そのため、アプリケーションに使用するのに最適なテクノロジーについて通知する「標準」ベンチマークはありません。 要件、データ、インフラストラクチャのみが、知っておくべきことを教えてくれます。
まず、少し哲学。 NoSqlは周囲を囲んでおり、これから逃れることはできません(私は本当にやりたくありませんでした)。 このテキストの範囲を超えて根本的な原因に関する質問を残します。この傾向は、新しいNoSqlソリューションの出現と古いソリューションの開発に反映されているだけであることに注意してください。 もう1つの側面は、正反対の混合、つまり、従来のリレーショナルデータベースでのスキーマレスデータの保存のサポートです。 リレーショナルデータストレージモデルとその他すべての接合部にあるこの灰色の領域には、目を見張るほどの可能性があります。 しかし、いつものように、データに適したバランスを見つけることができる必要があります。 これは、たとえば、NoSqlソリューションのパフォーマンスと従来のデータベースのパフォーマンスなど、ほとんど比較できるものを比較する必要があるという事実のために、難しい場合があります。 この短いメモでは、そのような試みを提案し、PostgreSQLのjsonbとMysqlのjsonおよびMongodbのbsonとのパフォーマンスの比較を示します。
一体何が起こっているの?
フィールドからの簡単なメッセージ:
他にもいくつかの例がありますが、それらについては次に説明します。 素晴らしいことは、これらのデータ型はバイナリではなく、バイナリjsonストレージを想定しているため、作業がはるかに高速になることです。 基本的な機能はどこでも同じです。 これらは明らかな要件です-作成、選択、更新、削除。 この状況の人の最も古く、ほとんど穴居人の欲求は、一連のベンチマークを保持することです。 PostgreSQLとMysqlが選択された理由 jsonサポートの実装は両方のケースで非常に似ており(同じウェイトカテゴリに属している以外)、Mongodbは世界の古いNoSqlのようなものです。
EnterpriseDBによって実行される作業は、この点で少し時代遅れですが、それは千里の道の最初の一歩として取ることができます。 現時点では、この道路の目標は、人為的な状況で誰がより速く/遅くなるかを示すことではなく、中立的な評価を行い、フィードバックを得ることです。
ソースデータと詳細
EnterpriseDBの
