時間が経ち、マルチセルラープロセッサは成長を続け、発展します。 ただし、これまでのところ、それは増殖せず、4つのセルのみで構成されていますが、これは彼より先です。 この記事では、新しいMulticlet R1プロセッサの主な機能、その特徴と機能について説明し、新世代のプロセッサと王朝の祖先であるMulticlet P1プロセッサを比較します。
プロセッサーのリリースの歴史的な瞬間を簡単に調べ、プロセッサーの理論的基礎を簡単に見て、新しいプロセッサーの機能とその主な機能に注意を払い、プロセッサーP1とR1を比較し、R1の最初の製品のプロトタイプを示し、最後に小さな発表を行います。
図1. R1プロセッサのシリコンウェーハ
1.作成の歴史Multiclet Companyは2010年に設立されました。 プロジェクトの開発を考慮して、2001年からN.V. Streltsovの指揮の下で実施されたウラル建築研究所の焼結コンピューターは、新しいロシアアーキテクチャを備えた最初のプロセッサーを作成するための一歩を踏み出しました。 そして、すべての努力の結果、ユニバーサルマルチセルラーアーキテクチャの最初の代表であるMulticlet P1プロセッサが生まれました。 文字「P」はパフォーマンスを表します。 プロセッサのリリース後、デバッグキットの2つのバージョンが作成され、その後、フォリガー、Key_P1情報保護デバイスを含むいくつかのシリアルデバイスが作成されました。 何か新しいことを試してみたいというユーザーの活発な仕事がありました。 このアクティビティの結果は、タッチスクリーン、非同期モーターの制御、高度計、3軸センサーアナライザーなどの使用例です。
しかし、もちろん、新しいレベルに上げる必要がありました。 そして2014年、R1-1と呼ばれる動的再構成を備えたプロセッサが誕生しました。 テスト結果に基づいて、この改訂版はプロトタイプに組み込まれ、2014年12月にR1プロセッサがリリースされ、2015年3月からプラスチックケースで利用可能になりました。これがこの記事で説明するプロセッサです。
エカテリンブルクでマルチセルラープロセッサが開発されており、クリスタルはマレーシアのSilTerra工場で焼かれています。
図2. R1プロセッサー
2.アーキテクチャの簡単な基本R1プロセッサは、マルチセルラーアーキテクチャの最初の代表と同様に、4つのセルで構成されています。 次の基本原則がアーキテクチャに組み込まれています。
- セルは独立していて同一です
- 誰も、何も細胞を制御せず、中央制御装置はありません
- セルは、任意の量の任意の構成で結合できます
- データ上の命令の直接接続(命令は、命令の引数として直接示され、その結果が必要です)
- 同じプログラムを任意の数のセルで実行できます
- 作業があるときに作業します(データがない場合、それらに依存する命令は実行されません)
- 実行する準備ができているすべてのコマンドが同時に実行されます(各メジャーで、各セルの各ブロックALU_INTEGER、ALU_FLOAT、DMSなどから1コマンドを実行できます)
- 動的なリソース割り当て
プロセッサユニット-セルの構成を検討してください。 プロセッサセルR1は、命令サンプリングおよび分配ユニット(IDU)、制御ユニットおよび命令デコーダ(CU)、バッファデバイス(BUF)、スイッチングデバイス(SU)、結果マルチプレクサ、割り込みコントローラ(IC)、およびデバッグユニット(JTAG)を含む-GPR)、汎用レジスターのブロック(GPR)、実行デバイス(EU)、倍精度浮動小数点演算論理装置(以下ALU)(ALU_FLOAT)、整数用ALU(ALU_INTEGER)およびデータメモリアクセスユニットで構成(DMS)。
セルの接続要素は細胞間媒体であり、これはセルのスイッチングデバイスとその入力および出力を接続するワイヤです。 結果のリポジトリ(SU)は結果のリポジトリであり、「細胞間環境」からの情報を保存します。
このアーキテクチャの主な利点は、最大のパフォーマンスと動的なリソース割り当てを実現しながら、低消費電力です。
このアーキテクチャの実装の単純さ、ブロードキャスト配信の原理の使用、分岐予測子の複雑なブロックの欠如、キャッシュ、命令の並べ替えなどにより、低消費電力が実現します。
