まえがき
3年生の学生として、コース作業のトピックとして「Neo4jの例を使用したデータベースのグラフ化」を選択しました。 それまではリレーショナルデータベースのみを研究して使用していたので、なぜグラフデータベースが必要なのか、いつその機能を使用したほうがよいのかと思っていました。 インターネット上の多くのサイトを閲覧した後、私は理論のみを発見し、それ以上は発見しませんでした。 理論は必ずしも説得力があるとは限らず、統計をいくつか見たいので、興味があり、コースでこれを行うことに決め、MySQLをNeo4jの対戦相手として選択しました。
だから、この対立に勝つのは誰ですか?
Neo4jとグラフデータベースについて簡単に
Neo4jは、2003年のNeo Technologyの投資から始まったオープンソースのグラフデータベースです。 2007年以降、公開されています。 Neo4jには、ACIDコンプライアンス、クラスタリングの維持、災害復旧など、データベースのすべての機能が備わっています。 今日では、データベースグラフのリーダーです。
ACID(原子性、一貫性、分離、耐久性)-トランザクションの信頼できる操作を保証する一連のプロパティ。
グラフデータベースのコンポーネントは、ノードとエッジです。 独自のフィールドセットで補足することができます。 このようなデータベースのモデルを図に概略的に示します。
Neo4jにデータを保存する
nodestore.dbファイルには、ノードに関する情報を含む特定のサイズのレコードが含まれています。
1.記録がアクティブであることを示すラベル。
2.このノードに含まれる最初の関係へのポインター。
3.このノードに含まれる最初のプロパティへのポインター。
ノードには独自の識別子が含まれていません。 nodestore.dbの各エントリは同じ容量を占有するため、ノードへのポインターを計算できます。
relationshipstore.dbファイルには、関係を説明する同じサイズのエントリも含まれていますが、それらは次の要素で構成されています。
1.記録がアクティブであることを示すラベル。
2.この関係を含むノードへのポインター。
3.この関係が向けられるノードへのポインター。
4.関係のタイプ。
5.(指定されたノード内の)先にある関係へのポインター。
6.背後(特定のノード内)にある関係へのポインター。
7.先にある関係へのポインター(この関係が向けられているノード内)。
8.背後にある関係へのポインター(この関係が向けられているノード内)。
9.この関係の最初のプロパティへのポインター。
充填データ
有効性を比較するには、データベースに同じコンテンツを入力する必要があります。 このデータは大きくする必要があることに注意してください。 少量では、違いは見られません。 したがって、私は300 MB以上のリレーショナルモデルを生成するという目標を設定しました。
ソーシャルネットワークというサブジェクトエリアを選択しました。 ER図を作成し、それに基づいてリレーショナルモデルとグラフモデルを作成しました。
その後、MySQLにデータを入力し、このデータを生成するためのクラスと、新しいデータをデータベースに導入するメソッドを作成しました。
MySQLに入力されたデータの量:
addUsers(100,000); -ユーザー数。
addGroups(200,000); -グループの数。
addPhotos(300,000); -写真の数。
addAudio(250,000); -オーディオ録音の数。
addFriendships(1,000,000); -友達の数。
addMessages(4,000,000); -メッセージの数。
addUserAudio(350,000); -オーディオ録音の数。
addUserGroups(400,000); -ユーザーグループの数。
addUserPhoto(400,000); -ユーザーの写真の数。
次に、このデータをNeo4jに変換しました。 データベースへの入力に時間がかかったことは注目に値します。 自分でこのようなことをすることに決めた場合は、多くの時間を費やすか、テキストフィールドを使用しないという事実に備えてください(私の場合は時間がかかりました)。 その後、情報がNeo4jとMySQLで占める場所を比較しました。 わずかなショックがありました。リレーショナルデータベースでは351.5 MB、グラフでは3.45 GBが必要でした。 それでは、実験を始めましょう。
実験1
実験の説明:識別子によるユーザーの検索時間の測定。
