プライベートおよび企業コンテンツの爆発的な成長は、この10年間で最も重要な特徴の1つとして認識されています。 エコノミスト誌によると、 2000年代初頭にはわずか150エクサバイト(10億ギガバイト)のコンテンツしか作成されておらず、10年後にはこの数値は1200エクサバイトに増加しました。 予測によると、この数字は2020年までに1,000倍に増加します。
Cloud4Yでは、将来のデータウェアハウジングの要件について可能な唯一の予測は、完全な予測不能性であり、その量は想像できるよりも大幅に大きくなるという事実です。 この成長を管理しようとする代わりに、「ビッグコンテンツ」の管理に焦点を移すべきです。
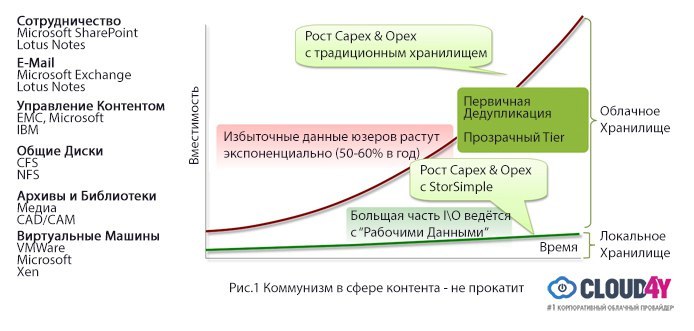
コンテンツ共産主義が機能しない、またはGoogleのように考える
コンテンツの総量は着実に増加しています。 ただし、ほとんどの人は、コンテンツの特定の「ワーキングセット」にのみ関心があります。 たとえば、SharePointでは、人々は追加された最新のデータをより頻繁に心配し、電子メールに関しては、1年前に受け取ったものではなく、今日の手紙を気にします。
「ビッグコンテンツ」の従来の問題は、共有コンテンツが保存される控えめな共有ドライブです。 たとえば、企業のプレゼンテーションをここに保存し、一般的な個人が単純にそれを取り、コピーと貼り付けを行い、自分からスライドをいくつか追加して、新しいコピーを保存します。 同じスライドは何度も再保存されますが、古いプレゼンテーションは消えません。 おなじみですか? 
「ビッグコンテンツ」の膨大な新しいボリュームは、ビデオやその他の
メディアの膨大なボリュームと見なされ
ます 。 これらすべてにより、すべてのコンテンツを1つのコームの下に並べることはできません。 Googleで作業する場合は、Googleのように考える必要があります。そうしないと、情報量に比例して資本および運用費用が増加します。
検索エンジンがすべてのデータが同じであると見なした場合、必要な情報は最初のページと20ページの両方で見つけることができます。 検索サービスは情報をランク付けすることを学んでおり、同じアプローチを、人間が介入することなく、毎日自動的に保存するデータに適用する必要があります。 優先コンテンツはアクセス可能なローカルディスクに配置し、セカンダリデータはクラウドで自動的にランク付けする必要があります。
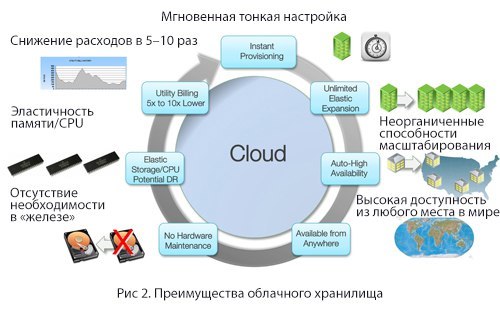
クラウドおよび回復力のあるクラウドストレージの可能性
ストレージに関して言えば、クラウドには否定できない利点がいくつかあります。
- すぐに微調整
- 組織化されていないスケーリング機能
- 世界中のどこからでも高可用性
- ハードウェアは不要
- メモリ弾力性/ CPU
- コストを5〜10倍削減
クラウドストレージに関するいくつかの神話は次のとおりです。
- クラウドがHTTP / REST APIを使用するため、ユーザーアプリケーションを書き直し、バックアップを再編成する必要があります 。
- 遅延とWAN帯域幅のコストによるパフォーマンスの問題に直面する必要があります。
- WAN最適化はパブリッククラウドでは機能しません
- クラウドは安全ではありません
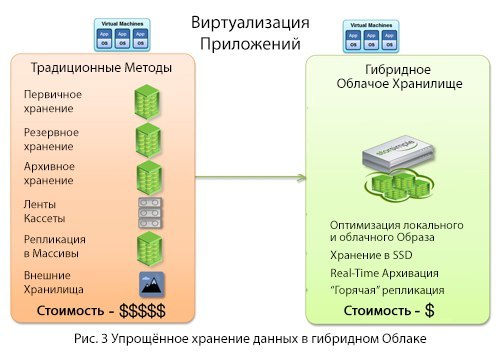
クラウドとしての階層アーキテクチャ:エンタープライズクラウドストレージ戦略
クラウド固有の機能を活用するには、クラウド用に設計されたアーキテクチャが必要です。 この記事では、Cloud -as-a-Tierアーキテクチャの使用を検証し、それを使用して安全なマルチレベルの企業クラウドストレージシステムを編成する方法についてのアイデアを提供します。 これは、データの保存、アーカイブ、および保護、および災害復旧の従来の方法と比較して、クラウド内のコンテンツの動的なライフサイクルのコンテキストでこれを考慮します。
結論として、新しいシンプルな企業クラウドストレージアーキテクチャのモデルを紹介します。これは、以下を作成するためのハードウェアとソフトウェアの購入の代替手段となります。
