このチュートリアルについて
このチュートリアルは、SQL言語(DDL、DML)の「記憶のスタンプ」のようなものです。 これは、専門的な活動の過程で蓄積された情報であり、常に私の頭の中に保存されています。 これは私にとって十分な最小値であり、データベースを操作するときに最もよく使用されます。 より完全なSQL構造を使用する必要がある場合は、通常、インターネット上のMSDNライブラリに助けを求めます。 私の意見では、すべてを頭の中に収めることは非常に難しく、これは特に必要ありません。 しかし、基本的な構造を知ることは非常に便利です。 Oracle、MySQL、Firebirdなど、多くのリレーショナルデータベースでほぼ同じ形式で適用できます。 違いは主にデータタイプにあり、詳細は異なる場合があります。 SQL言語の基本的な構造はそれほど多くはなく、絶えず練習すればすぐに記憶されます。 たとえば、オブジェクト(テーブル、制約、インデックスなど)を作成するには、データベースを操作する環境(IDE)のテキストエディターがあれば十分であり、特定のタイプのデータベース(MS SQLを操作するために調整されたビジュアルツールを調べる必要はありません、Oracle、MySQL、Firebird、...)。 すべてのテキストが目の前にあり、たとえばインデックスや制約を作成するために多数のタブを実行する必要がないため、これは便利です。 データベースとの絶え間ない作業により、スクリプトを使用してオブジェクトを作成、変更、特に再作成することは、ビジュアルモードで行う場合よりも何倍も高速です。 また、スクリプトモードでも(それぞれ、慎重に)、オブジェクトの命名規則を設定および制御する方が簡単です(私の主観的な意見)。 さらに、スクリプトは、1つのデータベース(たとえば、テストデータベース)で行われた変更を同じ形式で別のデータベースに転送する必要がある場合(生産的)に使用すると便利です。
SQL言語はいくつかの部分に分かれています。ここでは、最も重要な2つの部分を検討します。
- DDL-データ定義言語
- DML-データ操作言語。次の構成要素が含まれます。
- SELECT-データ選択
- INSERT-新しいデータを挿入します
- 更新-データ更新
- DELETE-データ削除
- MERGE-データのマージ
なぜなら 私は実務家なので、この教科書には理論がほとんどないので、すべての構成は実際的な例で説明します。 さらに、プログラミング言語、特にSQLは、自分でそれを感じ、特定の構成を実行したときに何が起こるかを理解することによって、実際にのみ習得できると信じています。
このチュートリアルは、ステップバイステップの原則に基づいて作成されています。 それを順番に、そしてできれば例の直後に読むことが必要です。 ただし、途中でチームについてさらに詳しく知る必要がある場合は、MSDNライブラリなど、インターネットで特定の検索を使用してください。
このチュートリアルを書くときは、MS SQL Serverバージョン2014データベースを使用しましたが、スクリプトにはMS SQL Server Management Studio(SSMS)を使用しました。
MS SQL Server Management Studio(SSMS)について簡単に説明します
SQL Server Management Studio(SSMS)は、データベースコンポーネントを構成、管理、および管理するためのMicrosoft SQL Serverのユーティリティです。 このユーティリティには、スクリプトエディター(主に使用します)と、オブジェクトおよびサーバー設定で動作するグラフィカルプログラムが含まれています。 SQL Server Management Studioのメインツールはオブジェクトエクスプローラーで、ユーザーはサーバーオブジェクトを表示、取得、管理できます。 このテキストはウィキペディアから部分的に借りています。
新しいスクリプトエディターを作成するには、[新しいクエリ]ボタンを使用します。
現在のデータベースを変更するには、ドロップダウンリストを使用できます。
特定のコマンド(またはコマンドのグループ)を実行するには、そのコマンドを選択して[実行]ボタンまたは[F5]キーを押します。 エディターに現在コマンドが1つしか含まれていない場合、またはすべてのコマンドを実行する必要がある場合は、何も選択する必要はありません。
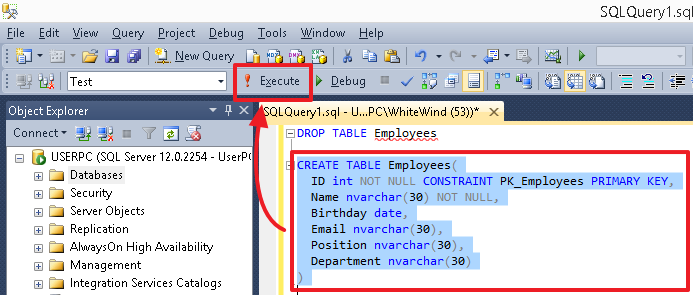
スクリプト(特にオブジェクト(テーブル、列、インデックス)の作成)を実行した後、変更を確認するには、コンテキストメニューから更新を使用して、対応するグループ(テーブルなど)、テーブル自体、またはその中の列グループを強調表示します。

実際、ここに挙げた例を完了するために知っておく必要があるのはそれだけです。 SSMSユーティリティの残りの部分は、自分で簡単に習得できます。
理論のビット
リレーショナルデータベース(RDB、または単にDBのコンテキストでは以下)は、相互接続されたテーブルのコレクションです。 大まかに言うと、データベースとは、データが構造化された形式で保存されているファイルです。
DBMS-これらのデータベースの管理システム、つまり 特定のタイプのデータベース(MS SQL、Oracle、MySQL、Firebirdなど)を操作するためのツールのセットです。
ご注意
なぜなら 人生では、口語で「Oracle DB」、または実際には「Oracle DBMS」を意味する「Oracle」とさえ言われますが、このチュートリアルの文脈では「DB」という用語が時々使用されます。 コンテキストから、私はそれが正確に何を意味するのかが明確になると思います。
テーブルは列のコレクションです。 列はフィールドまたは列とも呼ばれ、これらのすべての単語は同じものを表す同義語として使用されます。
テーブルはRDBのメインオブジェクトであり、すべてのDBDデータはテーブルの列に1行ずつ保存されます。 行、レコードも同義語です。
各テーブルとその列に名前が付けられ、その後、それらにアクセスされます。
MS SQLのオブジェクトの名前(テーブル名、列名、インデックス名など)の最大長は128文字です。
参考 -ORACLEデータベースでは、オブジェクトの名前の最大長は30文字です。 したがって、特定のデータベースでは、文字数の制限を満たすために、オブジェクトの命名規則を独自に作成する必要があります。
SQLは、DBMSを介してデータベースでクエリを実行できるようにする言語です。 特定のDBMSでは、SQL言語に特定の実装(独自の方言)を持たせることができます。
DDLとDMLはSQL言語のサブセットです。
- DDL言語は、データベースの構造を作成および変更するために使用されます。 テーブルとリレーションシップを作成/変更/削除します。
- DML言語を使用すると、テーブルデータを操作できます。 彼女のラインで。 テーブルからデータを選択したり、テーブルに新しいデータを追加したり、既存のデータを更新および削除したりできます。
