Habrahabrの読者に、Malwarebytesのチーフアーキテクトによる、わずか4台のサーバーで毎分100万件のリクエストを処理した方法に関する記事の翻訳を提供します。Malwarebytesで私たちは大きな成長を遂げており、シリコンバレーで約1年前に入社して以来、私の主な責任の1つは、急成長する企業と製品をサポートするために必要なすべてのインフラストラクチャを開発するためのいくつかのシステムアーキテクチャの設計と開発でした毎日何百万人もの人々によって使用されています。 私はウイルス対策業界でさまざまな企業で12年以上働いていますが、毎日処理しなければならない膨大な量のデータのために、これらのシステムがどれほど複雑かを知っています。
おもしろいのは、過去9年間ほど、私が出会ったすべてのWebバックエンド開発がRuby on Railsで行われたことです。 誤解しないでください、私はRuby on Railsが大好きで、これは素晴らしい環境だと思いますが、しばらくすると、Rubyスタイルのシステムの開発について考えることに慣れてしまい、マルチスレッド、同時実行、高速実行、メモリの効率的な使用が含まれていました。 何年もの間、私はC / C ++、Delphi、およびC#で執筆しました。仕事に適したツールを選択すれば、それほど複雑ではないことに気付き始めました。
チーフアーキテクトとして、私はネット上で非常に人気のある言語とフレームワークについての知識のファンではありません。 コードの有効性、生産性、および保守性は、主にソリューションをどの程度簡単に構築できるかにかかっていると思います。
問題
匿名のテレメトリおよび分析収集システムの一部の1つに取り組んで、数百万の顧客からの膨大な数のPOST要求を処理するタスクに直面しました。 Webプロセッサは、データのコレクション(ペイロード)を含むJSONドキュメントを受信している必要があります。このデータは、Amazon S3に保存する必要があります。これにより、map-reduceシステムはこのデータを後で処理します。
従来は、ワーカー層アーキテクチャに目を向け、次のようなものを使用していました。
- Sidekiq
- レスク
- DelayedJob
- Elasticbeanstalkワーカー層
- うさぎ
- 等々
さらに、バックグラウンドタスクをスケーリングできるように、Webフロントエンド用とワーカー用の2つの異なるクラスターをインストールします。
しかし、私たちのチームは最初からGoでそれを書くべきだと考えていました。なぜなら、議論の段階で、このシステムは膨大なトラフィックに対処しなければならないことをすでに理解していたからです。 私は約2年間Goを使用し、その上でいくつかのシステムを開発しましたが、そのような負荷で動作するものは今のところありません。
まず、POSTリクエストで受け入れられるリクエストデータを記述するいくつかの構造と、それらをS3バケットにダウンロードする方法を作成しました。
type PayloadCollection struct { WindowsVersion string `json:"version"` Token string `json:"token"` Payloads []Payload `json:"data"` } type Payload struct {
Goルーチンを使用したGo-aheadソリューション
最初に、単純なgoroutineを使用して処理を並列化しようとするだけで、POSTハンドラーの最も単純な単純なソリューションを採用しました。
func payloadHandler(w http.ResponseWriter, r *http.Request) { if r.Method != "POST" { w.WriteHeader(http.StatusMethodNotAllowed) return }
中程度の負荷の場合、このアプローチはほとんどの人に有効ですが、大規模では効果がないことがすぐにわかりました。 多くの要求があると予想していましたが、実稼働環境で最初のバージョンを展開したときに、桁違いに誤解されていることに気付きました。 トラフィック量を完全に過小評価しました。
上記のアプローチはいくつかの理由で悪いです。 実行するゴルーチンの量を制御する方法はありません。 そして、1分あたり100万件のPOSTリクエストを受信したため、このコードはもちろんすぐにクラッシュし、クラッシュしました。
再試行
別の方法を見つけなければなりませんでした。 最初から、リクエストの処理時間を最小限に抑え、バックグラウンドで重いタスクを実行する必要があることを説明しました。 もちろん、これはRuby on Railsの世界でこれを行う方法です。そうしないと、利用可能なすべてのWebハンドラーによってブロックされます。プーマ、ユニコーン、パッセンジャーのいずれを使用してもかまいません(JRubyについてはここで説明しないでください)。 そのため、Resque、Sidekiq、SQSなどのタスクには一般に受け入れられているソリューションを使用する必要があります。問題を解決する方法は数多くあるため、このリストは膨大です。
そして2番目の試みは、タスクキューを配置してS3にアップロードできるバッファーチャネルを作成することでした。キュー内のオブジェクトの最大数を制御できるため、すべてのメモリを保持するためのRAMがあります。キューチャネルでタスクをバッファリングするのは非常に簡単だと判断しました。
var Queue chan Payload func init() { Queue = make(chan Payload, MAX_QUEUE) } func payloadHandler(w http.ResponseWriter, r *http.Request) { ...
