前のパーツ
この部分では、考慮します
マルチテーブルクエリ:
- テーブル結合結合-結合
- WHERE句を使用してテーブルをリンクする
- 垂直マージクエリの結果-UNION
サブクエリを使用する:
- FROM、SELECTブロックのサブクエリ
- APPLYコンストラクトのサブクエリ
- WITH句を使用する
- WHEREブロックのサブクエリ:
いくつかの新しいデータを追加します。
デモンストレーションのために、いくつかの部門と投稿を追加します。
SET IDENTITY_INSERT Departments ON INSERT Departments(ID,Name) VALUES(4,N' ') INSERT Departments(ID,Name) VALUES(5,N'') SET IDENTITY_INSERT Departments OFF
SET IDENTITY_INSERT Positions ON INSERT Positions(ID,Name) VALUES(5,N'') INSERT Positions(ID,Name) VALUES(6,N'') INSERT Positions(ID,Name) VALUES(7,N'') SET IDENTITY_INSERT Positions OFF
JOIN接続-水平データ接続操作
ここでは、データベース構造の知識、すなわち その中にあるテーブル、これらのテーブルに保存されているデータ、およびテーブルのどのフィールドが関連しているか。 まず、データベースの構造を常に徹底的に研究します。 通常のクエリは、どこから来たのかがわかっている場合にのみ記述できます。 私たちの構造は、従業員、部署、役職の3つのテーブルで構成されています。 これが最初の部分の図です:
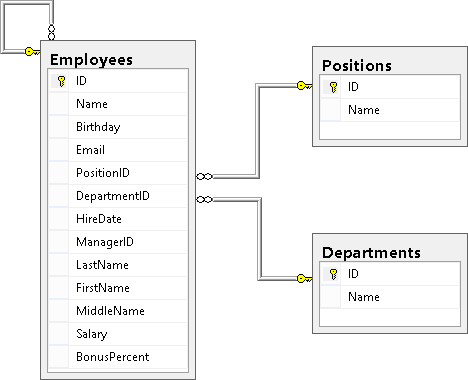 RDBの本質が分割して征服することである場合、アソシエーションの操作の本質は、テーブルで分割されたデータを再び接着することです。 それらを人間の形に戻します。
RDBの本質が分割して征服することである場合、アソシエーションの操作の本質は、テーブルで分割されたデータを再び接着することです。 それらを人間の形に戻します。簡単に言えば、テーブルを他のテーブルと水平方向に結合する操作は、そこから欠落しているデータを取得するために使用されます。 従業員表からの要求に応じて、最終結果を取得するためにDepartments表にDepartment Nameフィールドがなかった場合の、ディレクターの週次レポートの例を思い出してください。
理論から始めましょう。 接続には5つのタイプがあります。
- JOIN -left_table JOIN right_table ON join_condition
- LEFT JOIN -left_table LEFT JOIN right_table ON join_conditions
- RIGHT JOIN -left_table RIGHT JOIN right_table ON join_conditions
- FULL JOIN -left_table FULL JOIN right_table ON join_condition
- CROSS JOIN -left_table CROSS JOIN right_table
| 短い構文 | 完全な構文 | 説明(これは誰もがすぐに明確になるとは限りません。したがって、明確でない場合は、例を確認してからここに戻ってください。) |
|---|
| 参加する | インナージョイン | left_tableおよびright_tableの行から、結合条件を返す行のみが結合されます。 |
| 左から参加 | 左外部結合 | left_tableのすべての行が返されます(キーワードLEFT)。 右テーブルのデータは、join_条件が満たされている左テーブルの行によってのみ補完されます。 欠落データの場合、right_table行の代わりにNULL値が挿入されます。 |
| 正しい参加 | 右アウタージョイン | right_tableのすべての行が返されます(キーワードRIGHT)。 join_条件が満たされている左側のテーブル行のみが左側のテーブルデータで補完されます。 欠落データの場合、left_table行の代わりにNULL値が挿入されます。 |
| 完全参加 | フルアウタージョイン | left_tableおよびright_tableのすべての行が返されます。 left_tableおよびright_tableの行についてjoin_条件が満たされる場合、それらは1つの行に結合されます。 join_条件が満たされない行の場合、行内のどのテーブルのデータが利用できないかに応じて、left_tableの場所またはright_tableの場所にNULL値が挿入されます。 |
| クロスジョイン | - | left_tableの各行を、right_tableのすべての行と組み合わせます。 このタイプの化合物は、デカルト積と呼ばれることもあります。 |
表からわかるように、短い構文の完全な構文は、INNERまたはOUTERという単語の存在のみが異なります。
個人的には、クエリを作成するときは常に次の理由で短い構文のみを使用します。
- これは短く、不要な単語でクエリを詰まらせません。
- LEFT、RIGHT、FULLおよびCROSSによると、JOINの場合、どのような接続について話しているのかが明確です。
- この場合のINNERとOUTERという言葉は、初心者をより混乱させる不必要な初歩的なものだと思います。
しかし、もちろん、これは私の個人的な好みであり、おそらく誰かが長い間書くのが好きで、彼はこれに彼の魅力を見ています。
各タイプの接続を理解することは非常に重要です。なぜなら、 特定のタイプのアプリケーションでは、クエリ結果が異なる場合があります。 別の種類の接続を使用して同じクエリの結果を比較し、今のところ違いを確認して先に進みます(ここに戻ります)。
| ID | お名前 | DepartmentID | ID | お名前 |
|---|
| 1000 | イワノフI.I. | 1 | 1 | 運営 |
| 1001 | ペトロフP.P. | 3 | 3 | IT |
| 1002 | シドロフS.S. | 2 | 2 | 簿記 |
| 1003 | アンドレエフA.A. | 3 | 3 | IT |
| 1004 | ニコラエフN.N. | 3 | 3 | IT |
| ID | お名前 | DepartmentID | ID | お名前 |
|---|
| 1000 | イワノフI.I. | 1 | 1 | 運営 |
| 1001 | ペトロフP.P. | 3 | 3 | IT |
| 1002 | シドロフS.S. | 2 | 2 | 簿記 |
| 1003 | アンドレエフA.A. | 3 | 3 | IT |
| 1004 | ニコラエフN.N. | 3 | 3 | IT |
| 1005 | アレクサンドロフA.A. | ヌル | ヌル | ヌル |
| ID | お名前 | DepartmentID | ID | お名前 |
|---|
| 1000 | イワノフI.I. | 1 | 1 | 運営 |
| 1002 | シドロフS.S. | 2 | 2 | 簿記 |
| 1001 | ペトロフP.P. | 3 | 3 | IT |
| 1003 | アンドレエフA.A. | 3 | 3 | IT |
| 1004 | ニコラエフN.N. | 3 | 3 | IT |
| ヌル | ヌル | ヌル | 4 | マーケティングと広告 |
| ヌル | ヌル | ヌル | 5 | 物流 |
| ID | お名前 | DepartmentID | ID | お名前 |
