はじめにとDDL-データ定義言語
パート
1-habrahabr.ru/post/255361DML-データ操作言語
最初の部分では、MERGEコマンドを除き、ほぼすべてのコマンドセットを使用して、DML言語について少し触れました。
私自身の経験のシーケンスに従ってDMLについてお話します。 途中で、注目すべき「つるつるした」場所についても説明します。これらの「つるつるした」場所は、SQL言語の多くの方言で似ています。
なぜなら 教科書は(プログラマーだけでなく)幅広い読者層に当てられているため、説明が適切な場合があります。 長くて退屈です。 これは、専門的な活動の結果として実際に主に得られる資料に対する私のビジョンです。
このチュートリアルの主な目的は、SQL言語の本質を完全に理解し、その構造を正しく使用する方法を教えることです。 この分野の専門家は、この資料をめくることに興味があるかもしれません。多分彼らは自分自身のために何か新しいものを引き出すことができるか、記憶をリフレッシュするために読むだけで役立つかもしれません。 みんなが興味を持ってくれることを願っています。
なぜなら MS SQLデータベース方言のDMLは、SELECTコンストラクトの構文と非常に関連しているので、それからDMLについて話を始めます。 私の意見では、SELECTコンストラクトはDML言語の最も重要なコンストラクトです。 部品を犠牲にして、必要なデータがデータベースから選択されます。
DML言語には、次の構成要素が含まれています。
- SELECT-データ選択
- INSERT-新しいデータを挿入します
- 更新-データ更新
- DELETE-データ削除
- MERGE-データのマージ
このパートでは、次のようなSELECTコマンドの基本的な構文のみを検討します。
SELECT [DISTINCT] _ * FROM WHERE ORDER BY _
SELECTステートメントのトピックは非常に広範囲であるため、このパートではその基本的な構成のみに焦点を当てます。 基盤をよく知らないと、もっと複雑な構造を研究し始めることができないと思います。 その後、すべてがこの基本設計(サブクエリ、関連付けなど)を中心に展開されます。
また、このパートの一部として、TOPオファーについても説明します。 私は意図的にこの構文を基本的な構文で示しませんでした。 SQL言語の方言ごとに異なる方法で実装されます。
DDL言語がより静的な場合、つまり それを使用して、剛体構造(テーブル、リレーションシップなど)が作成され、DML言語は本質的に動的です。ここでは、さまざまな方法で正しい結果を得ることができます。
トレーニングは、ステップバイステップモードでも継続されます。 読むときは、すぐに自分の手で例を試してみてください。 結果の分析を行った後、直感的に理解してみてください。 たとえば、関数の値など、理解できないものが残っている場合は、インターネットに問い合わせてください。
例は、最初の部分でDDL + DMLを使用して作成されたテストデータベースに表示されます。
最初の部分でデータベースを作成しなかった人(誰もがDDL言語に興味があるわけではないため)には、次のスクリプトを使用できます。
これで、DML言語の学習を開始する準備が整いました。
SELECT-データサンプリング演算子
まず、アクティブなクエリエディターの場合、ドロップダウンリストで選択するか、USE Testコマンドを使用して、現在のテストデータベースを作成します。
SELECTの最も基本的な形式から始めましょう。
SELECT * FROM Employees
このクエリでは、Employeesテーブルからすべての列(これは「*」で示されます)を返すように求められます-「SELECT all_fields from the employees_table」として読み取ることができます。 クラスター化インデックスが存在する場合、返されるデータはほとんどの場合、ID列でソートされます(ただし、これはポイントではありません。ほとんどの場合、ORDER BY ...を使用して明示的にソートを指定するためです) :
| ID | お名前 | 誕生日 | メール | 位置ID | DepartmentID | 雇う | マネージャーID |
|---|
| 1000 | イワノフI.I. | 1955-02-19 | i.ivanov@test.tt | 2 | 1 | 2015-04-08 | ヌル |
| 1001 | ペトロフP.P. | 1983-12-03 | p.petrov@test.tt | 3 | 3 | 2015-04-08 | 1003 |
| 1002 | シドロフS.S. | 1976-06-07 | s.sidorov@test.tt | 1 | 2 | 2015-04-08 | 1000 |
| 1003 | アンドレエフA.A. | 1982-04-17 | a.andreev@test.tt | 4 | 3 | 2015-04-08 | 1000 |
一般に、MS SQLダイアレクトでは、最も単純な形式のSELECTクエリにはFROMブロックが含まれない場合があります。この場合、それを使用して値を取得できます。
SELECT 5550/100*15, SYSDATETIME(),
| (列名なし) | (列名なし) | (列名なし) |
|---|
| 825 | 2015-04-11 12:12:36.0406743 | 1 |
式(5550/100 * 15)の結果は825でしたが、計算機に頼ると値(832.5)が得られることに注意してください。 825の結果は、この式ではすべての数値が整数であるため、結果が整数であることが判明しました。 (5550/100)は(55.5)ではなく55を与えます。
MS SQLの次のロジックを思い出してください。
- 整数/整数=整数(つまり、この場合整数の除算が行われます)
- 実数/全体=実数
- 全体/リアル=リアル
つまり 結果はより大きな型に変換されるため、最後の2つのケースでは実数を取得します(数学のように、実数の範囲は整数の範囲より大きいため、結果はそれに変換されます)。
SELECT 123/10,
ここで(123.)=(123.0)、この場合は0を破棄でき、ポイントのみを残すことができます。
他の算術演算についても、同じロジックが適用されます。除算の場合は、このニュアンスがより適切です。
したがって、数値列のデータ型に注意してください。 その場合、全体であり、実際の結果を取得する必要がある場合は、変換を使用するか、定数(123.)として指定された数値の後にドットを配置します。
CASTまたはCONVERT関数を使用して、フィールドを変換できます。 たとえば、IDフィールドを使用します。タイプはintです。
SELECT ID, ID/100,
| ID | (列名なし) | (列名なし) | (列名なし) | (列名なし) |
|---|
| 1000 | 10 | 10 | 10 | 10.000000 |
