
こんにちは、Habr!
Wrikeは 、数十万人のユーザーからの毎日のデータフローに直面しています。 これらの情報はすべて保存、処理、およびそこから価値を抽出する必要があります。
Apache Sparkは、この膨大な量のデータに対処するのに役立ちます。
Sparkの紹介や、そのプラス面とマイナス面については説明しません。 あなたはそれについて
ここ 、
ここ、または
公式文書で読むことができ
ます 。 この記事では、
Spark SQLライブラリと、ビッグデータを分析するための実用的なアプリケーションに焦点を当てます。
SQL? 私には思えなかった?
従来、ほとんどすべてのIT企業の分析部門は、ビジネスとSQLの複雑さに精通した専門家に基づいて構築されていました。 BIまたは分析部門の仕事は、
ETLなしではほとんどありません。 次に、ほとんどの場合、SQLを使用して最も簡単にアクセスできるデータソースを使用します。
Wrikeも例外ではありません。 長い間、サーバーのログに基づいてユーザーの行動を分析するタスクに直面するまで、データの主なソースはETLおよび
Google Analyticsと組み合わせたデータベースの断片でした。
この問題の解決策の1つは、Hadoop用のMap-Reduceを作成し、社内の意思決定にデータを提供するプログラマーを雇うことです。 SQLに精通し、ビジネスの複雑さに精通している資格のあるスペシャリストのグループ全体が既にある場合、なぜこれを行うのでしょうか?代替ソリューションは、すべてをリレーショナルデータベースに保存することです。 この場合、主な頭痛の種は、テーブルと入力ログの両方のスキーマをサポートすることです。 数億レコードのテーブルを持つDBMSのパフォーマンスについては、話すことさえできないと思います。
私たちにとっての解決策はSpark SQLでした。
OK、次は何ですか?
Spark RDDとは異なり、Spark SQLの主要な抽象化はDataFrameです。
DataFrameは、名前付き列の形式で編成されたデータの分散コレクションです。 DataFrameは、概念的にはデータベースのテーブル、Rまたは
Python Pandasのデータフレームに似ていますが、もちろん、分散コンピューティング用に最適化されています。
さまざまなデータソースに基づいてDataFrameを初期化できます:JSONやParquetなどの構造化ファイルまたは弱構造化ファイル、JDBC / ODBCを介した通常のデータベース、およびサードパーティのコネクタ(
Cassandraなど )を介した他の多くの方法。
DataFrame APIはScala、Java、Python、およびRから入手できます。また、SQLの観点からは、
Hiveダイアレクトのすべての機能を完全にサポートする通常のSQLテーブルのようにアクセスできます。 Spark SQLはHiveインターフェースを実装しているため、システムを書き換えずにHiveをSpark SQLに置き換えることができます。 以前にHiveを使用したことはないが、SQLに精通している場合は、おそらくこれ以上何も勉強する必要はありません。
%my-favorite-software%でSpark SQLに接続できますか?
