
この作業の目的は、サイクルを最適化するための別の手法を指定することです。 同時に、既存のアーキテクチャに焦点を合わせても問題はありませんが、反対に、主に常識に頼って、できるだけ抽象的に行動しようとします。
著者は、この手法を、「
loops unrolling 」や
「loops nesting 」などの類推によって「ループをフラッキングする」と呼びました。 さらに、この用語は意味を反映しており、忙しくない。
サイクルは最適化の主要なオブジェクトであり、ほとんどのプログラムがほとんどの時間を費やすサイクルです。 十分な数の最適化手法があります。
ここでそれらに精通することができ
ます 。
最適化のための主要なリソース
- サイクルを終了するロジックの節約。 ループを終了するための基準をチェックすると、分岐が発生し、分岐が「パイプラインを壊します」ので、あまり頻繁にチェックしないようにしましょう。 結果は、 Dufのdeviceなどの素敵なコードサンプルです。
void send(int *to, int *from, int count) { int n = (count + 7) / 8; switch (count % 8) { case 0: do { *to = *from++; case 7: *to = *from++; case 6: *to = *from++; case 5: *to = *from++; case 4: *to = *from++; case 3: *to = *from++; case 2: *to = *from++; case 1: *to = *from++; } while (--n > 0); } }
現時点では、プロセッサの遷移の予測子 (存在する場合)により、このような最適化は無効になっています。
- ブラケットからループ不変量を削除する( 巻き上げ )。
- メモリのキャッシュのより効果的な作業のためのメモリを使用した作業の最適化。 サイクル内で明らかにキャッシュサイズを超えるメモリ量の呼び出しがある場合、これらの呼び出しの順序で重要になります。 明らかな場合に加えて、コンパイラーがこれに対処することは困難です;時々、効果を達成するために、別のアルゴリズムが実際に書かれています。 したがって、この最適化は、適用されるプログラマの肩にかかっています。 そして、コンパイラ/プロファイラは統計を提供し、ヒントを与えます...フィードバック。
- (明示的または暗黙的)プロセッサ並列処理を使用します。 最新のプロセッサは、コードを並行して実行できます。
明示的な並列アーキテクチャ( EPIC 、 VLIW )の場合、1つの命令に、異なる機能ブロックに影響を与える複数の命令(並列で実行される)を含めることができます。
スーパースカラープロセッサは、独立して命令のフローを解析し、並列処理を探し出し、可能な限りそれを使用します。
コマンドのスーパースカラー実行の概略図
別のオプションは、ベクトル演算SIMDです。
現在、プロセッサの並列処理を最大限に活用する方法を探しています。
何がありますか
はじめに、実験のために
Intel Core-i7 2600プロセッサーでMSVS-2013(x64)を使用したいくつかの簡単な例を見てみましょう。 ちなみに、GCCはいずれにしても、このような単純な例でも同じことを行うことができます。
最も単純なループは、整数配列の合計を計算することです。
int64_t data[100000]; … int64_t sum = 0; for (int64_t val : data) { sum += val; }
コンパイラが作成するものは次のとおりです。
lea rsi,[data] mov ebp,186A0h ;100 000 mov r14d,ebp ... xor edi,edi mov edx,edi nop dword ptr [rax+rax] ; loop_start: add rdx,qword ptr [rsi] lea rsi,[rsi+8] dec rbp jne loop_start
ダブルと同じ(AVX、
/ fp:正確 &/ fp:厳格-ANSI互換性):
vxorps xmm1,xmm1,xmm1 lea rax,[data] mov ecx,186A0h nop dword ptr [rax+rax] loop_start: vaddsd xmm1,xmm1,mmword ptr [rax] lea rax,[rax+8] dec rcx jne loop_start
このコードは、85秒で100万回実行されます。
ここでは、並列処理を識別するためのコンパイラーの作業は見られませんが、タスクでは明らかなように見えます。 コンパイラはデータの依存関係を検出し、それを回避できませんでした。
同じ、ただし(AVX、/ fp:高速-ANSI互換性なし):
