
ほとんどの人にとって、一般的なサイト監査はかなり複雑で時間がかかる作業ですが、Screaming Frog SEO Spider(SEO Spider)などのツールを使用すると、専門家と初心者の両方にとって作業がはるかに簡単になります。 Screaming Frogのユーザーフレンドリーなインターフェイスは簡単で素早い操作を提供しますが、さまざまな構成オプションと機能により、プログラムとの最初のステップであるプログラムを知ることが難しくなります。
次の手順は、主にサイトの監査だけでなく、他のタスクにもScreaming Frogを使用するさまざまな方法を示すことを目的としています。
サイトクロールの基本
デフォルトでは、Screaming Frogはアクセスしているサブドメインのみをスキャンします。 Spiderが遭遇する追加のサブドメインは、外部リンクと見なされます。 追加のサブドメインをスキャンするには、Spider設定メニューを調整する必要があります。 [すべてのサブドメインをクロール]オプションを選択すると、サイトのサブドメインに表示されるリンクをSpiderで確実に分析できます。

スキャンを高速化するには、画像、CSS、JavaScript、SWF、または外部リンクを使用しないでください。
スキャンを特定のフォルダーに制限する場合は、デフォルト設定を変更せずに、URLを入力して「開始」ボタンをクリックするだけです。 プリセット設定を変更した場合、「ファイル」メニューを使用してリセットできます。

特定のフォルダーからスキャンを開始し、サブドメインの残りの部分を分析したい場合は、必要なURLで作業を開始する前に、まず「構成」と呼ばれるSpiderセクションに移動し、「開始外のクロール」オプションを選択しますフォルダ。」
特定のサブドメインまたはサブカテゴリのセットをスキャンする方法。
サブドメインまたはサブカテゴリの特定のリストを機能させるには、RegExを使用して、「構成」メニューに特定の要素を含める(設定を含める)または除外する(設定を除外する)ルールを設定できます。
次の例では、havaianas.com Webサイトのすべてのページがスキャン対象として選択されていますが、個々のサブドメインの[About]ページを除きます(例外)。 次の例は、同じサイト(包含)のサブドメインの英語ページを正確にスキャンする方法を示しています。
私のサイトのすべてのページのリストをスキャンしたい場合。
デフォルトでは、Screaming FrogはSpiderが遭遇するすべてのJavaScriptイメージ、CSS、およびフラッシュファイルをスキャンします。 HTMLのみを解析するには、「Spider」設定メニューの「画像の確認」、「CSSの確認」、「JavaScriptの確認」および「SWFの確認」オプションをオフにする必要があります。 Spiderの起動は、指定された位置を考慮せずに実行されます。これにより、内部リンクがあるサイトのすべてのページのリストを取得できます。 スキャンが完了したら、「内部」タブに移動し、HTML標準に従って結果をフィルタリングします。 CSV形式の完全なリストを表示するには、[エクスポート]ボタンをクリックします。

ヒント:後続のスキャンに指定された設定を使用する場合、Screaming Frogは指定されたオプションを保存する機会を提供します。
特定のサブディレクトリ内のすべてのページのリストをスキャンする場合。
「画像の確認」、「CSSの確認」、「JavaScriptの確認」、「SWFの確認」に加えて、「スパイダー設定」メニューで「フォルダー外のリンクを確認」を選択する必要があります。 つまり、これらのオプションをSpiderから除外すると、選択したフォルダーのすべてのページのリストが表示されます。
クライアントが商業サイトにリダイレクトしたばかりのドメインのリストをスキャンする必要がある場合。
このサイトのURLをReverseInter.netに追加し、上部の表のリンクをクリックして、同じIPアドレス、DNSサーバー、またはGAコードを使用しているサイトを見つけます。
次に、Scraperと呼ばれるGoogle Chromeの拡張機能を使用して、「サイトにアクセス」というアンカーが付いたすべてのリンクのリストを見つけることができます。 Scraperが既にインストールされている場合は、ページ上の任意の場所をクリックして「Scrape Similar」を選択することで起動できます。 ポップアップウィンドウで、XPathリクエストを次のように変更する必要があります。
// [text()= 'visit site'] / @ href。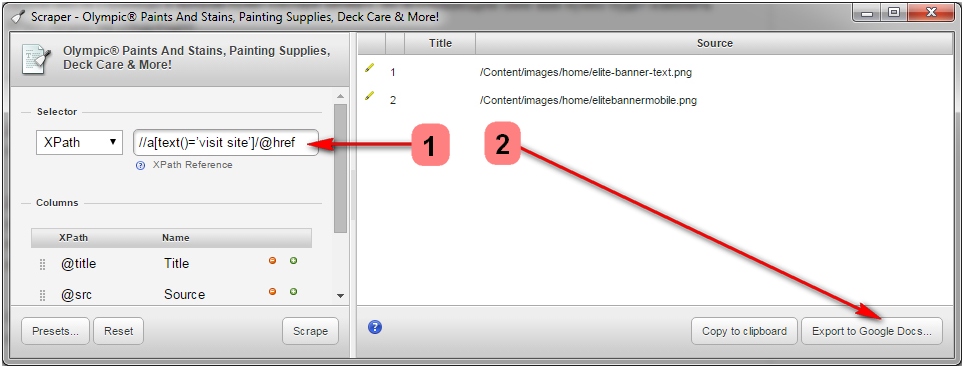
次に、「Scrape」をクリックし、「Googleドキュメントにエクスポート」をクリックします。 Word文書から、リストを.csvファイルとして保存できます。
次に、このリストをSpiderにダウンロードしてスキャンを実行できます。 Spiderの作業が終了すると、対応するステータスが[内部]タブに表示されます。 または、応答コードに移動し、「リダイレクト」位置を使用して結果をフィルタリングし、商用サイトまたは他の場所にリダイレクトされたすべてのドメインを表示できます。
.csvファイルをScreaming Frogにロードするときは、それに応じて「CSV」形式タイプを選択する必要があります。そうしないと、プログラムがクラッシュします。
ヒント:この方法を使用して、競合他社にリンクしているドメインを特定し、それらがどのように使用されたかを特定することもできます。
サイトのすべてのサブドメインを見つけて、内部リンクを確認する方法。
ReverseInternetでドメインのルートURLを入力し、「サブドメイン」タブをクリックしてサブドメインのリストを表示します。
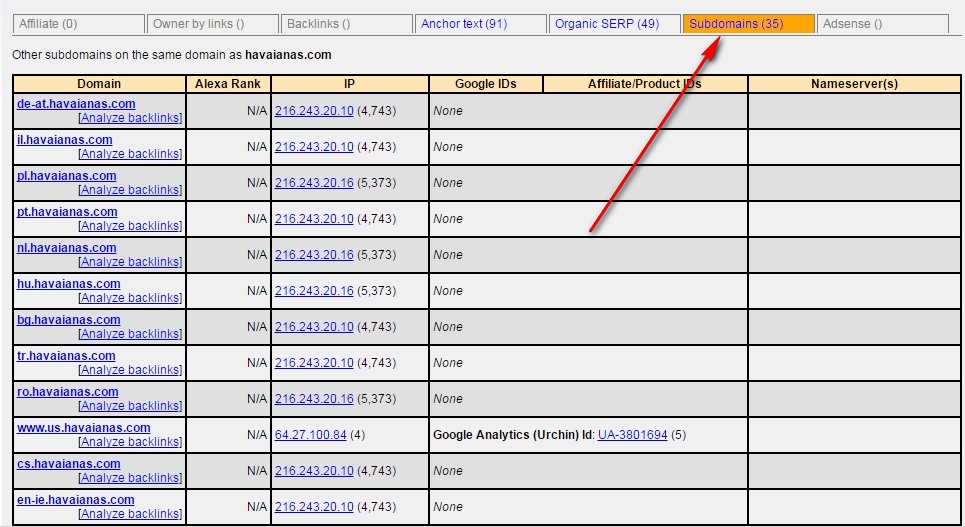
その後、Scrape Similarを使用して、XPathクエリを使用してURLのリストをコンパイルします。
// [text()= 'visit site'] / @ href。結果を.csv形式でエクスポートし、「リスト」モードを使用してCSVファイルをScreaming Frogにアップロードします。 Spiderの作業が終了すると、サブドメインページ、アンカーエントリ、さらには繰り返しページタイトル上のリンクだけでなく、ステータスコードを表示できます。
コマーシャルサイトまたはその他の大規模サイトをスキャンする方法。
Screaming Frogは数十万ページをスキャンすることを目的としていませんが、大規模なサイトをスキャンする際にプログラムのクラッシュを防ぐのに役立ついくつかの手段があります。 まず、Spiderが使用するメモリの量を増やすことができます。 次に、包含および除外ツールを使用して、サブディレクトリのスキャンを無効にし、サイトの特定のフラグメントのみで作業できます。 第三に、HTMLに焦点を合わせて、画像、JavaScript、CSS、フラッシュファイルのスキャンをオフにすることができます。 これにより、メモリリソースが節約されます。
ヒント:以前に大きなサイトをスキャンするときに操作が完了するまで非常に長い時間待機する必要があった場合、Screaming Frogを使用すると、大量のメモリを使用する手順を一時停止できます。 この最も価値のあるオプションを使用すると、プログラムがクラッシュしてメモリサイズを増やす準備が整ったと思われる瞬間までに、既に取得した結果を保存できます。
現時点では、このオプションはデフォルトで有効になっていますが、大規模なサイトをクロールする場合は、Spiderの設定メニューの[詳細設定]タブで、[高メモリ使用量で一時停止]フィールドにチェックマークを入れてください。
古いサーバーでホストされているサイトをクロールする方法。
場合によっては、古いサーバーが1秒あたりのURLリクエスト数を処理できないことがあります。 [構成]メニューでスキャン速度を変更するには、[速度]セクションを開き、ポップアップウィンドウで同時に使用するスレッドの最大数を選択します。 このメニューから、1秒あたりに要求されるURLの最大数を選択することもできます。
ヒント:スキャン結果で多数のサーバーエラーが見つかった場合は、Spider設定メニューの[詳細設定]タブに移動して、[応答タイムアウト]値と新しいリクエストの試行回数(5xx応答再試行)を増やします。 これにより、より良い結果を得ることができます。
Cookieを必要とするサイトをクロールする方法。
検索ボットはCookieを受け入れませんが、サイトのスキャン時にCookieを有効にする必要がある場合は、[構成]メニューの[詳細]タブで[Cookieを許可]を選択します。
プロキシまたは他のユーザーエージェントを使用してサイトをクロールする方法。
設定メニューで「プロキシ」を選択し、適切な情報を入力します。 別のエージェントを使用してスキャンするには、構成メニューで[ユーザーエージェント]を選択し、ドロップダウンメニューから検索ボットを選択するか、その名前を入力します。
Screaming Frog SpiderがIDを要求するページに入ると、ウィンドウが表示され、ユーザー名とパスワードを入力する必要があります。
この手順を行わずに続行するには、構成メニューの[詳細設定]タブで、[認証の要求]オプションをオフにします。
内部リンク