SQLでは、2種類のコメント(単一行と複数行)を使用できます。
そして
実際、これの理論に関するすべてで十分です。
DDL-データ定義言語
たとえば、プログラマーではない人の通常の形式で従業員に関するデータを含むテーブルを考えてみましょう。
| 従業員番号 | 氏名 | 生年月日 | 電子メール | 役職 | 部門 |
|---|
| 1000 | イワノフI.I. | 1955年2月19日 | i.ivanov@test.tt | 監督 | 運営 |
| 1001 | ペトロフP.P. | 1983年12月3日 | p.petrov@test.tt | プログラマー | IT |
| 1002 | シドロフS.S. | 1976/07/07 | s.sidorov@test.tt | 会計士 | 簿記 |
| 1003 | アンドレエフA.A. | 1982年4月17日 | a.andreev@test.tt | 上級プログラマー | IT |
この場合、テーブルの列には次の名前があります:従業員番号、名前、生年月日、電子メール、役職、部門。
これらの各列は、含まれるデータのタイプによって特徴付けられます。
- 従業員番号は整数です
- 名前-文字列
- 生年月日-日付
- メール-文字列
- 位置-ライン
- 部門-ライン
列タイプは、特定の列が格納できるデータの種類を示す特性です。
まず、MS SQLで使用される次の基本データ型のみを覚えておけば十分です。
| 価値 | MS SQLでの指定 | 説明 |
|---|
| 可変長文字列 | varchar(N)
そして
nvarchar(N)
| 数値Nを使用して、対応する列の可能な最大行長を指定できます。 たとえば、「名前」列の値に最大30文字を含めることができる場合は、nvarchar(30)に設定する必要があります。
varcharとnvarcharの違いは、varcharを使用すると、1文字が1バイトのASCII形式で文字列を保存でき、各文字が2バイトのUnicode形式で文字列を保存できることです。
varchar型は、このフィールドにUnicode文字を保存する必要がないことが100%確実な場合にのみ使用してください。 たとえば、varcharは次のように電子メールアドレスを保存するために使用できます。 通常、ASCII文字のみが含まれます。
|
| 固定長ストリング | char(N)
そして
nchar(N)
| このタイプは可変長ストリングと異なり、ストリングの長さがN文字より短い場合、常にスペースで長さNに埋め込まれ、この形式でデータベースに保存されます。 データベースでは、正確にN文字を使用します(1文字はcharに1バイト、nchar型に2バイトを使用します)。 私の練習では、このタイプはめったに使用されず、使用される場合、主にchar(1)形式で使用されます。 フィールドが1文字で定義されている場合。 |
| 整数 | int | このタイプでは、列に正と負の整数のみを使用できます。 参照用(今ではこれはあまり関係ありません)--2 147 483 648から2 147 483 647までのint型を許可する数値の範囲。通常、これは識別子を設定するために使用される主な型です。 |
| 実数または実数 | 浮く | 簡単に言えば、これらは小数点(コンマ)が存在できる数値です。 |
| 日付 | 日付 | 列に日付のみを格納する必要がある場合は、日付、月、年の3つのコンポーネントで構成されます。 たとえば、2014年2月15日(2014年2月15日)。 このタイプは、「入学日」、「生年月日」などの列に使用できます。 日付のみを修正することが重要である場合、または時刻コンポーネントが重要ではなく破棄できる場合、または不明な場合。 |
| 時間 | 時間 | このタイプは、時間データのみを列に格納する必要がある場合に使用できます。 時間、分、秒、ミリ秒。 たとえば、17:38:31.3231603
たとえば、毎日のフライト出発時刻。
|
| 日時 | 日時 | このタイプでは、日付と時刻の両方を同時に保存できます。 たとえば、02.15.2014 17:38:31.323
たとえば、これはイベントの日付と時刻です。
|
| 旗 | 少し | このタイプは、「はい」/「いいえ」タイプの値を保存するのに便利です。「はい」は1として保存され、「いいえ」は0として保存されます。 |
また、フィールドの値は、禁止されていない場合は示されていない可能性があり、この目的にはNULLキーワードが使用されます。
サンプルを実行するには、Testというテストデータベースを作成します。
次のコマンドを実行することにより、単純なデータベース(追加のパラメーターを指定せずに)を作成できます。
CREATE DATABASE Test
コマンドを使用してデータベースを削除できます(このコマンドには非常に注意する必要があります)。
DROP DATABASE Test
データベースに切り替えるには、次のコマンドを実行できます。
USE Test
または、SSMSメニュー領域のドロップダウンリストからテストデータベースを選択します。 私と一緒に仕事をするとき、データベースを切り替えるこの方法が最もよく使用されます。
データベースで、スペースとキリル文字を使用して、フォームの説明をそのまま使用してテーブルを作成できます。
CREATE TABLE []( [ ] int, [] nvarchar(30), [ ] date, [E-mail] nvarchar(30), [] nvarchar(30), [] nvarchar(30) )
この場合、角括弧で名前を囲む必要があります[...]。
ただし、データベースでは、利便性を高めるために、オブジェクトのすべての名前をラテンアルファベットで指定し、名前にスペースを使用しない方が適切です。 MS SQLでは、通常この場合、各単語は大文字で始まります。たとえば、「Personnel number」フィールドでは、PersonnelNumberという名前を設定できます。 名前に番号を使用することもできます(例:PhoneNumber1)。
ご注意
一部のDBMSでは、次のPHONE_NUMBER命名形式が望ましい場合があります。たとえば、この形式はORACLEデータベースでよく使用されます。 当然、フィールド名を設定するときは、DBMSで使用されるキーワードと一致しないことが望ましいです。
このため、角括弧で囲まれた構文を忘れて、[Employees]テーブルを削除できます。
DROP TABLE []
たとえば、従業員を含むテーブルは「従業員」と呼ばれ、そのフィールドには次の名前を付けることができます。
- ID-従業員番号(従業員識別子)
- 名前-名前
- 誕生日-生年月日
- メール-メール
- 位置-位置
- 部門-部門
多くの場合、IDフィールドの名前にはIDという単語が使用されます。
テーブルを作成します。