| 1001 | 10 | 10.01 | 10.01 | 10.010000 |
| 1002 | 10 | 10.02 | 10.02 | 10.020000 |
| 1003 | 10 | 10.03 | 10.03 | 10.030000 |
メモへ。 ORACLEデータベースでは、FROMブロックのない構文は無効です;そこで、この目的のために、1行を含むDUALシステムテーブルが使用されます。
SELECT 5550/100*15,
ご注意 多くのRDBのテーブル名の前には、スキーマの名前を付けることができます。
SELECT * FROM dbo.Employees
スキーマは、独自の名前を持つデータベースの論理ユニットであり、テーブル、ビューなどのデータベースオブジェクトをグループ化できます。
異なるデータベースのスキーマの定義は異なる場合があります。スキーマがデータベースのユーザーに直接関連している場合、つまり この場合、スキームとユーザーは同義語であり、スキームで作成されるすべてのオブジェクトは基本的にこのユーザーのオブジェクトであると言えます。 MS SQLでは、スキーマは独立して作成できる独立した論理ユニットです(CREATE SCHEMAを参照)。
デフォルトでは、dbo(データベース所有者)と呼ばれるMS SQLデータベースに単一のスキーマが作成され、作成されたすべてのオブジェクトはデフォルトでこのスキーマに作成されます。 したがって、クエリでテーブルの名前を単に指定すると、現在のデータベースのdboスキーマで検索されます。 特定のスキーマでオブジェクトを作成する場合、オブジェクトの名前の前にスキーマの名前を付ける必要もあります(例:「CREATE TABLE schema_name.table_name(...)」)。
MS SQLの場合、スキーマ名の前に、指定されたスキーマが存在するデータベースの名前を付けることもできます。
SELECT * FROM Test.dbo.Employees
このような改良は、たとえば次の場合に役立ちます。
- 1つのリクエストで、異なるスキームまたはデータベースにあるオブジェクトを参照します
- あるスキーマまたはデータベースから別のスキーマまたはデータベースにデータを転送する必要があります
- 1つのデータベースにある場合、別のデータベースからデータを要求する必要があります
- など
スキーマは、データベースアーキテクチャ、特に大規模なデータベースを開発するときに使用すると便利な非常に便利なツールです。
また、リクエストのテキストでは、単一行の「-...」と複数行の「/ * ... * /」コメントの両方を使用できることを忘れないでください。 リクエストが大きく複雑な場合、コメントは、あなたや他の誰かが、しばらくして、その構造を覚えたり理解したりするのに大いに役立ちます。
テーブルに多くの列があり、特にテーブルにまだ多くの行がある場合、さらにネットワーク経由でデータベースにクエリを行う場合は、必要なフィールドをカンマで直接リストして選択することをお勧めします。
SELECT ID,Name FROM Employees
つまり ここでは、テーブルからIDとNameフィールドのみを返す必要があると言います。 結果は次のようになります(ところで、ここでオプティマイザーはNameフィールドによって作成されたインデックスを使用することにしました)。
| ID | お名前 |
|---|
| 1003 | アンドレエフA.A. |
| 1000 | イワノフI.I. |
| 1001 | ペトロフP.P. |
| 1002 | シドロフS.S. |
メモへ。 たとえば、どのインデックスが使用されているかを調べるなど、データのサンプリング方法を確認すると役立つ場合があります。 これは、「推定実行計画の表示-計算計画の表示」ボタンをクリックするか、「実際の実行計画を含める-結果にクエリ実行の実際の計画を含める」を設定した場合に実行できます:

実行計画の分析は、クエリの最適化に非常に役立ちます。どのインデックスが欠落しているか、またはどのインデックスがまったく使用されておらず削除できるかを見つけることができます。
DMLを習得し始めたばかりの場合は、それほど重要ではないので、メモを取り、安全に忘れることができます(これは役に立たないかもしれません)-私たちの最初の目標は、DML言語の基本を学び、正しく使用する方法を学ぶことです。最適化は別の技術です。 客観的な観点から正しい結果を返すクエリを手に持っているだけで、個々の人がすでに最適化に取り組んでいることがより重要な場合があります。 最初に、目標を達成するための手段を使用してクエリを正しく記述する方法を学習する必要があります。 ここで達成しなければならない主な目標は、クエリが正しい結果を返すことです。
テーブルのエイリアスを定義する
列をリストするとき、列の前にFROMブロックにあるテーブルの名前を付けることができます。
SELECT Employees.ID,Employees.Name FROM Employees
ただし、通常、この構文は使用するのに不便です。 テーブル名が長い場合があります。 これらの目的のために、通常、短い名前が指定および適用されます-エイリアス:
SELECT emp.ID,emp.Name FROM Employees AS emp
または
SELECT emp.ID,emp.Name FROM Employees emp
ここで、empは、このSELECTステートメントのコンテキストで使用できるEmployeesテーブルのエイリアスです。 つまり このSELECTステートメントのコンテキストでは、テーブルに新しい名前を付けたと言えます。
もちろん、この場合、クエリ結果は「SELECT ID、Name FROM Employees」とまったく同じになります。 これが必要な理由は(この部分でも)さらに理解されますが、現時点では、テーブル名が直接またはエイリアスを使用して列名の前に指定(指定)できることを覚えています。 ここでは、2つのうち1つを使用できます。 エイリアスを設定した場合、エイリアスを使用する必要がありますが、テーブル名は使用できなくなります。
メモへ。 ORACLEでは、ASキーワードなしでテーブルエイリアスを指定するオプションのみが許可されます。
DISTINCT-重複する行を削除する
DISTINCTキーワードは、クエリ結果から重複する行を削除するために使用されます。 大まかに言えば、最初にDISTINCTオプションなしでクエリが実行され、その後、すべての重複が結果からスローされると想像してください。 例を使用してより明確にするためにこれを示しましょう:
これは視覚的に次のようになります(すべての複製には同じ色のマークが付けられます)。
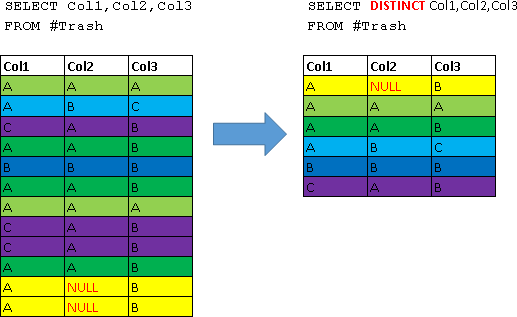
次に、より実用的な例を使用して、これを適用できる場所を見てみましょう-Employeesテーブルから部門の一意の識別子のみを返します(つまり、従業員が登録されている部門のIDを見つけます):