サイトの外部および内部リンクに関する情報(アンカー、ディレクティブ、リンクなど)を取得する必要がある場合の対処方法。
サイトの画像、JavaScript、Flash、またはCSSを確認する必要がない場合は、メモリリソースを節約するためにこれらのオプションをスキャンモードから除外します。
Spiderがスキャンを完了したら、Advanced Exportメニューを使用して、All LinksデータベースからCSVをエクスポートします。 これにより、すべての参照場所とそれに対応するアンカーエントリ、ディレクティブなどが提供されます。
各ページのリンク数をすばやく計算するには、「内部」タブに移動し、「外部リンク」オプションで情報を並べ替えます。 100番目の位置より上にあるものはすべて、追加の注意が必要な場合があります。
ページまたはサイトへの壊れた内部リンクを見つける方法。
いつものように、プロセスを最適化するために、スキャンオブジェクトから画像、JavaScript、Flash、またはCSSを除外することを忘れないでください。
Spiderでスキャンした後、「ステータスコード」機能を使用して「内部」パネルの結果をフィルタリングします。 404、301、およびその他のステータスコードはすべて明確に表示されます。
プログラムウィンドウの下部にあるスキャン結果で個々のURLをクリックすると、情報が表示されます。 下部のウィンドウの[リンク内]をクリックすると、選択したURLにリンクするページのリスト、およびこれらのページで使用されるアンカーエントリとディレクティブが表示されます。 この関数を使用して、更新が必要な内部リンクを識別します。
壊れたリンクまたはリダイレクトを含むページのリストをCSV形式でエクスポートするには、「高度なエクスポート」メニューの「リダイレクト(3xx)リンク」または「クライアントエラー(4xx)リンク」または「サーバーエラー(5xx)リンク」オプションを使用します「。
ページまたはサイト上の壊れた発信リンク(またはすべての壊れたリンクを同時に)を識別する方法。
同様に、「外部リンクの確認」ボックスにチェックを入れることを忘れずに、最初にHTMLコンテンツのスキャンに焦点を当てます。
スキャンが完了したら、上部ウィンドウの[外部]タブを選択し、[ステータスコード]を使用してコンテンツをフィルタリングして、200以外のステータスコードを持つURLを識別します。スキャン結果の任意のURLをクリックし、[リンク内]タブを選択します下のウィンドウに-選択したURLを指すページのリストがあります。 この情報を使用して、更新が必要なリンクを特定します。
アウトバウンドリンクの完全なリストをエクスポートするには、[内部]タブの[エクスポート]をクリックします。 また、外部画像、JavaScript、CSS、Flash、およびPDFへのリンクをエクスポートするフィルターを設定することもできます。 エクスポートをページのみに制限するには、「HTML」オプションを使用してソートします。
アウトバウンドリンクのすべての場所とアンカーエントリの完全なリストについては、[詳細エクスポート]メニューから[すべてのアウトリンク]を選択し、エクスポートしたCSVの[宛先]列をフィルターしてドメインを除外します。
スキャンが完了したら、上部ウィンドウの[応答コード]パネルを選択し、[リダイレクト(3xx)]オプションを使用して結果を並べ替えます。 これにより、リダイレクトされるすべての内部リンクおよび発信リンクのリストが取得されます。 「ステータスコード」フィルターを適用すると、結果をタイプ別に分類できます。 下のウィンドウで[リンク]をクリックすると、リダイレクトリンクを使用するすべてのページが表示されます。
このタブから直接情報をエクスポートすると、上部のウィンドウに表示されるデータ(元のURL、ステータスコード、リダイレクトが行われる場所)のみが表示されます。
リダイレクトリンクを含むページの完全なリストをエクスポートするには、[詳細エクスポート]メニューの[リンクのリダイレクト(3xx)]を選択する必要があります。 これにより、すべてのリダイレクトリンクの場所を含むCSVファイルが返されます。 内部リダイレクトのみを表示するには、「宛先」列を使用して、ドメインに関するデータでCSVファイルのコンテンツをフィルタリングします。
ヒント:エクスポートされた2つのファイルの上で、VLOOKUPを使用して、Source列とDestination列を最終URLの場所にマップします。
数式の例は次のとおりです。
= VLOOKUP([@ Destination]、 'response_codes_redirection_(3xx).csv'!$ A $ 3:$ F $ 50.6、FALSE)。 「response_codes_redirection_(3xx).csv」はリダイレクトURLを含むCSVファイルで、「50」はこのファイルの行数です。