vxorps ymm2,ymm0,ymm0 lea rax,[data] mov ecx,30D4h ; 12500, 1/8 vmovupd ymm3,ymm2 loop_start: vaddpd ymm1,ymm3,ymmword ptr [rax+20h] ; SIMD vaddpd ymm2,ymm2,ymmword ptr [rax] lea rax,[rax+40h] vmovupd ymm3,ymm1 dec rcx jne loop_start vaddpd ymm0,ymm1,ymm2 vhaddpd ymm2,ymm0,ymm0 vmovupd ymm0,ymm2 vextractf128 xmm4,ymm2,1 vaddpd xmm0,xmm4,xmm0 vzeroupper
26秒かかり、ベクトル演算が使用されます。
同じループですが、従来のCスタイルの場合:
for (i = 0; i < 100000; i ++) { sum += data[i]; }
(/ fp:precision)で予期せずに取得します。
vxorps xmm4,xmm4,xmm4 lea rax,[data+8h] lea rcx,[piecewise_construct+2h] vmovups xmm0,xmm4 nop word ptr [rax+rax] loop_start: vaddsd xmm0,xmm0,mmword ptr [rax-8] add rax,50h vaddsd xmm1,xmm0,mmword ptr [rax-50h] vaddsd xmm2,xmm1,mmword ptr [rax-48h] vaddsd xmm3,xmm2,mmword ptr [rax-40h] vaddsd xmm0,xmm3,mmword ptr [rax-38h] vaddsd xmm1,xmm0,mmword ptr [rax-30h] vaddsd xmm2,xmm1,mmword ptr [rax-28h] vaddsd xmm3,xmm2,mmword ptr [rax-20h] vaddsd xmm0,xmm3,mmword ptr [rax-18h] vaddsd xmm0,xmm0,mmword ptr [rax-10h] cmp rax,rcx jl loop_start
並列処理はありません。メンテナンスサイクルを節約するための試みです。 このコードは87秒間実行されます。 / fpの場合:高速コードは変更されていません。
ループのネストを使用してコンパイラーに伝えましょう。
double data[100000]; … double sum = 0, sum1 = 0, sum2 = 0; for (int ix = 0; i < 100000; i+=2) { sum1 += data[i]; sum2 += data[i+1]; } sum = sum1 + sum2;
要求したとおりの結果が得られ、コードは/ fp:fastおよび/ fp:exactオプションと同じです。 一部のプロセッサー(AMD Bulldozer)での
Vaddsd操作は、並行して実行できます。
vxorps xmm0,xmm0,xmm0 vmovups xmm1,xmm0 lea rax,[data+8h] lea rcx,[piecewise_construct+2h] nop dword ptr [rax] nop word ptr [rax+rax] loop_start: vaddsd xmm0,xmm0,mmword ptr [rax-8] vaddsd xmm1,xmm1,mmword ptr [rax] add rax,10h cmp rax,rcx jl loop_start
このコードは43秒で数百万回実行され、「単純で正確な」アプローチの2倍の速度です。
4つの要素のステップで、コードは次のようになります(コンパイラオプション/ fp:fast&/ fp:preciseでも同じです)
vxorps xmm0,xmm0,xmm0 vmovups xmm1,xmm0 vmovups xmm2,xmm0 vmovups xmm3,xmm0 lea rax,[data+8h] lea rcx,[piecewise_construct+2h] nop dword ptr [rax] loop_start: vaddsd xmm0,xmm0,mmword ptr [rax-8] vaddsd xmm1,xmm1,mmword ptr [rax] vaddsd xmm2,xmm2,mmword ptr [rax+8] vaddsd xmm3,xmm3,mmword ptr [rax+10h] add rax,20h cmp rax,rcx jl loop_start vaddsd xmm0,xmm1,xmm0 vaddsd xmm1,xmm0,xmm2 vaddsd xmm1,xmm1,xmm3
このコードは34秒で100万回実行されます。 ベクトルコンピューティングを保証するには、次のようなさまざまなトリックを使用する必要があります。
- プラグマの形式でコンパイラーにヒントを記述します。 #pragma ivdep ( #pragma loop(ivdep) 、# pragma GCC ivdep )、#pragma vector always、#pragma omp simd ...