SELECT DISTINCT DepartmentID FROM Employees
ここに3行ありました。 1つの部門(IT)に2人の従業員がいます。
次に、どの部署でどの投稿が表示されるかを確認します。
SELECT DISTINCT DepartmentID,PositionID FROM Employees
ここでは4行になりました。 この表には重複した組み合わせ(DepartmentID、PositionID)はありません。
しばらくDDLに戻る
デモ例のデータが不足し始めているので、より広範囲かつ明確に説明したいので、Employessテーブルを少し拡張しましょう。 さらに、「繰り返しは学習の母です」と言っている小さなDDLを思い出します。もう一度、少し進んでUPDATEステートメントを適用しましょう。
データが正常に更新されたことを確認します。
SELECT * FROM Employees
| ID | お名前 | ... | 姓 | 名 | ミドルネーム | 給料 | ボーナスパーセント |
|---|
| 1000 | イワノフI.I. | | イワノフ | イワン | イバノビッチ | 5000 | 50 |
| 1001 | ペトロフP.P. | | ペトロフ | ピーター | ペトロビッチ | 1500 | 15 |
| 1002 | シドロフS.S. | | シドロフ | シドール | ヌル | 2500 | ヌル |
| 1003 | アンドレエフA.A. | | アンドレエフ | アンドレイ | ヌル | 2000年 | 30 |
クエリ列のエイリアスの定義
ここに書くよりもここに表示する方が簡単だと思います:
SELECT
| 氏名 | 入学日 | 生年月日 | Zp |
|---|
| イワノフイワンイワノビッチ | 2015-04-08 | 1955-02-19 | 5000 |
| ペトロフペトルペトロビッチ | 2015-04-08 | 1983-12-03 | 1500 |
| ヌル | 2015-04-08 | 1976-06-07 | 2500 |
| ヌル | 2015-04-08 | 1982-04-17 | 2000年 |
ご覧のとおり、設定した列エイリアスは結果のテーブルのヘッダーに反映されます。 実際、これが列エイリアスの主な目的です。
注意してください、 最後の2人の従業員にはミドルネーム(NULL値)がないため、式「LastName + '' + FirstName + '' + MiddleName」の結果もNULLを返しました。
MS SQLで文字列を接続(追加、連結)するには、「+」記号を使用します。
NULLが関係するすべての式(たとえば、NULLによる除算、NULLによる加算)はNULLを返すことに注意してください。
メモへ。
ORACLEの場合、||演算子は文字列を連結するために使用され、連結は「LastName ||」のようになります。 '|| FirstName ||' '|| MiddleName "。 ORACLEの場合、文字列型には例外があり、NULLと空の文字列 ''は同じであることに注意してください。したがって、ORACLEでは、この式は最後の2人の従業員に対してSidorov SidorとAndreyev Andreyを返します。 バージョンORACLE 12cの時点では、私の知る限り、この動作を変更するオプションはありません(正しくない場合は修正してください)。 ここで、これが良いか悪いかを判断するのは難しいです。なぜなら、 場合によっては、MS SQLのようにNULL文字列の動作がより便利であり、ORACLEのように他の場合に便利です。
ORACLEは、[...]を除く上記のすべての列エイリアスも受け入れます。
ISNULL関数を使用して構造を損傷しないようにするために、MS SQLではCONCAT関数を使用できます。 3つのオプションを検討して比較します。
SELECT LastName+' '+FirstName+' '+MiddleName FullName1,
| Fullname1 | Fullname2 | 氏名3 |
|---|
| イワノフイワンイワノビッチ | イワノフイワンイワノビッチ | イワノフイワンイワノビッチ |
| ペトロフペトルペトロビッチ | ペトロフペトルペトロビッチ | ペトロフペトルペトロビッチ |
| ヌル | シドロフ・シドール | シドロフ・シドール |
| ヌル | アンドレイエフアンドレイ | アンドレイエフアンドレイ |
MS SQLでは、等号を使用してエイリアスを指定できます。
SELECT ' '=HireDate,
ASキーワードまたは等号を使用してエイリアスを指定することは、おそらく好みの問題です。 しかし、他の人の要求を解析するとき、この知識は役に立ちます。
結論として、エイリアスについては、ラテン文字と数字のみを使用して名前を設定し、「...」、「...」、および[...]の使用を避けた方がよいと言います。つまり、テーブルに名前を付けるときに使用したのと同じルールを使用します。 さらに、例では、このような名前のみを使用し、「...」、「...」、[...]は使用しません。
基本的な算術SQLステートメント
| オペレーター | アクション |
|---|
| + | 加算(x + y)または単項プラス(+ x) |
| - | 減算(xy)または単項マイナス(-x) |
| * | 乗算(x * y) |
| / | 除算(x / y) |
| % | 除算の残り(x%y)。 たとえば、15%10は5になります |
算術演算子の優先順位は、数学と同じです。 必要に応じて、括弧を使用して演算子の適用順序を変更できます-(a + b)*(x /(yz))。
そしてもう一度、NULLを使用した操作がNULLを与えることを繰り返します。例えば、10 + NULL、NULL * 15 / 3、100 / NULL-これはすべてNULLになります。 つまり 単に不定の値を指定すると、明確な結果が得られません。 クエリのコンパイル時にこれを考慮し、必要に応じて、ISNULL、COALESCE関数を使用してNULL値を処理します。
SELECT ID,Name, Salary/100*BonusPercent AS Result1,
| ID | お名前 | 結果1 | 結果2 | 結果3 |
|---|
| 1000 | イワノフI.I. | 2500 | 2500 | 2500 |
| 1001 | ペトロフP.P. | 225 | 225 | 225 |
| 1002 | シドロフS.S. | ヌル | 0 | 0 |
| 1003 | アンドレエフA.A. | 600 | 600 | 600 |
| 1004 | ニコラエフN.N. | ヌル | 0 | 0 |
| 1005 | アレクサンドロフA.A. | ヌル | 0 | 0 |
COALESCE関数について少しお話しします。
COALESCE (expr1, expr2, ..., exprn) - NULL .