|---|
| 1000 | イワノフI.I. | 1 | 1 | 運営 |
| 1001 | ペトロフP.P. | 3 | 3 | IT |
| 1002 | シドロフS.S. | 2 | 2 | 簿記 |
| 1003 | アンドレエフA.A. | 3 | 3 | IT |
| 1004 | ニコラエフN.N. | 3 | 3 | IT |
| 1005 | アレクサンドロフA.A. | ヌル | ヌル | ヌル |
| ヌル | ヌル | ヌル | 4 | マーケティングと広告 |
| ヌル | ヌル | ヌル | 5 | 物流 |
| ID | お名前 | DepartmentID | ID | お名前 |
|---|
| 1000 | イワノフI.I. | 1 | 1 | 運営 |
| 1001 | ペトロフP.P. | 3 | 1 | 運営 |
| 1002 | シドロフS.S. | 2 | 1 | 運営 |
| 1003 | アンドレエフA.A. | 3 | 1 | 運営 |
| 1004 | ニコラエフN.N. | 3 | 1 | 運営 |
| 1005 | アレクサンドロフA.A. | ヌル | 1 | 運営 |
| 1000 | イワノフI.I. | 1 | 2 | 簿記 |
| 1001 | ペトロフP.P. | 3 | 2 | 簿記 |
| 1002 | シドロフS.S. | 2 | 2 | 簿記 |
| 1003 | アンドレエフA.A. | 3 | 2 | 簿記 |
| 1004 | ニコラエフN.N. | 3 | 2 | 簿記 |
| 1005 | アレクサンドロフA.A. | ヌル | 2 | 簿記 |
| 1000 | イワノフI.I. | 1 | 3 | IT |
| 1001 | ペトロフP.P. | 3 | 3 | IT |
| 1002 | シドロフS.S. | 2 | 3 | IT |
| 1003 | アンドレエフA.A. | 3 | 3 | IT |
| 1004 | ニコラエフN.N. | 3 | 3 | IT |
| 1005 | アレクサンドロフA.A. | ヌル | 3 | IT |
| 1000 | イワノフI.I. | 1 | 4 | マーケティングと広告 |
| 1001 | ペトロフP.P. | 3 | 4 | マーケティングと広告 |
| 1002 | シドロフS.S. | 2 | 4 | マーケティングと広告 |
| 1003 | アンドレエフA.A. | 3 | 4 | マーケティングと広告 |
| 1004 | ニコラエフN.N. | 3 | 4 | マーケティングと広告 |
| 1005 | アレクサンドロフA.A. | ヌル | 4 | マーケティングと広告 |
| 1000 | イワノフI.I. | 1 | 5 | 物流 |
| 1001 | ペトロフP.P. | 3 | 5 | 物流 |
| 1002 | シドロフS.S. | 2 | 5 | 物流 |
| 1003 | アンドレエフA.A. | 3 | 5 | 物流 |
| 1004 | ニコラエフN.N. | 3 | 5 | 物流 |
| 1005 | アレクサンドロフA.A. | ヌル | 5 | 物流 |
テーブルのエイリアスを覚えるときです
2番目のパートの冒頭で説明したテーブルのエイリアスについて思い出してください。
マルチテーブルクエリでは、エイリアスはフィールドの取得元のテーブルを明示的に示すのに役立ちます。 例を見てみましょう:
SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name FROM Employees emp JOIN Departments dep ON emp.DepartmentID=dep.ID
従業員と部門の両方のテーブルに、IDとNameという名前のフィールドが含まれています。 そしてそれらを区別するために、フィールド名の前にエイリアスとドットを付けます。 「Emp.ID」、「emp.Name」、「dep.ID」、「dep.Name」。
エイリアスがなければ、リクエストは次のようになるため、短いエイリアスを使用する方が便利な理由を思い出してください。
SELECT Employees.ID,Employees.Name,Employees.DepartmentID,Departments.ID,Departments.Name FROM Employees JOIN Departments ON Employees.DepartmentID=Departments.ID
私にとっては、読むのが非常に長く、悪くなっています。 フィールド名は、重複するテーブル名の間で視覚的に失われます。
マルチテーブルクエリでは、エイリアスなしで名前を指定できますが、2番目のテーブルで名前が重複していない場合は、接続の場合は常にエイリアスを使用することをお勧めします。 同じ名前のフィールドが時間の経過とともに2番目のテーブルに追加されないことを誰も保証せず、クエリは単純に壊れ、このフィールドがどのテーブルを参照しているのか理解できないと誓います。
エイリアスのみを使用すると、テーブルをそれ自体に結合できます。 タスクは、各従業員の直前に受け入れられた従業員のデータを取得することであったと想定します(従業員番号は1減ります)。 従業員番号が順番に発行され、穴が空いていない場合、およそ次のようにこれを実行できます。
SELECT e1.ID EmpID1, e1.Name EmpName1, e2.ID EmpID2, e2.Name EmpName2 FROM Employees e1 LEFT JOIN Employees e2 ON e1.ID=e2.ID+1
つまり ここにEmployeesの1つのテーブルがあり、エイリアス「e1」と2番目の「e2」を指定しました。
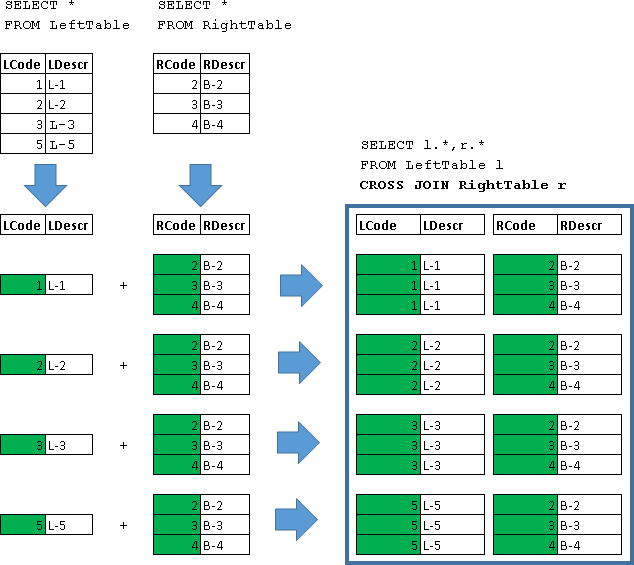
各タイプの水平接続を分解します
この目的のために、LeftTableおよびRightTableと呼ばれる2つの小さな抽象テーブルを検討します。
CREATE TABLE LeftTable( LCode int, LDescr varchar(10) ) GO CREATE TABLE RightTable( RCode int, RDescr varchar(10) ) GO INSERT LeftTable(LCode,LDescr)VALUES (1,'L-1'), (2,'L-2'), (3,'L-3'), (5,'L-5') INSERT RightTable(RCode,RDescr)VALUES (2,'B-2'), (3,'B-3'), (4,'B-4')
これらの表の内容を見てみましょう。
SELECT * FROM LeftTable
| LCode | LDescr |
|---|
| 1 | L-1 |
| 2 | L-2 |
| 3 | L-3 |
| 5 | L-5 |
SELECT * FROM RightTable
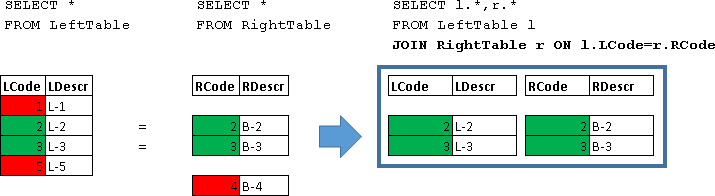
参加する
SELECT l.*,r.* FROM LeftTable l JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
|---|
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
ここでは、条件が満たされた文字列結合が返されました(l.LCode = r.RCode)
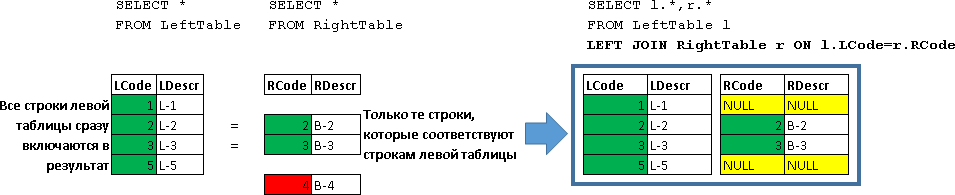
左から参加
