腐敗に関して最も疑わしい職員を特定する方法は? 最も簡単な方法は、収入と生活水準を比較することです。
この記事では、役人に関する情報が公開されているサイトの可能性を示し、これらの役人がどのように生きているかを調べ、腐敗の観点から最も疑わしい人を特定しようとします。
公共収入の報告が重要なのはなぜですか? それらを制御できるからです。
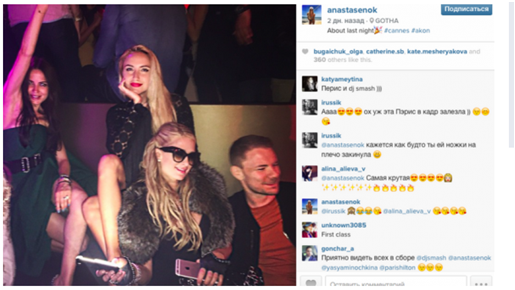 ウクライナのアレクサンドル・エルショフの交通警察の元長の娘のインスタグラムからの写真。 写真では、パリス・ヒルトンの隣にあるカンヌのエルショフの娘。 スキャンダルの結果、 Yershovは 、申告された収入と家族のライフスタイルの不一致により辞職しました。
ウクライナのアレクサンドル・エルショフの交通警察の元長の娘のインスタグラムからの写真。 写真では、パリス・ヒルトンの隣にあるカンヌのエルショフの娘。 スキャンダルの結果、 Yershovは 、申告された収入と家族のライフスタイルの不一致により辞職しました。データはどこから来たのですか?
当局者の宣言に関するデータはdeclarations.com.uaから、エリートの不動産所有者についてはgarnahata.in.uaから取得しました。 どちらのサイトも、元はヤヌコビッチの家からの文書をデジタル化するために組織されたジャーナリストとボランティアの事務文具コミュニティのプロジェクトです。
現在、さまざまな部門の役人の約1万1千の宣言と、エリートの不動産所有者の約9千の記録がサイトで入手できます。 宣言者の中には、主にさまざまな省庁(現場サービスを含む)、法廷職員、検察官の代表者がいます。 データは代表的なふりをしていない(ウクライナの
約40万人の役人)が、それらを掘り下げることはまだ興味深い。
どちらのサイトにもオープンAPIがあり
、Pythonスクリプトを使用してJSON形式のデータをダウンロードでき
ます 。 宣言のデータオブジェクトのスキーマはgithubに
あり 、エリートプロパティ所有者のデータのオブジェクトのスキーマは
ここにあり
ます 。 データ構造の例と理解-
サイトの宣言の1つのスキャンされたコピー 。
データをダウンロードしたら、それらをRに解析し、いくつかを集計して、2013年と2014年の宣言のみを残しました。
JSONファイルからデータを取得するサンプルコード
decl_raw<-rjson::fromJSON(file="feed.json")
decl_df<-data.frame(matrix(NA,nrow=length(decl_raw), ncol = 0))
decl_df$general.post.region<-“”
decl_df$general.post.office<-“”
decl_df$general.post.post<-“”
for (i in 1:length(decl_raw))
{
decl_df$general.post.region[i]<-decl_raw[[i]]$general$post$region
decl_df$general.post.office[i]<-decl_raw[[i]]$general$post$office
decl_df$general.post.post[i]<-decl_raw[[i]]$general$post$post
}
decl_df$vehicle35<-0
decl_df$vehicle36<-0
decl_df$vehicle37<-0
decl_df$vehicle38<-0
decl_df$vehicle39<-0
decl_df$vehicle40<-0
decl_df$vehicle41<-0
decl_df$vehicle42<-0
decl_df$vehicle43<-0
decl_df$vehicle44<-0
for (i in 1:length(decl_raw))
{
for (unit in 35:44)
{
j = 0
col_name<-paste0("vehicle", unit)
raw_col_name<-paste0("decl_raw[[",i,"]]$vehicle$`",unit,"`")
if (length(eval(parse(text=raw_col_name)))!=0)
{
for (k in 1:length(eval(parse(text=raw_col_name))))
{
if (length(eval(parse(text=paste0("decl_raw[[",i,"]]$vehicle$`",unit,"`[[",k, "]]$brand"))))!=0 && eval(parse(text=paste0("decl_raw[[",i,"]]$vehicle$`",unit,"`[[",k, "]]$brand")))!="")
{j = j+1}
}
}
decl_df[i, grep(col_name, colnames(decl_df))]<-j
}
}
decl_df_all$vehicle_names<-""
for (i in 1:length(decl_raw))
{
vname<-""
for (unit in 35:44)
{
col_name<-paste0("vehicle", unit)
raw_col_name<-paste0("decl_raw[[",i,"]]$vehicle$`",unit,"`")
if (length(eval(parse(text=raw_col_name)))!=0)
{
for (k in 1:length(eval(parse(text=raw_col_name))))
{
if (length(eval(parse(text=paste0("decl_raw[[",i,"]]$vehicle$`",unit,"`[[",k, "]]$brand"))))!=0 && eval(parse(text=paste0("decl_raw[[",i,"]]$vehicle$`",unit,"`[[",k, "]]$brand")))!="")
{
vname=paste(vname,eval(parse(text=paste0("decl_raw[[",i,"]]$vehicle$`",unit,"`[[",k, "]]$brand"))), sep=";")
}
}
}
}
decl_df$vehicle_names[i]<-vname
}
— .
