ログの集中処理のタスクは非常に単純に定式化されており、多数のサーバーの動作を監視する必要があるときに発生します。 ログからシステムの重要な機能と幸福に関する多くの情報を取得できることを言及する価値はないと思います。 ログの書き込みと読み取りは、プログラムを作成できることと同じくらい重要です。
したがって、このようなシステムを実装するために、管理者は、まず、これらのログを収集する方法、そして次に、これらのログを使用するのが便利で中心的な方法を任されます。 Habréで何度も説明されている、よく開発されたELKバンチ(Elasticsearch + Logstash + Kibana)のおかげで、管理者はログにあるすべての情報を便利に検索および表示するためのツールを使用できます。 したがって、2番目の問題に対する答えは最初は利用可能であり、ログを収集する問題を解決するためだけに残っています。
私の場合、システムの要件はサーバー上にクライアントがなく、ログをWindowsサーバーから取得する必要があるという事実であったため、コレクションツールとしてWindowsのネイティブであるpowershellを選択しました。
これに基づいて、ログから情報を収集および表示するための次のモデルがコンパイルされました:ログはpowershellスクリプトを使用してサーバーからリモートで収集され、その後ファイルとしてストレージに追加され、ELK(Elasticsearch + Logstash + Kibana)が処理して表示します。
バンドル全体の動作の例を画像に示します。
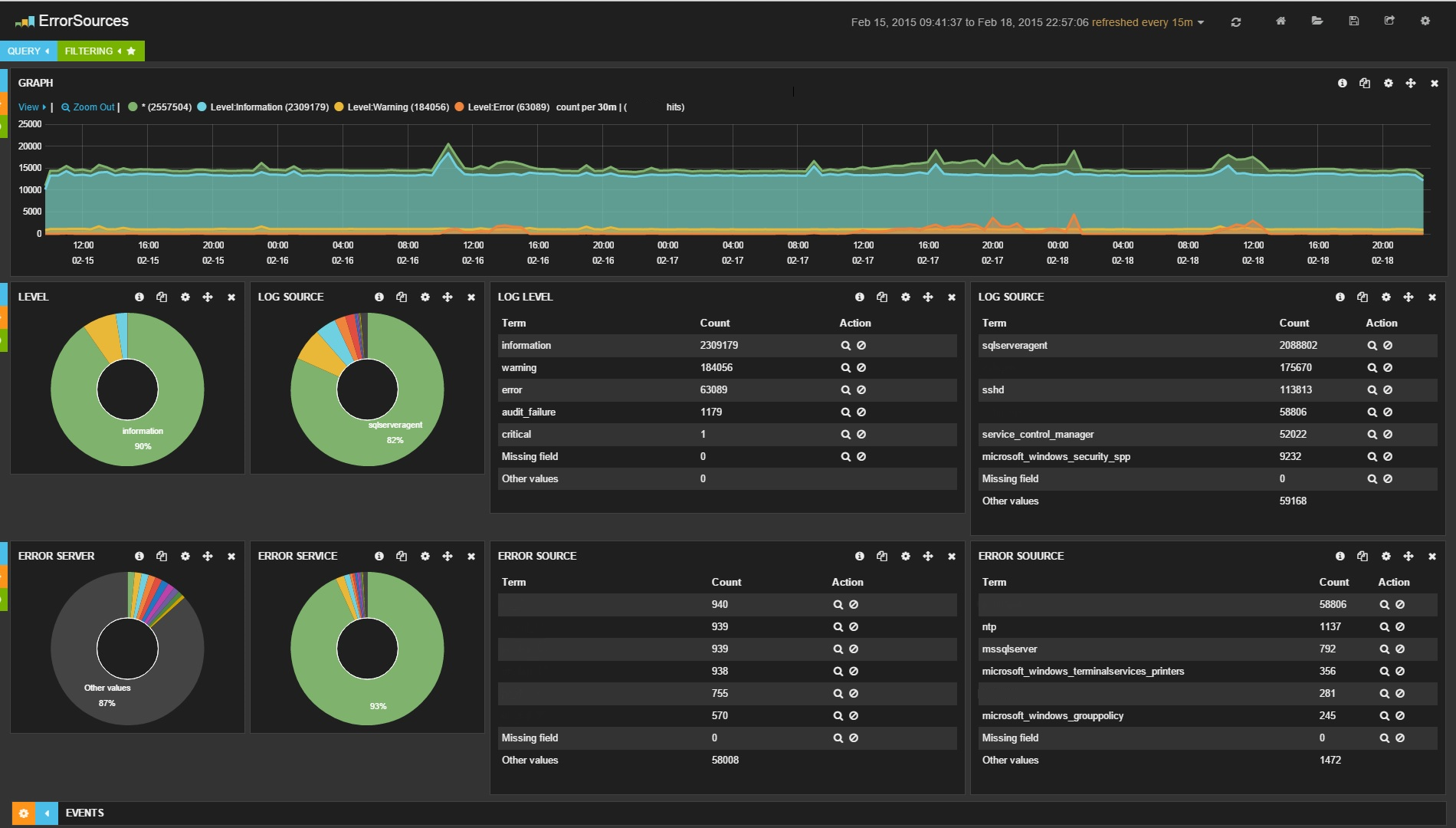
批判を予想して、このシステムはリアルタイムでログを収集するタスクを設定しないことを説明します。目標は統計であり、一定期間にわたって収集され、ダッシュボードに表示されます。 朝に来て、夜間にサーバーがどのように動作するかを確認し、たとえば先週得られた結果と比較するために使用されます。 提案されたシステムでは、ログはそれぞれ1時間に1回収集されます。現在のログとダッシュボードに表示される内容(正確には、表示および表示)との時間差は約1時間です。
現在、PowerShellのリモートコンピューターからログを取得するには2つの方法があります。
- ネイティブPowerShellコマンド:Get-EventLog -ComputerName $ computer –LogName System
- WMI-request経由でログを取得:Get-WmiObject -Class win32_NTLogEvent -filter "logfile = 'System'" -ComputerName $ computer
ただし、最初のケースでは、システムのイベントログを含むファイルが完全にアップロードされてから、スクリプトが実行されるコンピューターで処理されます。 その結果、そのような要求は不当に長く処理されます。 ログを選択する機能(たとえば、最終日のみ)は、ファイル全体が最初に引き出されてからいくつかの作業が行われるため、ここではうまく機能しません。
2番目のケースでは、WMI要求がサーバーに送信され、サーバー側で処理が行われます。ここで重要なのは、要求段階で既に関心のあるログの間隔を制限できるようになることです(以下の例では、間隔は1時間に設定されています)。 このコマンドは最初のコマンドよりもはるかに高速で実行され、クエリの実行時間は要求されたログ間隔に直接依存するため、Get-WmiObjectを選択しました。