SELECT l.*,r.* FROM LeftTable l LEFT JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
|---|
| 1 | L-1 | ヌル | ヌル |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | ヌル | ヌル |
ここでは、LeftTableのすべての行が返され、条件が満たされたRightTableからの行データによって補完されました(l.LCode = r.RCode)
正しい参加
SELECT l.*,r.* FROM LeftTable l RIGHT JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
|---|
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| ヌル | ヌル | 4 | B-4 |
ここでは、条件が満たされたLeftTableの行データで補完されたすべてのRightTable行が返されました(l.LCode = r.RCode)

実際、LeftTableとRightTableを適切に再配置すると、左結合を使用して同様の結果が得られます。
SELECT l.*,r.* FROM RightTable r LEFT JOIN LeftTable l ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
|---|
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| ヌル | ヌル | 4 | B-4 |
LEFT JOIN、つまり 最初に、どのテーブルデータが私にとって重要であるかを考え、次にどのテーブルが補完テーブルの役割を果たすかを考えます。
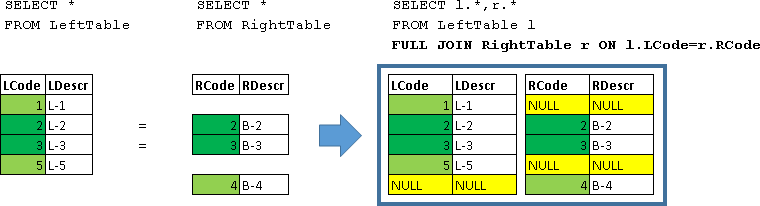
FULL JOINは、本質的にLEFT JOINとRIGHT JOINの同時参加です。
SELECT l.*,r.* FROM LeftTable l FULL JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
|---|
| 1 | L-1 | ヌル | ヌル |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | ヌル | ヌル |
| ヌル | ヌル | 4 | B-4 |
LeftTableとRightTableのすべての行が返されます。 条件が満たされる行(l.LCode = r.RCode)は、1行に結合されました。 左側または右側の欠落データにはNULL値が入力されます。
クロスジョイン
SELECT l.*,r.* FROM LeftTable l CROSS JOIN RightTable r
| LCode | LDescr | RCode | RDescr |
|---|
| 1 | L-1 | 2 | B-2 |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 2 | B-2 |
| 5 | L-5 | 2 | B-2 |
| 1 | L-1 | 3 | B-3 |
| 2 | L-2 | 3 | B-3 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | 3 | B-3 |
| 1 | L-1 | 4 | B-4 |
| 2 | L-2 | 4 | B-4 |
| 3 | L-3 | 4 | B-4 |
| 5 | L-5 | 4 | B-4 |
LeftTableの各行は、RightTableのすべての行のデータに接続されています。
EmployeesおよびDepartmentsテーブルに戻ります
水平方向のジョイントがどのように機能するかを理解してください。 この場合は、「JOIN接続-水平方向のデータ接続操作」セクションの最初に戻って、EmployeesテーブルとDepartmentsテーブルを自分で結合した例を理解してから、ここに戻って議論してください。
各リクエストの概要を要約してみましょう。
| リクエスト | まとめ |
|---|
| 本質的に、このクエリは、DepartmentID値が指定されている従業員のみを返します。
つまり 任意の部門に登録されている従業員(extrathatsを除く)のデータが必要な場合に、この接続を使用できます。 |
| すべての従業員を返します。 DepartmentIDを持たない従業員の場合、「dep.ID」および「dep.Name」フィールドにはNULLが含まれます。
ISNULL(dep.Name、 'off-state')などを使用して、必要に応じてNULL値を処理できることに注意してください。
このタイプの接続は、たとえば給与を計算するためのリストを取得するなど、すべての従業員のデータを取得することが重要な場合に使用できます。 |
| ここで、左側に穴があります。 部署がありますが、この部署には従業員はいません。
このような接続は、たとえば、どの部門と誰が占有され、どの部門がまだ形成されていないかを調べる必要がある場合に使用できます。 この情報を使用して、部門を形成する新しい従業員を検索し、受け入れることができます。 |
| このリクエストは、従業員に関するすべてのデータと利用可能な部門に関するすべてのデータを取得する必要がある場合に重要です。 したがって、従業員または部門(フリーランサー)のいずれかによって穴(NULL値)を取得します。
たとえば、このクエリを使用して、すべての従業員が適切な部門に属しているかどうかを確認できます。 フリーランサーとしてリストされている一部の従業員は、単に部門を示すのを忘れていました。 |
| このフォームでは、どこに適用できるか考えることさえ難しいので、以下にCROSS JOINの例を示します。 |
DepartmentID値がEmployeesテーブルで繰り返された場合、そのような各行は同じIDを持つDepartmentsテーブルの行に接続されました。つまり、Departmentsデータは条件(emp.DepartmentID = dep.ID)が満たされたすべてのレコードと結合されました:

私たちの場合、すべてが正しく判明しました。 DepartmentsテーブルのデータでEmployeesテーブルを補完しました。 私はこれに特に注目しました。なぜなら この動作が不要な場合があります。 デモンストレーションのために、タスクを設定します。各部門について、最後に受け入れられた従業員を表示します。従業員がいない場合は、単に部門名を印刷します。 おそらく、このソリューションはそれ自体を示唆しています-前のリクエストを取得して、結合条件をRIGHT JOINに変更し、さらにフィールドを再配置します。
SELECT dep.ID,dep.Name,emp.ID,emp.Name FROM Employees emp RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID
| ID | お名前 | ID | お名前 |
|---|
| 1 | 運営 | 1000 | イワノフI.I. |
| 2 | 簿記 | 1002 | シドロフS.S. |
| 3 | IT | 1001 | ペトロフP.P. |
| 3 | IT | 1003 | アンドレエフA.A. |
| 3 | IT | 1004 | ニコラエフN.N. |
| 4 | マーケティングと広告 | ヌル | ヌル |
| 5 | 物流 | ヌル | ヌル |
しかし、最後の従業員が承認された行のみが必要な場合、IT部門用に3行を取得しました。 ニコラエフN.N.