. .
decl_df$income.own<-decl_df$income.own.6+decl_df$income.own.7+decl_df$income.own.8+
decl_df$income.own.9+decl_df$income.own.10+decl_df$income.own.11+
decl_df$income.own.12+decl_df$income.own.13+decl_df$income.own.14+
decl_df$income.own.15+decl_df$income.own.16+decl_df$income.own.17+
decl_df$income.own.18+decl_df$income.own.19+decl_df$income.own.20+
decl_df$income.own.21
for (i in 1:nrow(decl_df))
{
if (decl_df$income.own[i]==0 && decl_df$income.own.5[i]>0)
{decl_df$income.own[i]<-decl_df$income.own.5[i]}
}
decl_df$income.family<-decl_df$income.family.6+decl_df$income.family.7+
decl_df$income.family.8+decl_df$income.family.9+decl_df$income.family.10+
decl_df$income.family.11+decl_df$income.family.12+
decl_df$income.family.13+decl_df$income.family.14+
decl_df$income.family.15+decl_df$income.family.16+
decl_df$income.family.17+decl_df$income.family.18+
decl_df$income.family.19+decl_df$income.family.20+
as.numeric(gsub(",", ".", decl_df$income.family.22))
for (i in 1:nrow(decl_df))
{
if (decl_df$income.family[i]==0 && decl_df$income.family.5[i]>0)
{decl_df$income.family[i]<-decl_df$income.family.5[i]}
}
decl_df$income_per_member<-rowSums(cbind(decl_df$income.own,decl_df$income.family), na.rm=TRUE)
decl_df$income_per_member<-decl_df$income_per_member/decl_df$number_of_family_members_incl_decl
decl_df$income_per_member_ths<-decl_df$income_per_member/1000
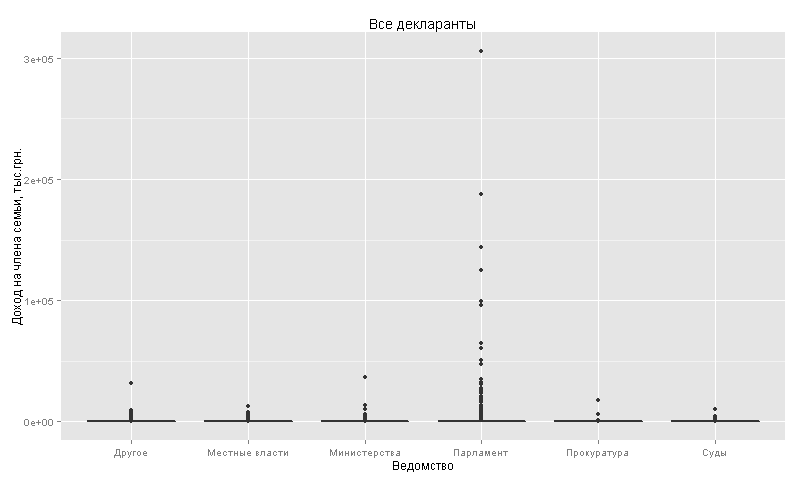
10%- , 10% - -: 10% — 305,8 .. ( 12 .), 90%- 382 ..
quantile(decl_df$income_per_member_ths, probs=seq(0,1,0.1))

:
qplot(data=decl_df, x=office_g, y = income_per_member_ths,
geom="boxplot",
xlab="",
ylab=" , ..",
main=" ")
. 50 .. . 1 .. ( 97%):
qplot(data=decl_df[decl_df$income_per_member_ths<1000,],
x=office_g, y = income_per_member_ths, geom="boxplot",
xlab="",
ylab=" , ..",
main=" 1 ..")
