多くの人々は不動産の売買の問題に直面しており、ここでの重要な基準は、他の同等のオプションと比較して、より高価なものを購入したり、安く販売したりしないことです。 最も単純な方法は、特定の場所でのメーターの平均価格に焦点を合わせ、特定のアパートの長所と短所の費用の割合を巧妙に増減する比較方法です。

しかし、このアプローチは時間がかかり、不正確であり、アパートのさまざまな違いをすべて考慮することはできません。 したがって、「公正な」価格を予測してデータ分析を使用し、不動産を選択するプロセスを自動化することにしました。 この出版物では、このような分析の主要な段階について説明し、3つの品質基準に基づいて18のテスト済みモデルから最適な予測モデルを選択します。その結果、Rを使用して作成された1つのWebアプリケーションを使用して、最高の(過小評価された)アパートがすぐにマップにマークされます
データ収集
問題の声明から明らかなように、データの入手先の問題が生じます。ロシアには不動産を見つけるための主要なサイトがいくつかあり、WinNERデータベースがあります。かなり便利なインターフェイスには最大数の広告が含まれ、csv形式でアップロードできます。 ただし、このベースで以前に時間ベースのアクセス(分、時間、日)が許可されていた場合、最小3か月のアクセスになり、通常の買い手または売り手にとっては多少冗長になります(真剣に受け止めたとしても、これらの費用は発生します)。 このオプションを使用すると、非常に簡単になります。そのため、他の方法で、不動産サイトから解析してみましょう。 いくつかのオプションから、最も便利な悪名高い
cian.ruを選択し
ました。 当時、データ表示は単純な表形式で表示されていましたが、すべてのデータをRに解析しようとすると失敗しました。 一部のセルでは、データが不完全な場合があり、R関数の標準的な手段では、アンカーワードまたはシンボルをキャッチできず、ループ(このようなタスクのRでは正しくありません)を使用するか、まったく知らない正規表現を使用する必要がありました、したがって、私は代替手段を使用する必要がありました。 この代替手段は、ページ(またはサイト)から情報を取得できる独自のREST APIを持ち、JSONの結果を返す優れたサービス
import.ioであることが判明しました。 また、RはAPIへのリクエストを実装し、JSONを解析できます。
このサービスをすぐにマスターしたので、1つのページからすべての必要な情報(各アパートメントのすべてのパラメーター)を抽出する抽出プログラムを作成しました。 そして、Rはすでにすべてのページを反復処理し、それぞれに対してこのAPIを呼び出し、受信したJSONデータを単一のテーブルに接着します。
import.ioを使用
すると、すべてのページを処理する完全に自律的なAPIを作成でき
ますが、サードパーティのAPIを正しく配置(1ページを解析)し、残りをRで引き続き実行できないと判断しました。将来のモデルの制限について、データソースが選択されます。
- モスクワ市
- モデル内のアパートの1つのタイプ(つまり、odnushkiまたはdvushkaまたはtreshka)
- 同じ地下鉄駅内(ジオコーディングが使用されているため、最寄りの地下鉄駅までの距離)
- 再販(新しい建物はすべて根本的に異なり、互いに質的に異なるため、これは広告では言われていないか、コメントに何かが書かれていますが、どちらも適切なモデルを作成することはできません)
データの概要
よくあることですが、データには、排出量、ギャップ、および新しい建物が二次財産として売却されたり、土地を売却したりするときのデマが含まれているだけです。
したがって、最初はすべてのデータを「きちんとした」外観にする必要があります。
チートチェック
ここでは主に発表の説明に重点を置いており、明らかに必要なサンプルに関連しない単語がある場合、これらの観察は除外され、R
grep関数によってチェックされます。 また、計算はRのベクトルであるため、この関数は正しい観測値のベクトルをすぐに返し、それを適用して、サンプルをフィルター処理します。