例:
SELECT COALESCE(f1, f1*f2, f2*f3) val
私は主にDML言語の構成要素に焦点を当てますが、ほとんどの場合、例で見られる関数については説明しません。 特定の関数の機能がわからない場合は、インターネットでその説明を探してください。たとえば、Google検索で「MS SQL文字列関数」、「MS SQL数学関数」、「MS SQL関数」などを指定して、関数グループの情報を直接検索することもできますNULL処理。」 関数に関する多くの情報があり、簡単に見つけることができます。 たとえば、MSDNライブラリでは、COALESCE関数について詳しく知ることができます。
COALESCEとCASEを比較したMSDNクリッピング
COALESCE式は、CASE式の構文ショートカットです。 これは、コードCOALESCE(expression1、... n)がクエリオプティマイザーによって次のCASE式として書き換えられることを意味します。
CASE WHEN (expression1 IS NOT NULL) THEN expression1 WHEN (expression2 IS NOT NULL) THEN expression2 ... ELSE expressionN END
たとえば、除算の残り(%)の使用方法を検討します。
この演算子は、レコードをグループに分割する場合に非常に便利です。たとえば、偶数の従業員番号(ID)を持つすべての従業員を引き出します。2で割り切れるID SELECT ID,Name FROM Employees WHERE ID%2=0
| ID | お名前 |
|---|
| 1000 | イワノフI.I. |
| 1004 | ニコラエフN.N. |
| 1002 | シドロフS.S. |
ORDER BY-クエリの結果の並べ替え
ORDER BY句は、クエリの結果をソートするために使用されます。 SELECT LastName, FirstName, Salary FROM Employees ORDER BY LastName,FirstName
| 姓 | 名 | 給料 |
|---|
| アンドレエフ | アンドレイ | 2000年 |
| イワノフ | イワン | 5000 |
| ペトロフ | ピーター | 1500 |
| シドロフ | シドール | 2500 |
ORDER BY句のフィールド名の後に、降順でこのフィールドを並べ替えるために使用されるDESCオプションを指定できます。 SELECT LastName,FirstName,Salary FROM Employees ORDER BY
| 姓 | 名 | 給料 |
|---|
| イワノフ | イワン | 5000 |
| シドロフ | シドール | 2500 |
| アンドレエフ | アンドレイ | 2000年 |
| ペトロフ | ピーター | 1500 |
ご注意ください。昇順の並べ替えにはASCキーワードがありますが、既定では昇順の並べ替えが使用されるため、このオプションを忘れることができます(このオプションを一度使用した場合は覚えていません)。
ORDER BY句では、SELECT句にリストされていないフィールドを使用できることに注意してください(DISTINCTを使用する場合を除き、このケースについては後述します)。たとえば、TOPオプションを使用して少し前に進み、たとえば、プライバシーの目的で給与自体を表示してはならないことを考慮して、給与が最も高い3人の従業員を選択する方法を示します。 SELECT TOP 3
| ID | 姓 | 名 |
|---|
| 1000 | イワノフ | イワン |
| 1002 | シドロフ | シドール |
もちろん、ここでは複数の従業員が同じ給与を持っている場合があり、この要求がどの特定の3人の従業員に返されるかを言うのは困難です。これはタスクディレクターで解決する必要があります。このタスクについてディレクターと話し合った後、次のオプションを使用することに同意し、決定したと仮定します-生年月日フィールドで追加のソートを実行します(つまり、私たちは行くのに長い道のりがあります)、そして複数の従業員の生年月日が一致する可能性がある場合除外)、その後、ID値の降順で3番目のソートを実行できます(最後に選択されるのは、IDが最も高いものです-たとえば、最後に受け入れられた人、たとえば、従業員番号が順番に発行されます): SELECT TOP 3
つまり
クエリ結果を予測可能にするようにしてください。これにより、フライトの結果報告の場合に、なぜこれらの人々がブラックリストに登録されたのか、つまり、承認された規則に従って、すべてが正直に選択されました。ORDER BY句で異なる式を使用してソートすることもできます。 SELECT LastName,FirstName FROM Employees ORDER BY CONCAT(LastName,' ',FirstName)
また、ORDER BYでは、列に定義されたエイリアスを使用できます。 SELECT CONCAT(LastName,' ',FirstName) fi FROM Employees ORDER BY fi
DISTINCT句を使用する場合、SELECTブロックにリストされている列のみがORDER BY句で使用できることに注意してください。 つまり
DISTINCT操作を適用した後、新しい列のセットを持つ新しいデータセットを取得します。このため、次の例は機能しません。 SELECT DISTINCT LastName,FirstName,Salary FROM Employees ORDER BY ID
つまり
結果がユーザーに返される前に、ORDER BY句がすでに最終セットに適用されています。1. ORDER BY , SELECT:
SELECT LastName,FirstName,Salary FROM Employees ORDER BY
, .