「直線上」のマルチセルアーキテクチャは高速であり、「ターン」では既存のアーキテクチャよりも悪くないという事実により、高いパフォーマンスが実現されます。
プログラム全体は、パラグラフにグループ化された一連の命令です。
マルチセルラーアーキテクチャの段落は、従来のプロセッサアーキテクチャの大きなチームと考えることができます。 パラグラフは「ストレート」であると理解され、パラグラフ間の移行は「ターン」です。
図3.回転の図
アーキテクチャの利点を簡単に説明し、ixbtフォーラムのAlexDiを少し修正して引用します。
「サイクルごとに最大4つの任意の命令の最大64命令の異常な実行、遷移前の遷移の事前計算、遷移ポイント後のコマンドの事前デコード、すべての命令の結果の算術フラグの保存」各クロックサイクルで最大12個のコマンド(それぞれにALU_FLOAT、ALU_INTEGER、DMSの3つの独立したポートを持つ4つのセル)を送信できますが、1つのウェイアウトがあるため、クロックごとに最大4つのコマンドで現在のアーキテクチャ実装で結果を得ることができます。 ギガフロップスのパフォーマンスは、2つの引数(a + bi)*(c + di)の複雑な乗算のコマンドを実行するペースにより、ピーク時に得られます。その結果、1セルあたり6演算、4セルで乗算し、1サイクルあたり24演算になります。 サイクルあたりの操作数に周波数を掛けると(R1の場合は100 MHz)、2.4 GFlopsが得られます。
「マルチセルラープロセッサ-これは何ですか?」という記事で、アーキテクチャに慣れることができ
ます。3.プロセッサーR1の新機能当初、P1プロセッサをわずかに変更することを想定していましたが、改良の過程で、R1はほぼ完全に新しいコアを取得しました。 現在、プログラムメモリはすべてのセルに共通であり、サンプリングメカニズムはそれに応じて変更されています(P1では各セルに独自のプログラムメモリがありました)。 間接アドレス指定が登場し、直接読み取りおよび書き込みコマンドが追加され(優先メカニズムをバイパス)、インデックスレジスタの処理が改善されました。 そして、最も重要なのは、再構成(セルがグループに結合する能力)が登場したことです。
アセンブラコマンドの品揃えが増え、DTCメモリを操作するためのブロックが登場しました。 クロックには8〜12 MHzのクォーツクロッキングで十分ですが、SRAM、SDRAM、PROM、I / Oなどの外部メモリを操作できます。 USBは現在、標準の2.0デバイスで、RTCはボードに搭載されています。 アナログブロックの作業は重要なステップでした。R1プロセッサには、8個の独立した16ビットデルタシグマADCチャネル、48キロサンプル/秒、1 DACチャネルが最大100メガサンプル/秒(システム周波数で動作)が含まれています。 当初は2つのDACチャンネルが存在する予定でしたが、1つの完全に機能するDACチャンネルが判明しました。
R1プロセッサのいくつかの革新について、もう少し詳しく考えてみましょう。 しかし、最初に、アセンブラーの例の段落がどのように見えるかを思い出させてください(P1およびR1の場合、Cで記述できます)。
habr:
getl 1 ; 1
getl 2 ; 2
addl @1, @2 ; 1 + 2
getl 0x10000 ; 0x10000
wrl @2, @1 ; 0x10000
setl #0, @2 ;
jmp habrahabr ;
complete
habrahabr:
getl #0 ;
rdl @1 ; 0x10000
getl 3 ; 3
addl @1, @2 ; 3 + 3
wrl @1, 0x10000 ; 6 0x10000
jmp next
complete
, . .
:
Paragraph:
getl 0x50
wrl @1, 0x10
getl 0x12345
wrl @1, 0x50
setl #0, 0x10
jmp Paragraph1
complete
« »
Paragraph1:
rdl #0 ; 0x50
rdl @1 ; 0x12345
complete
«C »
Paragraph1:
rdl [#0] ; 0x12345
complete
#0 0x10, 0x50 rdl 0x50, 0x12345. .