この種のタスクは、たとえばサブクエリを使用して解決できます。
SELECT dep.ID,dep.Name,emp.ID,emp.Name FROM Employees emp JOIN ( SELECT MAX(ID) MaxEmployeeID FROM Employees GROUP BY DepartmentID ) lastEmp ON emp.ID=lastEmp.MaxEmployeeID RIGHT JOIN Departments dep ON emp.DepartmentID=dep.ID
| ID | お名前 | ID | お名前 |
|---|
| 1 | 運営 | 1000 | イワノフI.I. |
| 2 | 簿記 | 1002 | シドロフS.S. |
| 3 | IT | 1004 | ニコラエフN.N. |
| 4 | マーケティングと広告 | ヌル | ヌル |
| 5 | 物流 | ヌル | ヌル |
従業員をサブクエリデータと事前に組み合わせることにより、部門への接続に必要な従業員のみを残すことができました。
ここでは、サブクエリの使用にスムーズに進みます。 この形式でそれらを使用することは、直感的なレベルであなたに明らかであると思います。 つまり、サブクエリはテーブルの代わりに置き換えられ、その役割を果たしますが、複雑なことはありません。 サブクエリのテーマに個別に戻ります。
サブクエリが返す内容を個別に確認します。
SELECT MAX(ID) MaxEmployeeID FROM Employees GROUP BY DepartmentID
| MaxEmployeeID |
|---|
| 1005 |
| 1000 |
| 1002 |
| 1004 |
つまり 彼は部門ごとに最後に雇用された従業員の識別子のみを返しました。
接続は上から下に順番に行われ、山から転がる雪玉のように成長します。 まず、接続「Employees emp JOIN(サブクエリ)lastEmp」が発生し、新しい出力セットが形成されます。

次に、「Employees emp JOIN(サブクエリ)lastEmp」(条件付きで「最後の結果」と呼びます)によって取得されたセットと部門、つまり 「LastRIGHT JOIN Departments dep result」:

材料を統合する独立した作業
初心者の場合、各タイプの接続がどのように機能するかを100%理解し、最終的にどのタイプの結果が得られるかを正しく示すまで、各JOINコンストラクトを実行する必要があります。
JOIN接続に関する資料を統合するには、次の手順を実行します。
テーブルの内容を見てみましょう。
SELECT * FROM LeftTable
| LCode | LDescr |
|---|
| 1 | L-1 |
| 2 | L-2a |
| 2 | L-2b |
| 3 | L-3 |
| 5 | L-5 |
SELECT * FROM RightTable
| RCode | RDescr |
|---|
| 2 | B-2a |
| 2 | B-2b |
| 3 | B-3 |
| 4 | B-4 |
ここで、クエリの各行が接続の種類ごとにどのようになったかを自分で考えてみてください(Excelが役立ちます)。
SELECT l.*,r.* FROM LeftTable l JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
|---|
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
SELECT l.*,r.* FROM LeftTable l LEFT JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
|---|
| 1 | L-1 | ヌル | ヌル |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | ヌル | ヌル |
SELECT l.*,r.* FROM LeftTable l RIGHT JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
|---|
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| ヌル | ヌル | 4 | B-4 |
SELECT l.*,r.* FROM LeftTable l FULL JOIN RightTable r ON l.LCode=r.RCode
| LCode | LDescr | RCode | RDescr |
|---|
| 1 | L-1 | ヌル | ヌル |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | ヌル | ヌル |
| ヌル | ヌル | 4 | B-4 |
SELECT l.*,r.* FROM LeftTable l CROSS JOIN RightTable r
| LCode | LDescr | RCode | RDescr |
|---|
| 1 | L-1 | 2 | B-2a |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 3 | L-3 | 2 | B-2a |
| 5 | L-5 | 2 | B-2a |
| 1 | L-1 | 2 | B-2b |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 2 | B-2b |
| 5 | L-5 | 2 | B-2b |
| 1 | L-1 | 3 | B-3 |
| 2 | L-2a | 3 | B-3 |
| 2 | L-2b | 3 | B-3 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | 3 | B-3 |
| 1 | L-1 | 4 | B-4 |
| 2 | L-2a | 4 | B-4 |
| 2 | L-2b | 4 | B-4 |
| 3 | L-3 | 4 | B-4 |
| 5 | L-5 | 4 | B-4 |
JOIN接続についてもう一度
複数の順次結合操作を使用する別の例。 ここでは、意図的に繰り返しは行われませんでした。同じ素材を捨てないでください。 ;)しかし、「繰り返しは学習の母ではありません。」
複数の接続操作が使用される場合、この場合、それらは上から下に順番に適用されます。 大まかに言えば、各接続の後に新しいセットが作成され、この拡張セットで次の接続がすでに行われています。 簡単な例を考えてみましょう。
SELECT e.ID, e.Name EmployeeName, p.Name PositionName, d.Name DepartmentName FROM Employees e LEFT JOIN Departments d ON e.DepartmentID=d.ID LEFT JOIN Positions p ON e.PositionID=p.ID
最初に、Employeesテーブルのすべてのエントリが選択されました。
SELECT e.* FROM Employees e
次に、Departmentsテーブルへの接続がありました。
SELECT e.*,
次は、このセットとPositionsテーブルの接続です。
SELECT e.*,
つまり 次のようになります。

そして最後に、印刷を要求しているデータを返します。
SELECT e.ID,
したがって、WHEREフィルターとORDER BYソートを、取得したこのすべてのセットに適用できます。
SELECT e.ID,
| ID | EmployeeName | PositionName | 部署名 |
|---|
| 1004 | ニコラエフN.N. | プログラマー | IT |
| 1001 | ペトロフP.P. | プログラマー | IT |
つまり、最後に受信したセットは、基本的なクエリを実行できる同じテーブルです。
SELECT [DISTINCT] _ * FROM WHERE ORDER BY _
つまり、以前に1つのテーブルのみがソースとして機能していた場合、この場所を式に置き換えるだけです。
Employees e LEFT JOIN Departments d ON e.DepartmentID=d.ID LEFT JOIN Positions p ON e.PositionID=p.ID
その結果、同じ基本的なリクエストを受け取ります:
SELECT e.ID, e.Name EmployeeName, p.Name PositionName, d.Name DepartmentName FROM Employees e LEFT JOIN Departments d ON e.DepartmentID=d.ID LEFT JOIN Positions p ON e.PositionID=p.ID WHERE d.ID=3 AND p.ID=3 ORDER BY e.Name
そして、グループ化を適用します。
