Elasticsearchに基づいたプロジェクトでのSQL JOIN操作の出現を不当に無視しました

Crate.ioとElasticsearchの主な違いは、ESでのクエリおよびデータ変更言語としてのSQLのサポート、およびAPIとクラスター内の
バイナリデータを分散方式で分散する機能です。
Habréに投稿された出版物
「crate.ioとkibanaを使用して愛や冒険を見つける方法」で、私は長い間BLOB APIの使用例について語っていました。 Elasticsearchを使用すると、ドキュメントをjsonクラスターに保存し、インデックスを作成して検索することができます。 Crateは、SQLを使用してデータを操作する機能でESを補完します。 この記事では、クレートのインストール、およびjdbcドライバーを介した要求の実行に集中します。
crate.ioをインストールします
Mavenリポジトリーからソフトウェアをインストールする方法を提供します。これは、クレートだけでなく、Javaおよびgroovyプロジェクトで役立ちます。 この記事では、グルーブスクリプトを使用してJOINを試すために、データベースサーバーをインストール、構成、および起動します。
java -jar groovy-grape-aether-2.4.5.1.jar crate-io.groovy
スクリプトを実行するには、
特別なgroovy-all:
groovy-grape-aether-2.4.5.1.jarと
crate-io.groovyスクリプト
自体が必要です。
@Grab(group='org.codehaus.plexus', module='plexus-archiver', version='2.10.2') import org.codehaus.plexus.archiver.tar.TarGZipUnArchiver import com.github.igorsuhorukov.smreed.dropship.MavenClassLoader; @Grab(group='org.codehaus.plexus', module='plexus-container-default', version='1.6') import org.codehaus.plexus.logging.console.ConsoleLogger; def artifact = 'crate' def version = '0.54.1' def userHome= System.getProperty('user.home') def destDir = new File("$userHome/.crate-io") def crateIoDir= new File(destDir, "$artifact-$version"); if(!crateIoDir.exists()){ destDir.mkdirs() String sourceFile = MavenClassLoader.using("https://dl.bintray.com/crate/crate/").getArtifactUrlsCollection("io.crate:$artifact:tar.gz:$version", null).get(0).getFile() final TarGZipUnArchiver unArchiver = new TarGZipUnArchiver() unArchiver.setSourceFile(new File(sourceFile)) unArchiver.enableLogging(new ConsoleLogger(ConsoleLogger.LEVEL_DEBUG,"Logger")) unArchiver.setDestDirectory(destDir) unArchiver.extract() def crateCfg = new File("$crateIoDir.absolutePath/config/crate.yml") crateCfgText = crateCfg.text crateCfg.withWriter { w -> w << crateCfgText.replace('# es.api.enabled: false', 'es.api.enabled: true') } } def proc = "$crateIoDir.absolutePath/bin/crate".execute() proc.consumeProcessOutput(System.out, System.err) proc.waitFor()
このスクリプトは、ユーザーのホームディレクトリに.crate-ioディレクトリを作成し、ディレクトリ内に必要なバージョンのcrate.ioデータベースが既に存在するかどうかを確認します。 Mavenから互換性のあるクレートプロジェクトリポジトリがない場合、tar.gz形式のアセンブリがダウンロードされ、解凍されます。 同時に、config / crate.yml設定でElasticsearch APIが有効になります。 インストールが成功した場合、またはcrate.ioが以前にインストールされていた場合、スクリプトはサーバーを起動します。

起動後、ブラウザでサーバーのWebインターフェースに接続できます
http:// localhost:4200 / admin
Crate.io jdbc
prestoライブラリとcrate.ioプロジェクトの開発者のおかげで、シェアードナッシングアーキテクチャを備えたelasticsearchに基づいてデータベースで
SQLクエリを実行することが可能になりました。 プログラムから、Java、Python、PHP、Erlang、REST APIの
クライアントライブラリを使用してリクエストを実行できます。
jdbcドライバーに興味があります。 また、ドライバーをダウンロードする時点で、恐怖は23.4MB
Crate JDBCスタンドアロンjarから発生し、その中には何らかの理由で、そのAPIおよびトランスポート実装のクライアント部分だけでなく、elasticsearchサーバー全体がパックされています。 さて、私はトラフィックを気にしませんが、なぜすべてを詰め込むのがそんなに容赦ないのですか!? Mavenプロキシリポジトリがある場合、このドライバーは作業ネットワークから1回だけダウンロードされます。
プロジェクトリポジトリからの Crate JDBCスタンドアロンのMaven依存関係:
<dependency> <groupId>io.crate</groupId> <artifactId>crate-jdbc-standalone</artifactId> <version>1.9.3</version> <dependency>
データベースへの接続を作成するには
、指示に従ってすべて
を行いました 。 しかし、同じことをプログラムで行うことも、jdbcドライバーをサポートする別のエディターから行うこともできます。
構成されたドライバー:

接続を作成して確認しました:

2つのテーブルを作成しました:
create table maintable( id integer primary key, name string ); create table secondarytable ( reference integer, options string );

テーブルに挿入されたレコード:
insert into maintable(id,name) values(1,'record1'); insert into maintable(id,name) values(2, 'record2'); insert into secondarytable(reference,options) values(1,'option1'); insert into secondarytable(reference,options) values(2,'option2'); insert into secondarytable(reference,options) values(2,'option3'); insert into secondarytable(reference,options) values(null,'other option');

内部参加:
select id, name, options from maintable, secondarytable where id=reference
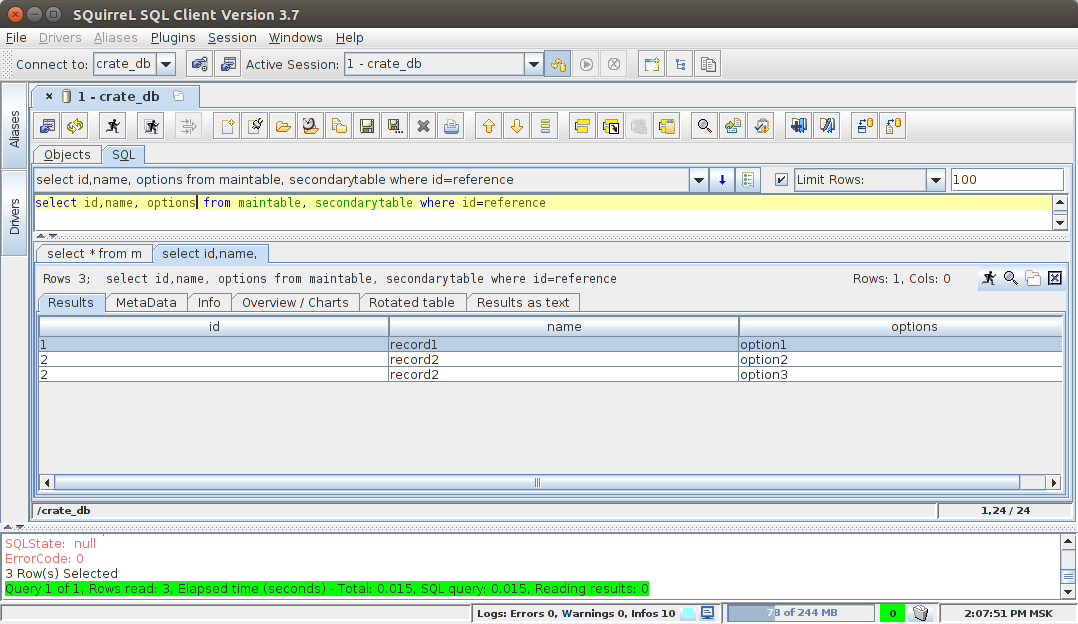
クロスジョイン:
select id,name, options from maintable, secondarytable

残念ながら、これまでのところcrate.ioでできるのは
内部結合とクロス結合だけです。 しかし、ベースは開発中であるため、外部結合の実装と既存の
機能のさらなる改善を待ってい
ます 。
おわりに
Crate.io -NoSQL Elasticsearchソリューション用のSQLアドオン。最近のバージョンでは、内部結合および相互結合が可能です。 クレートを使用するには、jdbcドライバーと
Kibanaを使用して、いくつかの制限付きでデータを視覚化できます。 クレートは、クラスタープロセスファイルシステムにバイナリデータを分散方式で保存することもできます。
groovyスクリプトを使用して、必要なバージョンをmavenリポジトリからインストールし、インストール中に構成を更新してサーバーを起動できます。
すべてのソリューションと同様に、crate.ioには独自の長所があります。
- 水平スケーリングの可能性(非共有アーキテクチャ)
- クエリおよびデータ操作言語としてのSQL、クエリでの制限付きJOINサポート
- ファイルシステム内のバイナリデータの分散ストレージとクラスター内のバイナリデータへのアクセス
- Elasticsearch API、Kibana、および既存のESツールを使用する機能(制限はありますが)
弱点と同様に:
- オブジェクトリレーショナル機能データベースへの変換
- ACIDのうち、 Elasticsearchは耐久性のみをサポートします