- 組み込み 'と-使用する命令をコンパイラに指示します。たとえば、2つの配列を合計すると次のようになります 。
どういうわけか、これはすべて「高水準言語」の明るいイメージにはあまり合いません。
一方では、必要に応じて、結果を得るために、これらの最適化はまったく負担になりません。 一方、移植性の問題が発生します。 4つの加算器を備えたプロセッサ用にプログラムが作成され、デバッグされたとします。 次に、6個の加算器を備えたプロセッサバージョンで実行しようとすると、期待どおりのゲインが得られません。
また、3つのバージョンでは、4分の1ではなく2倍の速度低下が発生します。
最後に、平方の合計を計算します(/ fp:正確):
vxorps xmm2,xmm2,xmm2 lea rax,[data+8h] ; pdata = &data[1] mov ecx,2710h ; 10 000 nop dword ptr [rax+rax] loop_start: vmovsd xmm0,qword ptr [rax-8] ; xmm0 = pdata[-1] vmulsd xmm1,xmm0,xmm0 ; xmm1 = pdata[-1] ** 2 vaddsd xmm3,xmm2,xmm1 ; xmm3 = 0 + pdata[-1] ** 2 ; sum vmovsd xmm2,qword ptr [rax] ; xmm2 = pdata[0] vmulsd xmm0,xmm2,xmm2 ; xmm0 = pdata[0] ** 2 vaddsd xmm4,xmm3,xmm0 ; xmm4 = sum + pdata[0] ** 2 ; sum vmovsd xmm1,qword ptr [rax+8] ; xmm1 = pdata[1] vmulsd xmm2,xmm1,xmm1 ; xmm2 = pdata[1] ** 2 vaddsd xmm3,xmm4,xmm2 ; xmm3 = sum + pdata[1] ** 2 ; sum vmovsd xmm0,qword ptr [rax+10h] ; ... vmulsd xmm1,xmm0,xmm0 vaddsd xmm4,xmm3,xmm1 vmovsd xmm2,qword ptr [rax+18h] vmulsd xmm0,xmm2,xmm2 vaddsd xmm3,xmm4,xmm0 vmovsd xmm1,qword ptr [rax+20h] vmulsd xmm2,xmm1,xmm1 vaddsd xmm4,xmm3,xmm2 vmovsd xmm0,qword ptr [rax+28h] vmulsd xmm1,xmm0,xmm0 vaddsd xmm3,xmm4,xmm1 vmovsd xmm2,qword ptr [rax+30h] vmulsd xmm0,xmm2,xmm2 vaddsd xmm4,xmm3,xmm0 vmovsd xmm1,qword ptr [rax+38h] vmulsd xmm2,xmm1,xmm1 vaddsd xmm3,xmm4,xmm2 vmovsd xmm0,qword ptr [rax+40h] vmulsd xmm1,xmm0,xmm0 vaddsd xmm2,xmm3,xmm1 ; xmm2 = sum; lea rax,[rax+50h] dec rcx jne loop_start
コンパイラーは、サイクルのロジックを節約するためにサイクルを10個の要素に分割しますが、5つのレジスタ(合計1つと乗算の2つの並列分岐ごとのペア)がかかります。
または/ fpの場合:fast:
vxorps ymm4,ymm0,ymm0 lea rax,[data] mov ecx,30D4h ;12500 1/8 loop_start: vmovupd ymm0,ymmword ptr [rax] lea rax,[rax+40h] vmulpd ymm2,ymm0,ymm0 ; SIMD vmovupd ymm0,ymmword ptr [rax-20h] vaddpd ymm4,ymm2,ymm4 vmulpd ymm2,ymm0,ymm0 vaddpd ymm3,ymm2,ymm5 vmovupd ymm5,ymm3 dec rcx jne loop_start vaddpd ymm0,ymm3,ymm4 vhaddpd ymm2,ymm0,ymm0 vmovupd ymm0,ymm2 vextractf128 xmm4,ymm2,1 vaddpd xmm0,xmm4,xmm0 vzeroupper
要約表:
| MSVC、/ fp:厳密、/ fp:正確、秒 | MSVC、/ fp:高速、秒 |
| foreach | 85 | 26 |
| Cスタイルのループ | 87 | 26 |
| CスタイルのネストX2 | 43 | 43 |
| CスタイルのネストX4 | 34 | 34 |
これらの数字を説明するには?