pg_nosql_benchmarkは、かなり明白なパスを示唆しています-最初に、わずかな変動を伴うさまざまなタイプの所定量のデータが生成され、それが調査中のデータベースに書き込まれ、そこからサンプルが
取得されます。
Mysqlを操作するための機能はありません。そのため、PostgreSQLでも同じ方法で実装する必要がありました。 この段階では、インデックスについて考えるときの微妙な点は1つだけです。事実、Mysqlは実装されていません
jsonに直接
インデックスを作成するため、仮想列を作成して既にインデックスを作成する必要があります。 さらに、mongodbの場合、生成されたデータの一部のサイズが4096バイトを超えており、mongoシェルバッファーに
収まらない 、つまり ただ捨てた。 ハッキングとして、jsファイルからinsert'yを実行することが判明しました(2 GBを超えることはできないため、複数のchunk'ovに分割する必要があります)。 さらに、シェルの起動、認証などに関連するコストを回避するために、適切な数の「no-op」リクエストが行われ、その時間は除外されます(実際には非常に短いですが)。
すべての変更を受信すると、次の場合のチェックが実行されました。
- PostgreSQL 9.5 beta1、gin
- PostgreSQL 9.5 beta1、jsonb_path_ops
- PostgreSQL 9.5 beta1、jsquery
- MySQL 5.7.9
- Mongodb 3.2.0ストレージエンジンWiredTiger
- Mongodb 3.2.0ストレージエンジンMMAPv1
それらはそれぞれ、デフォルト設定でボード上に
ubuntu 14.04 x64を備えた個別の
m4.xlargeインスタンスにデプロイされ、1,000,000に等しいエントリ数でテストが実行されました。
postgresql-server-dev-9.5もです。 結果はjsonファイルに保存され、matplotlibを使用して視覚化できます(
こちらを参照)。
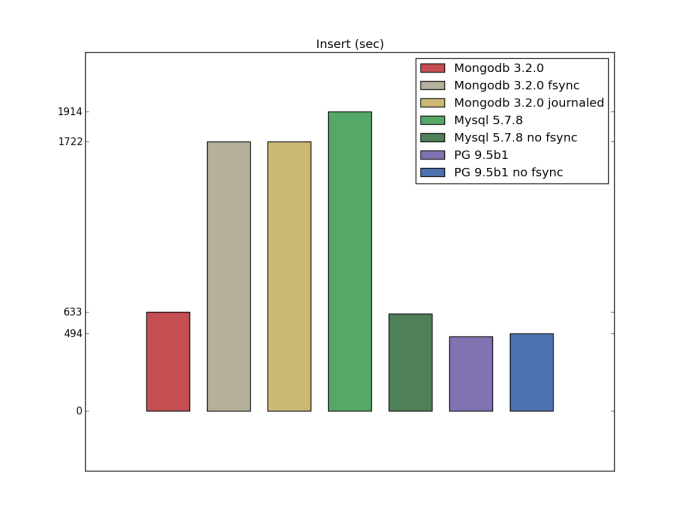
さらに、耐久性に関連する設定について疑問がありました。 そのため、次のケースに対していくつかの追加テストを実施しました(私の意見では、誰かがこれらの設定をライブで使用する可能性は低いため、一部は理論である可能性が高い)。
- Mongodb 3.2.0のジャーナル(writeConcern j:true)
- Mongodb 3.2.0 fsync(transaction_sync =(enabled = true、method = fsync))
- PostgreSQL 9.5ベータ1、fsyncなし(fsync = off)
- MySQL 5.7.9、fsyncなし(innodb_flush_method = nosync)
写真
クエリの実行時間に関連するすべてのグラフは、サイズ(メガバイト単位)に関連して秒単位で表示されます。 したがって、どちらの場合も、値が小さいほど生産性が向上します。
選択してください

挿入
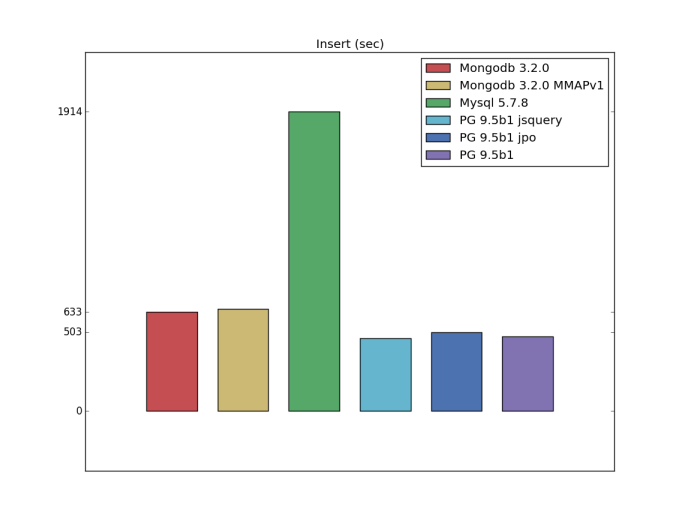
挿入(カスタム構成)
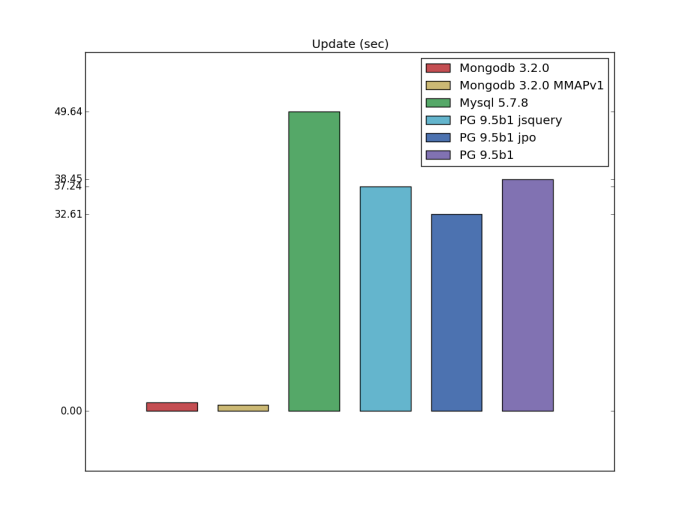
更新する
元の
pg_nosql_benchmarkコードに対する別の変更は、更新テストの追加です。 Mongodbがここでの明確なリーダーであることが判明しました。これは、PostgreSQLとMysqlで、現時点で1つの値を更新することで、フィールド全体を上書きすることを意味する可能性が高いためです。
更新(カスタム構成)
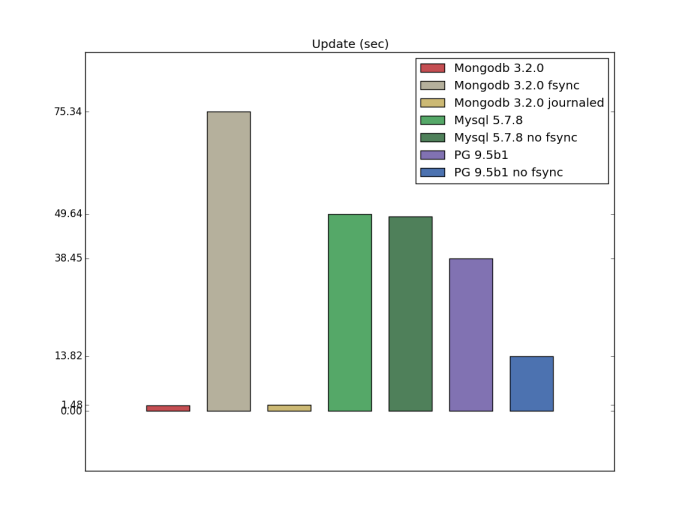
この
回答のドキュメントとピークから推測できるように、
writeConcern j:trueは単一のmongodbサーバーの可能な限り最高の耐久性レベルであり、明らかにfsync構成と同等である必要があります。 耐久性はチェックしませんでしたが、fsyncを使用したmongodbの更新操作の方がはるかに遅いことがわかりました。
テーブル/インデックスサイズ
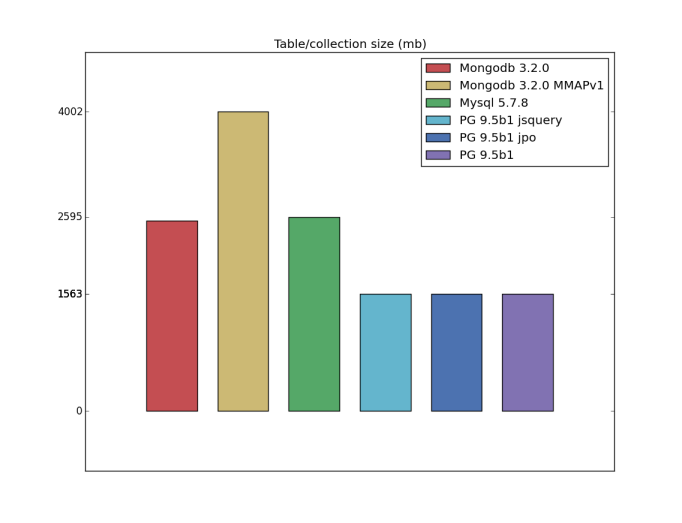
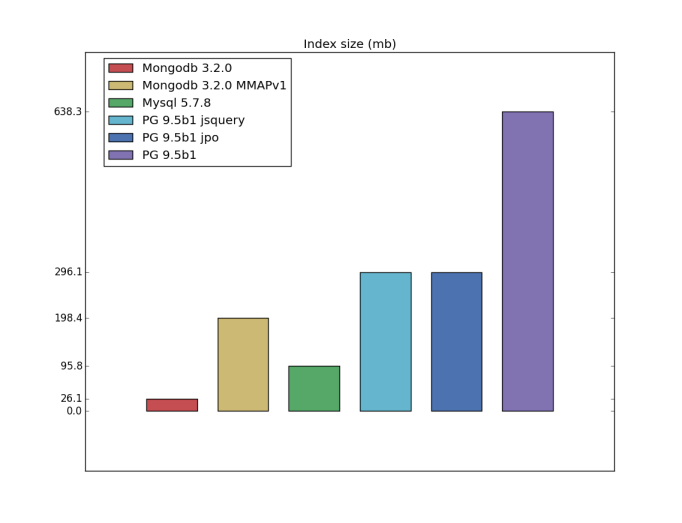
私はこれについて気持ちが悪い
パフォーマンスの測定は、特にこの場合、滑りやすいです。 上記のすべてを完全かつ完全なベンチマークと見なすことはできません。これは現在の状況を理解するための最初のステップにすぎません-思考の糧のようなものです。 現在、
ycsbを使用してテストを行っています。また、運が良ければ、クラスター構成のパフォーマンスを比較します。 さらに、建設的な提案、アイデア、修正があれば嬉しいです(何か見落としていたかもしれないので)。