何言ってるの?
この記事では、
Pandasql Pythonライブラリの使用についてお話したいと思います。
データ分析タスクに直面している多くの人々は、
Pandasライブラリに精通している可能性が高いです。 Pandasを使用すると、表形式のデータをすばやく簡単に操作できます。フィルター、グループ化、データの結合を行います。 ピボットテーブルを作成し、グラフを作成することもできます(単純な視覚化には、
plot()関数で十分です。さらに詳細な情報が必要な場合は、
matplotlibライブラリが役立ちます)。 Habréで、このライブラリを使用してデータを操作することについて繰り返し話しました:
one 、
two 、
three 。
しかし、私の経験では、誰もがPandasqlライブラリについて知っているわけではありません。Pandasqlライブラリを使用すると、テーブルとしてPandas DataFramesを操作し、SQL言語を使用してそれらにアクセスできます。 一部のタスクでは、宣言型SQL言語を使用して必要なものを表現する方が簡単なので、データを扱う人がそのような機能の可用性を知るのに役立つと思います。 実際のタスクについて話す場合、このライブラリを使用して、ファジー条件の下でのテーブルのjoin'aタスクを解決しました(異なるシステムからのイベントのレコードをほぼ同時に、約5秒のギャップで結合する必要がありました)。
特定の例でこのライブラリの使用を検討してください。
分析用データ
説明のために、私は、UdacityのData Analyst Nanodegree専門分野における学生の関与に関するデータを取りました。 このデータは、
Intro to Data Analysisコースで公開されました(Pandasqlライブラリはまったく考慮されていませんが、データ分析にPandasおよびNumpyライブラリを使用したい人にはこのコースをお勧めします)。
例では、2つのテーブルを使用します(データに関する詳細は、
こちらを参照してください )。
- 登録 :学生のランダムなサブセットの「データアナリストナノディグリー」専門分野の記録に関するデータ。
- アカウントキー :学生ID。
- 参加日 :学生が専門分野に登録した日。
- status :データ収集時の学生のステータス :学生がアクティブな場合は「現在」、コースを退会した場合は「キャンセル」。
- キャンセル日 :学生がコースを離れた日、アクティブな学生の場合はなし;
- is udacity :Udacityのテストアカウントの場合True、ライブユーザーの場合-False ;
- 毎日のエンゲージメント :学生がスペシャライゼーションに登録された日ごとの登録テーブルからのアクティビティに関するデータ。
- acct :学生ID;
- utc date :活動の日付;
- 合計訪問時間 :学生がData Analyst Nanodegree専門コースで費やした合計時間 。
例
次に、例を検討します。 PandasとPandasqlの標準機能を使用して、各問題を解決する方法を最も明確に示すように思えます。
最初に、必要なすべてのインポートを実行し、csvファイルからDataFramesにデータをロードする必要があります。 完全なサンプルコードとソースデータは
リポジトリにあり
ます 。
import pandas as pd import pandasql as ps from datetime import datetime import seaborn daily_engagements = pd.read_csv('./data/daily_engagement.csv') enrollments = pd.read_csv('./data/enrollments.csv')
seabornライブラリのインポートは、グラフィックをより美しくするためにのみ使用され、特別なライブラリ機能は使用されません。
簡単なリクエスト
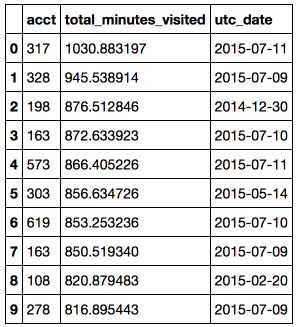