プロセッサの開発者だけが何が起こっているかの本当の状況を知っており、推測しかできないことに注意する価値があります。
加速はいくつかの独立した加算器によるものであるという最初の考えは明らかに誤りです。 i7-2600プロセッサには、独立したスカラー演算を実行できないベクトル加算器が1つあります。
プロセッサのクロック速度は最大3.8 GHzです。 85秒の単純なサイクル(100万回、100,000回の追加)で、反復あたり3クロックサイクルが得られます。 これは、vaddpdベクトル命令の実行の3クロックサイクルのデータ(
1、2 )とよく一致しています(スカラーを追加した場合でも)。 データに依存しているため、3クロックサイクルより速く反復を完了することはできません。
ネスト(X2)の場合、反復内のデータに依存せず、サイクルの違いで加算器パイプラインをロードできます。 しかし、次のイテレーションでは、データの依存関係もサイクルの違いで現れます。その結果、加速が2倍になります。
ネスティング(X4)の場合、加算コンベヤーもビート単位でロードされますが、(コンベヤーの長さによる)3倍の加速は発生せず、追加の要因が介在します。 たとえば、ループの反復がキャッシュライン
L0mに収まりなくなり、空きクロックサイクル(s)を受け取ります。
だから:- コンパイルモデル/ fpを使用する場合:最も単純なソースコードは、コードの最速バージョンを提供します。 私たちは高級言語を扱っています。
- ネストスタイルの手動最適化は、/ fp:正確なモデルに良い結果をもたらしますが、/ fp:fastを使用する場合にのみコンパイラに干渉します
- 手動の最適化は、ベクトル化されたコードよりも移植性があります
コンパイラについて少し
レジスタアーキテクチャは、高レベル言語のポータブルテキストから受け入れ可能なコードを取得するためのシンプルで普遍的な方法を提供します。 コンパイルは条件付きでいくつかのステップに分割できます。
- 解析 この段階で、構文的に制御された変換が実行され、静的チェックが実行されます。 出力には、解析ツリー( DAG )があります。
- 中間コード生成。 オプションで、中間コード生成を解析と組み合わせることができます。
また、 3アドレス命令を中間コードとして使用する場合、「 3アドレスコードは構文ツリーまたはDAGの線形化された表現であり、明示的な名前はグラフの内部ノードに対応する 」ため、この手順は簡単になります 。
本質的に、3アドレスコードは、無限の数のレジスタを持つ仮想プロセッサ用です。
- コード生成。 このステップの結果は、ターゲットアーキテクチャ用のプログラムです。 レジスタの実際の数は限られているため、この段階で、各一時レジスタにどの一時変数を含めるかを決定し、特定のレジスタに分散する必要があります。 純粋な形式であっても、このタスクはNP完全であり、さらに、レジスタの使用には通常さまざまな制限があるため、問題は複雑です。 ただし、この問題を解決するために、許容可能なヒューリスティックが開発されました。 さらに、3アドレス(または同等の)コードは、データストリームの分析、最適化、不要なコードの削除などの正式な装置を提供します。
問題が迫っています:
- レジスタ割り当てのNP完全問題を解決するために、ヒューリスティックが使用され、これにより許容可能な品質のコードが得られます。 これらのヒューリスティックは、メモリまたはレジスタの使用に関する追加の制限を好みません。 たとえば、インターレースメモリ、命令でのレジスタの暗黙的な使用、ベクトル演算、レジスタリング...ヒューリスティックが動作を停止し、最適に近いコードの構築を停止できる程度には、普遍的な方法で解決できる問題はなくなります。
その結果、(ベクトル?)プロセッサ機能は、コンパイラがトレーニングされたセットから典型的な状況を認識した場合にのみ使用できます。
- スケーリングの問題。 レジスタの割り当ては静的に行われます。同じシステムの命令を使用してプロセッサ上でコンパイルされたコードを実行しようとすると、多数のレジスタを使用してもゲインは得られません。