CREATE TABLE Employees( ID int, Name nvarchar(30), Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
必要な列を指定するには、NOT NULLオプションを使用できます。
既存のテーブルの場合、次のコマンドを使用してフィールドを再定義できます。
ご注意
SQL言語の一般的な概念は、ほとんどのDBMSで同じです(少なくとも、これまでに作業したDBMSで判断できます)。 さまざまなDBMSのDDLの違いは主にデータ型にあり(名前だけでなく、実装の詳細も異なる)、SQL言語実装の仕様もわずかに異なる場合があります(つまり、コマンドの本質は同じですが、しかし、方言にはわずかな違いがあるかもしれませんが、標準はありません)。 SQLの基本を所有しているため、1つのDBMSから別のDBMSに簡単に切り替えることができます。 この場合、新しいDBMSでのコマンドの実装の詳細、つまり ほとんどの場合、類似性を引き出すだけで十分です。
根拠がないように、ORACLE DBMSの同じコマンドの例をいくつか示します。
ORACLEの場合、varchar2タイプの実装に関して違いがあります;エンコーディングはデータベース設定に依存し、テキストは、たとえばUTF-8エンコーディングで保存できます。 さらに、ORACLEのフィールド長は、バイトと文字の両方で指定できます。この追加オプションでは、BYTEとCHARが使用されます。これらは、フィールド長の後に示されます。たとえば、次のようになります。
NAME varchar2(30 BYTE)
ORACLEのvarchar2(30)の単純な指示の場合、デフォルトでBYTEまたはCHARのどちらが使用されるかは、データベース設定に依存し、IDE設定で指定されることもあります。 一般的に、混乱することがあるので、ORACLEの場合、varchar2型を使用すると(たとえば、UTF-8エンコードを使用する場合にこれが正当化されることがあります)、明示的にCHARを記述することを好みます(通常、文字列の長さを文字で読み取る方が便利です) )
ただし、この場合、テーブルに既にデータがある場合、コマンドを正常に実行するには、テーブルのすべての行でIDフィールドと名前フィールドに入力する必要があります。 これを例で示し、ID、Position、Departmentフィールドのデータをテーブルに挿入します。これは次のスクリプトで実行できます。
INSERT Employees(ID,Position,Department) VALUES (1000,N'',N''), (1001,N'',N''), (1002,N'',N''), (1003,N' ',N'')
この場合、INSERTコマンドもエラーをスローします。 貼り付けるときに、必要な[名前]フィールドの値を指定しませんでした。
元のテーブルにこのデータが既にある場合、ALTER TABLE Employees ALTER COLUMN ID int NOT NULLコマンドは成功し、ALTER TABLE Employees ALTER COLUMN Name int NOT NULLコマンドはエラーメッセージを発行しました。 NameフィールドにNULL(指定されていない)値があること。
[名前]フィールドに値を追加し、データを再入力します。
INSERT Employees(ID,Position,Department,Name) VALUES (1000,N'',N'',N' ..'), (1001,N'',N'',N' ..'), (1002,N'',N'',N' ..'), (1003,N' ',N'',N' ..')
また、新しいテーブルを作成するときにNOT NULLオプションを直接使用できます。 CREATE TABLEコマンドのコンテキストで。
まず、次のコマンドを使用してテーブルを削除します。
DROP TABLE Employees
次に、必要な列IDと名前を持つテーブルを作成します。
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
列名の後にNULLを書き込むこともできます。これは、NULL値(指定なし)が許可されることを意味しますが、この特性はデフォルトで想定されるため、これは必要ありません。
既存の列をオプションにする場合は、次のコマンド構文を使用する必要があります。
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NULL
または単に:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30)
また、このコマンドを使用して、フィールドのタイプを別の互換性のあるタイプに変更したり、フィールドの長さを変更したりできます。 たとえば、[名前]フィールドを50文字に拡張してみましょう。
ALTER TABLE Employees ALTER COLUMN Name nvarchar(50)
主キー
テーブルを作成するときは、各行に一意の一意の列または列のセットが必要です。このレコードは、この一意の値によって一意に識別できます。 この値は、テーブルの主キーと呼ばれます。 Employeesテーブルの場合、そのような一意の値はID列(「従業員の人事番号」を含む-この場合、この値は各従業員に対して一意であり、繰り返すことはできません)です。
次のコマンドを使用して、既存のテーブルへの主キーを作成できます。
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID)
ここで、「PK_Employees」は主キー制約の名前です。 通常、PK_プレフィックスを使用して主キーに名前を付け、その後にテーブル名を付けます。
主キーが複数のフィールドで構成されている場合、これらのフィールドは、カンマで区切られた括弧内にリストする必要があります。
ALTER TABLE _ ADD CONSTRAINT _ PRIMARY KEY(1,2,…)
MS SQLでは、主キーを入力するすべてのフィールドにNOT NULL特性が必要であることに注意してください。
また、主キーはテーブルの作成時に直接決定できます。 CREATE TABLEコマンドのコンテキストで。 テーブルを削除します。
DROP TABLE Employees
次に、次の構文を使用して作成します。
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30), CONSTRAINT PK_Employees PRIMARY KEY(ID)
作成後、データテーブルに入力します。
INSERT Employees(ID,Position,Department,Name) VALUES (1000,N'',N'',N' ..'), (1001,N'',N'',N' ..'), (1002,N'',N'',N' ..'), (1003,N' ',N'',N' ..')