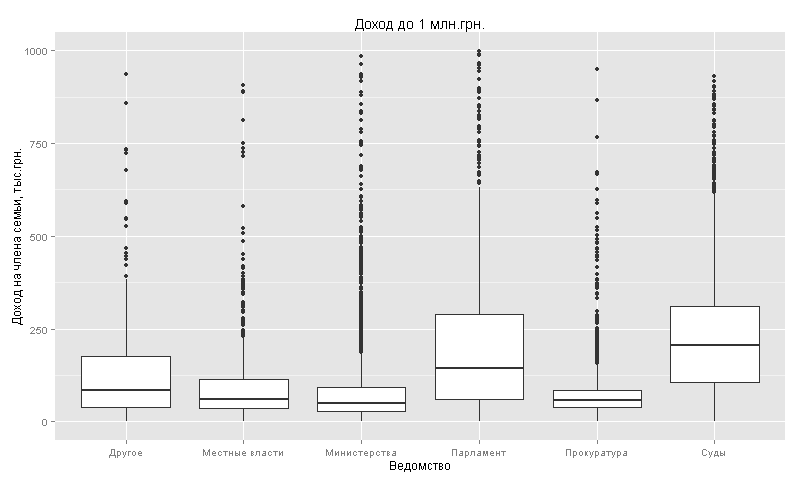
, (231 .) (209 .). 75-100 .. .
vs
, . .
decl_family<-decl_df[decl_df$number_of_family_members_incl_decl>1,]
qplot(data=decl_family, y=income.own/1000, x=income.family/1000,
xlim=c(0,800000), ylim=c(0,800000),
xlab=" , ..", ylab=" , ..")
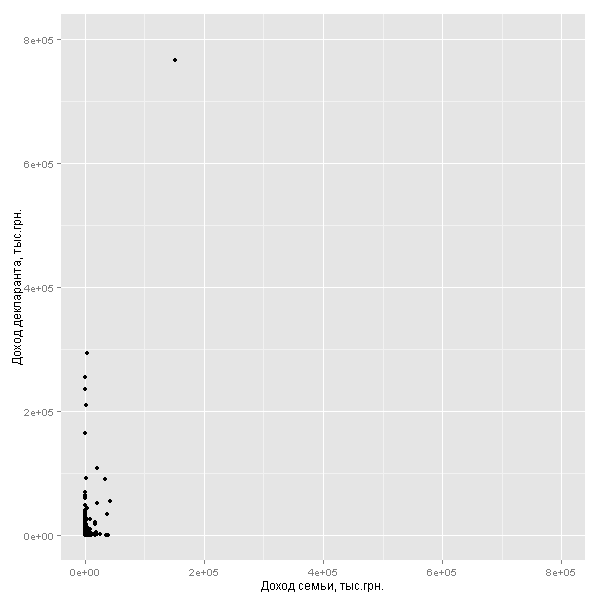
- . , ( 1 .. , — 94%):
nrow(decl_family[decl_family$income.own<1000000 & decl_family$income.family<1000000,])/nrow(decl_family)
qplot(data=decl_family, y=income.own/1000, x=income.family/1000,
xlim=c(0,1000), ylim=c(0,1000),
xlab=" , ..", ylab=" , ..",
main=" 1 ..")

, ( ), , 77% — , 30% (
International Labour Organization)
(. ). , . — (, - ).