目的 :特定の日の学生のアクティビティのトップ10を見つけます。
この例では、最初のN個のオブジェクトのフィルタリング、ソート、および取得の使用方法について説明します。 SQLクエリを実行するには、
sqldfモジュールの
sqldf関数を使用します。また、ローカル名
locals()辞書をこの関数に渡す必要もあり
globals() Pandasqlの
locals()および
globals()関数の使用については
Stackoverflowで読むことができ
ます )。
結論:最も勤勉な学生は、同じ日に勉強するのに17時間以上を費やしました。
集約関数を使用する
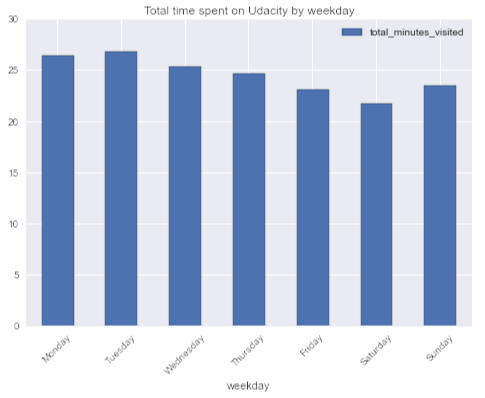
目的 :学生の活動に週ごとの季節性があるのではないか(単独で判断すると、通常、平日のオンラインコースには十分な時間はありませんが、週末により多くの時間を費やすことができます)。
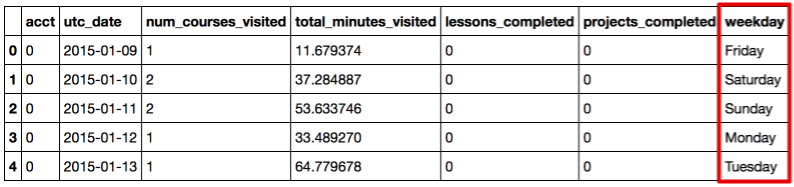
最初に、元のDataFrameに曜日列を追加し、日付を曜日に変換します。
daily_engagements['weekday'] = map(lambda x: datetime.strptime(x, '%Y-%m-%d').strftime('%A'), daily_engagements.utc_date) daily_engagements.head()
結論:好奇心が強いのですが、平均して、学生は火曜日にほとんどの時間をコースに費やし、土曜日にすべてを費やしています。 平均して、学生は週末よりも平日にMOOCに多くの時間を費やします。 私が代表ではないというもう1つの証拠。
テーブルを結合する
目的 :
スペシャライゼーションを完了していない(ステータスがキャンセルされている)学生と学習/スタディに成功した学生を考慮し、
スペシャライゼーションにサインアップした後の最初の週の1日あたりの平均アクティビティを比較します。 滞在して勉強した人は、より多くの時間を学習に費やしたという仮説があります。
この質問に答えるには、
登録表と
毎日のエンゲージメント表の両方のデータが必要なので、学生IDによる参加を使用します。
また、この問題には、考慮すべきいくつかの落とし穴があります。
- すべてのユーザーが生きているわけではなく、Udacityテストアカウントもあります。フィルターする必要があります
is_udacity = 0 ; - 学生は、1週間未満の間隔を含むなど、専門分野に複数回登録できるため、アクティビティの日付utcの日付が参加日とキャンセル日の間であることを確認する必要があります (キャンセルされたステータスの学生のみ)。
SQLクエリでcast関数と
strftime関数を使用して、文字列からタイムスタンプ(時代の始まりからの秒数)に日付をキャストし、これらの日付の差を日数で計算することに注意してください。
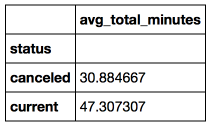
結論:専門分野を放棄しなかった学生は、平均して、勉強をやめることを決めた学生よりも、最初の週に53%多くの時間をUdacityに費やしました。
要約する
この記事では、データ分析にPandasqlライブラリを使用する例を見て、Pandas機能を使用して比較しました。 PandasqlでDataFramesを操作するために、フィルタリング、並べ替え、集計関数、および結合を使用しました。
Pandasはデータをすばやく簡単に変換できる非常に便利なライブラリですが、一部のタスクでは宣言型言語を使用して考えを表現する方が簡単で、Pandasqlが助けになります。 また、Pandasqlは、Pandasを使い始めたばかりで、SQLについて十分な知識を持っている人にとっても便利です。
完全なサンプルコードとソースデータも
githubリポジトリで提供されます。
興味のある方のために、
The Yhat Blogに優れたPandasqlチュートリアルもあります。