( ), , «*» . – , -, , , ( ), , , .. , .
, , , , (.. ), , .
, .
2.
MS SQL NULL .
SELECT BonusPercent FROM Employees ORDER BY BonusPercent
DESC
SELECT BonusPercent FROM Employees ORDER BY BonusPercent DESC
NULL , , :
SELECT BonusPercent FROM Employees ORDER BY ISNULL(BonusPercent,100)
ORACLE 2 NULLS FIRST NULLS LAST ( ). 例:
SELECT BonusPercent FROM Employees ORDER BY BonusPercent DESC NULLS LAST
.
TOP –
MSDNからのクリッピング。TOP-クエリの結果セットで返される行の数を、指定された数またはパーセント値に制限します。TOP句がORDER BY句と組み合わせて使用される場合、結果セットはソートされた結果の最初のN行に制限されます。それ以外の場合、最初のN行は未定義の順序で返されます。
通常、この式はORDER BY句とともに使用され、結果セットからN番目の行を返す必要がある場合の例をすでに見ました。ORDER BYがない場合、この提案は通常、多くのレコードが存在する可能性のある未知のテーブルを見る必要がある場合に適用されます。この場合、たとえば、最初の10行のみを返すように依頼できますが、明確にするために、2つだけを言います。 SELECT TOP 2 * FROM Employees
結果セットから対応する割合の行を返すために、単語PERCENTを指定することもできます。 SELECT TOP 25 PERCENT * FROM Employees
私の練習では、行数による選択がより頻繁に使用されます。また、TOPを使用すると、WITH TIESオプションを使用できます。これは、あいまいなソートの場合にすべての行を返すのに役立ちます。この文は、TOP Nの選択に該当する行と構成が等しいすべての行を返します。その結果、Nより多くの行を選択できます。デモ用に給与が1500の別の「プログラマ」を追加しましょう。 INSERT Employees(ID,Name,Email,PositionID,DepartmentID,ManagerID,Salary) VALUES(1004,N' ..','n.nikolayev@test.tt',3,3,1003,1500)
2000年の給与で役職と部門を指定せずに別の従業員を紹介します。 INSERT Employees(ID,Name,Email,PositionID,DepartmentID,ManagerID,Salary) VALUES(1005,N' ..','a.alexandrov@test.tt',NULL,NULL,1000,2000)
ここで、WITH TIESオプションを使用して、給与が3人の従業員の給与と同じで、給与が最小のすべての従業員を選択します(後で明らかになることを願っています)。 SELECT TOP 3 WITH TIES ID,Name,Salary FROM Employees ORDER BY Salary
ここでは、TOP 3が示されていますが、クエリは4つのレコードを返しました。4人の従業員には、TOP 3が返した給与値がありました(1500および2000)。これは次のように視覚的に機能します。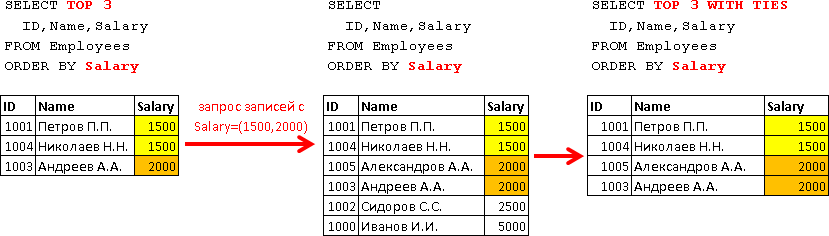
メモへ。
さまざまなデータベースでは、TOPはさまざまな方法で実装されます。MySQLには、このためのLIMIT句があり、追加で初期オフセットを設定できます。
ORACLE 12cでは、TOP機能とLIMIT機能を組み合わせた同等の機能も導入しました。「ORACLE OFFSET FETCH」という言葉を探してください。バージョン12cより前は、通常、ROWNUM疑似列がこの目的で使用されていました。
しかし、DISTINCT文とTOP文を同時に適用するとどうなりますか?実験を行うことにより、このような質問に簡単に答えることができます。一般的に、恐れることなく、実験するのを怠らないでください。そのほとんどは実際に学習されます。SELECTステートメントの語順は次のとおりです。最初の語はDISTINCTであり、その後にTOPが続きます。論理的に推論し、左から右に読む場合、最初は重複の拒否であり、次にこのセットでTOPが作成されます。さて、次のことを確認して確認しましょう。 SELECT DISTINCT TOP 2 Salary FROM Employees ORDER BY Salary
つまり
その結果、私たちはすべての給与のうち最低の2つを受け取りました。もちろん、一部の従業員のRFPが指定されていない(NULL)場合があります。このスキームにより、これを行うことができます。したがって、タスクに応じて、ORDER BY句でNULL値を処理するか、SalaryがNULLであるすべてのレコードを単純に破棄することを決定し、そのためにWHERE句の検討に進みます。WHERE-行フェッチ条件
この文は、特定の条件でレコードをフィルタリングするために使用されます。たとえば、「IT」部門で働くすべての従業員を選択します(ID = 3): SELECT ID,LastName,FirstName,Salary FROM Employees WHERE DepartmentID=3
| ID | 姓 | 名 | 給料 |
|---|
| 1004 | ヌル | ヌル | 1500 |
| 1003 | アンドレエフ | アンドレイ | 2000年 |
| 1001 | ペトロフ | ピーター | 1500 |
WHERE句は、ORDER BYコマンドの前に記述されます。コマンドが元の従業員セットに適用される順序は次のとおりです。- WHERE-指定されている場合、従業員のセット全体から最初に必要なのは、条件を満たすレコードのみの選択です
- DISTINCT-指定された場合、すべての重複は破棄されます
- ORDER BY-指定されている場合、結果はソートされます
- TOP-指定されている場合、指定された数のレコードのみがソート結果から返されます
明確にするために例を考えてみましょう。 SELECT DISTINCT TOP 1 Salary FROM Employees WHERE DepartmentID=3 ORDER BY Salary
