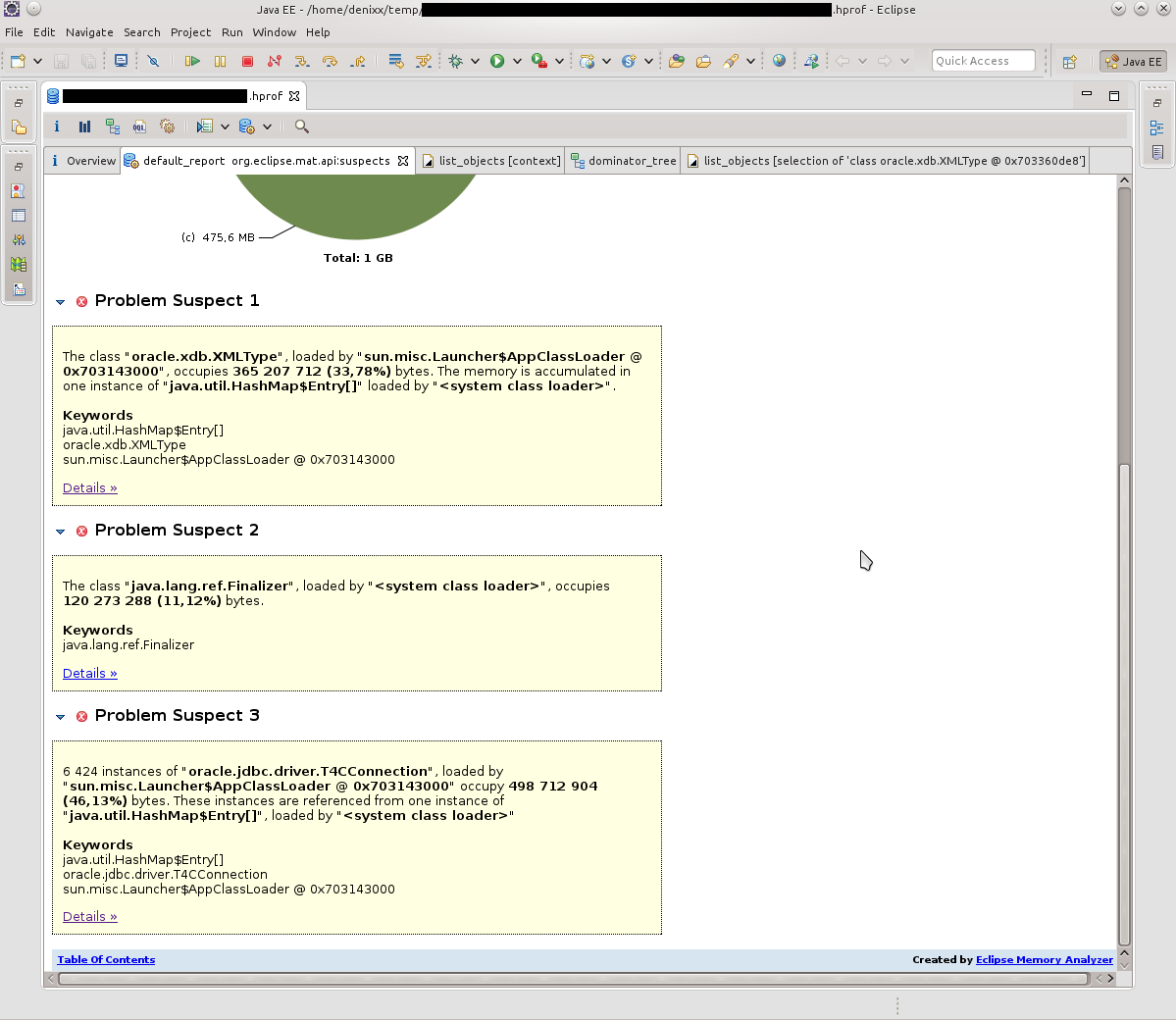
MATでダンプを開いた後、リークサスペクトレポートをリクエストしました。


正直言って、サプライズには限界がありませんでした。
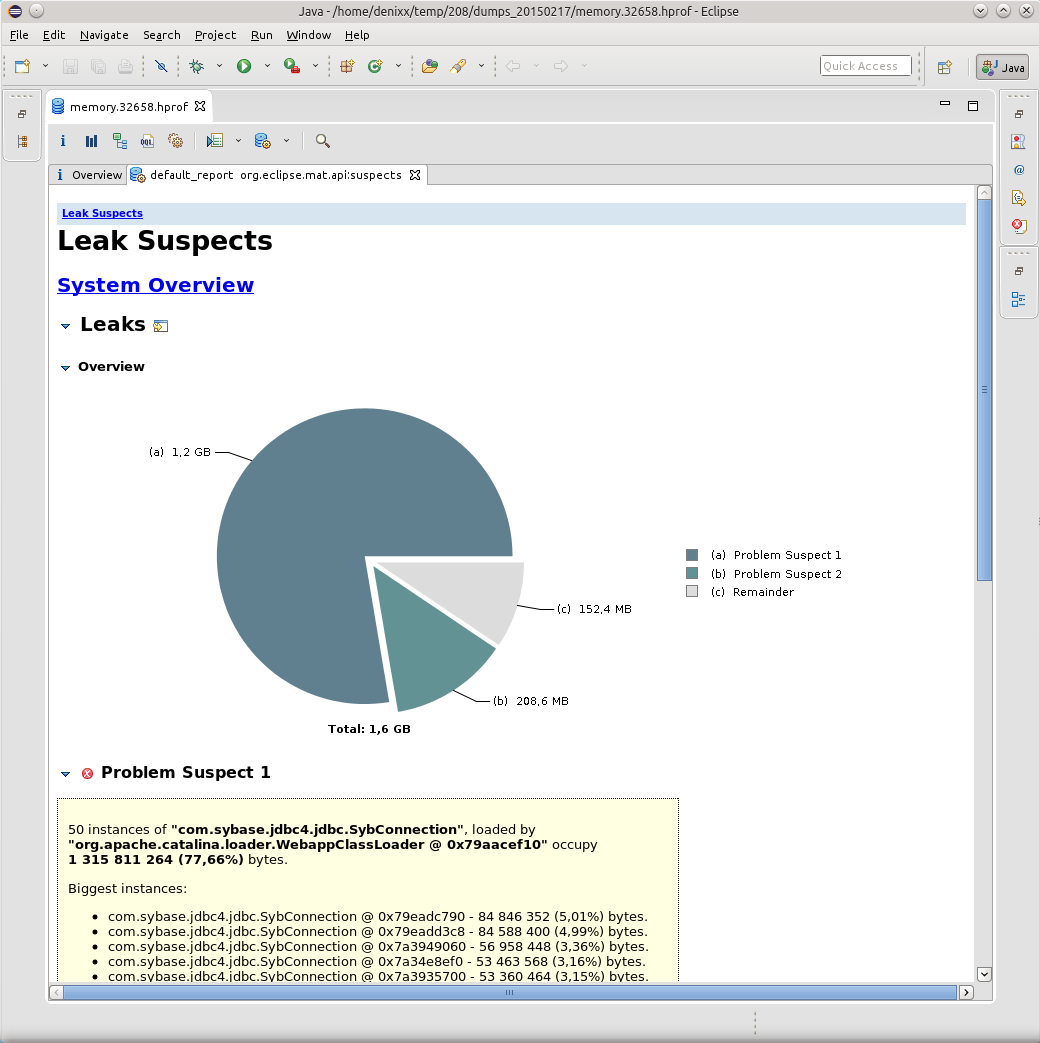
1.2ギガバイトは、ベースへの接続の重量を量ります。
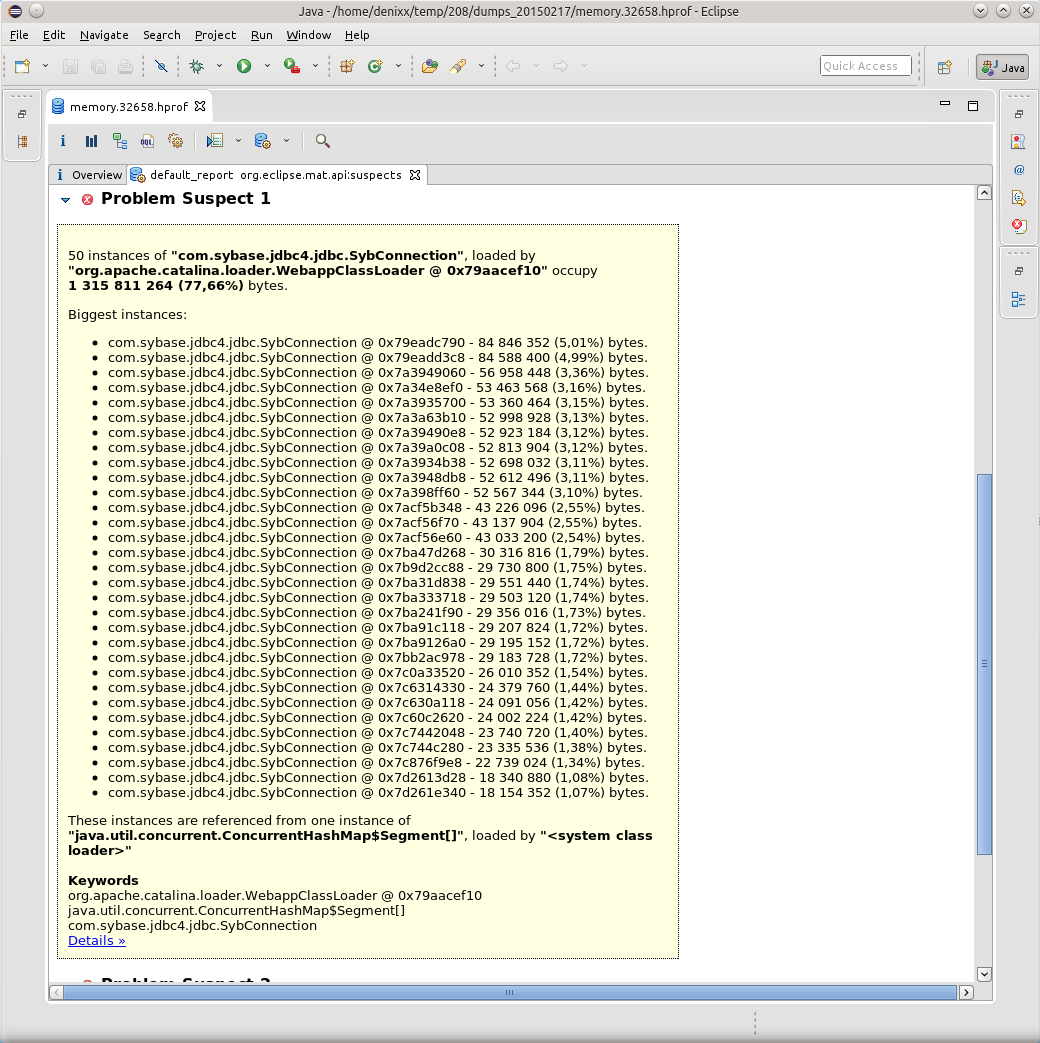
各接続の重量は17〜81メガバイトです。
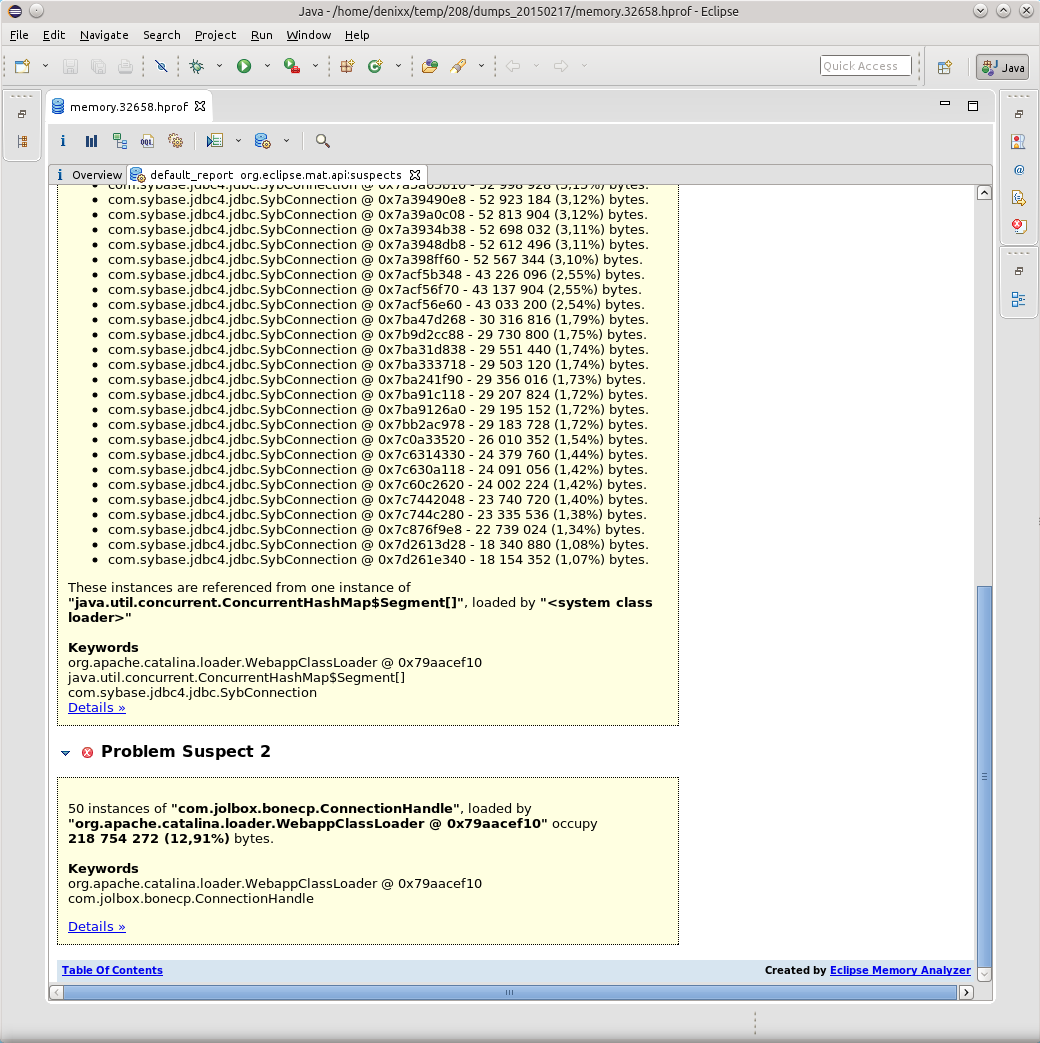
さて、プール自体はもう少しです。
ドミネーターツリーレポートは、問題を視覚化するのに役立ちました。
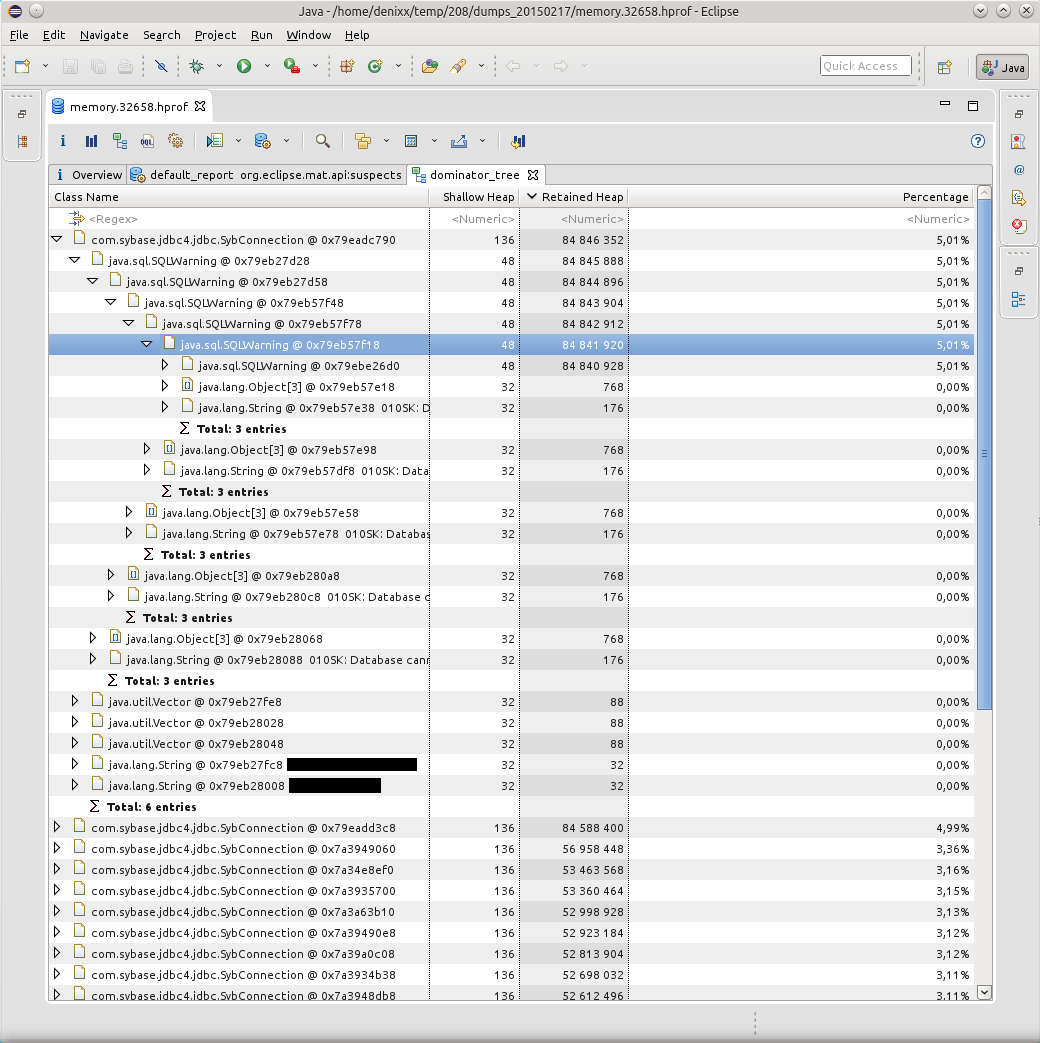
SQLWarningのキロメートルがすべてのフォールの原因であることが判明したため、データベースは「010SK:データベースは接続オプションSET_READONLY_TRUEを設定できません」と持続的に明確にしようとしました。構成できますか?知っている場合は教えてください)。
Googleは、Sybase ASEのこのような問題は2004年以来知られていると言いました:
https :
//forum.hibernate.org/viewtopic.php?f=1&t=932731要するに、「Sybase ASEは最適化を必要としないため、setReadOnly()はSQLWarningを生成します。」そして、これらのソリューションは引き続き機能します。