表の主キーが1つの列の値のみで構成される場合、次の構文を使用できます。
CREATE TABLE Employees( ID int NOT NULL CONSTRAINT PK_Employees PRIMARY KEY,
実際、制限の名前を設定することはできません。その場合、システム名(「PK__Employee__3214EC278DA42077」など)が割り当てられます。
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30), PRIMARY KEY(ID) )
または:
CREATE TABLE Employees( ID int NOT NULL PRIMARY KEY, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
ただし、次のように、永続テーブルの制約名を常に明示的に設定することをお勧めします。 明示的に与えられ、理解可能な名前を付けると、その後で操作しやすくなります。たとえば、削除できます。
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
ただし、制限の名前を指定しないこのような短い構文は、一時データベーステーブル(一時テーブルの名前が#または##で始まる)を作成するときに便利に使用され、使用後に削除されます。
まとめると
現時点では、次のコマンドを確認しました。
- CREATE TABLE table_name(フィールドとそのタイプ、制限の列挙)-現在のデータベースに新しいテーブルを作成します。
- DROP TABLE table_name-現在のデータベースからテーブルを削除します。
- ALTER TABLE table_name ALTER COLUMN column_name ...-列タイプを更新したり、設定を変更したりします(たとえば、NULLまたはNOT NULL特性を指定します)。
- ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY (field1、field2、...)-既存のテーブルに主キーを追加します。
- ALTER TABLE table_name DROP CONSTRAINT constraint_name-テーブルから制約を削除します。
一時テーブルについて少し
MSDNからのクリッピング。 MS SQL Serverには、ローカル(#)とグローバル(##)の2種類の一時テーブルがあります。 ローカル一時テーブルは、SQL Serverインスタンスとのセッションが最初に作成されてすぐに完了するまで、作成者にのみ表示されます。 ユーザーがSQL Serverのインスタンスから切断すると、ローカル一時テーブルは自動的に削除されます。 グローバル一時テーブルは、これらのテーブルを作成した後の接続セッション中にすべてのユーザーに表示され、これらのテーブルを参照するすべてのユーザーがSQL Serverインスタンスから切断されると削除されます。
一時テーブルは、tempdbシステムデータベースに作成されます。 それらを作成する場合、メインデータベースを詰まらせません。それ以外の場合、一時テーブルは通常のテーブルと完全に同一であり、DROP TABLEコマンドを使用して削除することもできます。 多くの場合、ローカル(#)一時テーブルが使用されます。
一時テーブルを作成するには、CREATE TABLEコマンドを使用できます。
CREATE TABLE
MS SQLの一時テーブルは通常のテーブルに似ているため、DROP TABLEコマンド自体で適宜削除することもできます。
DROP TABLE
また、一時テーブル(および通常のテーブル)を作成し、SELECT ... INTO構文を使用して、クエリによって返されたデータをすぐに取り込むことができます。
SELECT ID,Name INTO
ご注意
DBMSによっては、一時テーブルの実装が異なる場合があります。 たとえば、ORACLEおよびFirebird DBMSでは、一時テーブルの構造は、その中のデータストレージの詳細を示すCREATE GLOBAL TEMPORARY TABLEコマンドを使用して事前に定義する必要があります。その後、ユーザーはメインテーブルでそれを確認し、通常のテーブルのように操作します。
DB正規化-サブテーブル(ハンドブック)への分割と関係の定義
現在のEmployeesテーブルには、たとえば1人の従業員と2人目の従業員に対して単に「IT」を示すことができるため、ユーザーが「Position」および「Department」フィールドにテキストを入力できるという欠点があります。 、「IT部門」、3番目の「IT」を入力します。 その結果、ユーザーが何を意味したか、つまり明確になりません。 これらの従業員は1つの部門の従業員ですか、それともユーザーが記述されており、これらは3つの異なる部門ですか? さらに、この場合、一部のレポートのデータを正しくグループ化できません。各部門のコンテキストで従業員数を表示する必要がある場合があります。
2番目の欠点は、この情報の保存量とその複製、つまり重複です。 従業員ごとに部門のフルネームが表示されます。これには、部門名の各キャラクターを格納するためのデータベース内の場所が必要です。
3番目の欠点は、たとえば、「Programmer」の位置を「Junior Programmer」に変更する必要がある場合など、投稿の名前が変更された場合にこれらのフィールドを更新するのが難しいことです。 この場合、Positionが「Programmer」に等しいテーブルの各行を変更する必要があります。
これらの欠点を回避するために、データベースのいわゆる正規化も使用されます-サブテーブル、参照テーブルにそれを粉砕します。 理論のジャングルに行って標準形が何であるかを研究する必要はありません;正規化の本質を理解するだけで十分です。
参照「Positions」と「Departments」の2つのテーブルを作成してみましょう。1つ目はPositions、2つ目はそれぞれDepartmentsと呼びます。
CREATE TABLE Positions( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY, Name nvarchar(30) NOT NULL ) CREATE TABLE Departments( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY, Name nvarchar(30) NOT NULL )
ここでは、新しいIDENTITYオプションを使用したことに注意してください。これは、ID列のデータに、1から始まり、1ずつ増分して自動的に番号が付けられることを示します。 新しいレコードを追加すると、値1、2、3などが順番に割り当てられます。 このようなフィールドは通常、自動インクリメントと呼ばれます。 テーブルにはIDENTITYプロパティを持つフィールドを1つだけ定義できます。通常は、必ずというわけではありませんが、このようなフィールドはこのテーブルの主キーです。