decl_family$family.own.income.ratio<-""
for (i in 1:nrow(decl_family))
{
if (decl_family$income.family[i]==0)
{decl_family$family.own.income.ratio[i]<-"1. "}
else
{
if (decl_family$income.family[i]<=0.75*decl_family$income.own[i])
{decl_family$family.own.income.ratio[i]<-"2. (<0.75x)"}
else
{
if (decl_family$income.family[i]<=1.5*decl_family$income.own[i])
{
decl_family$family.own.income.ratio[i]<-"3. (0.75-1.5)"
}
if (decl_family$income.family[i]>1.5*decl_family$income.own[i])
{
decl_family$family.own.income.ratio[i]<-"4. , >1.5x"
}
}
}
}
decl_family$family.own.income.ratio<-as.factor(decl_family$family.own.income.ratio)
y<-as.data.frame(100*prop.table(table(decl_family$family.own.income.ratio,decl_family$office_g), margin=2))
ggplot(y, aes(x = Var2, y = Freq, fill = Var1)) +
geom_bar(stat="identity")+
ylab("%") +
xlab("")+
theme(text = element_text(size=14), legend.title=element_blank(),axis.text.x = element_text(angle=90, size=12,vjust=1,hjust=1))+
geom_text(aes(label = round(Freq,0),ymax=100),size=4,vjust=1.5,position="stack")+
scale_fill_brewer()
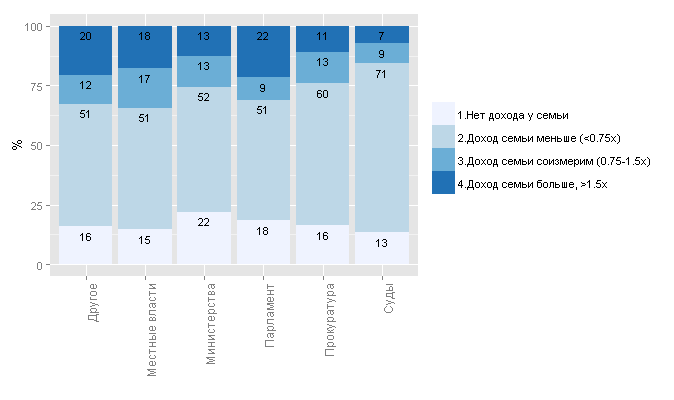
?

— . , , .
— , 40% ( ).
, .
— , . , , . — .
, , — — . .
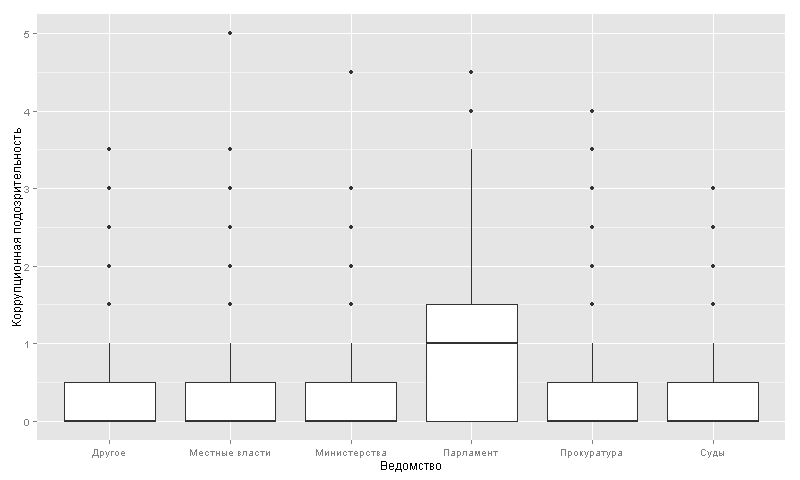
? . 1 .
, . 294 .
decl_df$income.own.and.family<-decl_df$income.own+decl_df$income.family
decl_df$banks<-decl_df$banks45+decl_df$banks47+decl_df$banks49+
decl_df$banks51+decl_df$banks52+decl_df$banks53
decl_df$banks.income.ratio<-decl_df$banks/(decl_df$income.own.and.family+1)
decl_df$susp1<-0
for (i in 1:nrow(decl_df))
{
if (decl_df$banks[i]>5*decl_df$income.own.and.family[i])
{decl_df$susp1[i]<-1}
}
. 50 .
decl_df$susp2<-0
for (i in 1:nrow(decl_df))
{
if (decl_df$income.own.and.family[i]==0)
{decl_df$susp2[i]<-1}
}
, , , .
478 . 25% , 2 — 49 .