ただし、これは問題の解決策ではありません。問題の解決策は、接続がプールに戻されたときに、誰もそれを必要としないという事実により、すべてのデータベース通知がクリアされるからです。
DBCPはこれを行うことができます:
http ://svn.apache.org/viewvc/commons/proper/dbcp/tags/DBCP_1_4/src/java/org/apache/commons/dbcp/PoolableConnectionFactory.java?view=markup、method passivateObject(Object obj)、687行目でconn.clearWarnings();を見ることができます。この呼び出しはSQLWarningをメモリ内のキロメートルから保存します。
これについては、チケットから学びました:
https :
//issues.apache.org/jira/browse/DBCP-102また、バグトラッカーでそのようなチケットについてのプロンプトが表示されました:
https ://issues.apache.org/jira/browse/DBCP-234、それはすでにDBCP 2.0に適用されます。
その結果、アプリケーションをDBCPに転送しました(バージョン1.4ですが)。 サービスの負荷はかなり大きい(1分あたり800から2kリクエスト)が、それでもアプリケーションは適切に動作し、これが主なことです。 BoneCPは5か月間サポートされていなかったため、彼はそれを正しく行いましたが、HikariCPは彼に取って代わりました。 あなたは物事がそのソースにどのようにあるかを見る必要があります...