ご注意
さまざまなDBMSで、カウンタを使用したフィールドの実装は独自の方法で実行できます。 たとえば、MySQLでは、そのようなフィールドはAUTO_INCREMENTオプションを使用して定義されます。 ORACLEおよびFirebirdでは、以前はこの機能はシーケンス(SEQUENCE)を使用してエミュレートできました。 しかし、ORACLEの知る限りでは、オプションGENERATED AS IDENTITYが追加されました。
EmployeesテーブルのPositionフィールドとDepartmentフィールドに記録されている現在のデータに基づいて、これらのテーブルに自動的に入力しましょう。
Departmentsテーブルについても同じことを行います。 INSERT Departments(Name) SELECT DISTINCT Department FROM Employees WHERE Department IS NOT NULL
PositionsテーブルとDepartmentsテーブルを開くと、IDフィールドによって番号付きの値セットが表示されます。 SELECT * FROM Positions
| ID | お名前 |
|---|
| 1 | 会計士 |
| 2 | 監督 |
| 3 | プログラマー |
| 4 | 上級プログラマー |
SELECT * FROM Departments
これらのテーブルは、ジョブの割り当てと部門のディレクトリの役割を果たします。次に、投稿と部門の識別子を参照します。まず、Employeesテーブルに新しいフィールドを作成して、識別子データを保存します。
参照フィールドのタイプは、ディレクトリ内と同じである必要があります。この場合は、intです。また、1つのコマンドで複数のフィールドを一度にテーブルに追加して、コンマで区切られたフィールドをリストすることもできます。 ALTER TABLE Employees ADD PositionID int, DepartmentID int
次に、これらのフィールドのリンク(リンク制限-外部キー)を作成します。これにより、ユーザーは、ディレクトリ内のID値に含まれない値にデータをフィールドに書き込むことができなくなります。 ALTER TABLE Employees ADD CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID)
そして、2番目のフィールドにも同じことを行います。 ALTER TABLE Employees ADD CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
これで、ユーザーはこれらのフィールドに対応するディレクトリのID値のみを入力できます。したがって、新しい部門または役職を使用するには、まず適切なディレクトリに新しいエントリを追加する必要があります。なぜなら
役職と部門はディレクトリに1つのコピーで保存されるようになりました。名前を変更するには、ディレクトリ内でのみ変更するだけで十分です。参照制約の名前は通常、コンポジットであり、接頭辞「FK_」で構成されます。その後、テーブル名が続き、アンダースコアの後に参照テーブルの識別子を参照するフィールドの名前が続きます。識別子(ID)は通常、リレーションシップとそこに格納される値にのみ使用される内部値であり、ほとんどの場合、完全に無関心なので、レコードの削除後など、テーブルでの作業中に発生する一連の数字の穴を取り除く必要はありません参考書から。また、場合によっては、リンクをいくつかのフィールドに整理できます。 ALTER TABLE ADD CONSTRAINT _ FOREIGN KEY(1,2,…) REFERENCES _(1,2,…)
この場合、テーブル「reference_table」では、主キーはいくつかのフィールドの組み合わせで表されます(field1、field2、...)。実際、ここで、PositionIDフィールドとDepartmentIDフィールドをディレクトリのID値で更新します。この目的のDMLにはUPDATEコマンドを使用します。 UPDATE e SET PositionID=(SELECT ID FROM Positions WHERE Name=e.Position), DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department) FROM Employees e
リクエストを実行して何が起こったのか見てみましょう: SELECT * FROM Employees
| ID | お名前 | 誕生日 | メール | 役職 | 部門 | 位置ID | DepartmentID |
|---|
| 1000 | イワノフI.I. | ヌル | ヌル | 監督 | 運営 | 2 | 1 |
| 1001 | ペトロフP.P. | ヌル | ヌル | プログラマー | IT | 3 | 3 |
| 1002 | シドロフS.S. | ヌル | ヌル | 会計士 | 簿記 | 1 | 2 |
| 1003 | アンドレエフA.A. | ヌル | ヌル | 上級プログラマー | IT | 4 | 3 |
すべて、PositionIDおよびDepartmentIDフィールドには、EmployeesテーブルのPositionおよびDepartmentフィールドのポジションおよび部門の必要性の識別子が入力されています。これらのフィールドを削除できます。 ALTER TABLE Employees DROP COLUMN Position,Department
これで、テーブルは次のフォームを取得しました。 SELECT * FROM Employees
| ID | お名前 | 誕生日 | メール | 位置ID | DepartmentID |
|---|
| 1000 | イワノフI.I. | ヌル | ヌル | 2 | 1 |
| 1001 | ペトロフP.P. | ヌル | ヌル | 3 | 3 |
| 1002 | シドロフS.S. | ヌル | ヌル | 1 | 2 |
| 1003 | アンドレエフA.A. | ヌル | ヌル | 4 | 3 |
つまり
最終的には冗長な情報を保存する必要がなくなりました。これで、役職と部署の番号によって、参照テーブルの値を使用して一意に名前を決定できます。 SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName FROM Employees e LEFT JOIN Departments d ON d.ID=e.DepartmentID LEFT JOIN Positions p ON p.ID=e.PositionID
| ID | お名前 | PositionName | 部署名 |
|---|
| 1000 | イワノフI.I. | 監督 | 運営 |
| 1001 | ペトロフP.P. | プログラマー | IT |
| 1002 | シドロフS.S. | 会計士 | 簿記 |
| 1003 | アンドレエフA.A. | 上級プログラマー | IT |
オブジェクトインスペクターでは、このテーブルで作成されたすべてのオブジェクトを確認できます。ここから、これらのオブジェクトでさまざまな操作を実行することもできます-たとえば、オブジェクトの名前変更や削除。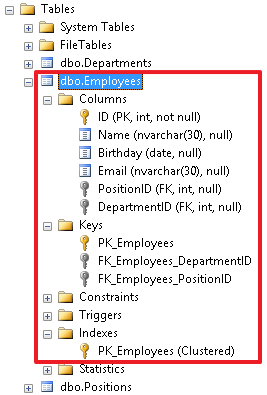 また、テーブルがそれ自体を参照できることにも注意してください。再帰リンクを作成できます。たとえば、従業員を含むテーブルに別のManagerIDフィールドを追加します。これは、この従業員が報告する従業員を示します。フィールドを作成します。
また、テーブルがそれ自体を参照できることにも注意してください。再帰リンクを作成できます。たとえば、従業員を含むテーブルに別のManagerIDフィールドを追加します。これは、この従業員が報告する従業員を示します。フィールドを作成します。 ALTER TABLE Employees ADD ManagerID int
このフィールドではNULL値を使用できますが、たとえば、優秀な従業員がいない場合、フィールドは空になります。次に、Employeesテーブルに外部キーを作成します。 ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
それでは、ダイアグラムを作成して、テーブル間の関係がどのように見えるかを見てみましょう。
 その結果、次の図が表示されます(EmployeesテーブルはPositionsテーブルとDepertmentsテーブルにリンクされ、自身も参照します):
その結果、次の図が表示されます(EmployeesテーブルはPositionsテーブルとDepertmentsテーブルにリンクされ、自身も参照します):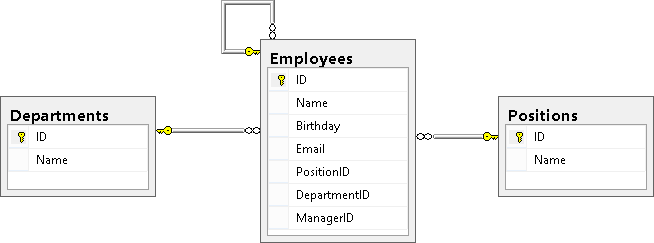 最後に、参照キー追加のオプションON DELETE CASCADEおよびON UPDATE CASCADEを含めることができます。これらのオプションは、参照テーブルで参照されているレコードを削除または更新するときの動作方法について説明します。これらのオプションが指定されていない場合、別のテーブルからのリンクを持つレコードのディレクトリテーブルのIDを変更することも、このレコードを参照するすべての行を削除するまでディレクトリからそのようなエントリを削除することもできません。ただし、これらの行のリンクを別の値に更新します。たとえば、FK_Employees_DepartmentIDのON DELETE CASCADEオプションを使用してテーブルを再作成します。
最後に、参照キー追加のオプションON DELETE CASCADEおよびON UPDATE CASCADEを含めることができます。これらのオプションは、参照テーブルで参照されているレコードを削除または更新するときの動作方法について説明します。これらのオプションが指定されていない場合、別のテーブルからのリンクを持つレコードのディレクトリテーブルのIDを変更することも、このレコードを参照するすべての行を削除するまでディレクトリからそのようなエントリを削除することもできません。ただし、これらの行のリンクを別の値に更新します。たとえば、FK_Employees_DepartmentIDのON DELETE CASCADEオプションを使用してテーブルを再作成します。 DROP TABLE Employees CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID) ON DELETE CASCADE, CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID) ) INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N' ..','19550219',2,1,NULL), (1001,N' ..','19831203',3,3,1003), (1002,N' ..','19760607',1,2,1000), (1003,N' ..','19820417',4,3,1000)
DepartmentsテーブルからID 3の部門を削除します。 DELETE Departments WHERE ID=3
Employeesテーブルのデータを見てみましょう。 SELECT * FROM Employees
| ID | お名前 | 誕生日 | メール | 位置ID | DepartmentID | マネージャーID |
|---|
| 1000 | イワノフI.I. | 1955-02-19 | ヌル | 2 | 1 | ヌル |
| 1002 | シドロフS.S. | 1976-06-07 | ヌル | 1 | 2 | 1000 |
ご覧のとおり、Employeesテーブルの部門3のデータも削除されています。ON UPDATE CASCADEオプションは同様に動作しますが、ディレクトリ内のID値を更新するときに機能します。たとえば、ジョブディレクトリのジョブIDを変更すると、EmployeesテーブルのDepartmentIDは、ディレクトリに設定した新しいID値に更新されます。しかし、この場合、これを実証することは単に機能しません。 DepartmentsテーブルのID列にはIDENTITYオプションがあり、次のクエリを実行できません(部門ID 3を30に変更)。 UPDATE Departments SET ID=30 WHERE ID=3
主なことは、これら2つのオプションON DELETE CASCADEおよびON UPDATE CASCADEの本質を理解することです。これらのオプションはめったに使用しないため、参照制約で指定する前に慎重に検討することをお勧めします。誤ってディレクトリテーブルからエントリを削除すると、大きな問題につながり、連鎖反応を引き起こす可能性があります。部門3を復元します。
TRUNCATE TABLEコマンドを使用して、Employeesテーブルを完全にクリアします。 TRUNCATE TABLE Employees
そして再び、前のINSERTコマンドを使用してデータをリロードします。 INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N' ..','19550219',2,1,NULL), (1001,N' ..','19831203',3,3,1003), (1002,N' ..','19760607',1,2,1000), (1003,N' ..','19820417',4,3,1000)
まとめると
現時点では、さらにいくつかのDDLコマンドが知識に追加されています。- フィールドにIDENTITYプロパティを追加-このフィールドをテーブルの自動入力(カウンターフィールド)にすることができます。
- ALTER TABLE _ ADD ___ – ;
- ALTER TABLE _ DROP COLUMN _ – ;
- ALTER TABLE _ ADD CONSTRAINT _ FOREIGN KEY () REFERENCES _() – .
