ICBDA 2015の一環として
、 Sberbankは顧客の流出を予測する競争を開催しました 。 私はこれについて少し混乱しましたが、何も勝ちませんでしたが、決定プロセスについて説明したいと思います。
Sberbankはデータをdataしみなく出荷しました。 11月、12月、1月に流出に陥ったことが知られている約20,000人のユーザーが与えられました。 また、2月に退職するかどうかを推測する必要があるユーザーが30,000人までいました。 さらに、およそ次の内容の35GBファイルが添付されました。
,
フィールドの物理的意味は特に開示されていません。 彼らは「とても面白い」と言った。 ユーザーIDを探す場所のみがわかっていました。 この配置は私には非常に奇妙に思えました。 ただし、Sberbankも理解できます。 そもそも、この地獄のデータ配列を脇に置き、トレーニングセットとテストセットのユーザーをより詳細に調べることにしました。
それは信じられないほど判明しました:ユーザーが11月と12月に去らなかったなら、1月に彼はおそらく去らないでしょう。 ユーザーが去った場合、彼はほとんどの場合戻らないでしょう:
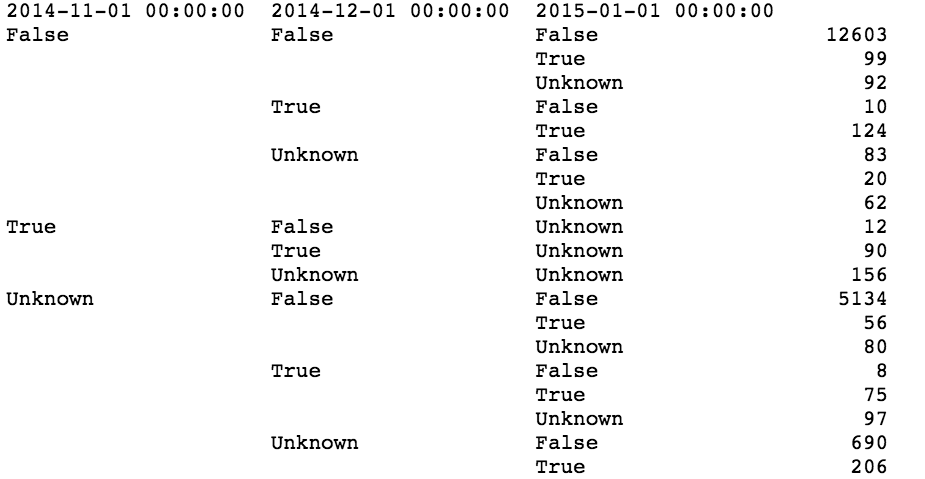
さらに、テストサンプルのユーザーの70%がトレーニングを受けていることがわかりました。 つまり、次の独創的な修飾子が頼みます。ユーザーが1月に去った場合、彼は流出し、2月に、1月に去らなかった場合、彼は流出しません。 このようなソリューションの品質を推定するために、1月からすべてのユーザーを取得し、12月のデータに基づいてユーザーの予測を行います。 それは非常に判明していませんが、何よりも優れています:
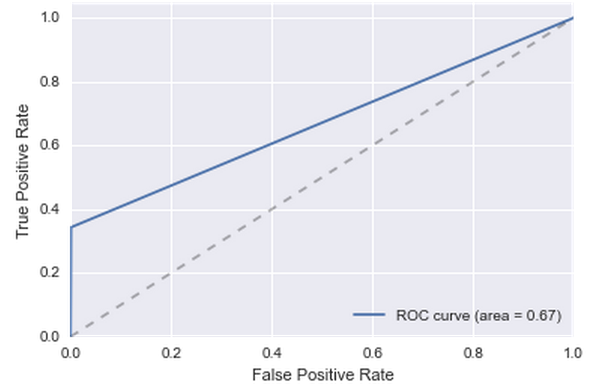
はい、1月と2月がまったく異なる月であることは明らかです。 12月の終わり、1月の前半は一般的にロシア人にとって特別です。 しかし、特別な選択はありません。何かについてアルゴリズムをチェックする必要があります。
何らかの方法でソリューションを改善するために、説明なしで巨大ファイルをソートする必要があります。 最初に、トレーニングまたはテストサンプルからidがユーザーに属していないすべてのレコードを破棄することにしました。 ああ、恐ろしいことに、単一のレコードを捨てることはできませんでした。 そこには1人のユーザーが対応していませんが、平均で300エントリです。 つまり、これらは集約されたデータではなく、ある種のログです。 さらに、60列のうち50列はハッシュです。 値の代わりにハッシュを使用してログを記録します。 私の意見では、これは完全にナンセンスです。 新しい知識を発見できる瞬間のデータ分析が大好きです。 この場合、開始は次のようになります。「7番目の列のユーザーが8UCcQrvgqGa2hc4s2vzPs3dYJ30 =を頻繁に持っている場合、おそらく、すぐに辞めることを意味します。」 あまり面白くない。 それにもかかわらず、私はいくつかの仮説をテストし、何が起こるかを見ることにしました。