- , , , .
, , , . ge lt .
:1) : ge ARG1, ARG2 — « »
: «1» ARG1 >= ARG2, 0
2) : lt ARG1, ARG2 — «»
: «1» ARG1 < ARG2, 0
0 3, 4 10, 11 . , :
Paragraph_pie:
var := rdl X ;
ge @var, -1 ; -1, .. 0
lt @var, 3 ; 3
and @1, @2 ; and
jne @1, parag_0to3 ; «1»
ge @var, 3
lt @var, 10
and @1, @2 ; and
jne @1, parag_4to10 ; «1»
ge @var, 10
jne @1, parag_11over ; «1»
complete
, DFADDR, , , switch-case. :
switch(Var)
{
case 1:
func1();
break;
case 2:
func2();
break;
case 3:
func3();
break;
default:
go_to_default();
break;
}
Switch_case0:
setl #DFADDR, go_to_default ; ,
p1:= rdl Var
subl @p1, 1
je @1, func1
subl @p1, 2
je @1, func2
subl @p1,3
je @1, func3
complete
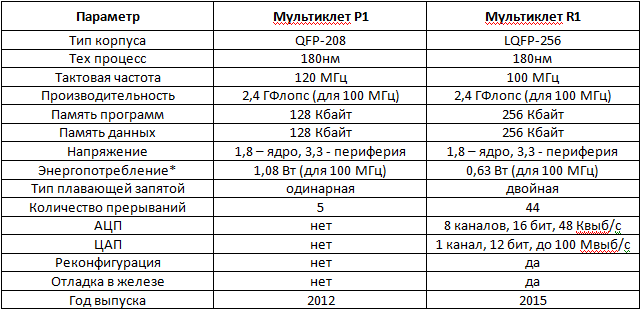
4. P1 R1 . P1 80, 100 120 . R1 PLL 8-12 .
P1 , . R1 , SRAM, SDRAM I/O. R1 .
, , R1 DTC, . R1, P1, .
R1 512 . P1 128 , 128 .
. , R1 .
, R1 – , .. . , , , , « » , 3 , . , , , fork() , , :
3 , main():
main1(), main2(), main3(), :
pre_reconf:
getl #PSW
getl 0x180 ; PSW
or @1, @2
setl #PSW, @1
jmp reconf
complete
reconf:
getl 0x8
patch @1, @1
setq #ICR, @1 ; 1000 ICR ,
getl 0x1
patch @1, @1
setq #ICR, @1 ; 0001
getl 0x6
patch @1, @1
setq #ICR, @1 ; 0110
getl 0x8
getl main3;
patch @2, @1
setq #NEWADDR, @1 ; 3-
getl 0x1
getl main2;
patch @2, @1
setq #NEWADDR, @1 ; 0-
getl 0x6
getl main1
patch @2, @1
setq #NEWADDR, @1 ; 1- 2-
complete
P1 R1:
* 75% DMAC + 25% ADD. R1 FFT 1,05 . P1 .
R1 clock gating , R1 1,5 P1.
, , . Geany.
Windows Linux. .
5. , R1 , , , . 4. 5.
4.

5.
( ) , .
, :
1)
2) – Geany
3) LDM-Systems R1
4) R1
5)
6) Geany
7) R1
8) ( R1)
9) ( R1)
10) ( R1)
11) DTC ( R1)
12) GPIO ( R1)
13) UART, RS-232, RS-485 ( R1)
14) I2C ( R1)
15) SPI, ( R1)
16) PWM ( R1)
17) USB 2.0 Beagle ( R1)
18) Ethernet: ( R1)
19) I2S ( R1)
20) ( R1)
21) ( R1)
22) WH1602A ( R1)
23) HY2B ( R1)
24) GSM SIM800( R1)
25) GLONASS/GPS ( R1)
26) Ethernet (lwip) ( R1)
27) USB ( R1)
28) FreeRTOS ( R1)
29) uClinux ( R1)
, .
!