以下のスクリプトには、いくつかの非自明で複雑な点があります。
最初に、最後の1時間にログが必要な場合にログをサンプリングする時間間隔を制限するためのロジックについて説明しますが、リクエストの時間から1時間ではなく、最後の1時間に、つまり 00分から そして59分で終わる
2番目のポイントは、WMI形式の時間が通常の形式と異なるため、時間のWMI形式への変換とその逆の変換が常に必要であるということです。
スクリプトが完了すると、出力はComputerName-JournalName.jsonという形式のファイルを生成します。
json形式は標準と多少矛盾しています(開き括弧と閉じ括弧はありません)が、Logstashパーサーは通常それをダイジェストして処理します。 サーバーごとに3つのファイルが作成されます。ComputerName-System.json ComputerName-Application.json ComputerName-Security.jsonファイルは同じ形式であるため、処理が理想的です。
次の行を編集するだけで、ログの収集を特定のログに制限できます。$ logjournals = "System"、 "Application"、 "Security"
次に、Logstashには次の構成が含まれています。
ServersEventLogs.conf input { file { type => "ServersLogs" discover_interval => 1800 path => [ "//storage/Logs/ServersLog/*/*.json" ] codec => "json" } } filter { date { type => "ServersLogs" match => [ "Time", "MM/dd/YYYY HH:mm:ss" ] locale => "en" target => "Logtimestamp" } mutate { gsub => [ "Level", "[ -]", "_" ] gsub => [ "Source", "[ -]", "_" ] gsub => [ "Server", "[ -]", "_" ] remove_field => ["message"] remove_field => ["host"] } } output { elasticsearch { embedded => false host => "logserver" protocol => "http" cluster => "windowseventlogs" codec => "plain" index => "windowseventlogs-%{+YYYY.MM.dd}" } }
データはElasticsearchに入力され、その後Kibanaを使用して表示されます。
その結果、情報が画面に表示されます(私の場合、過去2日間):最も問題のあるサーバーに関する情報、最も問題のあるサービスに関する情報。 グラフが描かれ、それに応じて、特定の時点でのログまたはエラーの数の増加をすぐに確認できます。 常にエラーテキストまたはユーザー名で検索するか、レベルまたはエラーIDで並べ替えることができます。