この記事では、機能、弱点、人気のあるキャプチャの認識に関するサイクルを続けています。
前の出版物では、
KCAPTCHA既製
ソリューションに触れました。これは、優れたセキュリティにもかかわらず、通常の多層パーセプトロンによる深刻な予備処理およびセグメンテーションなしで認識されました。
次はキリル文字のYandexキャプチャです。これは私たちの多くがよく知っているはずです。
したがって、このようなキャプチャがあります。

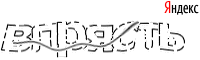
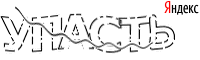
特徴
- 可変長
- 歪み
- ノイズ(曲線)
- キリル文字
- 右上隅のトレンディなロゴ
弱点
- 歪みは無視でき、セグメンテーションを妨げません
- ノイズは認識を少しだけ複雑にします
- 限られた語彙により、誤ったオプションを除外し、ネットワーク応答を調整できます
解決策
条件付きで認識を次の段階に分割します。
- 前処理
- テキストの検索とセグメント化
- 認識
- 結果の最終処理
前処理
Yandexのロゴを削除し、画像を自動トリミングします。
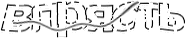
入力データを正規化します。
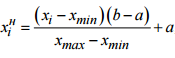
ここで、xはピクセルの色の値、[a、b]は入力信号の許容値の間隔です。 この例では、-1から1です。
テキストの検索とセグメント化
出力層の4つのニューロンを持つネットワークは、それぞれ4〜7の長さの値に対応し、キャプチャの長さを認識する役割を果たします。
さて、キャプチャの長さを知っているので、さらなる認識のために、画像を等しい部分に分割するだけです:

認識
文字を認識するために、2つの層のネットワークが使用されます。
最初の層はトレーニング可能で、900個のニューロンで構成され、出力は31個のニューロンで構成され、各ニューロンは図の文字に対応しています。
最初のトレーニングサンプルは
、ロシア語を話すインディアンの反門の
分離のおかげで作成され、2,000キャプチャになりました。ネットワークの短いトレーニングの後、Yandex自体と、Yandex辞書のデータに基づいて4から7文字の387,143単語の辞書が教師として機能しました。
辞書に存在する可能性のある正しいネットワーク回答は、トレーニングが行われた結果に応じて、Yandex検証のために送信されました。これにより、さらなるサンプリングのコストが大幅に削減されました。
日中、70%の各文字の認識精度が得られました。
結果の最終処理
認識結果を受信した後、辞書内のその存在がチェックされます。
認識結果が辞書にない場合、ほとんどの場合それは正しくありません。
多くの場合、同様の文字間でエラーが発生します(たとえば、n-およびs-e、b-s、p-l)。
この場合、ネットワークの回答に基づいて、最も可能性の高い文字を選択し、辞書で対応する単語を探します。
単語が存在しない場合、同様の長さと最小レーベンシュタイン距離を持つオプションを選択します。
このオプションは、18%のキャプチャ認識精度を提供します。
スペルの既製のソリューションは言うまでもなく、ロシア語での文字とその組み合わせの分布の頻度を使用することもできます。いずれにしても、多くのオプションがあります。
辞書にない結果の単純な調整でさえ、誤ったオプションの大部分を破棄します。
おわりに
先ほど言ったように、欲望と適切な数の例で、理解できる[だけでなく]キャプチャは人に認識されます。 画像自体を複雑にすることではなく、ボット検出技術に重点を置いて、それ自体が人を識別して除外するようにします。
キリル文字のYandex CAPTCHAはかなり弱いですが、ロシア語を話すユーザーにとっては、たとえばkcaptchaやrecaptcha(特に最初のバージョン)よりも使いやすいです。
近い将来、Yandexのメンバーはキャプチャに取り組み、信頼性と一般の人々の利便性の間の妥協点に達することができると確信しています。
ソースコード
ネットワークをテストまたは理解する場合は、
GitHubへようこそ。
PSこの分野でおもしろい仕事があれば、喜んでお手伝いします 。