SELECT ISNULL(dep.Name,'') DepName, COUNT(DISTINCT emp.PositionID) PositionCount, COUNT(*) EmplCount, SUM(emp.Salary) SalaryAmount, AVG(emp.Salary) SalaryAvg
ご覧のとおり、私たちはまだ基本的な構造を中心に展開していますが、最初にそれらを理解することが非常に重要である理由が明確になればと思います。
そして、私たちが見たように、クエリでは、テーブルの代わりにサブクエリを使用できます。同様に、サブクエリはサブクエリ内にネストできます。そして、これらすべてのサブクエリも基本的な構造です。つまり、基本設計は、リクエストを作成するブリックです。CROSS JOINを使用した有望な例
CROSS JOIN結合を使用して、従業員数、部門、職位をカウントしましょう。各部門について、既存のすべての投稿をリストします。 SELECT d.Name DepartmentName, p.Name PositionName, e.EmplCount FROM Departments d CROSS JOIN Positions p LEFT JOIN ( SELECT DepartmentID,PositionID,COUNT(*) EmplCount FROM Employees GROUP BY DepartmentID,PositionID ) e ON e.DepartmentID=d.ID AND e.PositionID=p.ID ORDER BY DepartmentName,PositionName
 この場合、最初にCROSS JOINを使用して接続が行われ、次に、結果セットに対してLEFT JOINを使用してサブクエリからのデータとの接続が行われました。LEFT JOINのテーブルの代わりに、サブクエリを使用しました。サブクエリは括弧で囲まれ、エイリアス(この場合は「e」)が割り当てられます。つまり、この場合、結合はテーブルではなく、次のクエリの結果で発生します。
この場合、最初にCROSS JOINを使用して接続が行われ、次に、結果セットに対してLEFT JOINを使用してサブクエリからのデータとの接続が行われました。LEFT JOINのテーブルの代わりに、サブクエリを使用しました。サブクエリは括弧で囲まれ、エイリアス(この場合は「e」)が割り当てられます。つまり、この場合、結合はテーブルではなく、次のクエリの結果で発生します。 SELECT DepartmentID,PositionID,COUNT(*) EmplCount FROM Employees GROUP BY DepartmentID,PositionID
| DepartmentID | 位置ID | 雇用者 |
|---|
| ヌル | ヌル | 1 |
| 2 | 1 | 1 |
| 1 | 2 | 1 |
| 3 | 3 | 2 |
| 3 | 4 | 1 |
エイリアス「e」とともに、DepartmentID、PositionID、およびEmplCountという名前を使用できます。実際、さらにサブクエリは、テーブルがその場所に立っている場合と同じように動作します。したがって、テーブルと同様に、サブクエリが返すすべての列名は明示的に指定する必要があり、繰り返さないでください。WHERE句を使用した通信
たとえば、JOIN接続を使用して次のクエリを書き換えます。 SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name FROM Employees emp JOIN Departments dep ON emp.DepartmentID=dep.ID
WHERE句を通じて、次の形式を取ります。 SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name FROM Employees emp, Departments dep WHERE emp.DepartmentID=dep.ID
ここで悪いのは、テーブルを結合するための条件(emp.DepartmentID = dep.ID)がフィルター条件(emp.DepartmentID = 3)と混在していることです。次に、CROSS JOINの作成方法を見てみましょう。 SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name FROM Employees emp CROSS JOIN Departments dep
WHERE句を通じて、次の形式を取ります。 SELECT emp.ID,emp.Name,emp.DepartmentID,dep.ID,dep.Name FROM Employees emp, Departments dep WHERE emp.DepartmentID=3
つまり
この場合、単にEmployeesテーブルとDepartmentsテーブルの結合条件を指定しませんでした。なぜこのリクエストが悪いのですか?他の誰かがあなたのリクエストを見て、「リクエストを書いた人がここに条件を追加するのを忘れたようです(emp.DepartmentID = dep.ID)」と考えて、喜んでこの条件を追加します。その結果、あなたが考えたことは、あなたはCROSS JOINを意味します。したがって、デカルト結合を作成する場合は、これがCROSS JOINコンストラクトを使用していることを明示することをお勧めします。クエリオプティマイザーの場合、接続をどのように実装するか(WHEREまたはJOINを使用)は問題ではなく、まったく同じ方法で実行できます。しかし、コードがわかりやすいという理由から、現代のDBMSではWHERE句を使用してテーブルを結合しないようにすることをお勧めします。接続にWHERE条件を使用します。JOIN構造がDBMSに実装されている場合、マナーが悪いと思います。WHERE条件はセットのフィルター処理に使用され、接続に使用される条件とフィルター処理を行う条件を混在させる必要はありません。しかし、WHEREを介した接続の実装が不可欠であるという結論に達した場合、もちろん優先順位は解決されたタスクと「すべての基盤で地獄に」にあります。UNION結合-クエリ結果の垂直結合の操作
水平結合と垂直結合というフレーズを具体的に使用しています。新参者はしばしばこれらの操作の本質を誤解し、混乱させることに気付きました。最初に、ディレクターのレポートの最初のバージョンをどのように作成したかを思い出しましょう。 SELECT '' Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=1
したがって、グループ化操作があることを知らなかったが、UNION ALLを使用してクエリ結果を結合する操作があることを知っている場合、次のようにこれらすべてのクエリを接着できます。 SELECT '' Info, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount FROM Employees WHERE DepartmentID=1

つまり
UNION ALLを使用すると、さまざまなクエリによって取得された結果を1つの共通の結果に結合できます。したがって、各リクエストの列の数は同じでなければならず、これらの列のタイプも互換性がなければなりません。行の下の行、番号の下の番号、日付の下の日付など。理論のビット
MS SQLは、次のタイプの垂直結合を実装します。| 運営 | 説明 |
|---|
| UNION ALL | 結果には、両方のセットのすべての行が含まれます。(A + B) |
| UNION | 2つのセットの一意の行のみが結果に含まれます。DISTINCT(A + B) |
| を除く | 結果は、下位セットにない、上位セットの一意の行です。2セットの違い。DISTINCT(AB) |
| 交差 | 両方のセットに存在する一意の文字列のみが結果に含まれます。2セットの交差点。DISTINCT(A&B) |
これはすべて、良い例で理解しやすくなっています。2つのテーブルを作成し、それらにデータを入力します。 CREATE TABLE TopTable( T1 int, T2 varchar(10) ) GO CREATE TABLE BottomTable( B1 int, B2 varchar(10) ) GO INSERT TopTable(T1,T2)VALUES (1,'Text 1'), (1,'Text 1'), (2,'Text 2'), (3,'Text 3'), (4,'Text 4'), (5,'Text 5') INSERT BottomTable(B1,B2)VALUES (2,'Text 2'), (3,'Text 3'), (6,'Text 6'), (6,'Text 6')
内容を見てみましょう。 SELECT * FROM TopTable
| T1 | T2 |
|---|
| 1 | テキスト1 |
| 1 | テキスト1 |
| 2 | テキスト2 |
| 3 | テキスト3 |
| 4 | テキスト4 |
| 5 | テキスト5 |
SELECT * FROM BottomTable