そして、実際には、キューからタスクを読み取って処理するために、次のコードに似たものを使用しました。
func StartProcessor() { for { select { case job := <-Queue: job.payload.UploadToS3()
正直なところ、私たちが何を考えていたのかわかりません。 どうやら、これは夜遅く、たくさんの酔っ払いのレッドブルでした。 このアプローチは何の利益ももたらさず、単に競争力の低さをバッファリングされたチャンネルと交換しただけで、これは単に問題を先送りにしただけです。 同期キュープロセッサは単位時間あたりS3に1パケットのデータのみをロードしましたが、着信リクエストの頻度はプロセッサがS3にロードする能力よりもはるかに高いため、バッファリングされたチャネルはすぐに限界に達し、新しいタスクをキューに追加する機能をブロックしました。
静かに問題を無視し、システムクラッシュのカウントダウンを開始しました。 このバグのあるバージョンを展開してから数分後に応答時間(遅延)が増加しました。
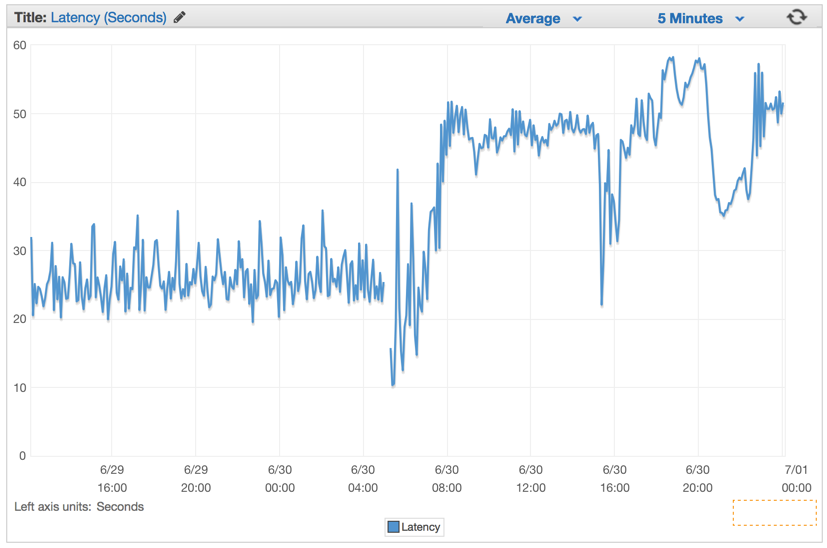
最適なソリューション
Goで一般的なチャネル操作パターンを使用して、チャネルの2つのレベルのシステムを作成することにしました。1つはチャネルキューを使用し、もう1つは一度にキューを処理するタスクハンドラの数を制御します。
アイデアは、S3でのダウンロードを並列化し、このプロセスを制御して、S3での接続エラーでマシンが過負荷にならないようにすることでした。 したがって、ジョブ/ワーカーパターンを選択しました。 Java、C#などに精通している人にとっては、これをパイプを使用してワーカースレッドプールを実装するための方法と考えてください。
var ( MaxWorker = os.Getenv("MAX_WORKERS") MaxQueue = os.Getenv("MAX_QUEUE") )
要求ハンドラーを変更して、データを含むJob型のオブジェクトを作成し、それをJobQueueチャネルに送信して、タスクハンドラーで取得できるようにしました。
func payloadHandler(w http.ResponseWriter, r *http.Request) { if r.Method != "POST" { w.WriteHeader(http.StatusMethodNotAllowed) return }
サーバーの初期化中に、Dispatcherを作成し、Run()を呼び出してワーカーのプールを作成し、JobQueueで着信タスクのリッスンを開始します。
dispatcher := NewDispatcher(MaxWorker) dispatcher.Run()