- 一次ストレージ
- バックアップストレージ
- アーカイブストレージ
- インフラストラクチャおよびデータフィード管理
- 災害復旧データレプリカ
- 地理的持続可能性のためのリモートサイト
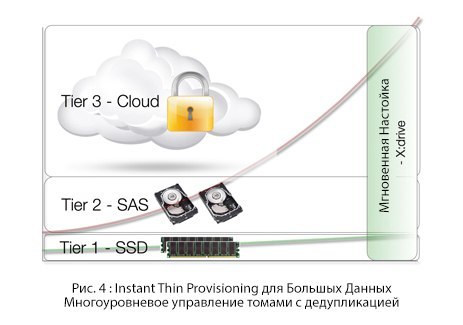
「ビッグコンテンツ」のリソースのシン割り当て
ビッグコンテンツ用のアプリケーションを展開する場合、主な質問は、そのために必要なメモリ量です。
計画がはるかに先に進み、ストレージボリュームを年単位ではなくテラバイト単位で計算する場合(つまり、使用済みの領域に対してのみ支払いたい場合)、大幅に節約できます。 一方、短期計画のみに従事していて、突然ディスク領域が不足すると、時間を失い、再計画と再編成を余儀なくされます。
結局、導入部で述べたように、「将来のデータウェアハウスの要件に関して可能な唯一の予測は、完全な予測不可能性です」。
HPが最初に3PARでテストした従来のアプローチは、「シンリソース割り当て」を意味し、事前の容量割り当ての必要性を排除します。 ハイブリッドクラウドは、この原則を新たなレベルに引き上げ、企業が必要なストレージボリュームを即座に提供し、使用済みのボリュームのみを支払うことを可能にします。
重複排除、データのランキングおよび自動階層化
これをすべて説明する最も簡単な例は、SharePointです。 すでに述べたように、ユーザーは、たとえば、サイズが5 MBのプレゼンテーションでは、著者の名前とタイトルページのみを変更し、両方のバージョンを保持することが一般的です。 従来、両方のバージョンの重量は5 MBです。 重複排除はこのアプローチを変更し、情報世界全体を一連の情報ブロックとして表します。 同じブロックが2回保存されることはありません。 この例では、変更されたブロックのみが保存されるため、プレゼンテーションの2番目のバージョンは5 MBではなく数十キロバイトを占有できます。
情報の世界を一連のブロックとして見ることには、他の利点もあります。 たとえば、常に必要なコンテンツは最前線に持ち込まれ、何年も使用されていないコンテンツは単にバックグラウンドの
どこかに保存されます。これはすべて、検索エンジンでのサイトのランキングに似ています。
クラウドとしてのセキュリティ
通常、セキュリティ侵害には、暗号化されていないデータへの個人のアクセスが含まれます。 最近の例としては、英国政府が各市民の保険情報を銀行の詳細とともに保存し、ロンドンに送信したことがあります。 その後、このデータはすべてインターネットで販売されました。 今日、高度なデータ暗号化により、これらのセキュリティ侵害は不可能になります。 クラウドのセキュリティは、単に子育ての問題です。
安全なクラウドを実装するために重要ないくつかの重要なアーキテクチャ上の問題があります。 ローカルストレージからストレージクラウドに移動するすべてのブロックは、静止時と移動中の両方で暗号化する必要があります。 2番目の重要なコンポーネントはキー管理です。これらはクラウドではなく顧客が保存する必要があります。 それ以外の場合は、暗号化されていないコンテンツにアクセスできるように、再びその人物に依存します。
追加の方法があります:各クライアントが独自のキーを持っている場合、リポジトリへの集約されたアクセス。 ただし、売り手であるアグリゲーターもこれらのキーにアクセスできます。これもセキュリティリスクです。
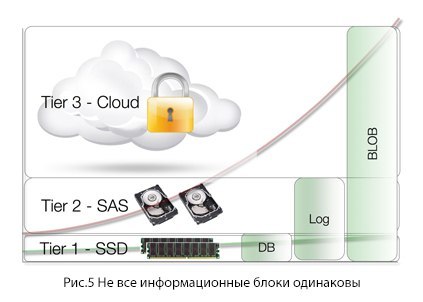
すべての情報ブロックが同じというわけではありません。
既に述べたように、「コンテンツの共産主義」はクラウドには適用されません。すべてのコンテンツをクラウドに転送するのは望ましくありません。未使用部分を可視性ゾーンから削除する必要があります。 Cloud -as-a-tierアーキテクチャに必要なのは、ユーザーの行動を理解し、それにストレージ機能を適応させる能力だけです。
ライブアーカイブ、またはティアで涙が出ない
格納される情報の量が増えると、管理者はその一部をアーカイブし、ライブアクセスから削除する必要があります。 これは通常、経済的な理由で行われます。 同時に、データの必要に応じて問題が発生する可能性があります。たとえば、6か月のダウンタイム後にアーカイブされたデータが年次レポートに緊急に必要な場合はどうなりますか。