これは、レジスタウィンドウのスタックを備えたSPARCにも当てはまります。レジスタウィンドウの数が多いほど、呼び出しフレームの数が多くなり、メモリアクセスの頻度が減るという事実になります。
EPIC-スケーリングの方向で試みが行われました-「複数の命令の各グループはバンドルと呼ばれます。 各バンドルには、次のグループがこの結果に依存することを示すストップビットがあります。 このビットを使用すると、複数のバンドルを並行して実行できる機能を備えた次世代のアーキテクチャを作成できます。 依存関係情報はコンパイラーによって計算されるため、機器はオペランドの独立性の追加検証を実行する必要はありません。」独立したバンドルを並列で実行でき、システム内の実行デバイスが多いほど、プログラムの内部並列性が広くなると想定されていました。 一方で、これらの機能は常に勝つとは限りません。いずれにせよ、配列の合計については、著者にとっては役に立たないようです。
スーパースカラープロセッサは、「私たちのための登録」と「私たち自身の登録」を導入することで問題を解決します。 コンパイラーは、レジスターをペイント(割り振り)するときの最初のコンパイラーの数によってガイドされます。 2番目の数は任意で、通常は最初の数よりも数倍多くなります。 デコード中、スーパースカラープロセッサは、プログラム本体のウィンドウ内の実際の番号に基づいてレジスタを再登録します。 ウィンドウサイズは、プロセッサが処理できるロジックの複雑さによって決まります。 もちろん、レジスタの数に加えて、機能デバイスもスケーリングの対象となります。
- 互換性の問題。 特にX84-64とテクノロジーラインに注目してください-SSE-SSE2-SSE3-SSSE3-SSE4-AVX-AVX2-AVX512-...
トップダウン互換性(つまり、コードは古いテクノロジー用にコンパイルされていますが、より若いプロセッサーで実行したい場合)は、1つの方法で実現できます-言及された各テクノロジー用のコードを生成し、実行時に適切な実行ブランチを選択することにより それはあまり魅力的ではありません。
ボトムアップ互換性は、プロセッサによって提供されます。 この互換性はコードの実行を保証しますが、効果的な実行を約束するものではありません。 たとえば、2つの独立した加算器を備えたテクノロジ用にコードがコンパイルされ、4つのプロセッサで実行された場合、実際に使用されるのはそのうちの2つだけです。 さまざまなテクノロジー用にコードのいくつかのブランチを生成しても、計画されているかどうかにかかわらず、将来のテクノロジーの問題は解決されません。
サイクルを見る
同じ問題を考慮して、配列を合計します。 この合計が単一の式の計算であると想像してください。 バイナリ加算を使用するため、式はバイナリツリーとして表すことができ、合計の結合性により、このようなツリーが多数あります。
計算は、ツリーを左から右に深くトラバースするときに行われます。 通常の合計は、左に伸びるリスト縮退ツリーのように見えます。
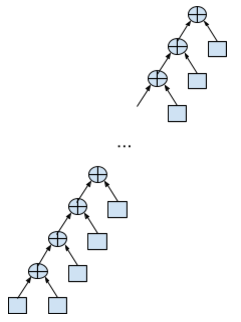
double data[N]; … double sum = 0; for (int i = 0; i < N; i++) { sum += data[i]; }
最大スタックの深さ(深さは、後置加算、つまりスタックを意味します)。ここでは2つの要素が必要になる場合があります。 並列性は想定されていません。各合計(最初の合計を除く)は、前の合計の結果を待つ必要があります。 データ依存性は明らかです。
しかし、3つのレジスタ(合計とスタックの最上位をエミュレートするための2つのレジスタ)で任意のサイズの配列を合計できます。
2ストリームサイクルのネストは次のようになります。
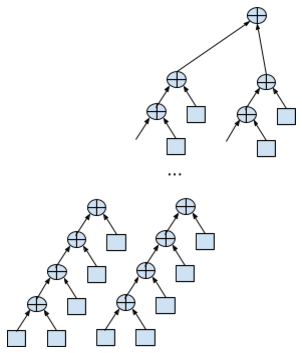
double data[N]; … double sum = 0; double sum1 = 0, sum2 = 0; for (int i = 0; i < N/2; i+=2) { sum1 += data[i]; sum2 += data[i + 1]; } sum = sum1 + sum2;