ログの各行には1つではなく2つのIDがあることが知られています。 したがって、私たちは何らかのトランザクションで作業していると仮定しました。 これを何らかの方法で確認するために、idが頂点に配置されたグラフが作成され、同じレコードで2つのidが出会った場合にエッジが表示されました。 ログに本当にトランザクションがある場合、グラフは非常にまばらになり、クラスタに適切にグループ化されるはずです。 結果は私が期待したものとはまったく異なり、クラスター間に目で見た多くのつながりがありました。
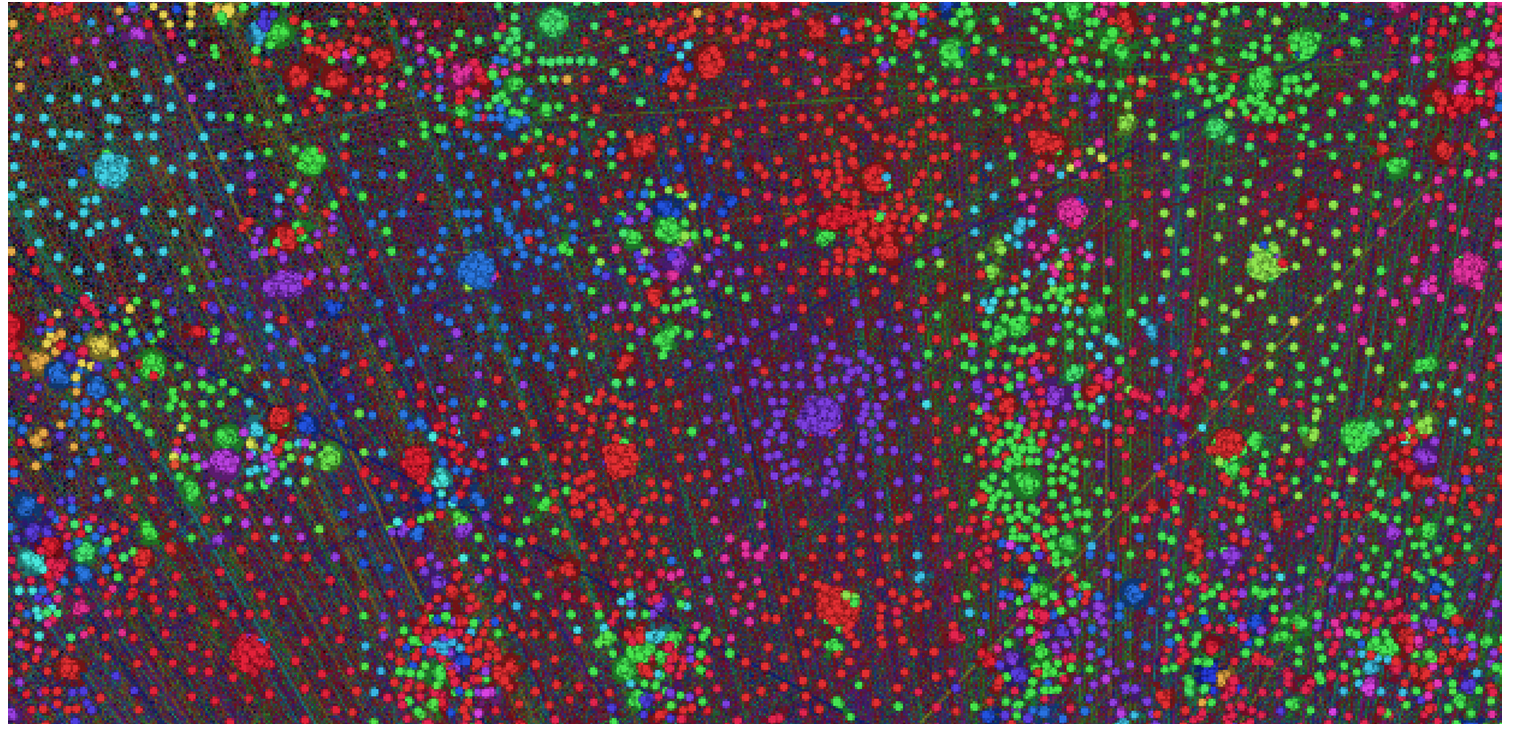
しかし、正式には、モジュール性が非常に高く、1つの頂点の周りにクラスターが形成されることが多かったため、結局これらはトランザクションであると判断しました。 さらに、より良いアイデアはありませんでした。
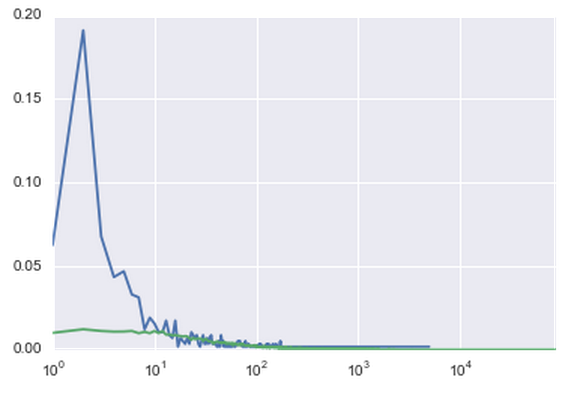
トランザクションを処理する場合、モデルを論理的に補完するのは、着信トランザクションと発信トランザクションの数です。 実際、1月に退職した人のうち、ほぼ40%が10件未満のインバウンドトランザクションを抱えていました。
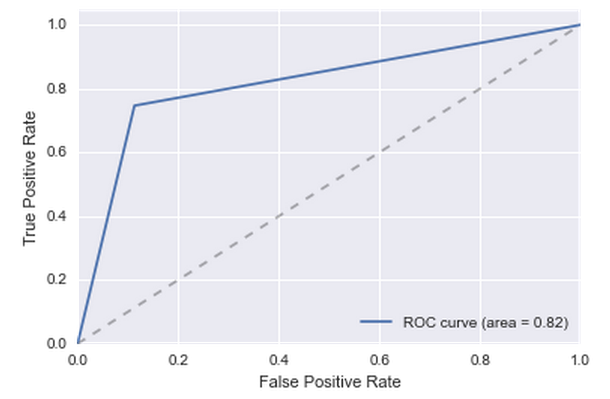
この単純な条件をモデルに追加して、高品質を取得します。
トランザクションの数だけがそれほどクールではないことは明らかです。 ユーザーは2014年1月に500件の取引を行い、2015年1月に簡単に退出できます。トレンドを確認する必要があります。 漏れは、確かに、すべてが最初の2か月目に終了します。