欠損値を確認する
欠落した値は非常にまれです(そして主に「現時点」で既に除外されている新しい建物と土地を含む「左」広告では)、残っている値では、何かをする必要があります。 一般に、このような観測を除外するか、これらの欠損値を置き換えるには、2つのオプションがあります。 観測を犠牲にしたくはありませんでしたが、データは「何を入力するのか」という原則に基づいて入力されていないと仮定して、定性変数をその値のモードに置き換え、定量的(フッテージ)を中央値。 もちろん、これは完全に正しいわけではなく、観測間の相関を実行し、得られた結果に応じてギャップを埋めることは完全に正しいでしょうが、このタスクでは、この冗長性を考慮し、さらに、そのような観測はほとんどありません。
排出チェック
放出はさらに一般的ではなく、量的、すなわち価格と映像の観点からのみ可能です。 ここでは、買い手(I)が自分のアパートの価格とおおよその映像を具体的に知っているという前提から進んだため、上限と下限の価格の初期値を設定し、映像を制限して、自動的に排出を取り除きます。 ただし、そうでない場合でも(制限を行わないでください)、結果を取得するか、散布図を見て異常値があることを確認すると、更新されたデータを使用してクエリを実行し、これらの観測を削除することでモデルを改善できます。
ガウス・マルコフの定理の主要な前提
詳細したがって、誤った観測値を削除し、分析を実行する前に、ガウスマルコフの定理の主要な前提でそれらを評価します。
今後は、モデルからの係数の解釈や信頼区間の正確な推定が必要ではなく、「理論上の」価格を予測する必要があるため、一部の前提は重要ではありません。
- データモデルが正しく指定されている。 一般に、はい、外れ値、誤った告知、欠損値の置換を排除することにより、モデルは非常に適切です。 いくつかの非厳密な多重共線性が存在する可能性があります(たとえば、5階建ての建物で、エレベーターやエリアがありません-共通/住宅)、上で書いたように、これは予測にとって重要ではなく、さらに、基本的な前提にも違反しません。 テストモデルを構築するために、すべての値が正しくダミー変数に変換され、厳密な多重共線性は除外されました。
- すべての回帰変数は決定論的であり、等しくありません。 はい、そうです。
- エラーは体系的ではありません。 最小二乗法では誤差を均等化する自由項が使用されるため、それは事実です。
- エラーの分散は同じです(同相分散性)。 回帰変数と従属変数のサイズの制限が使用されるため(スケールは同等)、不均一分散性は最小限であり、予測にとっても重要ではありません(標準誤差は受け入れられませんが、それらは私たちにとって興味深いものではありません)
- エラーは無相関です(内因性)。 いいえ、内生性が存在する可能性が最も高い(たとえば、アパートは1つのサイトまたは入り口からの「隣人」)、外部の不明な要因がありますが、予測のために、内生性の記録は重要ではありません、さらに、私たちは知りませんこの原因不明の要因。
データは一般に仮定と一致しているため、モデルを構築できます。
リグレッサーセット
変数(サイトから直接取得)に加えて、追加のリグレッサー、つまり5階建てのビルかどうか(これは通常非常に質的な違いであるため)、および最寄りのメトロまでの距離(同様に)を追加することにしました。 距離を決定するために、GoogleジオコーディングサービスAPIが使用されます(最も正確で制限に忠実で、Rに既製の関数があります)、アパートとメトロの住所が最初に
ジオコーディングされ、
ggmapパッケージの
ジオコード関数が
使用されます。 そして、距離は、haversineの式によって決定され、
geosphereパッケージの
distHaversine関数によって準備されます。
リグレッサーの総数は14個でした。
- メトロまでの距離
- 総面積
- リビングエリア
- キッチンエリア
- ハウスタイプ
- エレベーターの可用性と種類
- 可用性とバルコニーの種類
- バスルームの数と種類
- 窓はどこに行きますか?