お気に入りのソフトウェアが任意のJDBCコネクタの使用をサポートしている場合、答えはイエスです。
DBeaverが好きで、開発者は
IntelliJ IDEAが好きです。 そして、両方ともThriftサーバーに完全に接続します。
Thrift Serverは、Sparkをデータプロバイダーに変える標準のSpark SQLインストールの一部です。 上げるのはとても簡単です:
./sbin/start-thriftserver.sh
Thrift JDBC / ODBCサーバーは
HiveServer2と完全に互換性が
あり 、透過的にサーバー自体に置き換えることができます。
たとえば、DBeaverからSparkSQLへの接続ウィンドウは次のようになります。

1つのリクエストで異なるデータプロバイダーが必要です
簡単です。 Spark SQLは、SQLを使用して直接データソースを作成できるように、Hive方言を部分的に拡張します。
JSON形式のログに基づいて「テーブル」を作成しましょう。
CREATE TEMPORARY TABLE table_form_json USING org.apache.spark.sql.json OPTIONS (path '/mnt/ssd1/logs/2015/09/*/*-client.json.log.gz')
1つのファイルだけでなく、マスクを使用してその月のデータを利用できることに注意してください。
同じことを行いますが、PostgreSQLデータベースを使用します。 データとして、テーブル全体ではなく、特定のクエリの結果のみを取得します。
CREATE TEMPORARY TABLE table_from_jdbc USING org.apache.spark.sql.jdbc OPTIONS ( url "jdbc:postgresql://localhost/mydb?user=[username]&password=[password]&ssl=true", dbtable "(SELECT * FROM profiles where profile_id = 5) tmp" )
これで、JOINを使用してクエリを完全に自由に実行でき、Spark SQL Engineが残りの作業を行います。
SELECT * FROM table_form_json tjson JOIN table_from_jdbc tjdbc ON tjson.userid = tjdbc.user_id;
データソースの組み合わせはランダムな順序で可能です。 Wrikeでは、PostgreSQLデータベース、jsonログ、および寄木細工ファイルを使用しています。
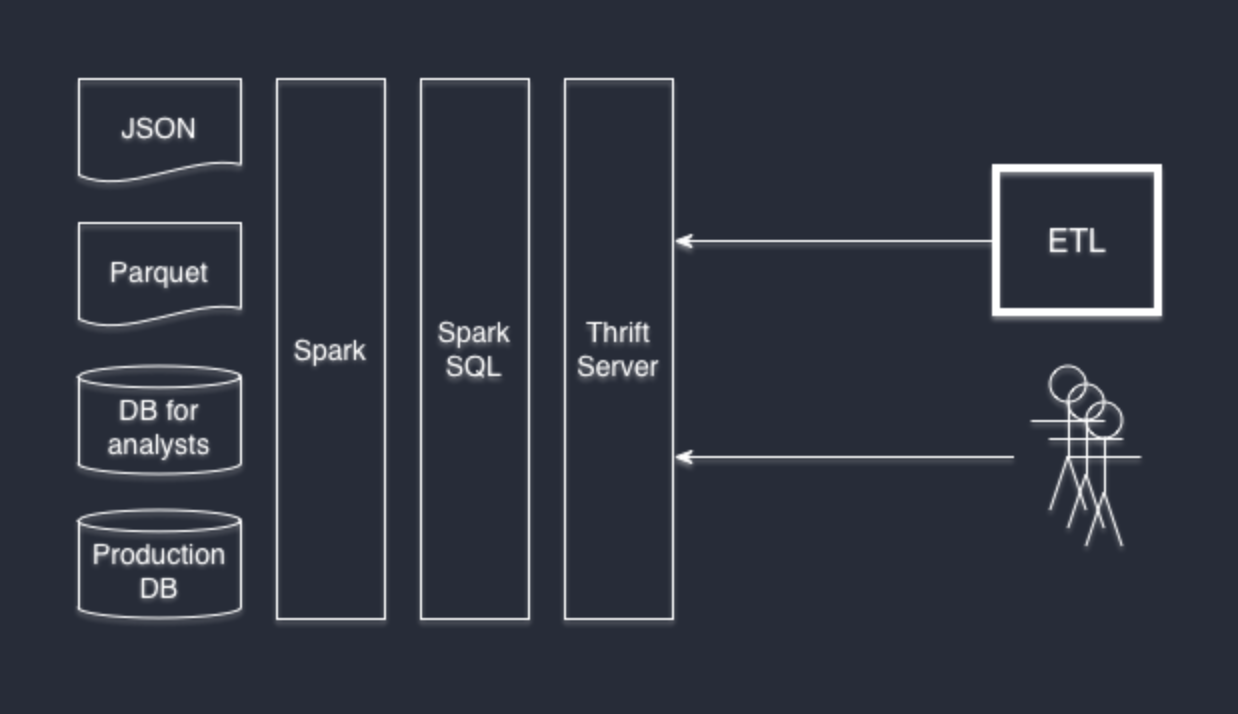
他に何か?
私たちのように、Sparkの使用だけでなく、内部での設計方法の理解にも興味がある場合は、以下の出版物に注意することをお勧めします。