– UNIQUE, DEFAULT, CHECK
UNIQUE制約を使用すると、特定のフィールドまたは一連のフィールドの各行の値は一意である必要があると言えます。Employeesテーブルの場合、Emailフィールドにそのような制限を課すことができます。値がまだ定義されていない場合のみ、メールに値を事前入力します。 UPDATE Employees SET Email='i.ivanov@test.tt' WHERE ID=1000 UPDATE Employees SET Email='p.petrov@test.tt' WHERE ID=1001 UPDATE Employees SET Email='s.sidorov@test.tt' WHERE ID=1002 UPDATE Employees SET Email='a.andreev@test.tt' WHERE ID=1003
そして今、あなたはこのフィールドに制約の一意性を課すことができます: ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
これで、ユーザーは複数の従業員から同じ電子メールを入力できなくなります。一意性制約は通常、次のように参照されます。最初に接頭辞「UQ_」、次にテーブル名が続き、アンダースコアの後にこの制限が課されるフィールドの名前があります。したがって、フィールドの組み合わせがテーブル行のコンテキストで一意でなければならない場合、それらをコンマで区切ってリストします。 ALTER TABLE _ ADD CONSTRAINT _ UNIQUE(1,2,…)
DEFAULT制約をフィールドに追加することにより、新しいレコードを挿入するときにこのフィールドがINSERTコマンドフィールドリストにリストされていない場合に置換されるデフォルト値を設定できます。この制限は、テーブルの作成時に直接設定できます。新しいフィールド「受取日」をテーブルEmployeesに追加してHireDateという名前を付け、このフィールドのデフォルト値が現在の日付になるとしましょう。 ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
または、HireDate列が既に存在する場合、次の構文を使用できます。 ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
ここでは、制限の名前を示しませんでした。DEFAULTの場合、これはそれほど重要ではないという意見がありました。しかし、あなたが良い方法でそれをするなら、私はあなたが怠beである必要はないと思うので、通常の名前を設定すべきです。これは次のように行われます。 ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
以前にそのような列がなかったため、各レコードに追加すると、現在の日付値がHireDateフィールドに挿入されます。もちろん、明示的に設定しない場合、つまり新しいレコードを追加するときに、現在の日付も自動的に挿入されます。列のリストで指定しないでください。追加された値のリストでHireDateフィールドを指定せずに、これを例で示しましょう。 INSERT Employees(ID,Name,Email)VALUES(1004,N' ..','s.sergeev@test.tt')
何が起こったのか見てみましょう: SELECT * FROM Employees
| ID | お名前 | 誕生日 | メール | 位置ID | DepartmentID | マネージャーID | 雇う |
|---|
| 1000 | イワノフI.I. | 1955-02-19 | i.ivanov@test.tt | 2 | 1 | ヌル | 2015-04-08 |
| 1001 | ペトロフP.P. | 1983-12-03 | p.petrov@test.tt | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | シドロフS.S. | 1976-06-07 | s.sidorov@test.tt | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | アンドレエフA.A. | 1982-04-17 | a.andreev@test.tt | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Sergeev S.S. | ヌル | s.sergeev@test.tt | ヌル | ヌル | ヌル | 2015-04-08 |
CHECKチェック制約は、フィールドに挿入された値をチェックする必要がある場合に使用されます。たとえば、従業員識別子(ID)である従業員番号フィールドにこの制限を課しています。この制限を使用して、従業員番号には1000〜1999の値が必要であると言います。 ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
通常、制限には同じ名前が付けられ、最初にプレフィックス「CK_」、次にテーブル名とこの制限が適用されるフィールドの名前が付けられます。無効なエントリを挿入して、制限が機能することを確認してみましょう(対応するエラーが表示されます)。 INSERT Employees(ID,Email) VALUES(2000,'test@test.tt')
挿入された値を1500に変更し、レコードが挿入されていることを確認します。 INSERT Employees(ID,Email) VALUES(1500,'test@test.tt')
名前を指定せずにUNIQUEおよびCHECK制約を作成することもできます。 ALTER TABLE Employees ADD UNIQUE(Email) ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
しかし、これは良い習慣ではなく、制限の名前を明示的に設定する方が良いです。後でより困難になるものを把握するには、オブジェクトを開いて、その原因を確認する必要があります。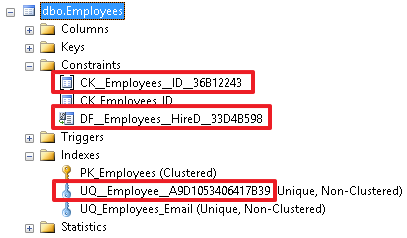 適切な名前を付けると、制限に関する多くの情報をその名前で直接見つけることができます。そして、それに応じて、テーブルがまだ存在しない場合は、テーブルを作成するときにこれらすべての制限をすぐに作成できます。テーブルを削除します。
適切な名前を付けると、制限に関する多くの情報をその名前で直接見つけることができます。そして、それに応じて、テーブルがまだ存在しない場合は、テーブルを作成するときにこれらすべての制限をすぐに作成できます。テーブルを削除します。 DROP TABLE Employees
そして、1つのCREATE TABLEコマンドによって作成されたすべての制限を使用して再作成します。 CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL DEFAULT SYSDATETIME(),
最後に、従業員のテーブルに挿入します。 INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES (1000,N' ..','19550219','i.ivanov@test.tt',2,1), (1001,N' ..','19831203','p.petrov@test.tt',3,3), (1002,N' ..','19760607','s.sidorov@test.tt',1,2), (1003,N' ..','19820417','a.andreev@test.tt',4,3)
PRIMARY KEYおよびUNIQUE制約を作成するときに作成されるインデックスについて少し
上記のスクリーンショットでわかるように、PRIMARY KEY制約とUNIQUE制約を作成すると、同じ名前(PK_EmployeesとUQ_Employees_Email)のインデックスが自動的に作成されました。デフォルトでは、主キーのインデックスはCLUSTEREDとして作成され、他のすべてのインデックスのインデックスはNONCLUSTEREDとして作成されます。クラスタインデックスの概念は、すべてのDBMSにあるわけではないことを言っておく価値があります。テーブルには、1つのクラスターインデックス(CLUSTERED)のみを含めることができます。 CLUSTERED-テーブルエントリがこのインデックスによってソートされることを意味します。また、このインデックスはテーブル内のすべてのデータに直接アクセスできると言うこともできます。これは、いわばテーブルのメインインデックスです。さらに大まかに言えば、これはテーブルにボルトで固定されたインデックスです。クラスタ化インデックスは、クエリの最適化に役立つ非常に強力なツールです。現時点では、これを覚えておいてください。言いたいならクラスターインデックスがプライマリキーではなく、別のインデックスに使用されるように、プライマリキーを作成するときに、NONCLUSTEREDオプションを指定する必要があります。 ALTER TABLE _ ADD CONSTRAINT _ PRIMARY KEY NONCLUSTERED(1,2,…)