- 電話の可用性
- 販売の種類
- 1階
- 最上階
- 5階建ての建物
テスト済みの予測分析モデル
詳細実用的な個人的価値に加えて、さまざまなモデルをテストすることも興味深かったので、最適なモデルを選択し、私が知っているすべての単純な回帰モデルのさまざまなサンプルをチェックすることにしました。つまり、次のモデルをテストしました。
1.すべてのリグレッサのMNC
2. OLS対数(異なるオプション:価格の対数および/または面積および/または地下鉄までの距離)
3.リグレッサーの包含および除外を伴うMNC
a)回帰変数の段階的な除外
b)直接検索アルゴリズム
4.罰金のあるモデル(不均一分散の影響を軽減するため)
a)なげなわ回帰(分別パラメーターを決定するための2つの方法-Cp-criterion Mallowと交差検証の最小化)
b)リッジ回帰(ペナルティパラメーターを見つける3つの方法-HKB、LW、および交差検証)
5.主成分の方法
a)すべてのリグレッサと
b)回帰変数を段階的に除外する
6.分位点(中央値)回帰(不均一分散の影響を減らすため)
7.ランダムフォレストアルゴリズム
テストしたモデルの総数は18個でした。
モデルを準備する過程で、次の材料が部分的に使用されました。
Mastitsky S.E.、Shitikov V.K. (2014)Rを使用した統計分析とデータ視覚化
-電子書籍のアクセスアドレス:
r-analytics.blogspot.com モデル性能基準
詳細すべてのモデルは本質的に根本的に異なっており、多くのモデルでは尤度関数はありません。したがって、内部品質基準を決定することは不可能であり、モデルの妥当性を主に評価するのに役立つため、それらに依存して効果的なモデルを選択することは完全に正しいわけではありません。 したがって、経験値と予測値の平均差に基づいてモデルの品質を評価することに焦点を当てます。 そして、それをより興味深いものにし、利益(費用対効果)を決定するために、二乗平均平方根誤差(いくつかの観測はそれを歪める可能性がある)は必ずしも指標ではありません、私は通常のRMSE-標準誤差だけでなく、MAE-平均二乗誤差も基準を評価するために使用しましたおよびMPE、平均パーセント誤差。
モデルテスト結果
詳細モデルはさまざまな関数によって評価され、予測値の構文も異なるため、一部のリグレッサが階乗であるという単純な指示はすべてのモデルに適していないため、すべての質的変数がダミー変数に変換され、この形式の追加のデータフレームが作成されましたモデルが構築されました。 これにより、すべてのモデルを均一に評価し、新しい価格を予測し、エラーを特定できます。
さまざまなランダムテストサンプル(異なる地下鉄駅、異なるタイプのアパート、その他のパラメーター)で、上記のすべてのモデルを3つのパフォーマンス基準で評価しました。 そして、3つの基準すべてでほぼ絶対的な(92%)勝者は、ランダムフォレストアルゴリズムでした。 また、さまざまなサンプルで、いくつかの基準、中央値回帰、価格の対数を含むMNC、完全なMNC、および場合によってはLassoを含むRidgeが良好な結果を示しました。 ペナルティのあるモデルは完全なMNCよりも優れていると考えられたため、結果はやや驚くべきものでしたが、常にそうであるとは限りませんでした。 したがって、単純なモデル(OLS)は、より複雑なモデルよりも優れた代替手段になる可能性があります。 異なるサンプルでは、異なる基準に従って、2番目の場所から始まる場所は異なるモデルで占められており、勝者はランダムフォレストであるという事実のため、私はそれをさらなる作業に使用することにしました。