| B1 | B2 |
|---|
| 2 | テキスト2 |
| 3 | テキスト3 |
| 6 | テキスト6 |
| 6 | テキスト6 |
UNION ALL
SELECT T1 x,T2 y FROM TopTable UNION ALL SELECT B1,B2 FROM BottomTable

UNION
SELECT T1 x,T2 y FROM TopTable UNION SELECT B1,B2 FROM BottomTable
基本的に、UNIONはUNION ALLとして表すことができ、それにDISTINCT操作が適用されます。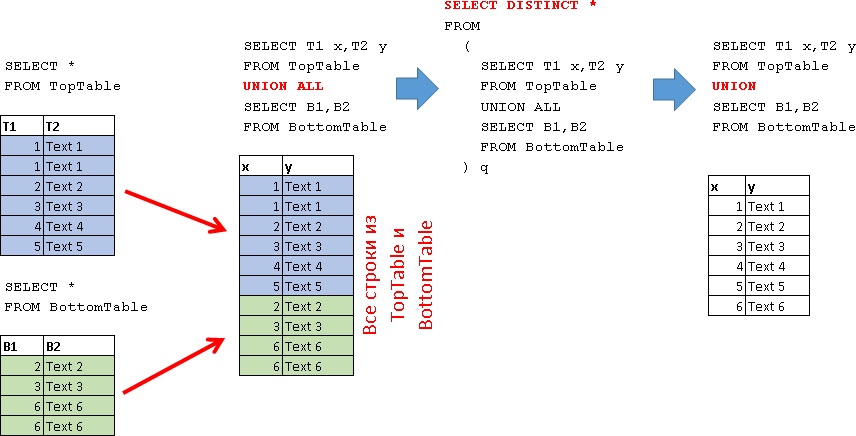
を除く
SELECT T1 x,T2 y FROM TopTable EXCEPT SELECT B1,B2 FROM BottomTable
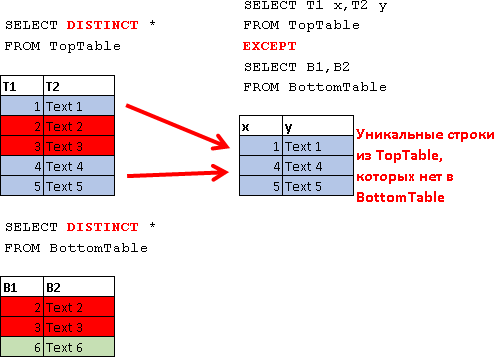
交差
SELECT T1 x,T2 y FROM TopTable INTERSECT SELECT B1,B2 FROM BottomTable

UNION接続に関する会話を終了する
これは基本的に垂直結合に関するもので、JOIN結合よりもはるかに簡単です。ほとんどの場合、UNION ALLは実際にアプリケーションを見つけますが、他のタイプの垂直関連付けもアプリケーションを見つけます。いくつかの操作が垂直方向に組み合わされているため、上から下に順番に実行されるとは限りません。別のテーブルを作成し、例を使用してこれを検討してみましょう。 CREATE TABLE NextTable( N1 int, N2 varchar(10) ) GO INSERT NextTable(N1,N2)VALUES (1,'Text 1'), (4,'Text 4'), (6,'Text 6')
たとえば、単純に次のように記述した場合: SELECT T1 x,T2 y FROM TopTable EXCEPT SELECT B1,B2 FROM BottomTable INTERSECT SELECT N1,N2 FROM NextTable
次に取得します。| x | y |
|---|
| 1 | テキスト1 |
| 2 | テキスト2 |
| 3 | テキスト3 |
| 4 | テキスト4 |
| 5 | テキスト5 |
つまり
INTERSECTが最初に実行され、EXCEPTの後に実行されたことがわかります。論理的には逆になっているはずですが、つまり 上から下に移動します。私はめったにこれらのユニオン操作を使用せず、さらに少ないので、結合を実行する順序を考えないように、括弧で結合のシーケンスを指定することができます。交差点: ( SELECT T1 x,T2 y FROM TopTable EXCEPT SELECT B1,B2 FROM BottomTable ) INTERSECT SELECT N1,N2 FROM NextTable
今、私は欲しいものを手に入れました。この構文が他のDBMSで機能するかどうかはわかりませんが、サブクエリを使用する場合: SELECT x,y FROM ( SELECT T1 x,T2 y FROM TopTable EXCEPT SELECT B1,B2 FROM BottomTable ) q INTERSECT SELECT N1,N2 FROM NextTable
ORDER BYを使用する場合、ソートは最終セットに適用されます。 SELECT T1 x,T2 y FROM TopTable UNION ALL SELECT B1,B2 FROM BottomTable UNION ALL SELECT B1,B2 FROM BottomTable ORDER BY x DESC
並べ替えタスクでは、最初のクエリで指定された列エイリアスを使用する方が便利です。UNIONユニオンで何かをプレイする場合、UNIONユニオンについて最も重要なことを書いた。ご注意 Oracleにも同じ種類の接続がありますが、唯一の違いはEXCEPT操作で、MINUSと呼ばれます。
サブクエリを使用する
私は最後にサブクエリを残しました、なぜなら それらを使用する前に、クエリを正しく作成する方法を学ぶ必要があります。さらに、場合によっては、サブクエリの使用を完全に回避でき、基本的な構造を省くことができます。間接的に、FROMブロックで既にサブクエリを使用しています。そこでは、サブクエリによって返される結果は、基本的に新しいテーブルの役割を果たします。ここでやめるのはほとんど意味がないと思います。2つのサブクエリを組み合わせた抽象的な例を考えてみましょう。 SELECT q1.x1,q1.y1,q2.x2,q2.y2 FROM ( SELECT T1 x1,T2 y1 FROM TopTable EXCEPT SELECT B1,B2 FROM BottomTable ) q1 JOIN ( SELECT T1 x2,T2 y2 FROM TopTable EXCEPT SELECT N1,N2 FROM NextTable ) q2 ON q1.x1=q2.x2
すぐにはっきりしない場合は、そのような要求を部分的に分解します。 つまり
最初のサブクエリ「q1」が返すもの、次に2番目のサブクエリ「q2」が返すものを見てから、サブクエリ「q1」と「q2」の結果に対してJOIN操作を実行します。WITH句
これは、特に大規模なサブクエリを処理する場合に非常に便利な設計です。比較: SELECT q1.x1,q1.y1,q2.x2,q2.y2 FROM ( SELECT T1 x1,T2 y1 FROM TopTable EXCEPT SELECT B1,B2 FROM BottomTable ) q1 JOIN ( SELECT T1 x2,T2 y2 FROM TopTable EXCEPT SELECT N1,N2 FROM NextTable ) q2 ON q1.x1=q2.x2
WITHで書かれた同じもの: WITH q1 AS( SELECT T1 x1,T2 y1 FROM TopTable EXCEPT SELECT B1,B2 FROM BottomTable ), q2 AS( SELECT T1 x2,T2 y2 FROM TopTable EXCEPT SELECT N1,N2 FROM NextTable )
ご覧のとおり、大きなサブクエリがレンダリングされ、WITHブロックに名前が付けられているため、メインリクエストのテキストをアンロードして理解できるようになっています。ViewEmployeesInfoビューが使用された前の部分の例を思い出してください。 CREATE VIEW ViewEmployeesInfo AS SELECT emp.*,
そして、このビューを使用したクエリ: SELECT DepartmentName, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount, AVG(Salary) SalaryAvg FROM ViewEmployeesInfo emp GROUP BY DepartmentID,DepartmentName ORDER BY DepartmentName
本質的に、WITHを使用すると、ビュー内のテキストをリクエストに直接配置できます。意味は同じです: WITH cteEmployeesInfo AS( SELECT emp.*,
作成されたビューの場合のみ、さまざまなリクエストから使用できます。ビューはデータベースレベルで作成されます。一方、WITHブロックで実行されるサブクエリは、このクエリのフレームワーク内でのみ表示されます。WITHの使用はCTE式とも呼ば
れます。同じクエリに複数回アクセスする必要がある場合、Common Table Expressions(CTE)はコードの量を大幅に削減できます。CTEは、単一の要求の一部として作成され、スキーマオブジェクトとして保存されないビューの役割を果たします。
CTEには別の重要な目的があり、その助けを借りて、再帰クエリを作成できます。
再帰クエリの小さな例を紹介します。別の従業員への従属を考慮に入れた従業員を表示します(覚えている場合、同じテーブルを参照するEmployeesテーブルにキーがあります)。 WITH cteEmpl AS( SELECT ID,CAST(Name AS nvarchar(300)) Name,1 EmpLevel FROM Employees WHERE ManagerID IS NULL
| ID | お名前 | 社員レベル |
|---|
| 1000 | イワノフI.I. | 1 |
| 1002 | _____ Sidorov S.S. | 2 |
| 1003 | _____ Andreev A.A. | 2 |
| 1005 | _____アレクサンドロフA.A. | 2 |
| 1001 | __________ Petrov P.P. | 3 |
| 1004 | __________ Nikolaev N.N. | 3 |