たとえば、PK_Employees制限インデックスをクラスター化せず、UQ_Employees_Email制限インデックスをクラスター化しましょう。まず、これらの制限を削除します。 ALTER TABLE Employees DROP CONSTRAINT PK_Employees ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
次に、CLUSTEREDおよびNONCLUSTEREDオプションを使用してそれらを作成します。 ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID) ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
これで、Employeesテーブルからフェッチした後、エントリがUQ_Employees_Emailクラスターインデックスでソートされていることがわかります。 SELECT * FROM Employees
| ID | お名前 | 誕生日 | メール | 位置ID | DepartmentID | 雇う |
|---|
| 1003 | アンドレエフA.A. | 1982-04-17 | a.andreev@test.tt | 4 | 3 | 2015-04-08 |
| 1000 | イワノフI.I. | 1955-02-19 | i.ivanov@test.tt | 2 | 1 | 2015-04-08 |
| 1001 | ペトロフP.P. | 1983-12-03 | p.petrov@test.tt | 3 | 3 | 2015-04-08 |
| 1002 | シドロフS.S. | 1976-06-07 | s.sidorov@test.tt | 1 | 2 | 2015-04-08 |
これ以前は、PK_Employeesインデックスがクラスター化インデックスであった場合、レコードはデフォルトでIDフィールドでソートされていました。ただし、この場合、これはクラスターインデックスの本質を示す単なる例です。ほとんどの場合、EmployeesテーブルへのクエリはIDフィールドで行われ、場合によっては、ディレクトリ自体として機能することもあります。ディレクトリの場合、通常、クラスターインデックスは主キーに基づいて構築することをお勧めします。リクエストでは、ディレクトリの識別子を参照して、たとえば名前(役職、部署)を取得することがよくあります。ここで、クラスター化インデックスがテーブルの行に直接アクセスできることを上で書いたことを思い出してください。追加のオーバーヘッドなしで任意の列の値を取得できます。クラスタ化インデックスは、選択が最も頻繁に行われるフィールドに適用すると有益です。サロゲートフィールドのテーブルにキーが作成される場合があります。この場合、より適切なインデックスのCLUSTEREDインデックスオプションを保存し、サロゲート主キーを作成するときにNONCLUSTEREDオプションを指定すると便利です。まとめると
この段階で、「ALTER TABLE table_name ADD CONSTRAINT constraint_name ...」という形式のコマンドによって作成される、最も単純な形式のあらゆる種類の制約に遭遇しました。- 主キー -主キー。
- 外部キー -リンクの設定とデータの参照整合性の制御。
- 一意 -一意性を作成できます。
- CHECK-入力されたデータの正確性を考慮します。
- DEFAULT-デフォルト値を設定できます。
- また、すべての制限がコマンド«使用して除去することができることは注目に値するALTER TABLE文 table_nameのDROP CONSTRAINTの CONSTRAINT_NAMEを」。
我々はまた、部分的に解体インデックスとクラスタ概念(触れCLUSTERED)と非クラスタ(NONCLUSTERED)インデックス。カスタムインデックスの作成
独立とは、PRIMARY KEYまたはUNIQUEを制限するために作成されないインデックスを意味します。次のコマンドを使用して、フィールドごとのインデックスを作成できます。 CREATE INDEX IDX_Employees_Name ON Employees(Name)
ここでCLUSTERED、NONCLUSTERED、UNIQUEオプションを指定することもできます。また、個々のASCフィールド(デフォルト)またはDESCのソート方向を指定することもできます。 CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
非クラスター化インデックスを作成する場合、NONCLUSTEREDオプションは次のように解放できます。これはデフォルトで暗示されています。ここでは、コマンド内のCLUSTEREDまたはNONCLUSTEREDオプションの位置を示すために示されています。次のコマンドでインデックスを削除できます。 DROP INDEX IDX_Employees_Name ON Employees
制約などの単純なインデックスは、CREATE TABLEコマンドのコンテキストで作成できます。たとえば、テーブルを再度削除します。 DROP TABLE Employees
そして、作成されたすべての制限とインデックスを1つのCREATE TABLEコマンドで再作成します。 CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(), ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID), CONSTRAINT UQ_Employees_Email UNIQUE(Email), CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999), INDEX IDX_Employees_Name(Name) )
最後に、従業員のテーブルに挿入します。 INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES (1000,N' ..','19550219','i.ivanov@test.tt',2,1,NULL), (1001,N' ..','19831203','p.petrov@test.tt',3,3,1003), (1002,N' ..','19760607','s.sidorov@test.tt',1,2,1000), (1003,N' ..','19820417','a.andreev@test.tt',4,3,1000)
さらに、値をINCLUDEで指定することにより、値を非クラスター化インデックスに含めることができることに注意してください。 つまり
この場合、INCLUDEインデックスはクラスターインデックスに似ており、インデックスがテーブルにボルトで固定されず、必要な値がインデックスにボルトで固定されます。したがって、このようなインデックスは、クエリクエリ(SELECT)のパフォーマンスを大幅に向上させることができます。リストされたすべてのフィールドがインデックス内にある場合、おそらくテーブルにまったくアクセスする必要はありません。ただし、これにより、インデックスのサイズが自然に増加します。リストされたフィールドの値はインデックスで複製されます。MSDNからのクリッピング。インデックスを作成するための一般的な構文
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON <object> ( column [ ASC | DESC ] [ ,...n ] ) [ INCLUDE ( column_name [ ,...n ] ) ]
まとめると
インデックスを使用すると、データサンプリング(SELECT)の速度が向上しますが、インデックスを使用すると、テーブルデータの変更率が低下します。各変更後、システムは特定のテーブルのすべてのインデックスを再構築する必要があります。いずれの場合も、サンプルのパフォーマンスとデータの変更の両方が標準に達するように、最適なソリューションであるゴールデン平均を見つけることをお勧めします。インデックスとその数を作成するための戦略は、テーブル内のデータが変更される頻度など、多くの要因に依存します。DDLの結論
ご覧のとおり、DDL言語は、一見すると思えるほど複雑ではありません。ここでは、3つのテーブルだけで動作する基本構造のほぼすべてを表示できました。主なことは本質を理解することであり、残りは実践の問題です。SQLと呼ばれるこのすばらしい言語を学ぶのは幸運です。パート2-habrahabr.ru/post/255523