計算には、2倍のリソース、すべてに5つのレジスタが必要ですが、合計の一部を並行して実行できるようになりました。
計算の観点から最も恐ろしいオプションは、リストに縮退した右成長ツリーです。その計算には、並列性がない場合に配列のサイズのスタックが必要です。
どのツリーオプションが最大の同時実行性を提供しますか? 明らかに、ソースデータへのアクセスがノードを要約するリーフでのみ行われる、バランスの取れた(可能な範囲で)ツリー。
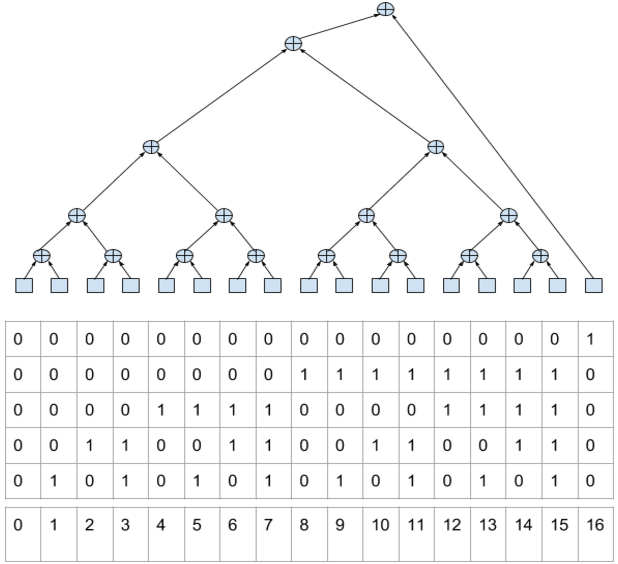
この擬似コードでは、次の関数が使用されます。
- push (val)-値をスタックの一番上に置き、スタックを増やします。 スタックはレジスタープールで編成されると想定されます。
- popadd ()-スタックの一番上にある2つの要素を合計し、結果を上から2番目に配置して、一番上の要素を削除します。
- bit_count (val)-整数値のビット数をカウントします
この擬似コードの操作後、スタックに残っている要素は目的の量に等しくなります。
どのように機能しますか? バイナリ表現の要素番号は、式ツリーの最上部から最上位ビットから最下位ビットまでのパスをエンコードすることに注意してください。 この場合、0は左への移動、1は右への移動を示します(
ハフマンコードに似
ています )。
連続して実行されるコックされた下位ビットの数は、現在の要素を処理するために実行する必要がある合計数に等しいことに注意してください。 そして、ある数のコックされたビットの総数は、これらの要素を操作する前のスタック上の要素の数を意味します。
次のことに注意してください。
- スタックサイズ、つまり それに必要なレジスタの数は、データサイズのlog2です。 一方では、これはあまり便利ではありません。 データのサイズを計算できます。コンパイル中にスタックのサイズを決定したいと思います。 一方、コンパイラがデータをタイルに分割することを妨げるものは誰もいません。タイルのサイズは、使用可能なレジスタの数に基づいて決定されます。
- このような問題の解釈では、利用可能な独立した加算器をいくつでも自動的に使用するには、並列処理で十分です。 配列からの要素のロードは、独立して並行して実行できます。 1つのレベルの合計も並行して実行されます。
- 並行性に問題があります。 コンパイル時にN個の加算器があったとします。 Nとは異なる数(すべてが考案されたため)で効果的に作業するには、ハードウェアサポートを使用する必要があります。
- 明示的な並行性を持つアーキテクチャの場合、すべてが簡単ではありません。 加算器のプールと、いくつかの独立した「ワイド」命令を並行して実行する許可が役立ちます。 要約すると、特定の加算器ではなく、キューの最初の加算器が取得されます。 広範な命令が3つの加算を実行しようとすると、3つの加算器がプールから回収されます。 そのような量の無料加算器がない場合、命令は解放されるまでブロックされます。
- スーパースカラーアーキテクチャでは、スタックの状態を追跡する必要があります。 スタックには単項演算(例:符号反転)と二項演算(例:popadd)があります。 依存関係のないリーフ操作(例:プッシュ)。 後者は最も簡単な方法であり、いつでも実行できます。 ただし、操作に引数がある場合、実行前に引数の準備ができるまで待機する必要があります。
そのため、popadd操作の両方の値がスタックの先頭にある必要があります。 しかし、ターンがそれらを要約する時までに、それらはすでにスタックのトップにいないかもしれません。 それらは物理的に配置され、連続していないことがあります。
出力は、実行命令が発行された時点でのスタックプールからの対応するレジスタの配置(割り当て)であり、結果の準備ができて配置する必要がある時点ではありません。
push(data[i]) , . . .
popadd , , . , popadd , .