この実験では、特定の回数、ユーザーの識別子を検索しました。 このために、コードを以下に示すメソッドを作成しました。
public static void main(String[] args){
プログラムコードを実行した後、テーブルをコンパイルし、そのためのビルド図を作成しました。 結果は私を喜ばせました。 Neo4jは素晴らしい仕事をしました。
ユーザー数= 100000
|
クエリ数
| MySQLの時間、ミリ秒
| Neo4jの時間、ミリ秒
|
10
| 4
| 9
|
100
| 34
| 76
|
1000
| 286
| 510
|
5000
| 1034
| 1103
|
10,000
| 1340
| 1187
|
30000
| 3390
| 1384
|
60,000
| 6876
| 2102
|
90,000
| 10537
| 3175
|
120,000
| 14033
| 3858
|

実験2
実験の説明:検索の識別子の出現間隔の値の変化でユーザーの友人が費やした時間の測定。
この実験では、有効な識別子値の範囲を選択し、この識別子を持つユーザーの友人を探しました。 次に、この範囲を変更して、もう一度実験しました。 その後、依存グラフを作成したデータに応じて、対応するテーブルを取得しました。

いずれにせよ、ビッグデータを検索するためのグラフベースの時間は、リレーショナルデータの時間よりも短かった。
実験3
実験の説明:ユーザーID値の範囲に応じて、少なくとも1つのグループを管理するユーザーからの写真の総数を見つけるのにかかった時間を測定します。
この実験は前のものと非常に似ていますが、より複雑です。 前の実験での時間値が繰り返しの間にあまり変わらなかった場合、ジャンプはこれではるかに強くなります。 したがって、この実験を3回実施し、対応する表を作成しました。
ユーザー数= 100000、写真数= 300000、ユーザー写真数= 400000
|
| 実験1
| 実験2
| 実験3
|
idの範囲<
| MySQLの時間、ミリ秒
| Neo4jの時間、ミリ秒
| MySQLの時間、ミリ秒
| Neo4jの時間、ミリ秒
| MySQLの時間、ミリ秒
| Neo4jの時間、ミリ秒
|
10
| 299
| 11339
| 164
| 92594
| 456
| 56575
|
100
| 10652
| 2748
| 674
| 2400
| 663
| 2826
|
1000
| 7243
| 4931
| 5433
| 2481
| 5649
| 1942
|
5000
| 22538
| 5521
| 23747
| 2408
| 23522
| 3514
|
10,000
| 47755
| 5627
| 44917
| 2650
| 44992
| 1844
|
30000
| 137572
| 8161
| 33856
| 3108
| 136592
| 3707
|
60,000
| 64002
| 13577
| 300814
| 5004
| 280672
| 6029
|
90,000
| 482329
| 13475
| 438875
| 5102
| 429304
| 5631
|
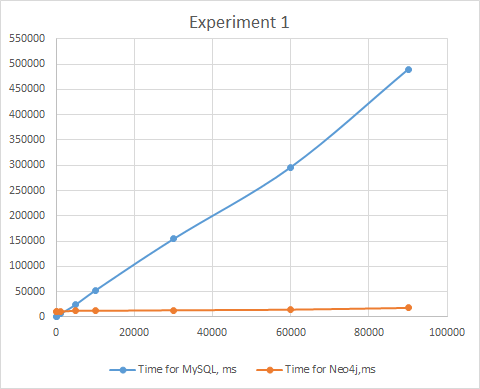
ハーバーでの議論の後、実験の条件へのアプローチを変えてみました:各実験の前にリクエストをよりシンプルなものに修正し、MySQLを再び上げて、MySQLとNeo4jが同時に動作しないという条件を提供しました。 次の結果が出ました。MySQLグラフがより安定し、グラフデータベースは少量のデータで非常に多くの関係を失い始めました。
| 実験1
|
idの範囲<
| MySQLの時間、ミリ秒
| Neo4jの時間、ミリ秒
|
10
| 120
| 10767
|
100
| 690
| 10706
|
1000
| 5879
| 10884
|
5000
| 24668
| 12245
|
10,000
| 52462
| 12280
|
30000
| 154534
| 13352
|
60,000
| 296369
| 14545
|
90,000
| 489830
| 18058
|
謙虚な調査結果
グラフデータベースは、大量のデータを検索するのに必要な時間ははるかに短いと言っても過言ではありませんが、ハードディスク上のより多くのスペースを占有します。 したがって、小規模なシステムの場合は、リレーショナルデータベースを使用するか、他のNoSQLデータベースの中から代替を探すことをお勧めします。
ご清聴ありがとうございました。