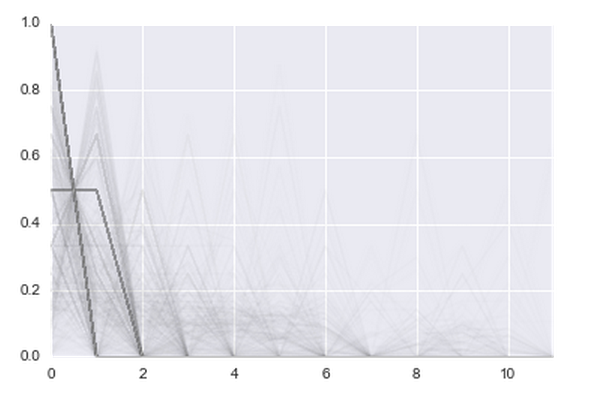
そして、より複雑な物語を持っている人のために:
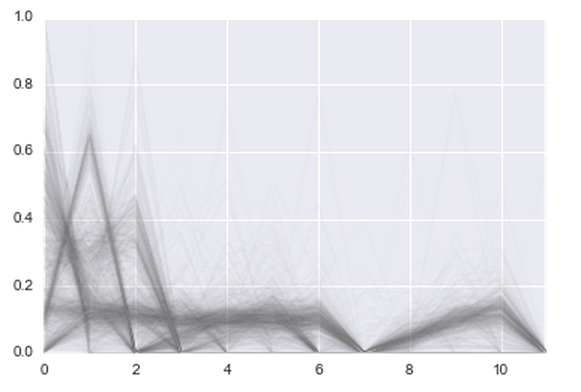
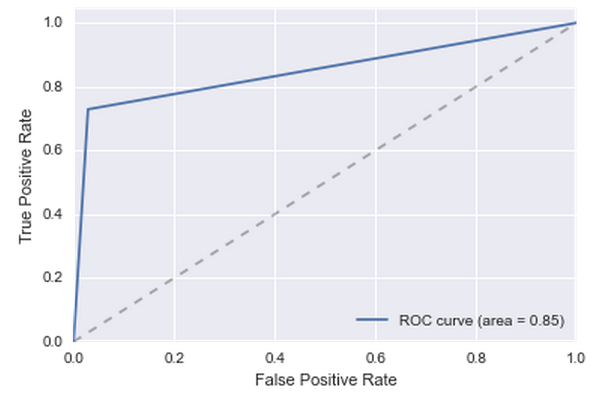
どういうわけか、この条件をモデルに追加できなかったため、機械学習に頼らなければなりませんでした。 「最初のトランザクションの前の月」、「最後のトランザクションの前の月」、「トランザクションのある月の数」などの機能について、深さ10の500ツリーでRandomForestを見ました。 品質が少し向上しました。
理解しやすい単純な解決策が尽きました。 そのため、さらに詳細な説明なしで巨大なファイルを掘り下げなければなりませんでした。 すべての列について、見つかった一意の値の数が計算されました。

一意の値の数がなぜ小数になるのですか? なぜなら、私は
固定メモリを使用して
一意の値を計算する
トリッキーな方法を使用する必要があったからです。 セットにすべてを詰め込んだだけでは、十分なメモリが得られません。
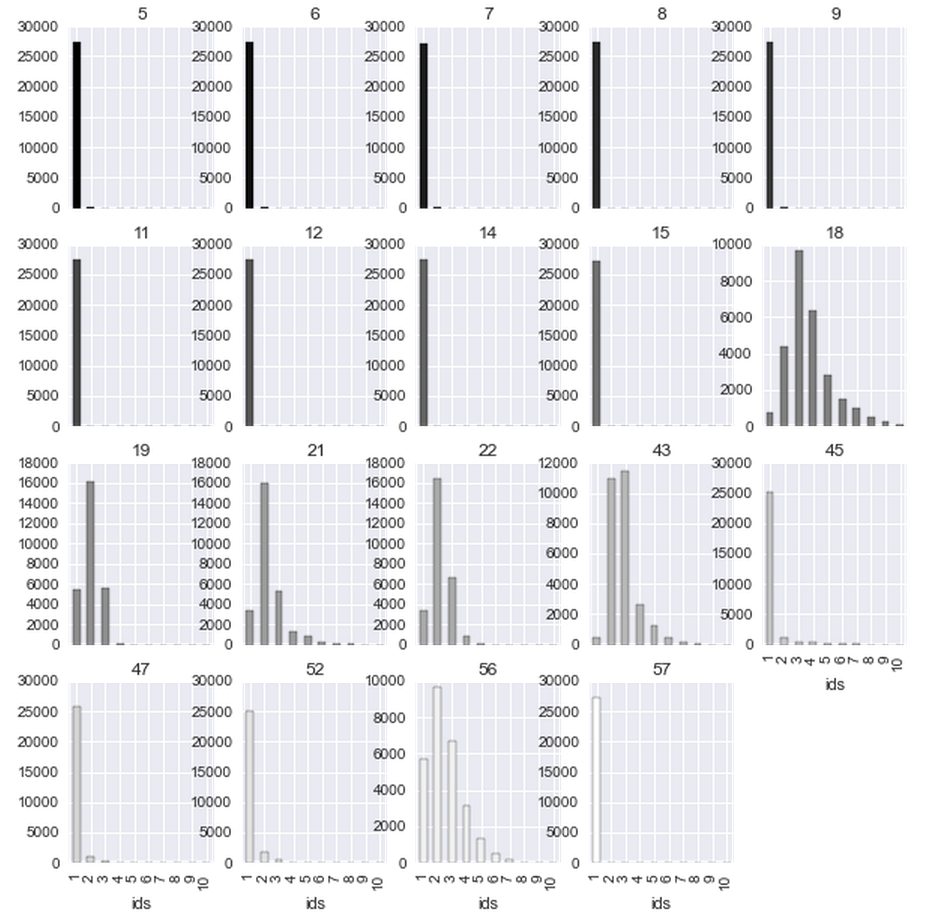
次に、合理的な数の異なる値がヒストグラムで計算された列の場合:

いくつかのヒストグラム、たとえば14と33、22と41が類似していることがわかります。実際、ほとんどのフィールドはペアになっています(はい、手動で機能相関グラフを作成しました)。

つまり、列の一部はid1、id2を表します。 一部のフィールドはトランザクションを示しています。 ユーザーを説明する列を確認するために、同じidに対して異なる値をとる頻度を計算しました。 列5から15はidで複数の値を取ることはほとんどないことが判明しました。 実際、それらのいくつかは都市の名前、郵便番号です。 彼らはカテゴリーとしてモデルに入りました。 残りは同じidに対して異なる値を取ることができます(もちろん、ほとんどがnullです)ので、それらは重み付きでモデルに入りました。
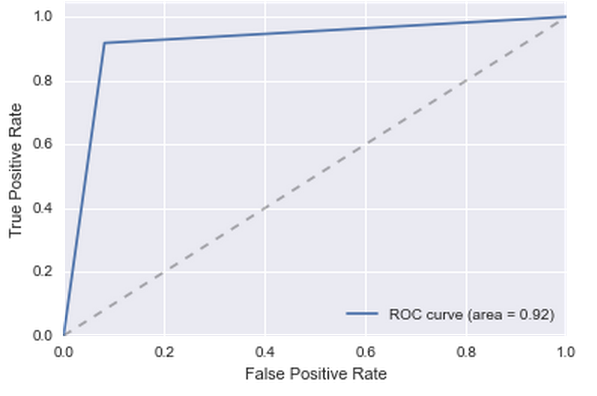
これらのすべてのカテゴリ機能により、モデルの複雑さは大幅に増加しました;新しい機能のほとんどは特別な貢献をしていません。 しかし、1つの機能がありました-56番目。 彼女は多くの影響を与えました。 品質が大幅に向上しました。
別のクールな機能を試しました。 彼は最初に構築したトランザクショングラフを取り出し、リークして残ったユーザーのいる場所を調べました。 ほとんどすべてが漏れているクラスターがあることに驚いた。 確かに、分類器はそれらに間違いを犯さなかったため、品質向上は機能しませんでした。
RandomForestのパラメーターも選択しました。 テストサンプルをマークアップしました。 1月に去った人は2月に去ると確信しました。 私は一般に、去った人の割合が正常であることを確認しました。 そして、ズベルバンクに送られました。 しかし、トップ3に自分が見つからなかったため、明らかに何かがうまくいかなかったようです。 しかし、大きなトップは表示されませんでした。