明確にするために、スペースはアンダースコアに置き換えられます。この教科書の枠組みの中で、再帰クエリがどのように構築されるかは考えません。これは初心者にとってはかなり具体的なトピックであり、今のところ完全に役に立たないと思います。再帰クエリの研究に着手する前に、私が説明したすべての基本構造を使用する方法を必ず学習する必要があります。この基礎がなければ、これ以上先に進むべきではありません。ほとんどの場合、複雑なクエリを作成するには基本的な構造の知識で十分です。サブクエリに関する会話を続ける
サブクエリの使用方法を見てみましょう。また、メインリクエストのエイリアスを使用してサブクエリにパラメータを渡します。ここでは、説明を深く掘り下げません。この段階までに、データを扱う原則を考えて理解することを既に学んでいるはずです。必ず練習し、例に従って結果を試して理解してください。理解するには、各例を自分で感じる必要があります。SELECTブロックでサブクエリを使用できます
レポートに戻る: SELECT DepartmentID, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount, AVG(Salary) SalaryAvg
ここで、部門の名前は、パラメーター付きのサブクエリを使用して取得することもできます。 SELECT (SELECT Name FROM Departments dep WHERE dep.ID=emp.DepartmentID) DepartmentName, COUNT(DISTINCT PositionID) PositionCount, COUNT(*) EmplCount, SUM(Salary) SalaryAmount, AVG(Salary) SalaryAvg FROM Employees emp
この場合、サブクエリ(SELECT Name FROM Departments dep WHERE dep.ID = emp.DepartmentID)が4回実行されます。各emp.DepartmentID値に対して、この場合のサブクエリは1行と1列のみを返す必要があります。サブクエリに多数の行がある場合は、TOPまたはその中の集約関数を使用して、最終的に1行になります。たとえば、部門ごとに、最後に受け入れられた従業員のIDを取得します。 SELECT ID, Name,
良くないですよね? なぜなら
3つのサブクエリはそれぞれ(返された行ごとに)4回実行され、合計12のサブクエリが実行されます。したがって、少なくともパラメーターを指定したサブクエリを使用することをお勧めします。次のように、単純な結合操作を使用してリクエストを表現できない場合 このような場合にサブクエリを使用すると、クエリの実行速度が大幅に低下する可能性があります。パラメーターを指定したサブクエリは、渡されたパラメーターごとに実行されるためです。サブクエリを適用する
最後の例のMS SQL: SELECT ID, Name,
APPLY構造を適用できます。これには、2つの形式があります-相互適用と外部適用。APPLY構文を使用すると、この例のように、各部門で受け入れられた最後の従業員のIDと名前の両方を取得する必要がある場合に、多くのサブクエリを削除できます。 SELECT ID, Name, empInfo.LastEmpID, empInfo.LastEmpName FROM Departments dep CROSS APPLY ( SELECT TOP 1 ID LastEmpID,Name LastEmpName FROM Employees emp WHERE emp.DepartmentID=dep.ID ORDER BY emp.ID DESC ) empInfo
| ID | お名前 | Lastempid | LastEmpName |
|---|
| 1 | 運営 | 1000 | イワノフI.I. |
| 2 | 簿記 | 1002 | シドロフS.S. |
| 3 | IT | 1004 | ニコラエフN.N. |
ここでは、CROSS APPLYブロックのサブクエリが、Departmentsテーブルの各行の値に対して実行されます。行のサブクエリが返されない場合、この部門は結果リストから除外されます。Departmentsテーブルのすべての行を返す場合は、このOUTER APPLYステートメントの次の形式を使用します。 SELECT ID, Name, empInfo.LastEmpID, empInfo.LastEmpName FROM Departments dep OUTER APPLY ( SELECT TOP 1 ID LastEmpID,Name LastEmpName FROM Employees emp WHERE emp.DepartmentID=dep.ID ORDER BY emp.ID DESC ) empInfo
| ID | お名前 | Lastempid | LastEmpName |
|---|
| 1 | 運営 | 1000 | イワノフI.I. |
| 2 | 簿記 | 1002 | シドロフS.S. |
| 3 | IT | 1004 | ニコラエフN.N. |
| 4 | マーケティングと広告 | ヌル | ヌル |
| 5 | 物流 | ヌル | ヌル |
一般に、かなり便利な演算子で、状況によってはリクエストを大幅に簡素化します。このサブクエリは、結果セットの各行に対しても機能します。渡された各パラメーターに対して、多くのサブクエリを使用する場合よりもはるかに効率的に機能します。APPLYを使用する場合のその他の詳細については、たとえば、サブクエリが複数の行を返す場合のように、自分で理解できると思います。さて、私はこれについて話し始めたので、自己分析の小さな例を挙げます。 SELECT dep.ID,dep.Name,pos.PositionID,pos.PositionName FROM Departments dep CROSS APPLY ( SELECT ID PositionID,Name PositionName FROM Positions ) pos
WHEREブロックでのサブクエリの使用
たとえば、3人以上の従業員がいる部門を取得します。 SELECT * FROM Departments dep WHERE (SELECT COUNT(*) FROM Employees emp WHERE emp.DepartmentID=dep.ID)>2
ここでは比較演算子を使用しているため、サブクエリは最大で1つの行と1つの値を返す必要があります。また、SELECTブロックでサブクエリが使用されている場合。EXISTSおよびNOT EXISTSコンストラクト
サブクエリの条件に一致するレコードがあるかどうかを確認できます。
ここではすべてが単純です。サブクエリが少なくとも1つの行を返す場合、EXISTSはTrueを返し、サブクエリが行を返さない場合はFalseを返します。NOT EXISTS-結果の逆。サブクエリを使用したINおよびNOT IN構文
その前に、値の列挙でINを調べました。これらの値のリストを返すサブクエリで使用することもできます。
サブクエリで条件(DepartmentID IS NOT NULL)を使用してNULL値を除外したことに注意してください。この場合のNULL値は同様に危険です-詳細については、第2部のIN構造の説明を参照してください。グループ比較操作ALLおよびANY
これらの演算子は非常に扱いにくいため、慎重に使用する必要があります。一般的に、私の練習ではこれらをほとんど使用せず、条件でINまたはEXISTS演算子を使用することを好みます。ALLおよびANY演算子は、サブクエリが返した各値との適合性を確認する必要がある場合に使用されます。EXISTS演算子と同様に、サブクエリでのみ機能します。たとえば、各部門で、同じ部門で働くすべての従業員に対して複数のRFPを持つ従業員を選択します。この目的のために、すべてを適用します。 SELECT ID,Name,DepartmentID,Salary FROM Employees e1 WHERE e1.Salary>ALL( SELECT e2.Salary FROM Employees e2 WHERE e2.DepartmentID=e1.DepartmentID
| ID | お名前 | DepartmentID | 給料 |
|---|
| 1000 | イワノフI.I. | 1 | 5000 |
| 1002 | シドロフS.S. | 2 | 2500 |
| 1003 | アンドレエフA.A. | 3 | 2000年 |
| 1005 | アレクサンドロフA.A. | ヌル | 2000年 |
ここでは、e1.Salaryがサブクエリが返したe2.Salaryの値よりも大きいことを確認します。サブクエリが単一の行を返さなかった従業員でさえも戻ってきたのはなぜだと思いますか?ロジックがこれであるため-エントリがないため、チェックするものがありません。これは、私がすでに最も多いことを意味します。 )))このトリックはここに隠されています。よりよく理解するために、ここでALL演算子をNOT EXISTS演算子に置き換える方法を見てみましょう。 SELECT ID,Name,DepartmentID,Salary FROM Employees e1 WHERE NOT EXISTS( SELECT * FROM Employees e2 WHERE e2.DepartmentID=e1.DepartmentID