サイトコンテンツ
情報のないコンテンツ(いわゆる「シンコンテンツ」-「現在のコンテンツ」)を含むページを識別する方法。
Spiderの作業が完了したら、HTMLフィルタリングを設定して[内部]パネルに移動し、[単語数]列まで右にスクロールします。 単語数の原則に従ってページのコンテンツをソートし、テキストが最も少ないページを特定します。 対応するURLの横に[単語数]列を左にドラッグすると、情報がさらに明らかになります。 CSV形式のデータを使いたければ、[内部]タブの[エクスポート]ボタンをクリックします。
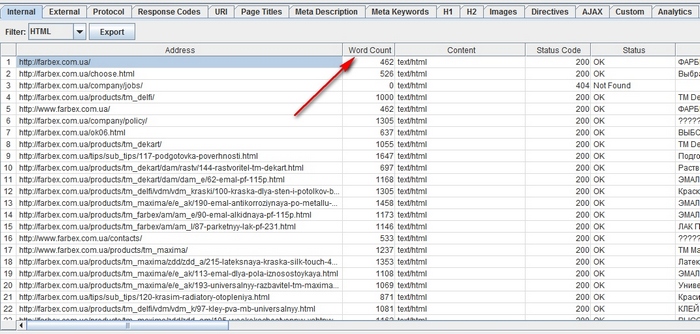
ワードカウントを使用すると、投稿されたテキストの量を推定できますが、このテキストが商品/サービスの名前だけなのか、キーワードに最適化されたブロックなのかについての明確な情報は提供しません。
特定のページの画像へのリンクのリストを強調表示する場合。
すでにサイト全体または別のフォルダをスキャンしている場合は、上のウィンドウでページを選択し、下のウィンドウで[画像情報]をクリックして、このページで見つかった画像を表示します。 写真は「宛先」列にリストされます。
ヒント:下部のウィンドウのエントリを右クリックして、URLをコピーまたは開きます。

この特定のURLをスキャンすることにより、単一のページに画像を表示できます。 Spiderスキャン構成の設定でスキャンの深さが「1」に設定されていることを確認します。 ページがスキャンされた後、「画像」タブに移動すると、Spiderが検出できたすべての画像が表示されます。
最後に、CSVを希望する場合は、[詳細エクスポート]メニューの[すべての画像の代替テキスト]オプションを使用して、すべての画像、その場所、および関連する置換テキストのリストを表示します。
置換テキストのない画像、または長い代替テキストのある画像を見つける方法。
まず、Spiderの[構成]メニューで[イメージの確認]の位置が選択されていることを確認する必要があります。 スキャンが完了したら、「画像」タブに移動し、「欠落している代替テキスト」または「100文字を超える代替テキスト」オプションを使用してコンテンツをフィルタリングします。 下のウィンドウの[画像情報]タブをクリックすると、少なくともいくつかの画像が配置されているすべてのページが表示されます。 ページは[差出人]列にリストされます。

同時に、「高度なエクスポート」メニューで時間を節約し、「すべての画像の代替テキスト」(すべての画像、すべてのテキスト)または「代替画像のない画像」(代替タグのない画像)をCSV形式にエクスポートできます。
Spider設定メニューで、スキャンする前に「CSSをチェック」を選択します。 プロセスの最後に、「CSS」オプションを使用して「Internal」パネルで分析結果をフィルタリングします。
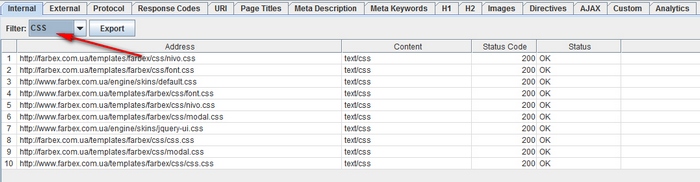
Spider設定メニューで、スキャンする前に、「JavaScriptをチェック」を選択します。 プロセスの最後に、「JavaScript」オプションを使用して「内部」パネルで分析結果をフィルタリングします。
サイトで使用されるすべてのjQueryプラグインとその場所を識別する方法。
まず、構成メニューで「JavaScriptをチェック」が選択されていることを確認します。 スキャンが完了したら、「内部」パネルで「JavaScript」フィルターを適用し、「jQuery」を検索します。 これにより、プラグインを含むファイルのリストを取得できます。 表示しやすいように、「アドレス」オプションでリストを並べ替えます。 次に、下部のウィンドウでInLinksを表示するか、情報をCSVにエクスポートします。 ファイルを使用するページを見つけるには、「差出人」列で作業します。
これに加えて、「Advanced Export」メニューを使用して「All Links」をCSVにエクスポートし、「Destination」列を除外してjquery URLのみを表示できます。
ヒント:すべてのjQueryプラグインがCEOに悪いだけではありません。 jQueryを使用してサイトを表示する場合、インデックスを作成しようとしているコンテンツがページのソースコードに含まれており、その後ではなくページの読み込み時に表示されることを確認するのは理にかなっています。 この側面がよくわからない場合は、インターネット上のプラグインについて読んで、その仕組みについて詳しく学んでください。
サイトのどこでフラッシュがホストされているかを判断する方法。