これは次のように なります。NULLのチェックは等号ではなく、IS NULLおよびIS NOT NULL演算子を使用して行われることに注意してください。「=」演算子(等号)を使用してNULLと比較できないことを忘れないでください。式の結果もNULLになります。たとえば、部門を持たないすべての従業員を選択します(つまり、DepartmentID IS NULL):
なります。NULLのチェックは等号ではなく、IS NULLおよびIS NOT NULL演算子を使用して行われることに注意してください。「=」演算子(等号)を使用してNULLと比較できないことを忘れないでください。式の結果もNULLになります。たとえば、部門を持たないすべての従業員を選択します(つまり、DepartmentID IS NULL): SELECT ID,Name FROM Employees WHERE DepartmentID IS NULL
次に、例として、BonusPercent値が示されているすべての従業員のボーナスを計算しましょう(つまり、BonusPercent IS NOT NULL): SELECT ID,Name,Salary/100*BonusPercent AS Bonus FROM Employees WHERE BonusPercent IS NOT NULL
はい、ところで、考えてみると、BonusPercentの値はゼロ(0)になる可能性があります。また、このフィールドに制限を課していないため、マイナス記号を付けて値を入力することもできます。問題について説明した後、これまでのところ(BonusPercent <= 0またはBonusPercent IS NULL)であれば、これは従業員にもボーナスがないことを意味します。最初に、言われたように、それを実行します。論理演算子ORおよびNOTを使用してこれを実装します。 SELECT ID,Name,Salary/100*BonusPercent AS Bonus FROM Employees WHERE NOT(BonusPercent<=0 OR BonusPercent IS NULL)
つまり
ここでブール演算子の研究を始めました。括弧内の式((BonusPercent <= 0 OR BonusPercent IS NULL))は、従業員にボーナスがないことを確認し、この値を反転させません。「ボーナスのない従業員ではないすべての従業員を返す」と述べています。また、この式を書き換えて、式(BonusPercent> 0およびBonusPercent IS NOT NULL)で表すことにより、すぐに「ボーナスのあるすべての従業員を返す」と言うことができます。 SELECT ID,Name,Salary/100*BonusPercent AS Bonus FROM Employees WHERE BonusPercent>0 AND BonusPercent IS NOT NULL
WHEREブロックでも、算術演算子と関数を使用してさまざまな種類の式を確認できます。たとえば、ISNULL関数で式を使用して同様のチェックを実行できます。 SELECT ID,Name,Salary/100*BonusPercent AS Bonus FROM Employees WHERE ISNULL(BonusPercent,0)>0
ブール演算子と単純比較演算子
はい、ここでは数学なしではできません。そのため、ブール演算子と単純な比較演算子について簡単に説明します。SQLには、AND、OR、NOTの3つのブール演算子のみがあります。| そして | 論理I。2つの条件(condition1 AND condition2)の間に置かれます。式がTrueを返すには、両方の条件がtrueでなければなりません。 |
|---|
| または | 論理OR。2つの条件(condition1 OR condition2)の間に置かれます。式がTrueを返すには、1つの条件のみがTrueであれば十分です。 |
|---|
| ない | 条件/論理式を反転します。別の式(NOT logical_expression)にスーパーインポーズされ、logical_expression = Falseの場合Trueを返し、logical_expression = Trueの場合Falseを返します |
|---|
ブール演算子ごとに、条件がNULLになる可能性がある場合の結果がさらに示される真理値表を提供できます。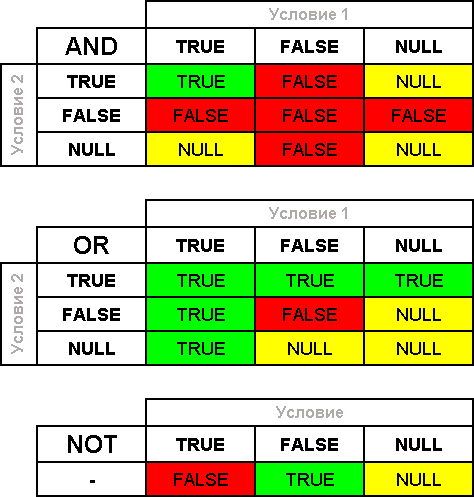 条件を形成するために使用される次の単純な比較演算子があります。
条件を形成するために使用される次の単純な比較演算子があります。| 状態 | 価値 |
|---|
| = | 同様に |
| < | 少ない |
| > | もっと |
| <= | より小さいか等しい |
| > = | より大きいか等しい |
<>
!= | 等しくない |
さらに、NULLの値/式をチェックするための2つの演算子があります。| NULLです | NULL等価チェック |
|---|
| NULLではない | NULL不等式の確認 |
|---|
優先度:1)すべての比較演算子。2)NOT; 3)AND; 4)または。複雑な論理式を構築する場合、括弧が使用されます。 ((1 AND 2) OR NOT(3 AND 4 AND 5)) OR (…)
また、括弧を使用して、計算の標準シーケンスを変更できます。ここでは、仕事に十分な量のブール代数のアイデアを与えようとしました。ご覧のとおり、より複雑な条件を記述するために、ロジックなしではできませんが、それらのいくつか(AND、OR、NOT)があり、人々が思いついたので、すべてが非常に論理的です。第二部を完成させます
ご覧のとおり、SELECT演算子の基本的な構文についても非常に長い間話すことができますが、記事のフレームワーク内にとどまるために、追加の論理演算子-BETWEEN、IN、LIKEを示します。BETWEEN-範囲の確認
この演算子の形式は次のとおりです。 _ [NOT] BETWEEN _ AND _
値は式にすることができます。例を見てみましょう: SELECT ID,Name,Salary FROM Employees WHERE Salary BETWEEN 2000 AND 3000
| ID | お名前 | 給料 |
|---|
| 1002 | シドロフS.S. | 2500 |
| 1003 | アンドレエフA.A. | 2000年 |
| 1005 | アレクサンドロフA.A. | 2000年 |
実際、BETWEENは次の形式の簡略化されたレコードです。 SELECT ID,Name,Salary FROM Employees WHERE Salary>=2000 AND Salary<=3000