1つのモデルが既に使用されているため、ダミー変数を明示的に指定する必要はありません。したがって、元のフレームに戻り、高品質変数が因子変数であることを示します。これにより、ダイアグラム上の後続の解釈が簡略化され、アルゴリズムは簡単になります(本質的には重要ではありませんが) ) テストモデリングでは、(同じ名前のパッケージの) randomForest関数をデフォルト値で使用し、 nodesize 、 maxnodes 、 nPerm treesの主要な複雑度パラメーターを変更しようとして、異なるサンプルの予測エラーの最小化がノードサイズパラメーター(最小ノード数) 1.したがって、モデルが選択されます。
地図表示
勝者が決定されます(ランダムフォレスト)。このモデルは、すべての観測値の「理論上の」価格を最小の誤差で予測します。 これで、絶対的、相対的な過小評価を計算し、ソートされたテーブルの形式で結果を表示できますが、表形式ビューに加えて、すぐに情報を得たいので、最良の結果の一部をすぐにマップに表示します。 このため、RにはGoogleマッピングシステムとの統合用に設計された
googleVisパッケージがあります(ただし、リーフレット用のパッケージもあります)。 ジオコーディングから受け取った座標を他の地図に表示することは禁止されているため、Googleも引き続き使用しました。 マップ上の表示は、
googleVisパッケージの1つの
gvisMap関数によって実行されます。
地図表示コードoutput $ view <-renderGvis({#view-htmlOutput出力要素
if((err()!= ""))return(NULL)
formap3 <-formap()
formap3 $ desc <-paste0(row.names(formap3)、
「。いいえ」、
formap3 $番号、
「」、
formap3 $アドレス、
「過小評価」、
形式(-formap3 $ abs.discount、big.mark = "")、
「ルーブル(」、
as.integer(formap3 $ otn.discount)、
「%)」)
gvisMap(formap3、「coord」、「desc」、options = list(
mapType = 'normal'、
enableScrollWheel = TRUE、
showTip = TRUE))
})
Web GUI
必要なすべてのパラメーターをコンソールに渡すのは時間がかかり、不便なので、すべてを自動的に実行したかったのです。 そして伝統的に、このために、十分なI / Oコントロールを持つ
shinyと
shinydashboardフレームワークでRを再び使用できます。
インターフェースのクライアント部分の完全なコードdashboardPage(
dashboardHeader(タイトル=「マイニングプロパティv0.9」)、
dashboardSidebar(