つまり
ここでは、同じことを他の言葉でのみ表現しました。「同じ部門の従業員がいない従業員を、彼よりも高い給料で戻す」。ここで、サブクエリがデータを返さない場合にALLが真の値を返す理由が明らかになります。また、ALLの場合、サブクエリからNULL値を除外することが重要です。そうしないと、各値のチェック結果が未定義になる可能性があります。この場合、ANDを使用するときのロジックALLとロジックを比較します。式(Salary> 1000 AND Salary> 1500 AND Salary> NULL)はNULLを返します。しかし、ANY(別名SOME)では、それは異なります: SELECT ID,Name,DepartmentID,Salary FROM Employees e1 WHERE e1.Salary>ANY(
| ID | お名前 | DepartmentID | 給料 |
|---|
| 1003 | アンドレエフA.A. | 3 | 2000年 |
ANY演算子では、サブクエリが条件と比較できるレコードを返すことが重要です。 なぜなら
IT部門を除き、すべての部門で1人の従業員のみが座り、Andreev AAのみが戻りました。そのRFPは同じ部門の他の従業員のRFPと比較できました。 つまり
ここでは、同じ部門のどのRFP従業員よりもRFPが大きい人を引き抜きました。理解を深めるために、EXISTSのあるものを見てみましょう。 SELECT ID,Name,DepartmentID,Salary FROM Employees e1 WHERE EXISTS( SELECT * FROM Employees e2 WHERE e2.DepartmentID=e1.DepartmentID
ここでの意味は、「この部門のRFPがこの従業員のRFPよりも低い従業員が少なくとも何人かいます」になりました。この形式では、サブクエリがデータを返さない場合にANYがfalse値を返す理由が明らかになります。ここでは、サブクエリ内のNULL値の存在はそれほど危険ではありません。任意の値と比較します。この場合、ORを使用するときのロジックと任意のロジックを比較します。expression(Salary> 1000 OR Salary> 1500 OR Salary> NULL)は、少なくとも1つの条件が満たされた場合にtrueを返すことができます。ANYを使用して同等性を比較する場合、INを使用して表すことができます。 SELECT * FROM Departments WHERE ID=ANY(SELECT DISTINCT DepartmentID FROM Employees)
ここでは、従業員がいるすべての部門を返します。したがって、これは次と同等になります。 SELECT * FROM Departments WHERE ID IN(SELECT DISTINCT DepartmentID FROM Employees)
ご覧のとおり、ALLおよびANYは他の演算子を使用して表現できます。しかし、場合によっては、それらを使用することでリクエストを読みやすくすることができるため、状況を把握するために、適切なケースでそれらを認識して適用する必要があります。つまり
リクエストを作成するとき、「POが最も多い従業員を選択する」ように求められたため、リクエストを作成できます。 SELECT * FROM Employees e1 WHERE e1.Salary>ALL(SELECT e2.Salary FROM Employees e2 WHERE e2.ID<>e1.ID AND e2.Salary IS NOT NULL)
意味を同様の「自分のスタッフ以上の従業員がいない従業員を選択する」に置き換えません。 SELECT * FROM Employees e1 WHERE NOT EXISTS(SELECT * FROM Employees e2 WHERE e2.Salary>e1.Salary)
これもまた、SQL言語はもともと一般ユーザー向けの言語として考えられていたため、さまざまな方法で自分の考えを表現できることを示しています。サブクエリについてのもう少しの言葉
サブクエリは、CASEコンストラクトをチェックインするために、他の多くのブロック(HAVINGブロックなど)でも使用できます。一般的に、あなたの想像力はすでに十分にあります。しかし、まず第一に、SELECT演算子の標準的な構造に関する問題を常に解決しようとすることをお勧めします。これが機能しない場合は、サブクエリの助けを借ります。したがって、この教科書では、3つの部分を基本構造の検討に当て、1つのセクションのみをサブクエリに割り当てました。次のように、サブクエリでSELECTの説明を開始できないと思います。サブクエリがあることを知っているが、基本構造を所有していないため、初心者でもそのような3階建ての構造(サブクエリ-サブクエリのサブクエリ)を積み上げることができます。しかし、基本を知っている場合、これらの3階建ての構造はすべて、たとえば化合物やグループ化を使用した単一のクエリで表現できます。私はサブクエリが悪いと言っているのではありません、なぜなら それらの助けを借りて、特定の問題をよりエレガントに解決できる場合もあります。ここでは、まずサブ構造も構築されているため、基本構造を自信を持って使用する方法を学ぶ必要があると言います。そのため、すべての設計は、意図した目的に使用される場合に優れています。おわりに
これで、SELECTステートメントのすべての基本的な構成が完了しました。数えれば、それほど多くはありませんが、それぞれを確実に所有し、それらを一緒に使用する能力があるため、ほとんどすべての情報をデータベースに保存することができます。この資料は、さまざまなDBMS(Paradox DBMSから始まる)で既に10年以上前に使用されているSQL言語の実際の経験に基づいて作成されました。このチュートリアルでは、データサンプリングに使用されるSQL言語のすべての基本構造の本質を可能な限り簡単な方法で説明しようとしました。私は、このチュートリアルがIT専門家だけでなく、幅広い人々に理解できるように説明しようとしました。私が成功し、この資料があなたが最初の一歩を踏み出すのに役立つか、あなたがこれまでに与えられなかった特定のデザインを理解するのに役立つことを願っています。いずれにせよ、この資料に慣れるために時間を割いてくれた皆さんに感謝します。次のパートでは、データ変更演算子に関する一般的な用語の概要を説明します。一般的に、この情報とDDLの知識は誰もが必要としないため(主にIT専門家)-ほとんどの人はSELECTステートメントを使用してデータを選択する方法を学ぶためにSQLを正確に学びます。次の部分は最終版になると思います。この時点までに得られたすべての知識は、次のパートでも役立ちます。データを変更するための複雑な構造を正しく記述するためには、必ずSELECTステートメントの構造を使用する必要があります。たとえば、テーブル内の行のグループを削除または変更する前に、このデータを正しく選択する必要があります。したがって、次の部分にはSELECT構造も含まれます。SELECTステートメントのためにSQLを正確に研究している人々にとっては興味深いと思います。自信を持ってクエリを作成するには、理論を理解するだけでは十分ではありません。まだたくさん練習する必要があります。この目的のために、「SQL-EX.RU-SQL言語の実践的知識」という有名なサイトをお勧めします。このサイトには、いくつかのデモデータベースが含まれており、最も単純なタスクの解決から始めて、最もトリッキーなクエリの作成を練習する機会を提供します。SQL言語に関するトレーニング資料も多数あります。さらに、格付けの問題を解決するために競い合い、最終的には理論の知識だけでなく、実践的なスキルを証明する証明書を取得できます。基本構造の使用方法を自信を持って学んだ後、以下を個別に学習することをお勧めします。- 以下を使用できるようにするOVER句。
- GROUP BYを使用しない集計関数(COUNT、SUM、MIN、MAX、AVG)。
- ランキング関数:ROW_NUMBER()、RANK()およびDENSE_RANK();
- 分析関数:LAG()およびLEAD()、FIRST_VALUE()およびLAST_VALUE();
- GROUP BY ROLLUP(...)、GROUP BY GROUPING SETS(...)、...およびこれらの目的で使用される補助関数を計算できる構造を研究するため:GROUPING_ID()およびGROUPING();
- PIVOT、UNPIVOTを構築します。
これに関するすべての簡単な情報は、「付録1-SELECTオペレーターのボーナス」および「付録2-OVERおよび分析関数」の5番目のパートに記載されています。これらすべてに関する追加情報は、同じMSDNライブラリでインターネット上で簡単に見つけることができます。学習で頑張ってください。パート5-habrahabr.ru/post/256169