単語BETWEENの前に、単語NOTを使用できます。これにより、指定された範囲に該当しない値がチェックされます。 SELECT ID,Name,Salary FROM Employees WHERE Salary NOT BETWEEN 2000 AND 3000
したがって、BETWEEN、IN、LIKEを使用する場合、ANDおよびORを使用して他の条件と組み合わせることもできます。 SELECT ID,Name,Salary FROM Employees WHERE Salary BETWEEN 2000 AND 3000
IN-値のリストへのエントリを確認します
この演算子の形式は次のとおりです。 _ [NOT] IN (1, 2, …)
例で示す方が簡単だと思います: SELECT ID,Name,Salary FROM Employees WHERE PositionID IN(3,4)
| ID | お名前 | 給料 |
|---|
| 1001 | ペトロフP.P. | 1500 |
| 1003 | アンドレエフA.A. | 2000年 |
| 1004 | ニコラエフN.N. | 1500 |
つまり
基本的に、これは次の式に似ています。 SELECT ID,Name,Salary FROM Employees WHERE PositionID=3 OR PositionID=4
NOTの場合、これは同様になります(部門3と部門4以外の全員を取得します)。 SELECT ID,Name,Salary FROM Employees WHERE PositionID NOT IN(3,4)
NOT INを使用したリクエストは、ANDで表現することもできます。 SELECT ID,Name,Salary FROM Employees WHERE PositionID<>3 AND PositionID<>4
INコンストラクトでNULL値を検索することは機能しないことに注意してください。NULL = NULLをチェックすると、TrueではなくNULLも返されます。 SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID IN(1,2,NULL)
この場合、テストをいくつかの条件に分割します。 SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID IN(1,2)
または、次のように書くことができます。 SELECT ID,Name,DepartmentID FROM Employees WHERE ISNULL(DepartmentID,-1) IN(1,2,-1)
この場合、最初のオプションはより正確で信頼性が高いと思います。さて、これは他の構造を構築できることを示すための単なる例です。また、NULLに関連するさらに陰湿なエラーに言及する価値があります。これは、NOT IN構文を使用すると発生する可能性があります。たとえば、部門が1であるか、部門がまったく指定されていない従業員を除く、すべての従業員を選択してみましょう。nullに等しい。解決策として、オプションはそれ自体を提案します: SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID NOT IN(1,NULL)
しかし、リクエストを実行すると、次のように表示されると予想されていましたが、1行は取得されません。| ID | お名前 | DepartmentID |
|---|
| 1001 | ペトロフP.P. | 3 |
| 1002 | シドロフS.S. | 2 |
| 1003 | アンドレエフA.A. | 3 |
| 1004 | ニコラエフN.N. | 3 |
繰り返しますが、値のリストで指定されたNULLがここで冗談を演じました。この場合、論理エラーが発生した理由を分析します。ANDを使用してクエリを展開します。 SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID<>1 AND DepartmentID<>NULL
正しい条件(DepartmentID <> NULL)は、ここで常に不確実性を与えます。NULL ここで、(TRUE AND NULL)がNULLを与えるAND演算子の真理値表を思い出してください。つまり
未定義の右条件により左の条件(DepartmentID <> 1)が満たされると、結果として式全体の不定値(DepartmentID <> 1 AND DepartmentID <> NULL)が取得されるため、行は結果に含まれません。条件は次のように正しく書き換えられます。 SELECT ID,Name,DepartmentID FROM Employees WHERE DepartmentID NOT IN(1)
INは引き続きサブクエリで使用できますが、このチュートリアルの以降の部分で既にこのフォームに戻ります。LIKE-パターンによる文字列の確認
この演算子については、最も単純な形式でのみ説明します。これは標準であり、SQL言語のほとんどの方言でサポートされています。この形式でも、文字列の内容を確認する必要がある多くの問題を解決するために使用できます。この演算子の形式は次のとおりです。 _ [NOT] LIKE _ [ESCAPE _]
次の特殊文字をpattern_stringで使用できます。- アンダースコア「_」-代わりに任意の単一文字を使用できることを示します
- パーセント記号「%」-代わりに、単一の文字を含め、任意の数の文字を使用できることを示します
記号「%」の例を検討します(実際には、より頻繁に使用される方法で)。 SELECT ID,Name FROM Employees WHERE Name LIKE '%'
記号「_」の例を検討してください。 SELECT ID,LastName FROM Employees WHERE LastName LIKE '_'
ESCAPEを使用すると、特殊文字「_」と「%」のチェックアクションをキャンセルするキャンセル文字を指定できます。この文は、行のパーセント記号またはアンダースコアを直接確認する必要がある場合に使用されます。ESCAPEを示すために、ゴミを1つのエントリに入れましょう。 UPDATE Employees SET FirstName='_, %' WHERE ID=1005
そして、次のクエリが返すものを確認してください。 SELECT * FROM Employees WHERE FirstName LIKE '%!%%' ESCAPE '!'
