この記事は、Apache Luceneテクノロジーに不慣れなユーザー向けに、初心者向けに設計されています。 Apache Luceneの内部構造、フレームワークの作成に使用されたアルゴリズム、データ構造、およびメソッドに関する資料はありません。 投稿は、単純なあいまいテキスト検索を整理する方法を示すために書かれたティーザートレーニング資料です。
githubのコード、ドキュメントとしての投稿自体、および検索クエリをテストするためのいくつかのデータは、トレーニングの資料として提供されています。
はじめに
Apache Luceneライブラリーの詳細は、
ここと
ここに記述さ
れてい
ます 。 この記事は、クエリ、インデックス作成、アナライザー、あいまい一致、トークン、ドキュメントなどの用語を満たします。
最初にこの記事を読むことをお勧めします。 その中で、これらの用語は、Apache Luceneライブラリに基づいたElasticsearchフレームワークのコンテキストで説明されています。 したがって、基本的な用語と定義は同じです。
ツールキット
この記事では、Apache Lucene 5.4.1の使用について説明します。 ソースコードは
githubで入手でき、リポジトリにはテスト用の小さな
データセットがあります。 基本的に、この記事はリポジトリ内のコードの詳細なドキュメントです。 BasicSearchExamplesTestクラスでテストを実行することにより、プロジェクトの「再生」を開始できます。
インデックスを作成する
MessageIndexerクラスを使用してドキュメントのインデックスを作成できます。
インデックスメソッドがあり
ます 。
public void index(final Boolean create, List<Document> documents) throws IOException { final Analyzer analyzer = new RussianAnalyzer(); index(create, documents, analyzer); }
入力として
createおよび
documents変数を受け入れます。
create変数は、インデクサーの動作を担当します。 trueの場合、インデックスがすでに存在していても、インデクサーは新しいインデックスを作成します。 falseの場合、インデックスが更新されます。
documents変数は、Documentオブジェクトのリストです。 ドキュメントはインデックスおよび検索オブジェクトです。 これはフィールドのセットであり、各フィールドには名前とテキスト値があります。 ドキュメントのリストを取得するために、
MessageToDocumentクラスが作成されます。 そのタスクは、bodyとtitleという2つの文字列フィールドを使用してDocumentを作成することです。
public static Document createWith(final String titleStr, final String bodyStr) { final Document document = new Document(); final FieldType textIndexedType = new FieldType(); textIndexedType.setStored(true); textIndexedType.setIndexOptions(IndexOptions.DOCS); textIndexedType.setTokenized(true);
インデックスメソッドのデフォルトは
lucene -analyzers-commonライブラリで利用可能な
RussianAnalyzerになっています。
インデックスの作成を
試すには、
MessageIndexerTestクラスに移動し
ます 。
検索する
基本的な検索機能を示すために、
BasicSearchExamplesクラスが
作成さ
れました 。 単純なトークン検索とファジー検索の2つの検索方法を実装しています。
searchIndexWithTermQuery()および
searchInBody()メソッドは単純な検索を担当し、
fuzzySearch()メソッドはファジー検索を担当します。
Luceneでクエリを作成する方法は多数ありますが、簡単にするために、通常の検索メソッドはQueryParserクラスとTermQueryクラスを使用してのみ実装されます。 ファジー検索メソッドはFuzzyQueryを使用します。これは、1つの重要なパラメーター
maxEditsに依存します。 このパラメーターはファジー検索を担当し
ます 。詳細は
こちら 。 大まかに言えば、それが大きいほど、検索はあいまい/あいまいになります。
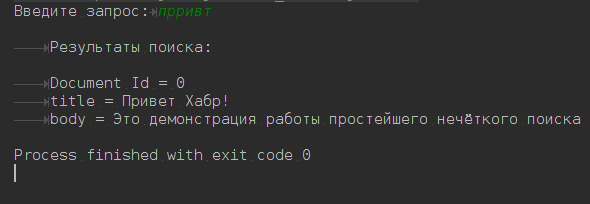
ここでさまざまな方法でリクエストをして
ください 。
検索を行うには、
BasicSearchExamplesTestクラスに移動します
タスク
このプロジェクトを退屈させないために、いくつかのタスクを完了してみてください。
- インタラクティブなコンソール検索を実行します。 検索結果が表示され、次のクエリが要求されます。
- 現在、検索はbodyフィールドでのみ機能します。 タイトルと本文フィールドで同時に検索を実行します。
- 索引付けされた単語(トークン)の数を数える
- メッセージモデルを拡張し、リージョン(region)とメッセージが作成された日付(creationDate)を追加します。 MessageToDocumentクラスにインデックスを作成するための新しいフィールドを忘れずに追加してください。 地域と日付によるフィルターを使用した新しい検索方法を追加します
- MoreLikeThisQueryクエリクラスを見てください。 スコア値を使用して、類似性によってすべてのドキュメントをグループ化してください。
- このファイルをダウンロードすると 、約5000の異なるメッセージが含まれています。 グループ化、新しいクエリ、フィルターの仕組みを確認してください。
おわりに
Apache Luceneの利点は、そのシンプルさ、高速性、低リソース要件です。 欠点は、特にロシア語での優れたドキュメントの欠如です。 このプロジェクトは非常に迅速に開発されているため、インターネットが詰まっている書籍、チュートリアル、およびQ / Aの関連性は長く失われています。 たとえば、LuceneインデックスからTF-IDFベクトルモデルを取得する方法を理解するのに4〜5日かかりました。 この投稿が情報不足というこの問題に専門家の注意を引くことを願っています。
Apache Luceneの世界に飛び込みたい人のために、Elasticsearchのドキュメントをご覧になることをお勧めします。 信頼できるソースへのリンクと例とともに、そこにある多くのものが非常によく説明されています。
オフトップ
これは私の最初の多かれ少なかれ深刻な投稿です。 したがって、批判、フィードバック、提案を表明してください。 現在、Apache Luceneと密接に協力しているため、さらにいくつかの記事を書くことができます。