スキャンする前に、構成メニューで「SWFをチェック」を選択します。 そして、スパイダーの作業の最後に、「内部」パネルの結果を「Flash」という値でフィルタリングします。

この方法では、ページにある.SWFファイルのみを検索できることに注意してください。 プラグインがJavaScriptを介してプルされる場合、カスタムフィルターを使用する必要があります。
スキャンが完了したら、「内部」パネルの「PDF」オプションを使用してSpiderの結果をフィルタリングします。
サイトまたはページグループ内のコンテンツセグメンテーションを識別する方法。
異常なコンテンツを含むサイト上のページを検索する場合は、このページに固有ではないHTML印刷を表示するカスタムフィルターを設定します。 これは、Spiderの起動前に行う必要があります。
これを行うには、Spiderを起動する前に、カスタムフィルターをインストールする必要があります。 それをインストールするには、構成メニューに移動し、「カスタム」をクリックします。 その後、ページのソースコードから任意のコードを入力します。
与えられた例では、タスクはそれぞれFacebookソーシャルネットワークの「いいね」ボタンを含むページを見つけることであり、http://www.facebook.com/plugins/like.php形式のフィルターが作成されました。
これを行うには、<iframeタグに適切なユーザーフィルターを設定する必要があります。
埋め込まれたビデオまたはオーディオコンテンツを含むページを見つける方法。
これを行うには、YouTubeまたはサイトで使用される他のメディアプレーヤーの埋め込みコードスニペットにカスタムフィルターを設定します。
メタデータとディレクティブ
見出しが長い、短い、または欠落しているページ、メタの説明、またはメタキーワードを見つける方法
スキャンが完了したら、「ページタイトル」タブに移動し、「70文字以上」でコンテンツをフィルタリングして、過度に長いページタイトルを表示します。 Meta DescriptionパネルとURLパネルでも同じことができます。 まったく同じアルゴリズムを使用して、ヘッダーまたはメタデータが欠落または短いページを識別できます。

重複した見出し、メタの説明、またはメタキーワードを持つページを見つける方法
スキャンが完了したら、[ページタイトル]タブに移動し、[重複]でコンテンツをフィルター処理して、重複したページタイトルを表示します。 Meta DescriptionパネルとURLパネルでも同じことができます。
リダイレクト/書き換え/正規化する必要がある重複コンテンツおよび/またはURLを見つける方法。
Spiderが作業を完了したら、「URL」タブに移動し、「Underscores」、「Uppercase」または「Non ASCII Characters」を使用して結果をフィルタリングし、より標準的な構造に書き換えられる可能性のあるURLを明らかにします。 複製ツールでフィルタリングして、複数のURLバージョンを持つページを表示します。 動的フィルターを適用して、パラメーターを含むURLを認識します。
さらに、「HTML」フィルターから「内部」パネルに移動し、さらに「ハッシュ」列まで右にスクロールすると、各ページに文字と数字の一意のシーケンスが表示されます。 [エクスポート]をクリックすると、Excelの条件付き書式設定を使用して、この列の重複する値を強調表示し、最終的にページが同一で表示されることを示すことができます。
スキャン後、[ディレクティブ]パネルに移動します。 ディレクティブのタイプを表示するには、右にスクロールして、どの列が埋められているかを確認します。 または、フィルターを使用して、次のタグのいずれかを見つけます。
- 索引
- インデックスなし
- フォローする;
- Nofollow;
- アーカイブなし
- Nosnippet;
- Noodp;
- Noydir;
- 画像インデックス
- 翻訳しない
- Unavailable_after;
- リフレッシュ
- 正規
robots.txtファイルが期待どおりに機能するかどうかを確認する方法。
デフォルトでは、Screaming Frogはrobots.txtと一致します。 優先順位として、プログラムはユーザーエージェント専用に作成されたディレクティブに従います。 存在しない場合、SpiderはGoogleボットの指示に従います。 Googlebot用の特別なディレクティブがない場合、Spiderはすべてのユーザーエージェントで受け入れられるグローバルディレクティブに従います。 この場合、Spiderは、後続のすべてのディレクティブに影響を与えることなく、ディレクティブのセットを1つだけ選択します。
Spiderからサイトの一部をブロックする必要がある場合は、これらの目的のためにユーザーエージェントScreaming Frog SEO Spiderで通常のrobots.txtの構文を使用します。 robots.txtを無視する場合は、プログラム構成メニューで適切なオプションを選択するだけです。
スキーママークアップまたはその他のmicrodataを見つけて確認する方法。
スキーママークアップまたはその他のmicrodataを含むすべてのページを検索するには、カスタムフィルターを使用する必要があります。 [構成]メニューで[カスタム]をクリックし、探しているマーカーを挿入します。
スキーママークアップを含むすべてのページを検索するには、次のコードスニペットをカスタムフィルターに追加します:itemtype = http://schema.org。
特定のタイプのマークアップを見つけるには、より具体的にする必要があります。 たとえば、カスタムフィルタ‹span itemprop =” ratingValue”›を使用すると、評価を構築するためのスキーママークアップを含むすべてのページを検索できます。
スキャンには5つの異なるフィルターを使用できます。 その後、「OK」をクリックして、ソフトウェアスキャナーでサイトまたはページのリストを表示するだけです。
スパイダーの作業が終了したら、上部ウィンドウの「カスタム」タブを選択して、探しているマーカーのあるすべてのページを表示します。 複数のユーザーフィルターを定義した場合、フィルターページ間でスキャン結果を切り替えて、それらを1つずつ表示できます。
サイトマップ
スパイダーがサイトのクロールを完了したら、[詳細エクスポート]をクリックして[XMLサイトマップ]を選択します。
サイトマップを保存し、Excelで開きます。 「読み取り専用」を選択し、「XMLテーブルとして」ファイルを開きます。 一部の回路を統合できないというメッセージが表示される場合があります。 「はい」ボタンをクリックするだけです。
サイトマップが表形式で表示されたら、頻度、優先度、その他の設定を簡単に変更できます。 サイトマップには、各URLの優先(正規)バージョンが1つだけ含まれていることを確認してください。パラメータやその他の重複要因はありません。
変更を行った後、ファイルをXMLモードで保存します。
まず、PCにサイトマップのコピーを作成する必要があります。 URLに移動してファイルを保存するか、Excelにインポートすることにより、ライブサイトマップを保存できます。
その後、「Mode」と呼ばれる「Screaming Frog」メニューセクションに移動し、「List」を選択します。 ページの上部で[ファイルの選択]をクリックし、ファイルを選択してスキャンを開始します。 [内部]タブの[サイトマップの未加工]セクションでのSpiderの作業が完了すると、リダイレクト、404エラー、URLの重複などを確認できます。
一般的なトラブルシューティングのヒント
サイトの一部のセクションがインデックス化またはランク付けされていない理由を判断する方法。
一部のページがインデックスに登録されないのはなぜですか? 最初に、それらがrobots.txtになく、noindexとしてマークされていないことを確認します。 次に、スパイダーがサイトのページにアクセスして内部リンクをチェックできることを確認する必要があります。 クモがサイトをクロールした後、[内部]タブのHTMLフィルターを使用して、内部リンクのリストをCSVファイルとしてエクスポートします。
CSVドキュメントを開き、2番目のシートで、インデックスまたはランク付けされていないURLのリストをコピーします。 VLOOKUPを使用して、同様の問題のあるURLがクロール結果に存在するかどうかを確認します。
サイトの移転/再設計が成功したかどうかを確認する方法。
Screaming Frogを使用して、古いURLがリダイレクトされているかどうかを確認できます。「リスト」モードはこれに役立ちます。これにより、ステータスコードを確認できます。古いURLで404エラーが発生した場合、リダイレクトが必要なURLが正確にわかります。スキャンプロセスが完了したら、[応答コード]タブに移動し、[応答時間]列を "大から小"の基準で並べ替えて、読み込み速度が遅いページを見つけます。まず、マルウェアやスパムによって残された痕跡を特定する必要があります。次に、構成メニューで[カスタム]をクリックし、探しているマーカーの名前を入力します。1回のスキャンで最大5つのマーカーを分析できます。必要な情報をすべて入力し、「OK」をクリックしてサイト全体またはページのリストを調べます。プロセスが完了したら、上部ウィンドウにある[カスタム]タブに移動して、指定した不正プログラムやウイルスプログラムの「痕跡」が見つかったすべてのページを表示します。複数のユーザーフィルターを設定した場合、それぞれの結果は別のウィンドウに表示され、フィルター間を移動してそれらに慣れることができます。PPCと分析
コンテキスト広告に使用されるすべてのURLのリストを同時に確認する方法。
アドレス一覧を.txtまたは.csv形式で保存し、モード設定を「モード」から「リスト」に変更します。次に、ダウンロードするファイルを選択して、「開始」をクリックします。[内部]タブで各ページのステータスコードを表示します。こする
できるだけ多くの情報を取得することが重要なURLがたくさんありますか?「モード」モードをオンにしてから、アドレスのリストを.txtまたは.csv形式でダウンロードします。Spiderが作業を完了すると、リスト内の各ページのステータスコード、発信リンク、単語数、そしてもちろんメタデータを確認できます。特定のマーカーを含むすべてのページのスクレイピングサイトを作成する方法。
まず、マーカー自体を扱う必要があります-必要なものを正確に決定します。その後、「構成」メニューで「カスタム」をクリックし、目的のマーカーの名前を入力します。最大5つの異なるマーカーを入力できることに注意してください。次に、[OK]をクリックしてスキャンプロセスを開始し、指定された「トレース」の存在によってサイトのページをフィルタリングします。 この例は、商品のコストに関連するセクションに「お電話ください」という言葉を含むすべてのページを見つける必要がある状況を示しています。これを行うために、HTMLコードが見つかり、ページのソースコードからコピーされました。スキャン後、指定されたマーカーを含むすべてのページのリストを表示するには、上部ウィンドウの「カスタム」セクションに移動する必要があります。複数のマーカーが入力されている場合、それぞれのマーカーに関する情報が個別のウィンドウに表示されます。ヒント:この方法は、サイトに直接アクセスできない場合に適しています。クライアントのサイトからデータを受信する必要がある場合、必要な情報をデータベースから直接取得して転送するように依頼する方がはるかに簡単かつ迅速になります。
この例は、商品のコストに関連するセクションに「お電話ください」という言葉を含むすべてのページを見つける必要がある状況を示しています。これを行うために、HTMLコードが見つかり、ページのソースコードからコピーされました。スキャン後、指定されたマーカーを含むすべてのページのリストを表示するには、上部ウィンドウの「カスタム」セクションに移動する必要があります。複数のマーカーが入力されている場合、それぞれのマーカーに関する情報が個別のウィンドウに表示されます。ヒント:この方法は、サイトに直接アクセスできない場合に適しています。クライアントのサイトからデータを受信する必要がある場合、必要な情報をデータベースから直接取得して転送するように依頼する方がはるかに簡単かつ迅速になります。URLの書き換え
クロールされたURLからセッションIDまたはその他のパラメーターを見つけて削除します。
IDセッションまたはその他のパラメーターでURLを識別するには、デフォルト設定に基づいてサイトをスキャンするだけです。Spiderの作業が完了したら、「URL」タブに移動して「動的」フィルターを適用し、必要なパラメーターを含むすべてのURLを表示します。スキャンしたページの表示からパラメーターを削除するには、設定メニューで「URL Rewriting」を選択します。次に、「パラメーターの削除」パネルで「追加」をクリックして、URLから削除するパラメーターを追加し、「OK」をクリックします。変更を有効にするには、Spiderを再起動する必要があります。スキャンしたURLを書き換える方法(たとえば、.comを.co.ukに変更するか、すべてのURLを小文字で書き込む)。
スパイダーによって解決されたアドレスのいずれかを書き換えるには、構成メニューで[URL書き換え]を選択し、[正規表現の置換]パネルで[追加]をクリックして、置換するものにRegExを追加します。必要な修正をすべて行った後、「書き換え前のURL」ウィンドウにテストURLを入力して、「テスト」パネルでそれらを確認できます。文字列「書き換え後のURL」は、設定したパラメーターに従って自動的に更新されます。すべてのURLを小文字に書き換える必要がある場合は、[オプション]パネルで[検出されたURLの小文字]を選択します。変更を行った後にSpiderを再起動して、それらが引き継ぐようにしてください。キーワード分析
競合他社のサイトのどのページが最も価値があるかを見つける方法。
一般に、競合他社は、内部リンクによってリンクの人気を拡大し、最も価値のあるページへのトラフィックを促進しようとします。 SEOに注意を払う競合他社も、企業ブログとサイトの最も重要なページとの間に強力なリンクを構築します。スキャンして競合他社のサイトの最も重要なページを見つけてから、「内部」パネルに移動し、「Inlinks」列の結果を「大から小」の順に並べ替えて、どのページに最も内部リンクがあるかを確認します。競合他社の企業ブログに関連するページを表示するには、Spiderの設定メニューで[フォルダー外のリンクをチェック]チェックボックスをオフにして、ブログのフォルダー/サブドメインをスキャンします。次に、「外部」パネルで、メインドメインのURLによる検索を使用して結果をフィルターします。最後まで右にスクロールし、「Inlinks」列のリストをソートして、最も頻繁にリンクするページを表示します。ヒント:プログラムテーブルを操作するために、ドラッグアンドドロップメソッドを使用して列を左右に移動します。内部リンクにアンカーを使用している競合他社を見つける方法。
[詳細エクスポート]メニューから[すべてのアンカーテキスト]を選択して、サイトのアンカーエントリを含むCSVをエクスポートし、その場所とバインドを確認します。競合他社が自分のサイトで使用しているメタキーワードを見つける方法。
スパイダーがスキャンを完了した後、メタキーワードパネルを見て、個々のページにあるメタキーワードのリストを表示します。メタキーワード1列をアルファベット順に並べ替えて、情報をより明らかにします。参照ビル
URLのリストを収集することで、リストモードでクロールして、ページに関する可能な限り多くの情報を収集できます。スキャンが完了したら、[応答コード]パネルのステータスコードを確認し、[送信リンク]パネルで送信リンク、リンクタイプ、アンカーエントリ、およびディレクティブを調べます。これにより、これらのページをリンクしているサイトとその方法がわかります。[アウトリンク]パネルを確認するには、関心のあるURLが上部ウィンドウで選択されていることを確認してください。カスタムフィルタを使用して、これらの場所に既にリンクがあるかどうかを判断することをお勧めします。[詳細エクスポートメニュー]パネルの[すべてのリンク]オプションをクリックして、リンクの完全なリストをエクスポートすることもできます。これにより、サードパーティのサイトへのリンクだけでなく、リストの個々のページへの内部リンクも表示できます。そのため、独自のリソースへのリンクを受け取りたいサイトがあります。Screaming Frogを使用すると、サイトのページ(またはサイト全体)への壊れたリンクを見つけることができ、好きなリソースの所有者に連絡した後、可能であれば壊れたリンクをリソースへのリンクに置き換えるように彼に提供します。バックリンクのリストをダウンロードし、リストモードでSpiderを起動します。次に、「Advanced Export Menu」の「All Out Links」をクリックして、外部リンクの完全なリストをエクスポートします。これにより、これらのページのすべてのリンクのURLとアンカーテキスト/代替テキストが提供されます。その後、CSVファイルの「Destination」列をフィルタリングして、サイトがリンクされているかどうか、およびどのアンカーテキスト/ Altテキストが含まれているかを判断できます。バックリンクが正常に削除されたことを確認する方法。
これを行うには、URLのルートドメインを含むカスタムフィルターをインストールし、バックリンクのリストをアップロードして、「リスト」モードでSpiderを起動する必要があります。スキャンが完了したら、カスタムパネルに移動して、引き続きリンクされているページのリストを表示します。ヒント:スキャン結果の上部ウィンドウでURLを右クリックすると、特に次のことができることに注意してください。- URLをコピーまたは開きます。
- アドレスの再スキャンを実行するか、リストから削除します。
- このページのURLまたは画像、インバウンドリンクとアウトバウンドリンクに関する情報をエクスポートします。
- Google、Bing、Yahooのページインデックスを確認してください。
- Majestic、OSE、Ahrefs、Blekkoのページバックリンクを確認してください。
- キャッシュバージョンを表示します。
- ページの古いバージョンを表示します。
- ページが配置されているドメインのrobots.txtを開きます。
- 同じIP上で他のドメインの検索を実行します。
おわりに
そこで、Screaming Frogプログラムの使用に関するすべての側面を詳細に調査しました。詳細な手順が、サイト監査をより簡単に、そして同時に非常に効果的にするのに役立つと同時に、膨大な時間を節約できることを願っています。