, , , .. — , - / , , .
decl_df$estate.own<-decl_df$estate24+decl_df$estate25+
decl_df$estate26+decl_df$estate27+decl_df$estate28
decl_df$estate.family<-decl_df$estate30+decl_df$estate31+
decl_df$estate32+decl_df$estate33+decl_df$estate34
x<-quantile(decl_df[decl_df$number_of_family_members>0,]$income.family, probs=seq(0,1,0.25))[2]
y<-mean(decl_df[decl_df$number_of_family_members>0,]$estate.family)
decl_df$susp3<-0
for (i in 1:nrow(decl_df))
{
if (decl_df$estate.family[i]>y & decl_df$estate.family[i]>decl_df$estate.own[i])
{
if (decl_df$income.family[i]<x)
{decl_df$susp3[i]<-2}
else
{decl_df$susp3[i]<-1}
}
}
128 , - ( ). 44 — .
decl_df$income.from.abroad<-decl_df$income.own.21+as.double(decl_df$income.family.22)
decl_df$susp4<-0
for (i in 1:nrow(decl_df))
{
if (decl_df$income.from.abroad[i]>
decl_df$income.own.and.family[i]-decl_df$income.from.abroad[i])
{decl_df$susp4[i]<-1}
}
, . 31 .
decl_df$vehicles<-decl_df$vehicle35+decl_df$vehicle36+
decl_df$vehicle40+decl_df$vehicle41
decl_df$susp5<-0
for (i in 1:nrow(decl_df))
{
if (decl_df$vehicles[i]>2 & decl_df$estate.own[i]==0 & decl_df$estate.family[i]==0)
{decl_df$susp5[i]<-1}
}
- , . -
Luxury vehicle.
: Acura, Alfa Romeo Giulia, Audi A4, Audi A6, Audi A7, Audi A8, Bentley, BMW 3, BMW 5, BMW 7, Cadillac, Ferrari, Hummer, Infinity, Jaguar, Lamborghini, Land Rover, Lexus, Maserati, Mercedes-Benz C, Mercedes-Benz E, Mercedes-Benz GL, Mercedes-Benz S, Porsche, Rolls-Royce, Saab 9-3, Saab 9-5, Volkswagen Phaeton, Volvo S60, Volvo S80.
, , , ( , ). 653 .
luxury_cars<-c('Acura', 'Lexus', 'Cadillac', 'Alfa Romeo Giulia', 'Jaguar', 'Volvo S60', 'Infinity', 'Saab 9-3', 'BMW 3', 'Audi A4', 'Mercedes-Benz C', 'Volvo S80', 'Audi A6', 'Audi A7', 'Mercedes-Benz E', 'Saab 9-5', 'Maserati', 'BMW 5', 'BMW 7', 'Audi A8', 'Mercedes-Benz S', 'Porsche', 'Volkswagen Phaeton', 'Rolls-Royce', 'Bentley', 'Ferrari', 'Lamborghini', 'Mercedes-Benz GL', 'Hummer', 'Land Rover')
for (j in (1:nrow(decl_df)))
{
decl_df$susp5.1[j]<-0
for (i in (1:length(luxury_cars)))
{
if (grepl(luxury_cars[i], decl_df$vehicle_names[j],
ignore.case=TRUE)==TRUE)
{
decl_df$susp5.1[j]<-decl_df$susp5.1[j]+
length(gregexpr(luxury_cars[i], decl_df$vehicle_names[j],ignore.case=TRUE)[[1]])
}
}
}
decl_df$susp5.2<-0
for (i in (1:nrow(decl_df))) {if (decl_df$susp5.1[i]>0) decl_df$susp5.2[i]<-1}
for (i in (1:nrow(decl_df))) {if (decl_df$vehicles[i]==1) decl_df$susp5.2[i]<-0}
, . 419 .
decl_df$familyPE.own.income.ratio<-0
decl_df[decl_df$income.own.and.family>0,]$familyPE.own.income.ratio<-
decl_df[decl_df$income.own.and.family>0,]$income.family.17/decl_df[decl_df$income.own.and.family>0,]$income.own.and.family
x<-mean(decl_df[decl_df$income.family.17>0,]$familyPE.own.income.ratio)
decl_df$susp6<-0
for (i in 1:nrow(decl_df))
{
if (decl_df$familyPE.own.income.ratio[i]>x)
{decl_df$susp6[i]<-1}
}
«» — .
— ( 80 ) 1 .
, ( ) , . , ( 2 ), 0,5 .
Excel,
, .
decl_df$suspicious<-decl_df$susp1+decl_df$susp2+
decl_df$susp3+decl_df$susp4+decl_df$susp5+decl_df$susp5.2+
decl_df$susp6+decl_df$hata_own+decl_df$hata_family*0.5
10 346 3971, — 0,5 1461 . — 5 ( 9,5).
: