みなさんこんにちは!
多くの人が
Google DeepMindについて聞いたことがあると思います。 人間よりもアタリゲームを上手にプレイするためのプログラムの教え方について 本日は、同様のことを行う方法に関する記事を紹介したいと思います。 この記事は、強化学習の特殊なケースである
Qラーニングアプリケーションの
例のアイデアとコードのレビューです。 この例は
、Google従業員DeepMindの記事に基づいてい
ます 。
ゲーム
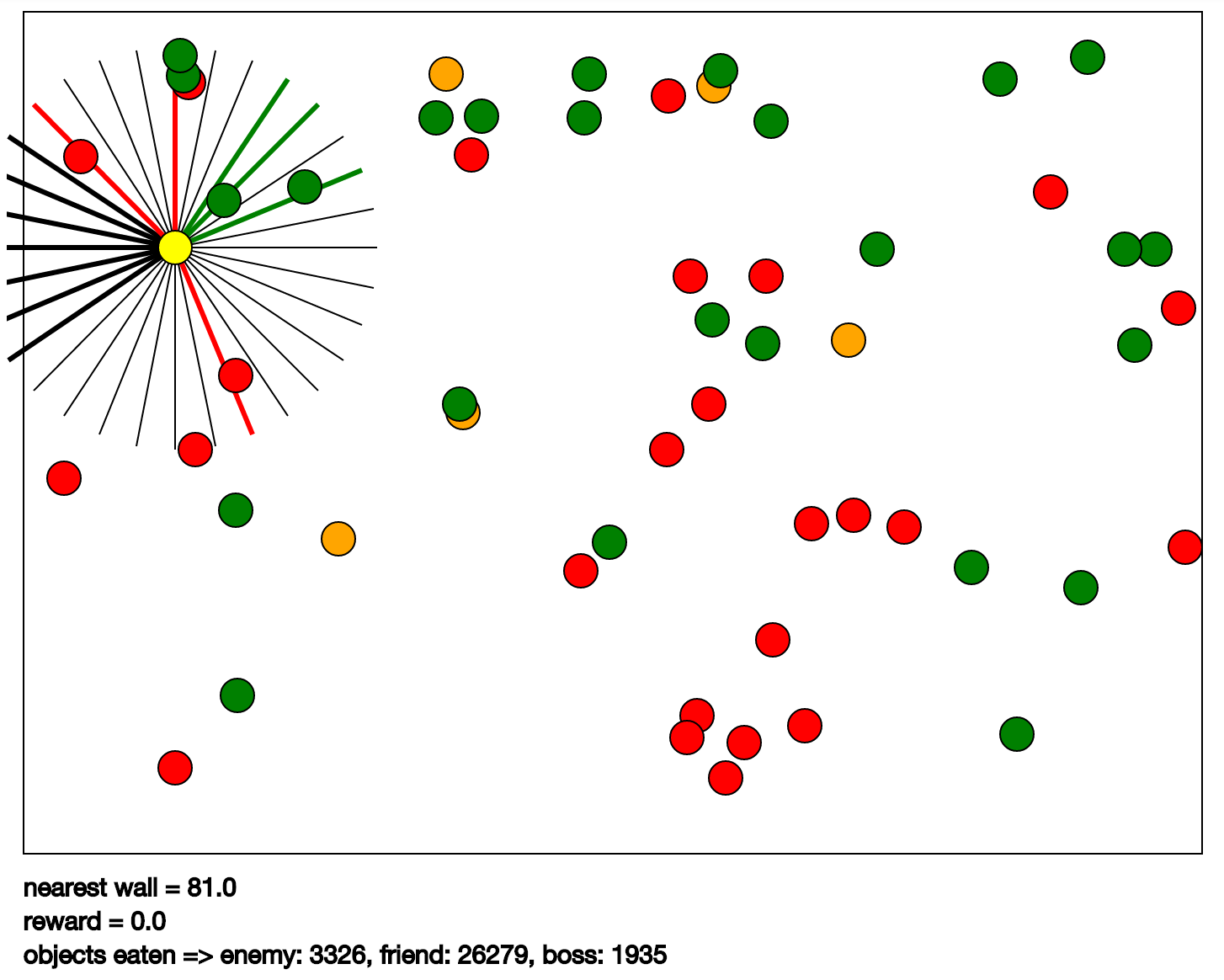
この例では、ゲームKarpathyゲームを使用します。 彼女はCPDVに描かれています。 その本質は次のとおりです。緑のボールを「食べ」、赤やオレンジを食べないように黄色のボールを制御する必要があります。 オレンジの場合、赤よりも大きなペナルティが与えられます。 黄色のボールには、視覚に関与する放射状に広がるセグメントがあります(プログラムでは、目と呼ばれます)。 そのようなセグメントの助けを借りて、プログラムは、セグメントの方向に最も近いオブジェクトのタイプ、その速度と距離を感知します。 オブジェクトのタイプは、ボールまたは壁の色です。 入力データのセットは、次のように取得されます。各目からのデータと独自の速度。 出力は黄色のボール制御コマンドです。 実際、これらは上、左、下、右の4つの方向の加速度です。
アイデア
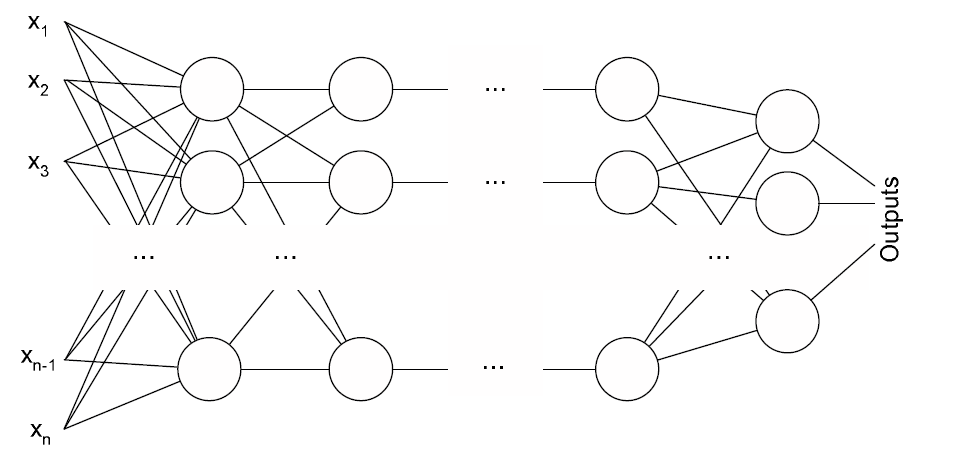 多層パーセプトロン
多層パーセプトロンがこのゲームをプレイします。 入力で、彼は上記の入力データを持っています。 出力は、可能なアクションのそれぞれの有用性です。 パーセプトロンは、逆伝播法によって訓練されます。 具体的には、RMSPropメソッドが使用されます。 その特徴は、最適化のためにすぐに多数の例を使用することですが、これが唯一の機能ではありません。 この方法の詳細については、
これらのスライドをご覧ください。 彼らはRMSPropだけではありません。 私はまだ良いものを見つけていません。 ニューラルネットワークの出力誤差は、同じ
Q学習を使用して計算されます。
テンソルフロー
最近リリースされた
TensorFlowライブラリのおかげで、アルゴリズムの独自の実装を書くことなく、これらのほとんどすべてを多少簡単にコーディングできます。 このライブラリを使用したプログラミングは、結果を得るために必要な計算のグラフを記述することになります。 次に、このグラフはTensorFlowセッションに送信され、そこで計算自体が実行されます。 RMSPropは完全にTensorFlowから取得されます。 ニューラルネットワークはそこから行列に実装されます。 Q学習は、従来のTensorFlow操作にも実装されています。
コード
次に、サンプルコードの最も興味深い場所を見てみましょう。
models.py-多層パーセプトロンimport math import tensorflow as tf from .utils import base_name
distinct_deepq.py-Qラーニングの実装 import numpy as np import random import tensorflow as tf from collections import deque class DiscreteDeepQ(object):
karpathy_game.py-ニューラルネットワークでプレイされるゲーム import math import matplotlib.pyplot as plt import numpy as np import random import time from collections import defaultdict from euclid import Circle, Point2, Vector2, LineSegment2 import tf_rl.utils.svg as svg
すべての動作を確認するには、
IPython Notebookが必要です。 これらはすべて、彼のために台本にまとめられるので。 スクリプトは、notebooks / karpathy_game.ipynbにあります。
結果
記事を書いている間に、私は数時間トレーニングを始めました。 以下にビデオを示します。最終的に、私はかなり短時間でグリッドを学習しました。
次に行く場所
さらに、このメソッドを
仮想quadrocopterに実装しようとする予定
です 。 まず、安定化を試みたいです。 それから、もし成功したら、それを飛ばそうとしますが、おそらく多層パーセプトロンの代わりに畳み込みネットワークが必要になるでしょう。
この例は、ユーザー
nivwusquorumによって
GitHubに慎重にレイアウトされています。これについては、彼に多大な感謝を表したいと思います。