.
. / . .
- ANSI - double' . /fp:fast, . , ( ) , .
- スタックのハードウェアサポートなしで、既存のアーキテクチャに説明されたスキームを実装することは可能ですか?はい、固定配列サイズの場合。コンパイラーは、たとえば64要素のサイズのタイルへのサイクルを認識し、スタックされたマシンをレジスターに明示的にペイントします。同時に、ループを終了するには、残りの次数2が64未満のコードが必要です。かなり面倒ですが、動作します。
lea rax,[data] vxorps xmm6,xmm6,xmm6 ; 0 vaddsd xmm0,xmm6,mmword ptr [rax] ; 0 vaddsd xmm1,xmm0,mmword ptr [rax+8] ; 1 vaddsd xmm0,xmm6,mmword ptr [rax+10h] ; 1 0 vaddsd xmm2,xmm0,mmword ptr [rax+18h] ; 1 2 vaddsd xmm0,xmm1,xmm2 ; 0 vaddsd xmm1,xmm6,mmword ptr [rax+20h] ; 0 1 vaddsd xmm2,xmm1,mmword ptr [rax+28h] ; 0 2 vaddsd xmm1,xmm6,mmword ptr [rax+30h] ; 0 2 1 vaddsd xmm3,xmm1,mmword ptr [rax+38h] ; 0 2 3 vaddsd xmm1,xmm2,xmm3 ; 0 1 vaddsd xmm0,xmm0,xmm1 ; 0 vaddsd xmm1,xmm6,mmword ptr [rax+40h] ; 0 1 vaddsd xmm2,xmm1,mmword ptr [rax+48] ; 0 2 vaddsd xmm1,xmm6,mmword ptr [rax+50h] ; 0 2 1 vaddsd xmm3,xmm1,mmword ptr [rax+58h] ; 0 2 3 vaddsd xmm1,xmm2,xmm3 ; 0 1 vaddsd xmm2,xmm6,mmword ptr [rax+60h] ; 0 1 2 vaddsd xmm3,xmm2,mmword ptr [rax+68h] ; 0 1 3 vaddsd xmm2,xmm6,mmword ptr [rax+70h] ; 0 1 3 2 vaddsd xmm4,xmm2,mmword ptr [rax+78h] ; 0 1 3 4 vaddsd xmm2,xmm4,xmm3 ; 0 1 2 vaddsd xmm3,xmm1,xmm2 ; 0 3 vaddsd xmm1,xmm0,xmm3 ; 1
これは、16要素のピラミッドのコードのように見える場合があります。
次は?
配列の合計を見つけることに注目しました-非常に簡単なタスクです。もっと複雑なものを見てみましょう。最後の例は非常に参考になります。最適化するために、再帰は通常反復に変換されます。その結果、典型的なテキスト(メインループ)は次のようになります。 nn = N >> 1; ie = N; for (n=1; n<=LogN; n++) { rw = Rcoef[LogN - n]; iw = Icoef[LogN - n]; if(Ft_Flag == FT_INVERSE) iw = -iw; in = ie >> 1; ru = 1.0; iu = 0.0; for (j=0; j<in; j++) { for (i=j; i<N; i+=ie) { io = i + in; rtp = Rdat[i] + Rdat[io]; itp = Idat[i] + Idat[io]; rtq = Rdat[i] - Rdat[io]; itq = Idat[i] - Idat[io]; Rdat[io] = rtq * ru - itq * iu; Idat[io] = itq * ru + rtq * iu; Rdat[i] = rtp; Idat[i] = itp; } sr = ru; ru = ru * rw - iu * iw; iu = iu * rw + sr * iw; } ie >>= 1; }
この場合、何ができますか?説明されているサイクルの最適化の精神では、おそらく何もありません。ここで説明したハードウェアスタックが役に立つかどうかは、興味深い質問です。ただし、これはまったく別の話です。PS:SIMDに関する相談のみならず、Tasit Murki(Felid)に感謝します。PPS:キングクリムゾンの映像から撮影したタイトルのイラスト-フラクチャー-Live in Boston 1974。