ファイティングOOM
MATが棚にすべてを配置する方法に感銘を受け、私はこの強力なツールを捨てないことに決めました。最初のアプリケーションでは、アプリケーションコードやストアードプロシージャコードの原因となるすべての種類が原因であるアプリケーションがフィンを接着するという事実に。 私はまだそれらをキャッチします。
両方のツールを使用して、OOMが落ちた理由を探して、送信された各ダンプを選択し始めました。
原則として、すべてのOOMがTaskThreadにつながりました。
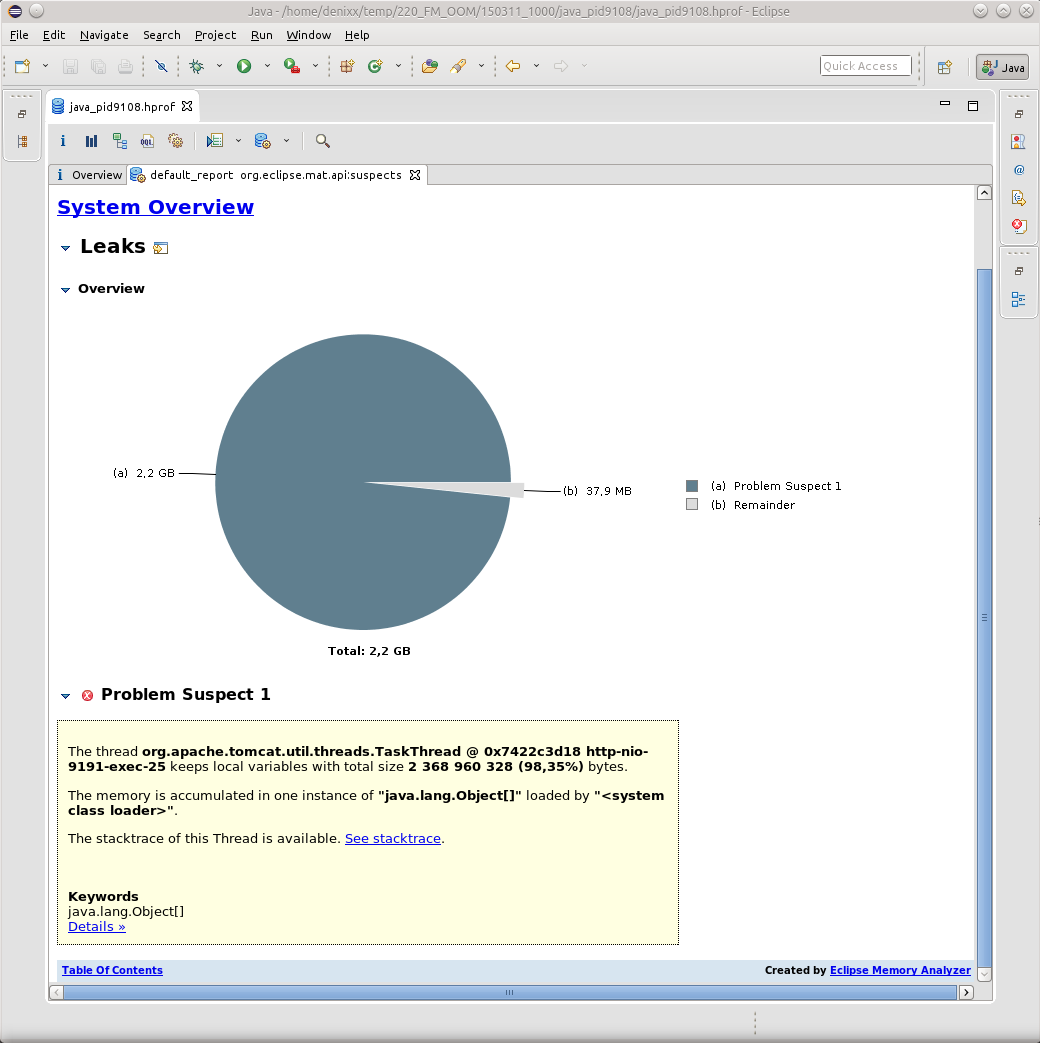
そして、スタックスタックを参照してください碑文をクリックすると、はい、その結果のマーシャリング中にスレッドが突然落ちたときの単なる平凡なケースになります。
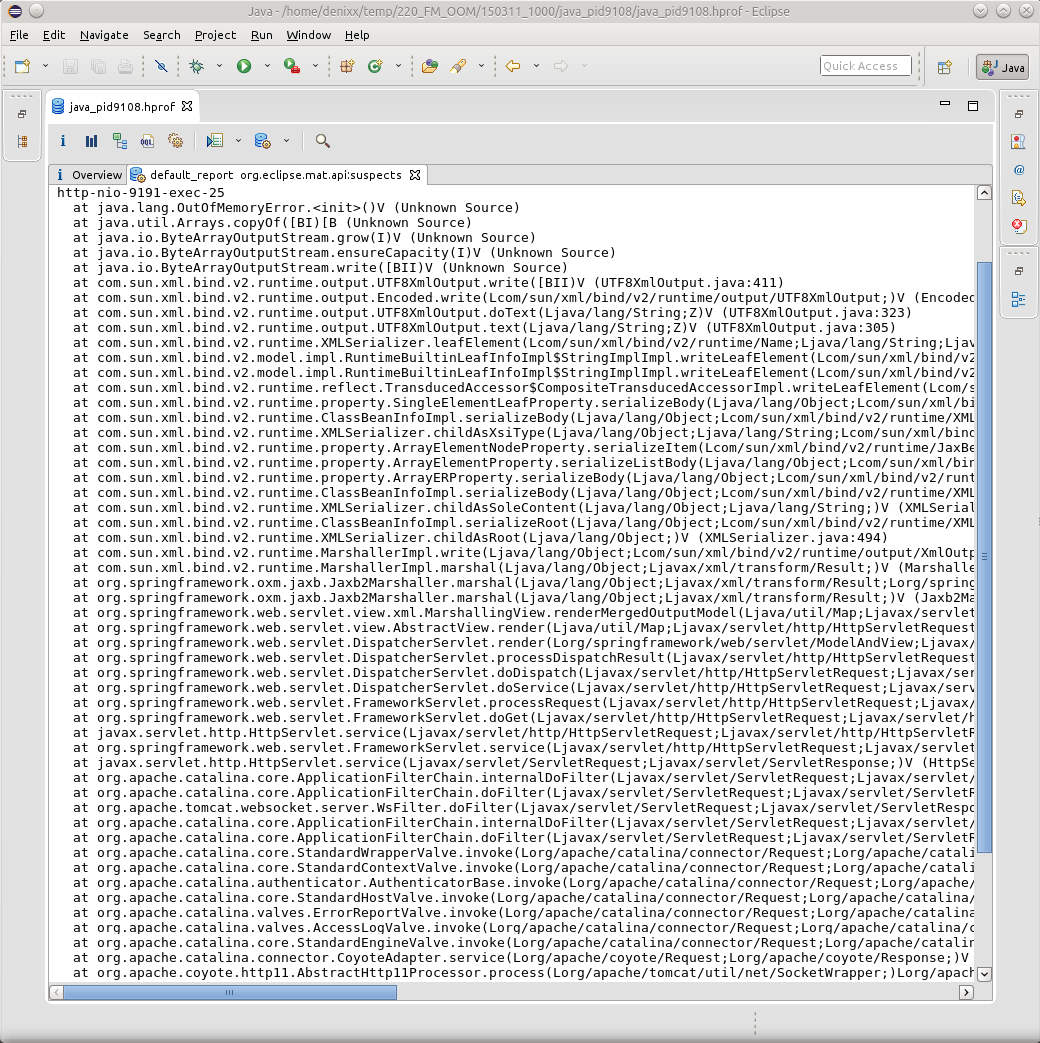
ただし、ここではOOMの原因を示すものは何もありません;これは結果にすぎません。 これまでのところ、MATのOQLのすべての魔法の知識が不足しているために、私にとっての理由を見つけるために役立つのはJVVMです。
そこでダンプをロードし、理由を見つけようとします!
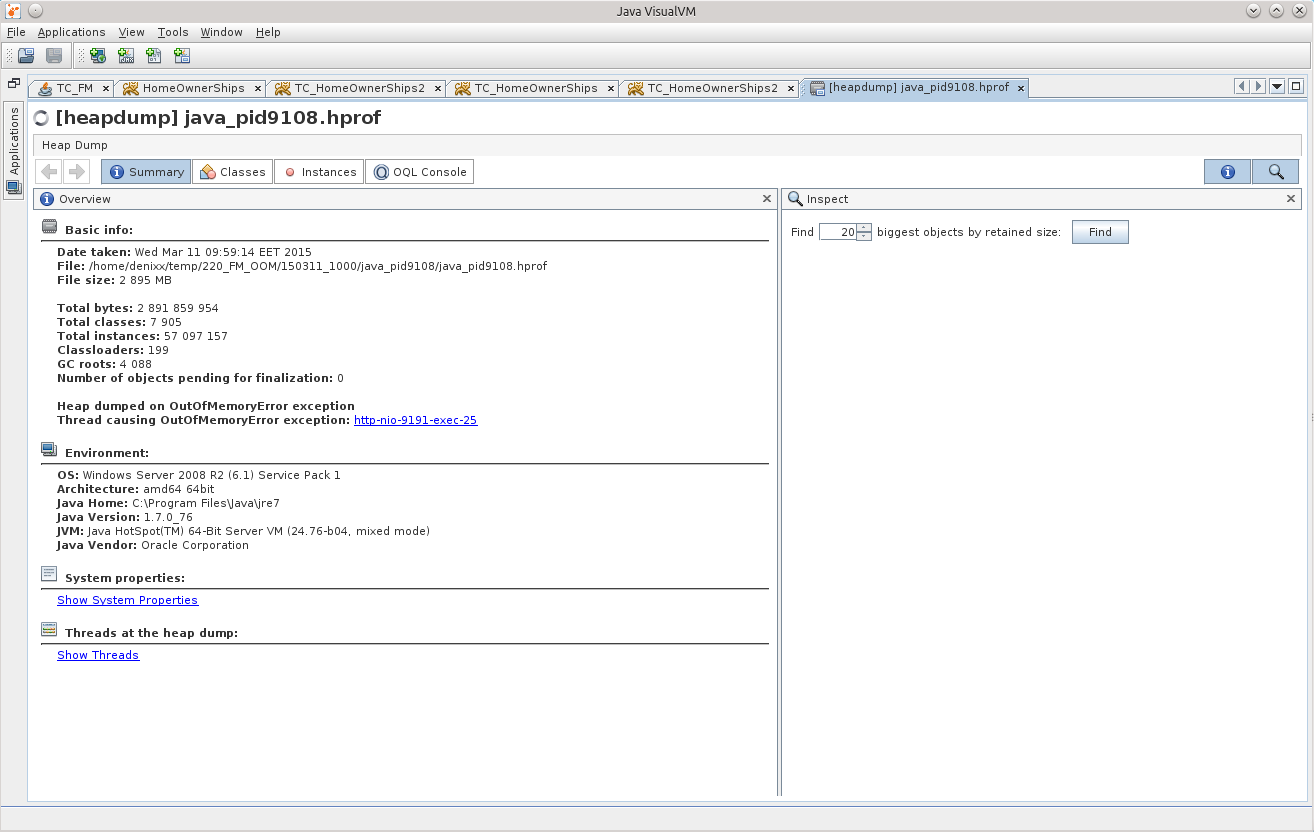
もちろん、データベースに関連するものを正確に探す必要があるため、まず、メモリ内にステートメントがあるかどうかを確認してみましょう。
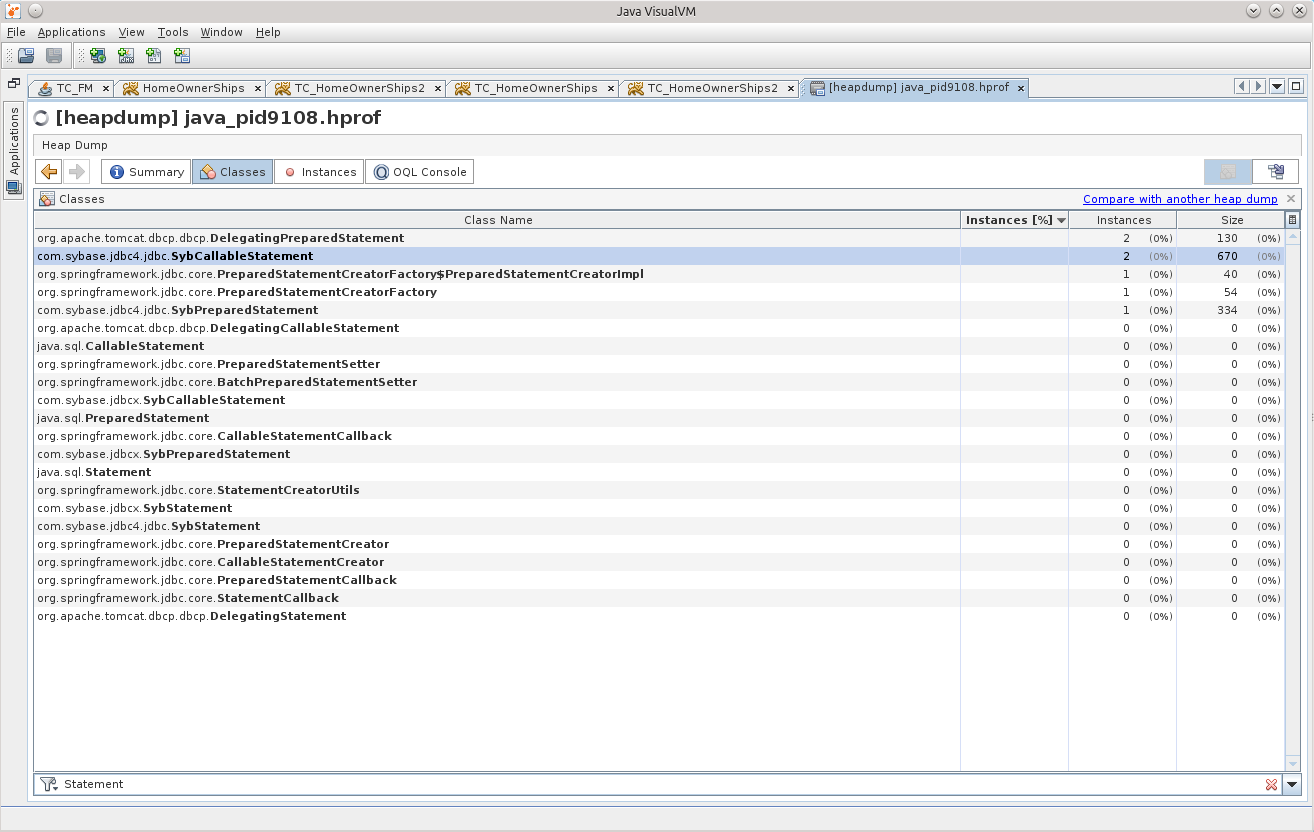
2つのSybCallableStatementと1つのSybPreparedStatement。
Statement'ovがはるかに大きくなると、問題はより複雑になると思いますが、次のクエリのいずれかを少し調整して、必要な条件を示し、すべてがうまくいくと思います。 さらに、もちろん、MATをよく見る価値があり、ストリームをマーシャリングしようとしている結果の種類、オブジェクト、およびステートメントのいずれを検索する必要があるかが明確になります。
select { instance: x, stmtQuery: x._query.toString(), params: map(x._paramMgr._params, function(obj1) { if (obj1 != null) { if (obj1._parameterAsAString != null) { return '\''+obj1._parameterAsAString.toString()+'\''; } else { return "null"; } } else { return "null"; } }) } from com.sybase.jdbc4.jdbc.SybCallableStatement x where x._query != null
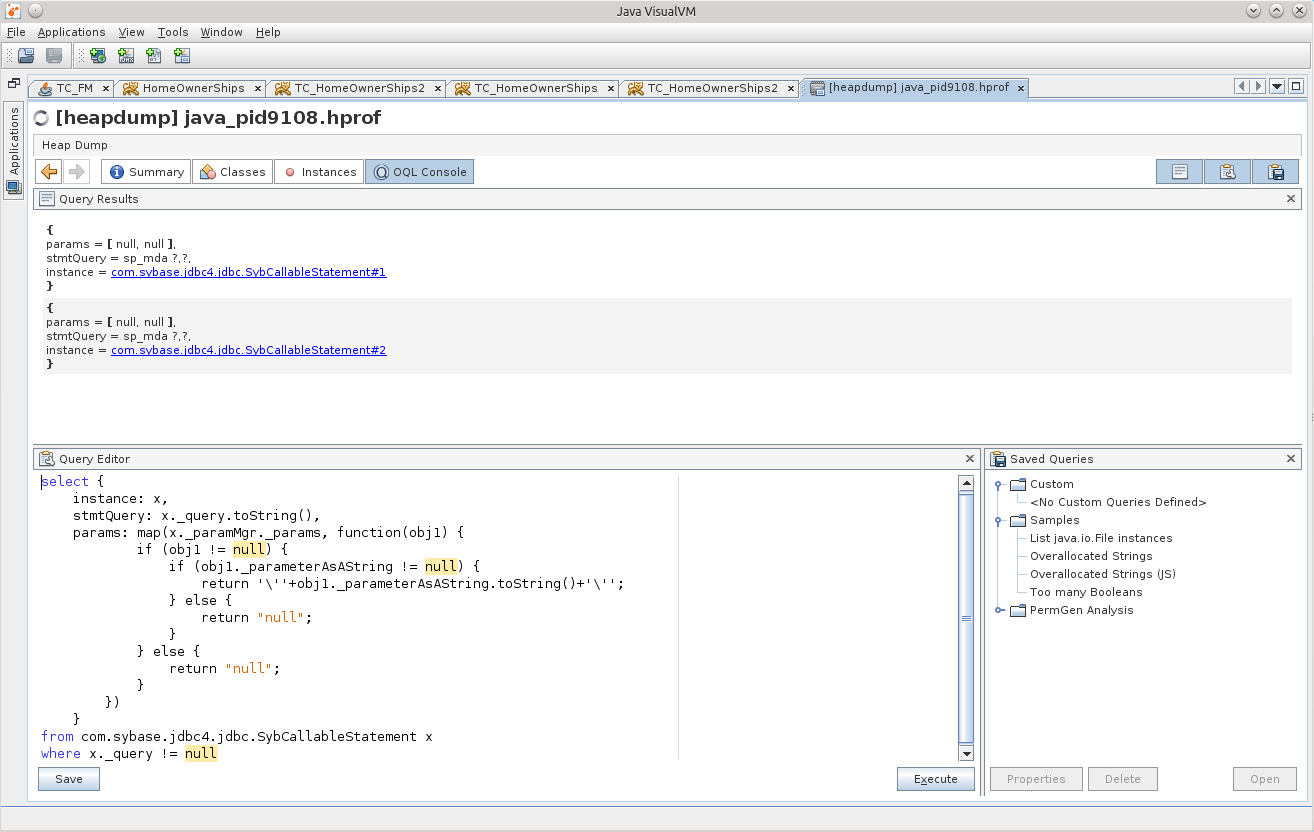
これらが「内部」の課題であることではありません。
select { instance: x, stmtQuery: x._query.toString(), params: map(x._paramMgr._params, function(obj1) { if (obj1 != null) { if (obj1._parameterAsAString != null) { return '\''+obj1._parameterAsAString.toString()+'\''; } else { return "null"; } } else { return "null"; } }) } from com.sybase.jdbc4.jdbc.SybPreparedStatement x where x._query != null
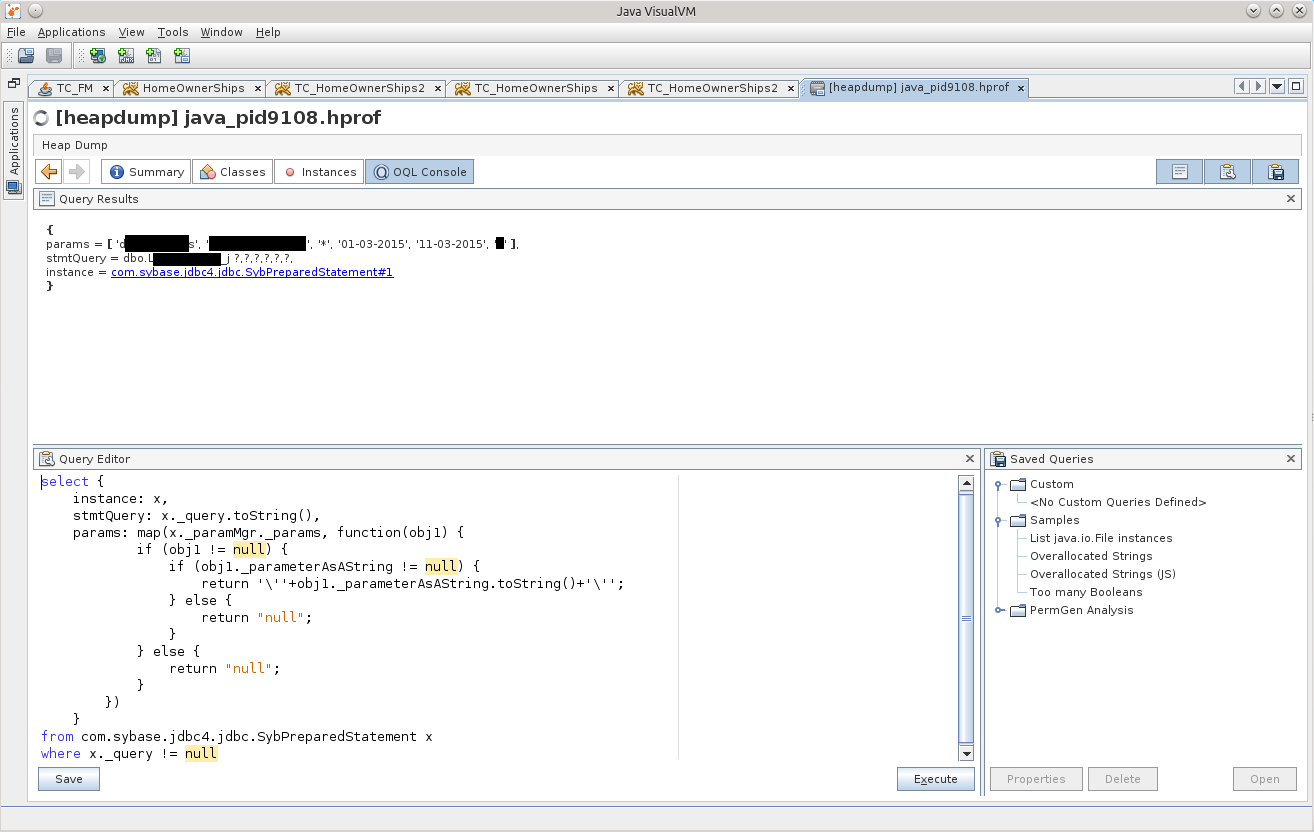
そして、ここにゲームがあります!
実験の純度のために、お気に入りのDB-IDEで同じクエリを投げることができ、非常に長い間うまくいきます。ストレージの腸を掘り下げると、そのクエリによって200万行が選択されていることが明らかになります。そのようなパラメータで。 これらの200万個もアプリケーションのメモリに入りますが、結果をマーシャリングしようとすると、アプリケーションにとって致命的になります。 これはハラキリです。 :)
同時に、GCはすべての証拠を慎重に削除しますが、これは彼を救いませんでしたが、ソースは彼の記憶に残り、彼は処罰されます。
なんらかの理由で、このすべての話の後、私はまだ失敗したように感じました。
さようなら
それで私の話は終わりました、楽しんでいただければ幸いです:)
私は上司に感謝したい、彼は私にそれを理解する時間を与えた。 この新しい知識は非常に役立つと思います。
いつも美味しいコーヒーをくれたスコリーニの女の子たちに感謝しますが、これらの感謝の言葉を読まないでしょう-ハブラハブルの存在を知っているとは思えません:)
コメントにさらに有用な情報と追加を表示したいと思います。非常に感謝します。
MATのドキュメントを読む時間だと思います...
UPD1 :はい、メモリダンプの作成などの有用なことについて話すのを完全に忘れていました。
docs.oracle.com/javase/7/docs/webnotes/tsg/TSG-VM/html/clopts.html#gbzrrオプション
-XX:+ HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath = / disk2 /ダンプ
アプリケーションがOutOfMemoryErrorでクラッシュしたときにダンプを生成するのに非常に便利です。
また、操作の途中で「利益」アプリケーションからメモリダンプを削除する機会もあります。
これにはjmapユーティリティがあります。
Windowsの呼び出し例:
「C:\ install \ PSTools \ PsExec.exe」-s「C:\ Program Files \ Java \ jdk1.7.0_55 \ bin \ jmap.exe」-dump:live、format = b、file = C:\ dump。 hprof 3440
最後のパラメーターは、JavaプロセスのPIDです。 PSToolsスイートのPsExecアプリケーションでは、これに-sスイッチを使用して、システム権限で他のアプリケーションを実行できます。 liveオプションは、ダンプを保存する前にGCを呼び出して、ゴミのメモリをクリアするのに便利です。 OOMが発生した場合、メモリをクリアする必要はなく、ガベージは残っていません。そのため、OOMの場合にライブオプションを設定する方法を探しないでください。
UPD2(2015-10-28)| ケース番号2〜3(同じことについての新しい記事を見るのではなく、これをアップデートとしてここに追加することにしました):
別の興味深いケースですが、Oracleベースを使用しています。
プロジェクトの1つは、XMLの機能を使用して、保存されたXMLドキュメントのコンテンツを検索します。 一般的に、このプロジェクトは、インスタンスの1つが突然、生命の兆候を示すのをやめたという事実に自分自身を感じることがありました。
猫で練習する「良い」チャンスを感じて、私は彼の記憶ダンプを見ることにしました。
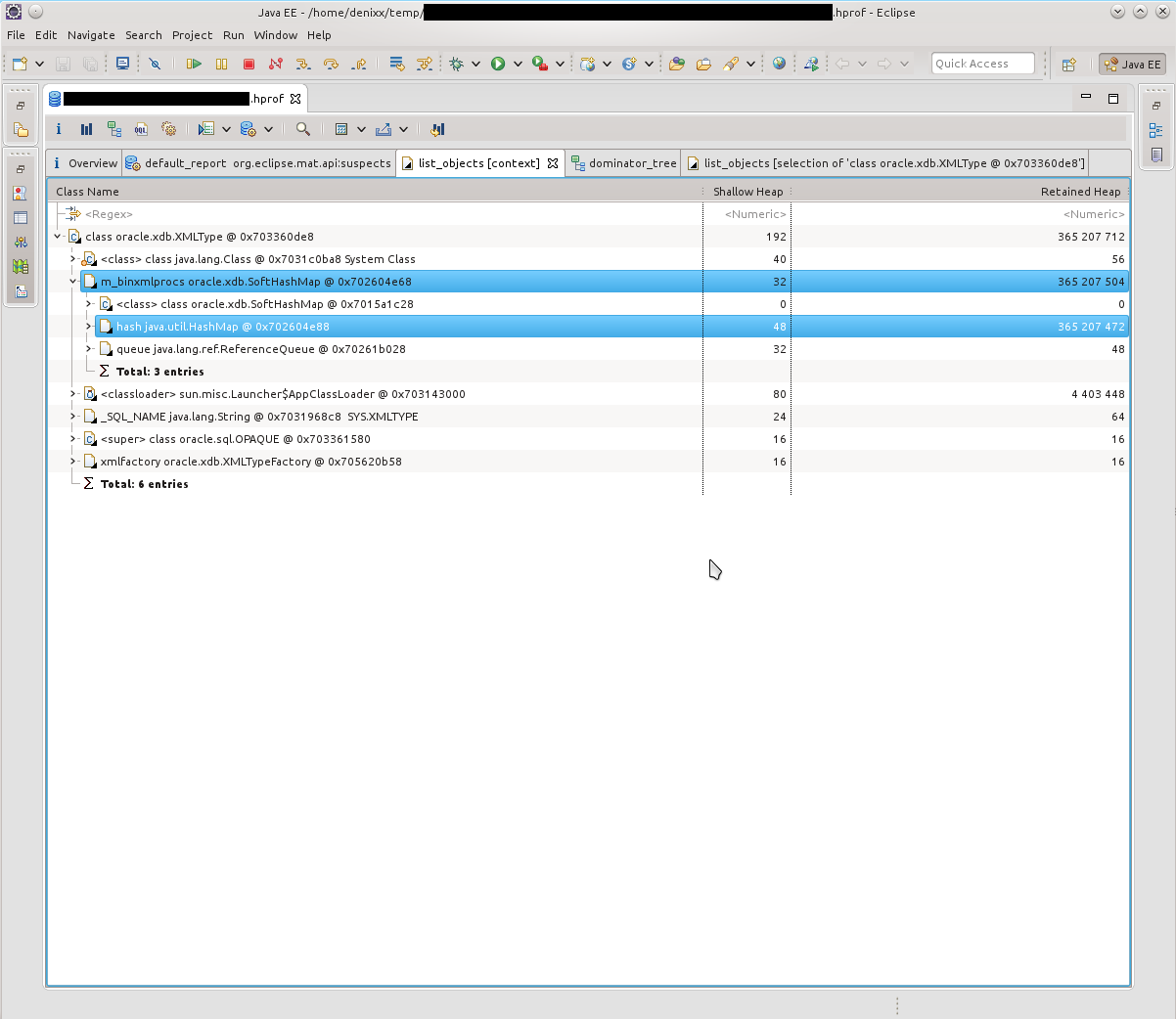
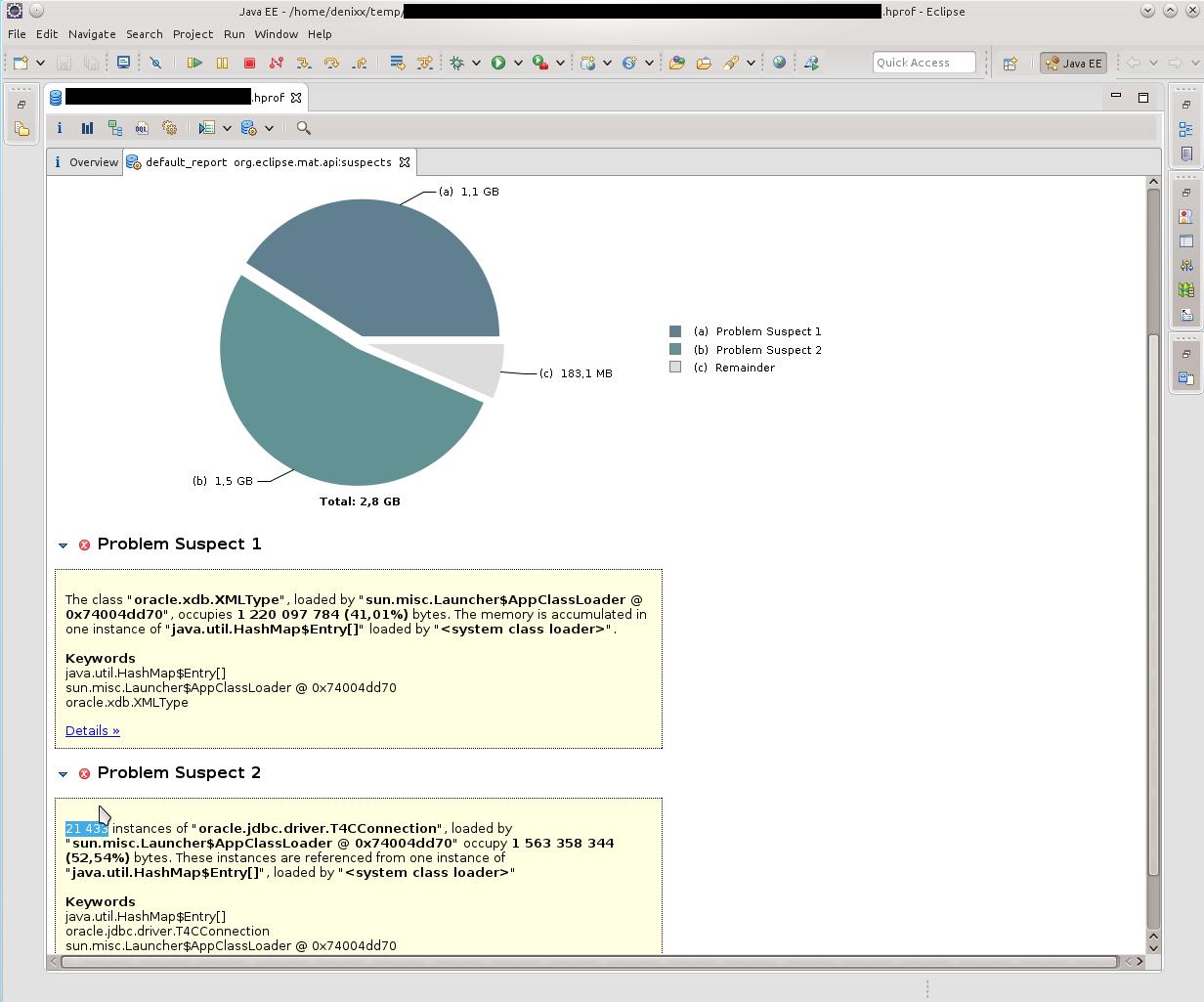 私が最初に目にしたのは、「記憶にたくさんの接続が残っている」ことでした。 21k !!!また、興味深いoracle.xdb.XMLTypeも熱を与えました。 「しかし、これはオラクルです!」、私の頭の中で回った。先を見て、はい、彼は責任があると言います。
私が最初に目にしたのは、「記憶にたくさんの接続が残っている」ことでした。 21k !!!また、興味深いoracle.xdb.XMLTypeも熱を与えました。 「しかし、これはオラクルです!」、私の頭の中で回った。先を見て、はい、彼は責任があると言います。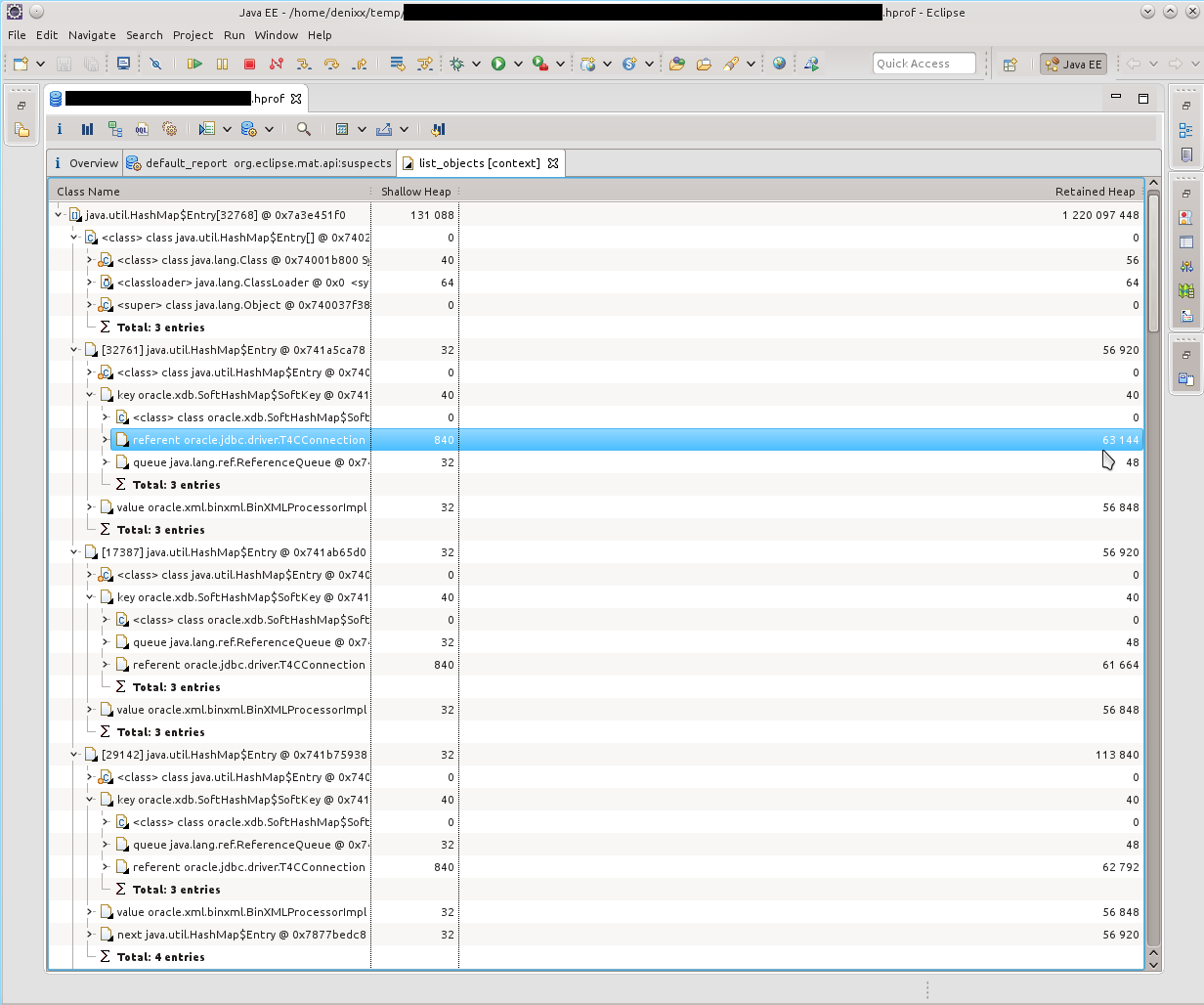 そのため、HashMap $ EntryにあるT4CConnectionの束を確認します。私はすぐにそれがSoftHashMapのように見えることに気付きました。これは、そのようなサイズに成長してはならないことを意味するはずです。しかし、結果は自分で確認できます-接続ごとに50〜60キロバイトで、実際にはたくさんあります。
そのため、HashMap $ EntryにあるT4CConnectionの束を確認します。私はすぐにそれがSoftHashMapのように見えることに気付きました。これは、そのようなサイズに成長してはならないことを意味するはずです。しかし、結果は自分で確認できます-接続ごとに50〜60キロバイトで、実際にはたくさんあります。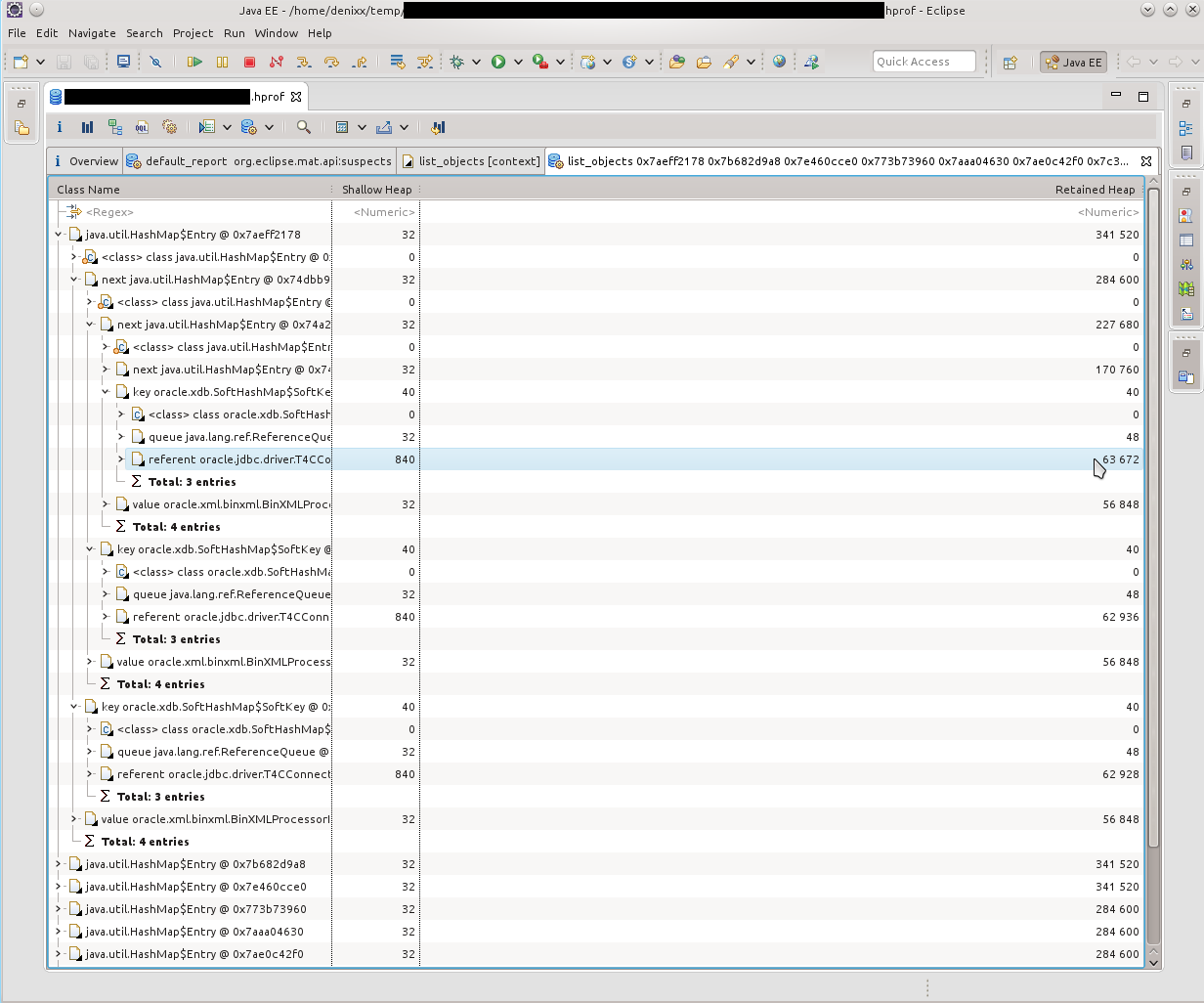 HashMap $ Entryとは何かを見てみると、写真はほぼ同じで、すべてがSoftHashMapとOracle接続で接続されていることがわかりました。
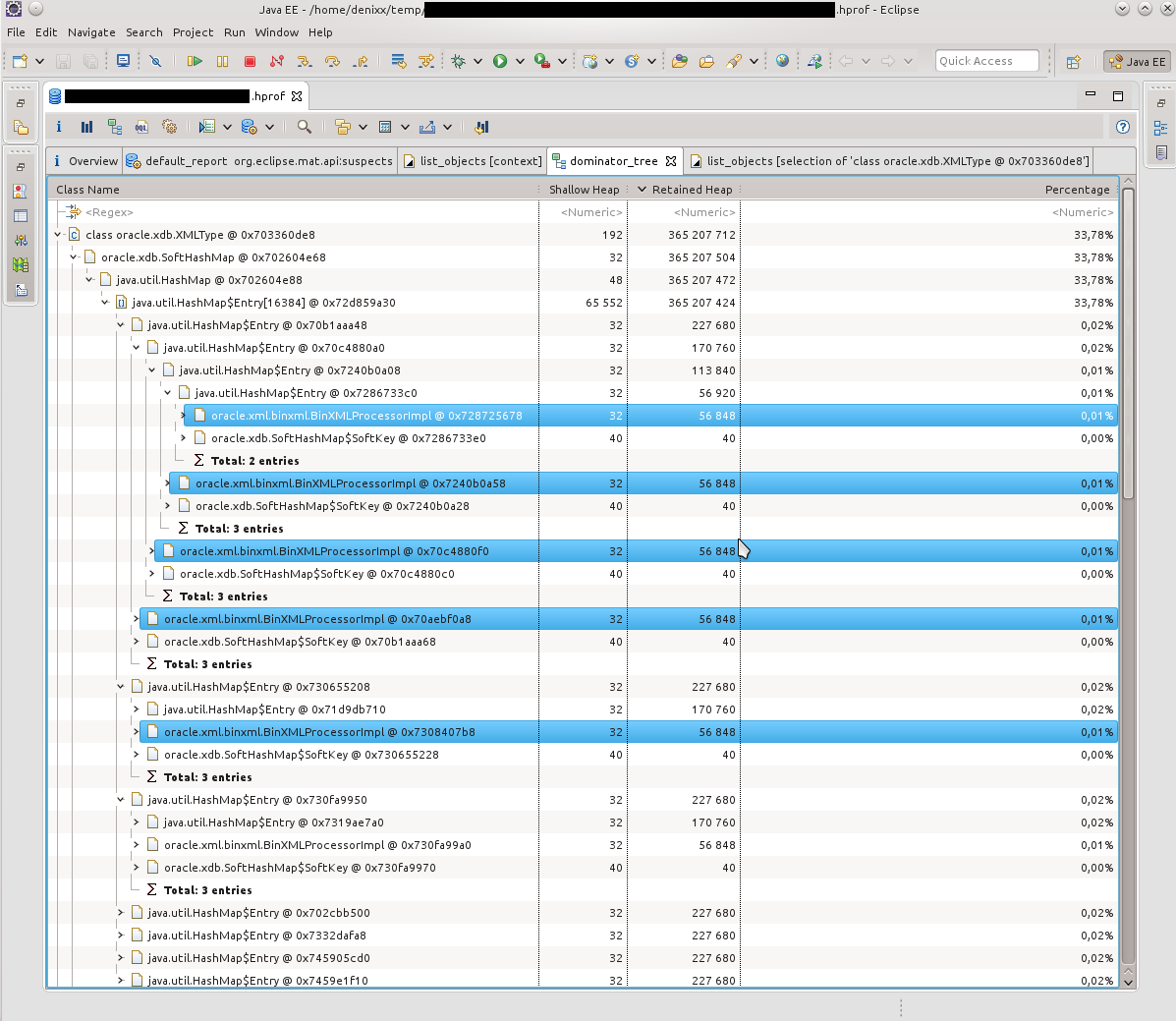
HashMap $ Entryとは何かを見てみると、写真はほぼ同じで、すべてがSoftHashMapとOracle接続で接続されていることがわかりました。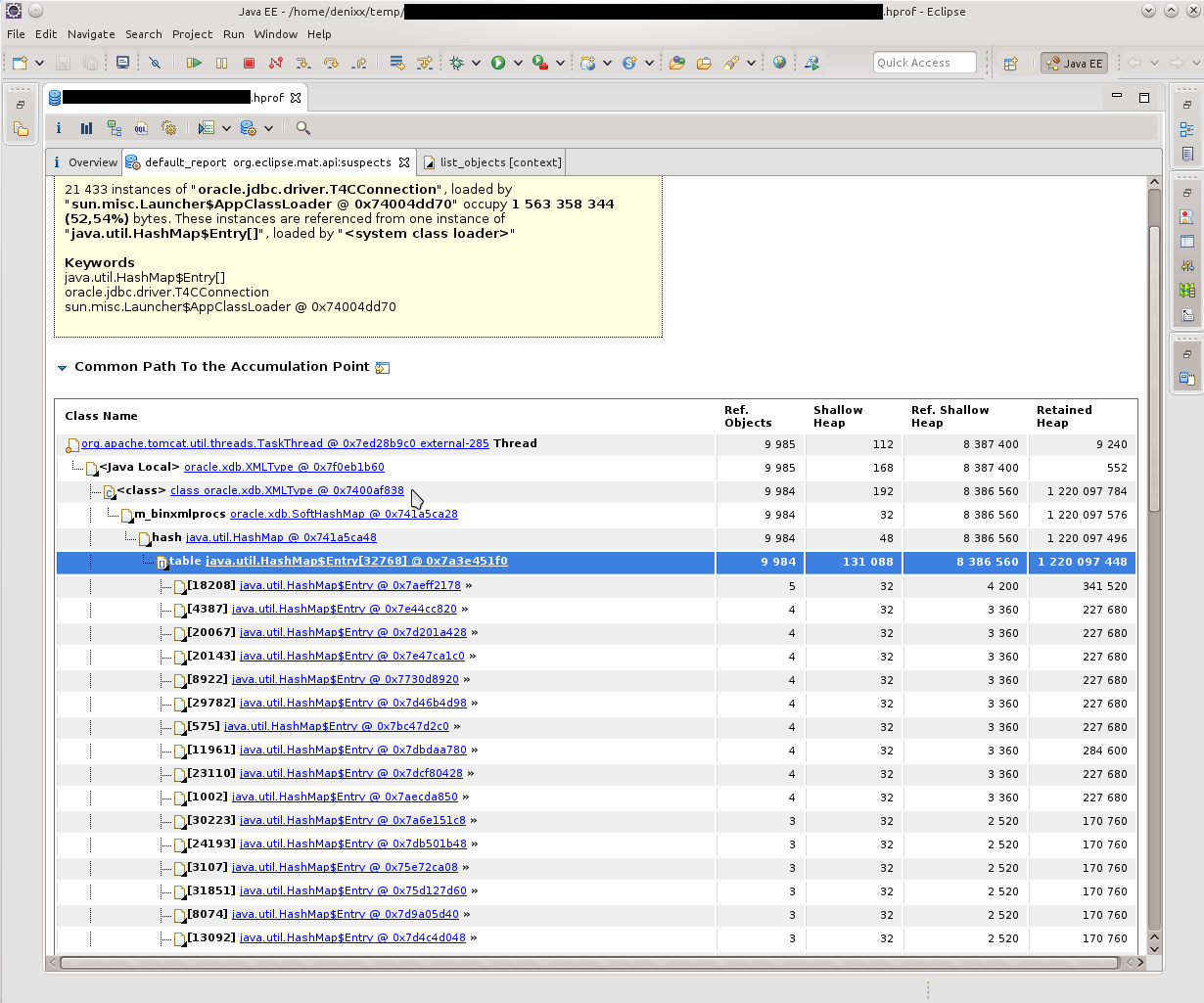 実際、それはそのような写真によって確認されました。 HashMap $ Entryは単なる海であり、それらは多かれ少なかれoracle.xdb.SoftHashMap内に蓄積されていました。次のダンプでは、写真はほぼ同じでした。ドミネーターツリーによると、各エントリ内にそのような重いBinXmlProcessorImplがあることが明らかでした。
実際、それはそのような写真によって確認されました。 HashMap $ Entryは単なる海であり、それらは多かれ少なかれoracle.xdb.SoftHashMap内に蓄積されていました。次のダンプでは、写真はほぼ同じでした。ドミネーターツリーによると、各エントリ内にそのような重いBinXmlProcessorImplがあることが明らかでした。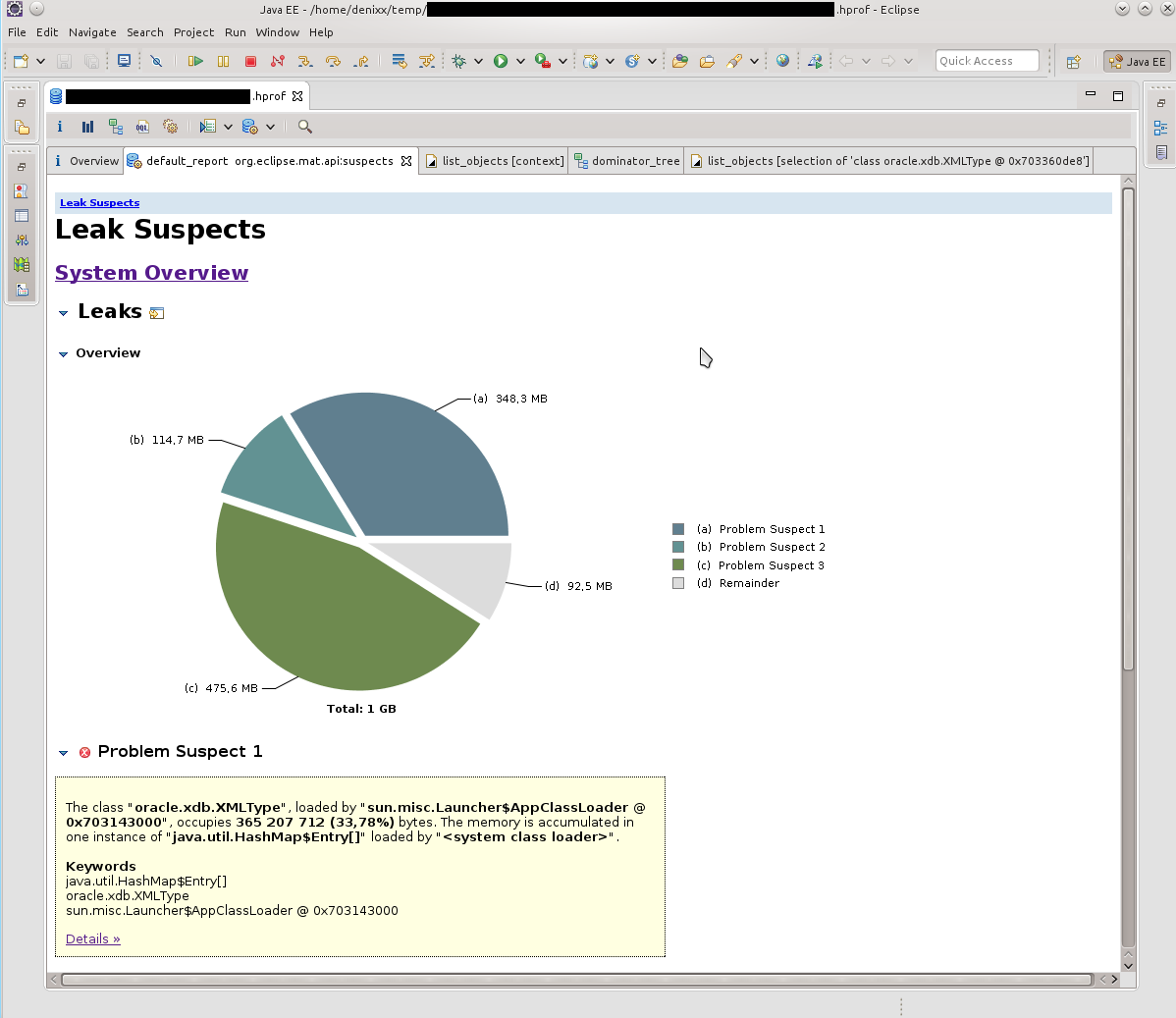
 -=-=-その瞬間、私はxdbが何であり、XMLとどのように関連しているかに強くなかったので、やや混乱して、グーグルするべきだと決めました。これらすべてをどうするかを知っています。そして本能がだまされていない、要求に応じて«oracle.xdb.SoftHashMap T4CConnection»が見つかりました。時間piotr.bzdyl.net/2014/07/memory-leak-in-oracle-softhashmap.htmlと2 leakfromjavaheap.blogspot.com/2014/02/をmemory-leak-detection-in-real-life.htmlOracleにはまだ妨害が残っていることを確認したが、問題は小さいままでした。検出された問題に関する情報を確認するようDBAに依頼しました。
-=-=-その瞬間、私はxdbが何であり、XMLとどのように関連しているかに強くなかったので、やや混乱して、グーグルするべきだと決めました。これらすべてをどうするかを知っています。そして本能がだまされていない、要求に応じて«oracle.xdb.SoftHashMap T4CConnection»が見つかりました。時間piotr.bzdyl.net/2014/07/memory-leak-in-oracle-softhashmap.htmlと2 leakfromjavaheap.blogspot.com/2014/02/をmemory-leak-detection-in-real-life.htmlOracleにはまだ妨害が残っていることを確認したが、問題は小さいままでした。検出された問題に関する情報を確認するようDBAに依頼しました。xxx: : SoftHashMap XMLType
yyy: Bug 17537657 Memory leak from XDB in oracle.xdb.SoftHashMap
yyy: The fix for 17537657 is first included in
12.2 (Future Release)
12.1.0.2 (Server Patch Set)
12.1.0.1.4 Database Patch Set Update
12.1.0.1 Patch 11 on Windows Platforms
yyy: . 説明
説明
When calling either getDocument() using the thin driver, or getBinXMLStream()
using any driver, memory leaks occur in the oracle.xdb.SoftHashMap class.
BinXMLProcessorImpl classes accumulate in this SoftHashMap, but are never
removed.
xxx: :)
修正の説明は次のとおりです。updates.oracle.com / Orion / Services / download?type = readme&aru = 18629243(アクセスにはOracleのアカウントが必要です)。-=-=-修正プログラムの適用後、アプリケーションのインスタンスは1か月間、これまでは過剰に使用されていません。*木材をタップ* *左肩にスパッツ*検索で頑張ってください!