sidebarMenu(
menuItem( "ソースデータ"、tabName = "ソース")、
menuItem( "Summary"、tabName = "Summary")、
menuItem(「生データ」、tabName =「生」)、
menuItem(「整頓データ」、tabName =「整頓」)、
menuItem( "予測データ"、tabName = "予測")、
menuItem( "Plots"、tabName = "Plots")、
menuItem( "結果マップ"、tabName = "マップ")
)
)、
dashboardBody(
tags $ head(tags $ style(HTML( '。box {overflow:auto;}')))、
tabItems(
tabItem( "ソース"、
ボックス(幅= 12、
fluidRow(
列(幅= 4
selectInput( "Metro"、 "Metro"、 ""、width = '60% ')、
#br()、
hr()、
#checkboxInput( "Kind.home0"、 "all"、TRUE)、
checkboxGroupInput( "Kind.home"、 "House Type"、c(
「パネル」= 1、
「スターリン」= 7
「シールド」= 8
「レンガ」= 2
「モノリシック」= 3
「ブリックモノリシック」= 4
「ブロック」= 5
「ツリー」= 6)、選択済み= c(1,2,3,4,5,6,7,8))、
hr()、
SliderInput(「Etag」、「Floor」、min = 0、max = 100、value = c(0、100)、step = 1)、
checkboxInput(「EtagP」、「最後ではない」)、
SliderInput( "Etagn"、 "In the house of floors"、min = 0、max = 100、value = c(0、100)、step = 1)
、
submitButton(「分析」、アイコン(「更新」))
)、
列(幅= 4
selectInput( "Rooms"、 "Rooms"、c
( ""、
"1" = "&room1 = 1"、
"2" = "&room2 = 1"、
"3" = "&room3 = 1")、幅= '45% ')、
#br()、
hr()、
#br()、
selectInput( "Balcon"、 "Balcony"、
c( "バルコニーなしでも可" = "0"、
「バルコニーのみ」=「&minbalkon = 1」、
「バルコニーなしのみ」=「&minbalkon = -1」)、
幅= '45% ')、
br()、
hr()、
br()、
#br()、
SliderInput(「キッチンM」、「キッチンエリア」、最小= 0、最大= 25、値= c(0、25)、ステップ= 1)、
sliderInput( "GilM"、 "Living Area"、最小= 0、最大= 100、値= c(0、100)、ステップ= 1)、
SliderInput(「TotalM」、「Total Area」、最小= 0、最大= 150、値= c(0、150)、ステップ= 1)
)、
列(幅= 4
SliderInput( "Price"、 "Price"、min = 0、max = 50000000、value = c(0、50000000)、step = 100000、sep = "")、
#hr()、
selectInput(「取引」、「取引タイプ」、
c( "any" = "0"、
「無料」=「&sost_type = 1」、
「代替」=「&sost_type = 2」)、
幅= '45% ')、
br()、
hr()、
#br()、
#br()、
#br()、
radioButtons( "wc"、 "Bathroom"、
c(「重要ではない」=「」、
「分離」=「&minsu_r = 1」、
「結合」=「&minsu_s = 1」))、
hr()、
selectInput(「Lift」、「Lifts(最小)」、
c( "0" = 0、
"1" = "&minlift = 1"、
"2" = "&minlift = 2"、
"3" = "&minlift = 3"、
"4" = "&minlift = 4"
)、
幅= '45% ')、
hr()、
selectInput(「obs」、「地図上にアパートメントを表示:」、c(1:10)、選択= 5、幅= 250)、
textOutput( "フラット")
)
)、
fluidRow(htmlOutput( "hyperf1"))、
fluidRow(textOutput( "testOutput"))
)
)、
tabItem( "Raw"、box(dataTableOutput( "Raw")、width = 12、height = 600))、
tabItem( "Summary"、box(verbatimTextOutput( "Summary")、width = 12、height = 600))、
tabItem( "Tidy"、box(dataTableOutput( "Tidy")、width = 12、height = 600))、
tabItem( "予測"、ボックス(dataTableOutput( "予測")、幅= 12、高さ= 600))、
tabItem( "Plots"、box(width = 12、plotOutput( "RFplot"、height = 275)、plotOutput( "r2"、height = 275)))、
tabItem( "Map"、box(width = 12、htmlOutput( "view")、DT :: dataTableOutput( "formap2")、height = 600))
)
)
)
これらすべての結果は、グラフィカルインターフェイスを備えた便利なアプリケーションであり、実際にはサイドメニューの2つの主要なポイント(制御用の他のアイテム)が最初と最後にあります。 サイドメニュー(図1)の最初の(
ソースデータ )項目には、アパートの検索と評価に必要なすべてのパラメーター(cianに類似)が設定されています。
図1選択されたメニューのウィンドウ
ソースデータサイドメニューの残りの項目に表示されます:
- リグレッサーの要約レポート
- データテーブル(生( 生データ )-解析後の初期、きちんとした( 整頓されたデータ )-パラメーターをきちんとした外観にし、パラメーターを調整し、ジオロケーションを追加した後、および最終( 予測データ )予測価格値の表)
- 3つのプロット図(図2)-モデルの精度とランダムフォレストアルゴリズムのリグレッサの重要性(ほとんどすべてのリグレッサが重要です)および初期価格と予測価格の分散図。
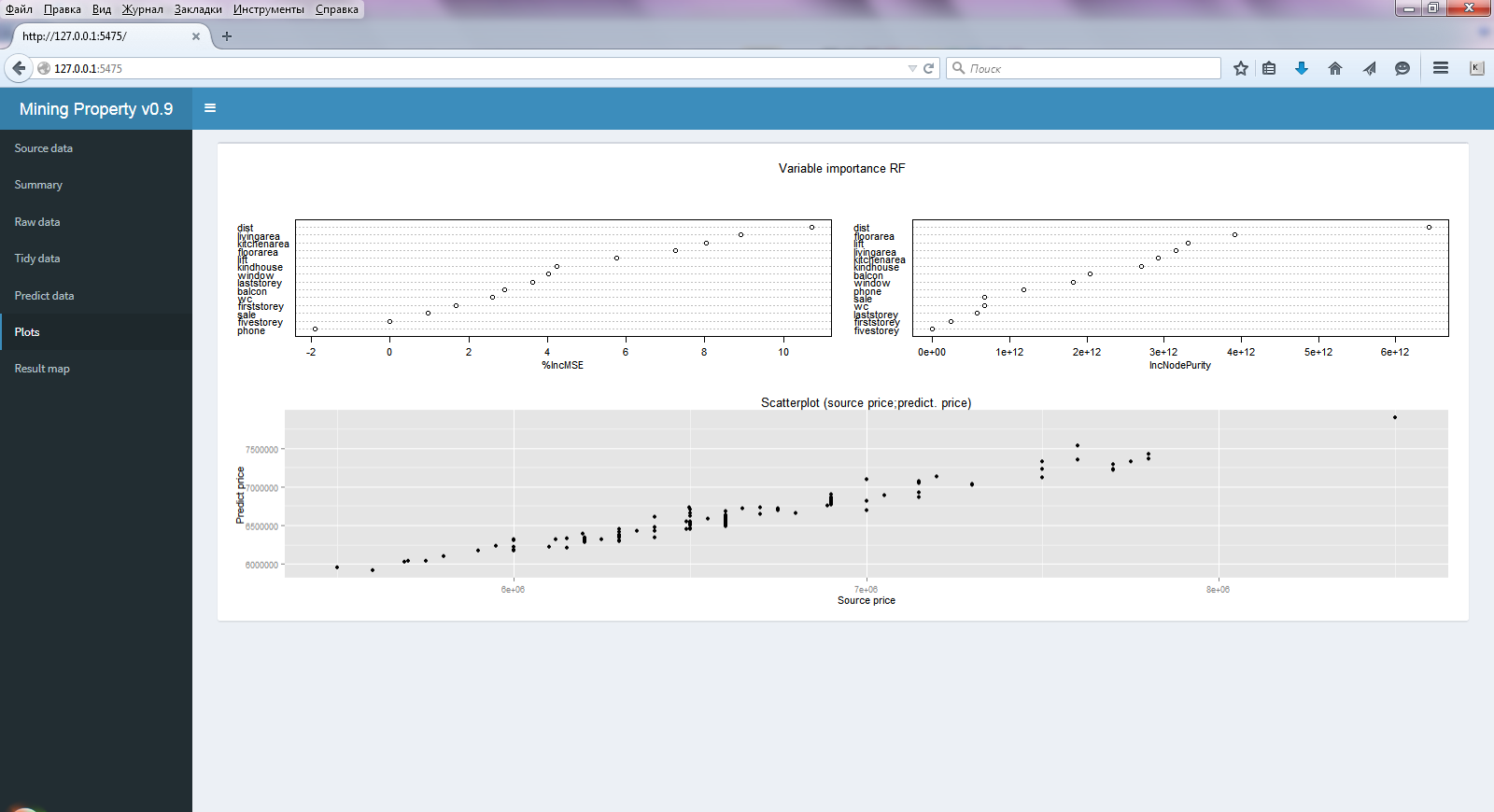
図2選択した
プロットメニューのウィンドウ
さて、最後の段落(
結果マップ )(図3)には、すべてが何のために開始されたか、選択された最良の結果のマップ、計算された予測価格とアパートの主な特性のテーブルが表示されます。
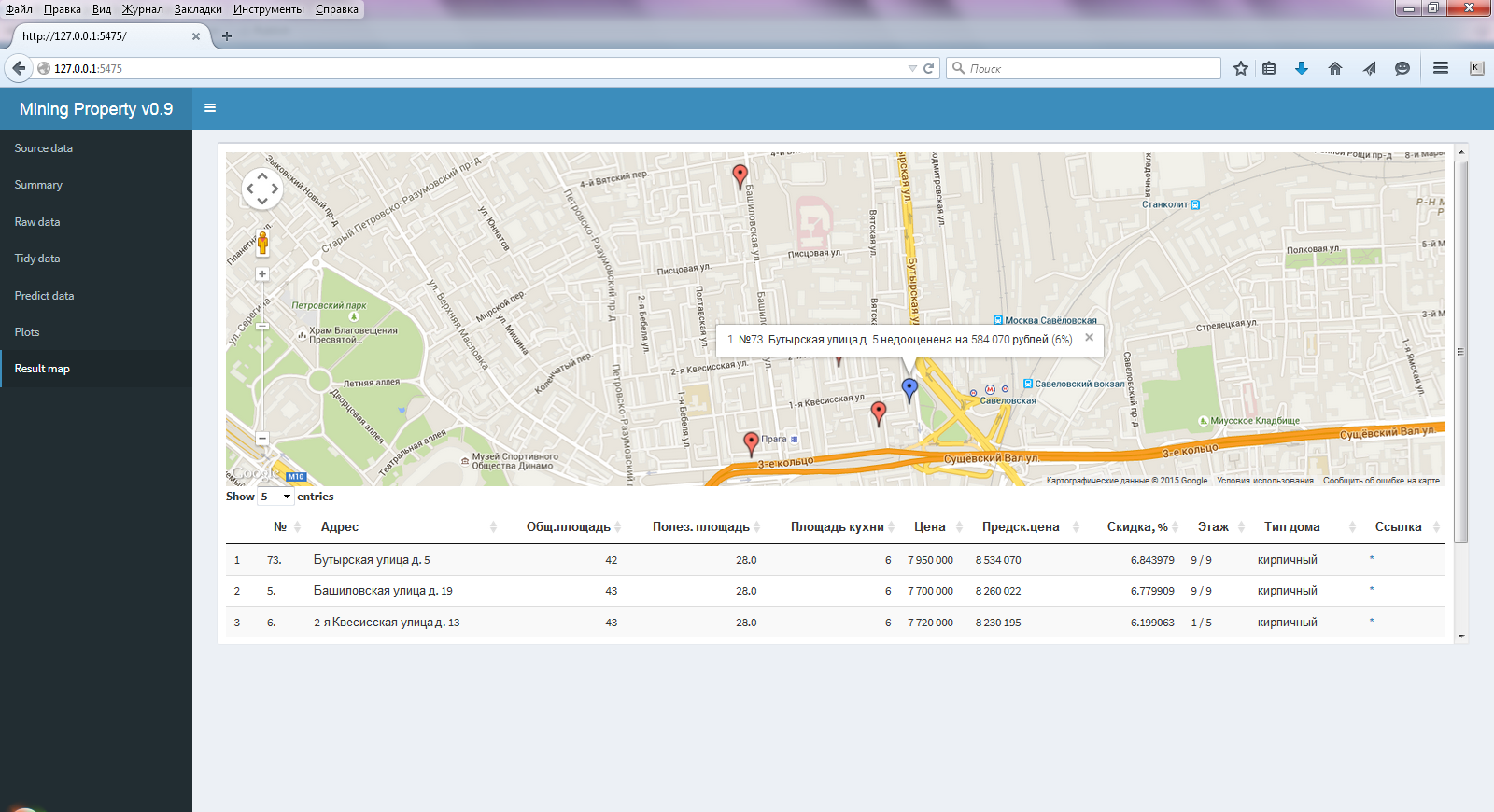
図3選択したメニューのウィンドウ
結果マップまた、この表には、この広告に移動するためのリンク(*)がすぐにあります。 この統合(表のJS要素を含む)により、
DTパッケージを作成できます。
おわりに
上記のすべてを要約すると、それはどのように機能しますか:
- 最初のページでは、最初のリクエストはコントロールを使用して設定されます
- これらの入力要素の選択に基づいて、クエリ文字列が形成されます(検証用のハイパーリンクとしても示されます)
- ページを示すこの行はimport.io APIに渡されます(これをすべて作成する過程で、 import.ioのおかげでcianは出力インターフェースを変更し始めました。文字通り5分で抽出プログラムを再トレーニングしました)
- APIから受信したJSONが処理されます
- すべてのページがスキャンされます(プロセスでは、プロセスのステータスバーが表示されます)
- テーブルは接着され、チェックされ(不正な値は除外され、欠損値は置換されます)、分析に適した均一な形式になります
- 住所のジオコーディングと距離の決定
- モデルは、ランダムフォレストアルゴリズムに従って構築されます
- 予測価格、絶対、相対偏差が決定されます
- 最良の結果は、マップとその下の表に表示されます(表示されているアパートメントの数は最初のページに示されています)
アプリケーションのすべての作業(リクエストの開始から地図上の表示まで)は1分未満で完了します(ほとんどの時間は位置情報に費やされます。これは、家庭での使用に関するGoogleの制限です)。
この出版物は、単純な家庭のニーズのために、1つのアプリケーションのフレームワーク内で、多くの小さな、しかし根本的に異なる興味深いサブタスクを解決できることを示しました。
- 鳴き声
- 解析
- サードパーティAPIの統合
- JSON処理
- ジオコーディング
- さまざまな回帰モデルを使用する
- さまざまな方法での有効性の評価
- ジオロケーション
- 地図表示
さらに、これらはすべて、ローカルまたはネットワーク上でホストできる便利なグラフィカルアプリケーションに実装され、すべてこれは1つのR(
import.ioをカウントしない)で行われ、シンプルでエレガントな構文の最小限のコード行で行われます。 もちろん、高速道路の近くの家やアパートの状態(これは広告に含まれていないため)などは考慮されませんが、マップにすぐに表示され、元の広告自体へのリンクを含む最終的なランク付けされたオプションのリストは、アパートの選択を非常に容易にしますそれに加えて、Rで多くのことを学びました。