文字列の完全な一致を確認する場合は、LIKEの代わりに、単に「=」記号を使用することをお勧めします。 SELECT * FROM Employees WHERE FirstName=''
メモへ。
MS SQLでは、LIKE演算子テンプレートで正規表現を検索することもできます;この演算子の標準機能では不十分な場合は、インターネットでそれを読んでください。
ORACLEは、REGEXP_LIKE関数を使用して正規表現で検索します。
行について少し
Unicode文字の存在について文字列をチェックする場合、引用符の前にN文字を置く必要があります。 N '...'。ただし、テーブルにはすべての文字フィールドがUnicode形式(nvarchar型)であるため、これらのフィールドには常にこの形式を使用できます。例:
SELECT ID,Name FROM Employees WHERE Name LIKE N'%' SELECT ID,LastName FROM Employees WHERE LastName=N''
正しく行われた場合、varchar型(ASCII)のフィールドと比較する場合、「...」を使用してチェックを使用する必要があり、nvarchar型(Unicode)のフィールドと比較する場合は、N「...」を使用してチェックを使用する必要があります。これは、クエリ実行中の暗黙的な型変換を回避するために行われます。フィールドに値を挿入(INSERT)または更新(UPDATE)するときに同じルールを使用します。文字列を比較するとき、データベース構成(照合)に応じて、文字列は大文字と小文字を区別しない(「ペトロフ」=「PETROV」の場合)または大文字と小文字を区別する(「ペトロフ」<>の場合)ペトロフ ')。大文字と小文字を区別する設定の場合、大文字と小文字を区別しない検索を行うには、たとえば、右式と左式を1つの大文字または小文字に予備変換します。 SELECT ID,Name FROM Employees WHERE UPPER(Name) LIKE UPPER(N'%')
日付について少し
日付を確認するときは、文字列と同様に、単一引用符「...」を使用できます。MS SQLの地域設定に関係なく、次の日付構文 'YYYYMMDD'(年、月、日をスペースなしでマージ)を使用できます。そのようなMS SQLの日付形式は常に理解します: SELECT ID,Name,Birthday FROM Employees WHERE Birthday BETWEEN '19800101' AND '19891231'
場合によっては、DATEFROMPARTS関数を使用して日付を設定する方が便利です。 SELECT ID,Name,Birthday FROM Employees WHERE Birthday BETWEEN DATEFROMPARTS(1980,1,1) AND DATEFROMPARTS(1989,12,31) ORDER BY Birthday
また、同様の関数DATETIMEFROMPARTSがあります。これは、日時を設定するのに役立ちます(datetime型の場合)。文字列をdate型またはdatetime型の値に変換する場合は、CONVERT関数を使用することもできます。 SELECT CONVERT(date,'12.03.2015',104), CONVERT(datetime,'2014-11-30 17:20:15',120)
値104および120は、文字列で使用される日付形式を示します。検索で「MS SQL CONVERT」を設定すると、MSDNライブラリですべての有効な形式の説明を見つけることができます。MS SQLで日付を操作するための関数はたくさんあります。「日付を操作するためのms sql関数」を探してください。ご注意 SQL言語のすべての方言には、日付を操作するための独自の関数セットがあり、日付を操作する独自のアプローチを適用します。
数字とその変換について少し
このセクションの情報は、おそらくITプロフェッショナルにとってより役立つでしょう。あなたが1人ではなく、データベースから必要な情報を取得するためのクエリの書き方を学ぶことが目標である場合、そのような微妙なことは必要ないかもしれませんが、いずれにしてもテキストをざっと読んで何かを考慮することができます。 SQLの勉強を始めたのであれば、すでにITに携わっています。CAST変換関数とは異なり、CONVERT関数では、変換スタイル(フォーマット)を担当する3番目のパラメーターを設定できます。さまざまなタイプのデータに対して、独自のスタイルセットを使用できます。これは、返される結果に影響を与える可能性があります。 CONVERT関数を使用して文字列を日付型および日付時刻型に変換することを検討する場合、スタイルの使用については既に触れました。CAST、CONVERT関数、およびスタイルの詳細については、MSDNの「CASTおよびCONVERT関数(Transact-SQL)」を参照してください。msdn.microsoft.com / en - us / library / ms187928.aspxここでは例を簡単にするために、Transact言語の指示を使用します。 SQL-DECLAREおよびSET。もちろん、整数を実数に変換する場合(整数と実数の除算の違いを示すために、このレッスンの冒頭で引用しました)、変換のニュアンスに関する知識はそれほど重要ではありません。そこで、整数を実数に変換しました(その範囲は整数の範囲よりはるかに大きいです): DECLARE @min_int int SET @min_int=-2147483648 DECLARE @max_int int SET @max_int=2147483647 SELECT
おそらく(1.)で割ることによって得られる暗黙的な変換の方法を示す必要はなかったでしょう。取得する結果のタイプをさらに制御するために、明示的な変換を行うことをお勧めします。ただし、小数点以下の指定桁数で数値型の結果を取得する場合は、整数値に(1.、1.0、1.00など)を掛けてMS SQLでトリックを適用できます。 DECLARE @int int SET @int=123 SELECT @int*1.,
場合によっては、変換の詳細が非常に重要になることがあります。たとえば、数値の文字列(varchar)への変換が行われる場合、結果の正確性に影響します。money型とfloat型の値をvarcharに変換する例を考えてみましょう。
例からわかるように、特に文字列に蒸留するとき、またはその逆の場合、実際には大きな浮動小数点エラーが発生することがあります(たとえば、あるシステムから別のシステムにデータがテキストファイルで転送される場合、さまざまな種類の統合が可能です) 。特定の文字(4文字以上)の精度を明示的に制御する必要がある場合は、データを格納するために、decimal / numeric型を使用した方がよい場合があります。十分な4文字がある場合、タイプmoneyを使用できます。これはおおよそ数値(20,4)に対応します。
ご注意
MS SQL 2008の時点では、以下を構築する代わりに使用できます。
DECLARE @money money SET @money = 1025.123456789
より短い変数初期化構文:
DECLARE @money money = 1025.123456789
第二部の結論
このパートでは、基本的な構文に関する最も重要な点を思い出して反映しようとしました。基本的な構造はバックボーンであり、これがないと、SQL言語のより複雑な構造の学習を開始できません。この資料が、SQL言語を学習する最初の一歩を踏み出すのに役立つことを願っています。この言語を学習し、実践に移してください。パート3-habrahabr.ru/post/255825