以下は、ディスパッチャの実装コードです。
type Dispatcher struct {
起動されてプールに追加されるハンドラの数を指定することに注意してください。 このプロジェクトとドッカー化されたGo環境でAmazon Elasticbeanstalkを使用し、常に本番環境でシステムを構成するために
12要素の
方法論を使用しようとしたため、環境変数からこれらの値を読み取ります。 したがって、ハンドラーの数と最大キューサイズを制御して、クラスター全体を再デプロイせずにこれらのパラメーターをすばやく強化できます。
var ( MaxWorker = os.Getenv("MAX_WORKERS") MaxQueue = os.Getenv("MAX_QUEUE") )
インスタント結果
最後のソリューションを展開した直後に、応答時間がわずかな数に減少し、リクエストを処理する能力が劇的に向上したことがわかりました。
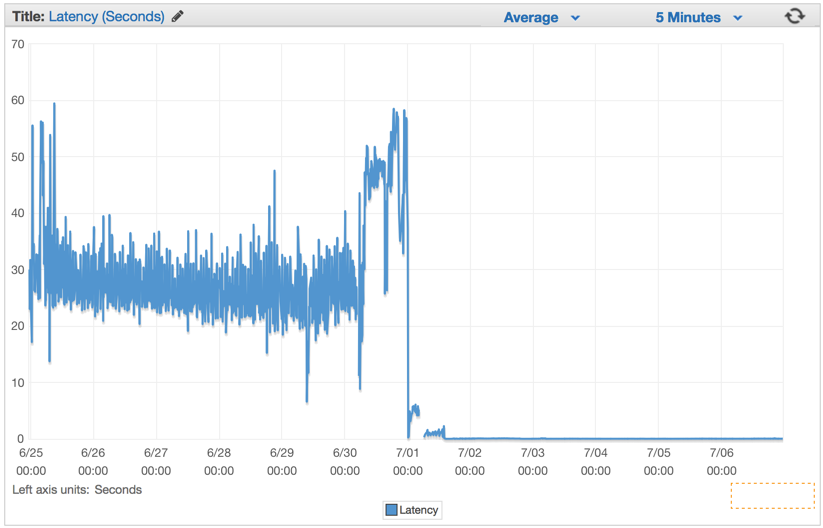
Elastic Load Balancerをウォームアップしてから数分後、ElasticBeanstalkアプリケーションが1分あたり約100万のリクエストを処理していることがわかりました。 通常、トラフィックのピークが毎分100万件を超えるリクエストに達する午前中は、数時間です。
新しいコードを展開するとすぐに、必要なサーバーの数が100台から20台に大幅に減少しました。
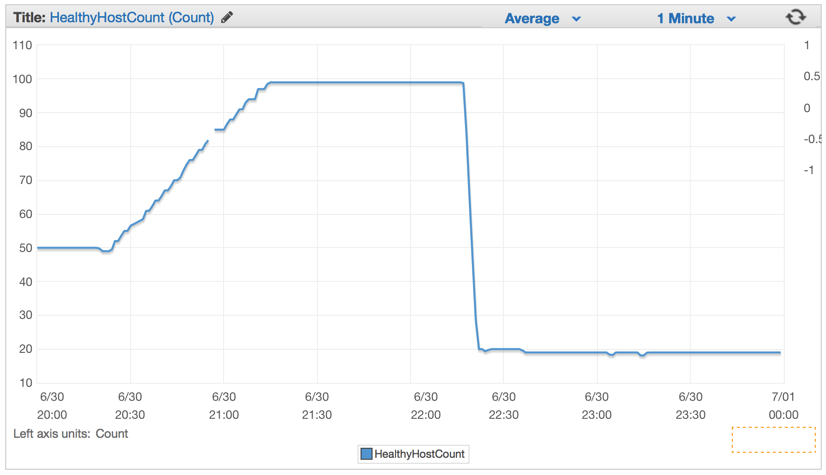
クラスターと自動スケーリングの設定をセットアップした後、その数をさらに減らすことができました-最大4 EC c4.largeインスタンスとElastic Auto-Scalingは、CPU使用率が5分間90%を超えた場合に新しいインスタンスを起動しました。
結論
私はシンプルさが常に勝つと確信しています。 多数のキュー、バックグラウンドプロセス、複雑なデプロイを備えた複雑なシステムを作成できましたが、これらすべての代わりに、ElasticBeanstalkの自動スケーリングの力とGolangが提供する競争力へのアプローチの効率性とシンプルさを活用することにしました。
私の現在のMacbook Proよりもさらに弱い4台のマシンのクラスターが毎日表示されるわけではなく、POSTリクエストを処理し、毎分100万回Amazon S3バケットに書き込みます。
タスクには常に適切なツールがあります。 また、Ruby on Railsシステムでより強力なWebハンドラーが必要な場合は、Rubyエコシステムから少し離れて、よりシンプルで強力なソリューションを実現してください。