コンテンツ管理システムやSharePointなどのシステムでは、コンテンツだけでなく、それに関連するセキュリティポリシーなどをアーカイブする必要があるため、アーカイブはさらに困難です。 相互接続された多数のブロックをアーカイブして、必要に応じて複合施設内のすべての情報にアクセスできるようにする必要があります。
クラウドは、その弾力性により、データ用に大量の空きスペースを提供し、問題の解決策になる可能性があります。 重複排除、圧縮、暗号化を組み合わせて、クラウドをプライマリストレージとバックアップストレージに使用すると、ストレージの経済性が最適になります。
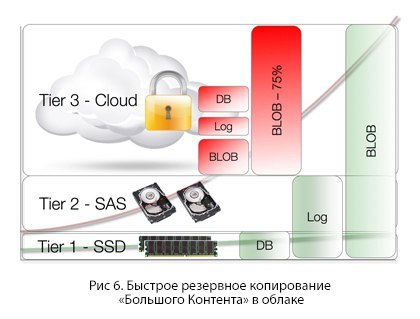
クラウド内の「ビッグコンテンツ」のクイックバックアップ
クラウドは、グローバルネットワークの単なるディスクと見なすべきではありません。 そうすることで、特にバックアップについて知らない場合、悲しい経験をすることができます。
人々は冗談を言って言う:「クラウドにバックアップする最も速い方法は何ですか? 答えは、単に何もしないことです。」 データをクラウドに保存する場合、これはバックアップです。 バックアップバージョンを作成するには、デバイスに現在保存されているコンテンツのみをコピーする必要があります-当然、重複排除、圧縮、暗号化の後。 より正確には、そのようなコンテンツの一意の情報ブロックのみがかなり控えめな量です。
クラウドからの「ビッグコンテンツ」の高速リカバリ
人々がバックアップの作成について本当に考えていないことは知られています-これらのコピーが必要になる瞬間まで。
クラウドアーキテクチャは、プライマリデータセンターまたはセカンダリデータセンターのデータ回復機能に大きな影響を与えます。 バックアップバージョンが数テラバイトの大きな情報ブロックである場合、リカバリは時間がかかり、痛みを伴うプロセスになる可能性があります。 迅速なリカバリを行うには、クラウド
としての機能をティア
として使用する必要があります。
このアプローチにより、高速SSDおよびローカルドライブにワーキングセットを保存するためのマルチレベル構造に情報を保存できます。 このアーキテクチャにより、情報ボリューム全体を引き出すことなく、マルチテラバイトボリュームを合理的に回復できます。 「ワーキングセット」という少量のデータのみが抽出され、残りのブロックはクラウドに残り、必要に応じて発行されます。 「作業セット」は文字通りその場で再作成され、この時点で全量のデータが再び適切に配置されます。
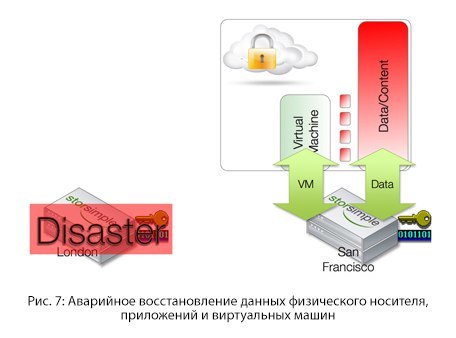
Cloud -as-a-Tierでの災害復旧
ユーザーに災害復旧手順を確認する頻度を尋ねると、非常に静かに話し始めるか、赤面します。 事故は本質的に予測不可能です。 9月11日まで、記録された保存データを転送する手順は航空機を使用して実行され、ハリケーンカトリーナが発生したとき、すべてのデータは浸水した鉱山に残っていました。
クラウドの出現により、クラウドはいつでもどこでも利用できるため、災害復旧ポリシーを定期的に確認することが可能になりました。
必要なのは、構成全体をインストールできるアクセス可能なデバイスを手元に用意することだけです。 その後、クラウドボリュームをストレージ用にリモートロケーションに再度転送すると、コンテンツが再び利用可能になります。
「ビッグコンテンツ」と仮想マシンには1つの共通の特性があります-それらは非常に膨大です。 クラウド
としてのクラウドアーキテクチャを使用して、広範な仮想マシンライブラリを保存することもできます。 このアーキテクチャは、仮想マシン全体に適用することも、単にデータウェアハウスに適用することもできます。
結論の代わりに
企業のストレージに対する従来のアプローチは、ソフトウェアまたはハードウェアの特性のために非常に複雑です。 従来のアプローチでは、必要な要素が多すぎます。
クラウドとしてのハイブリッドクラウドは、クラウドの固有の利点を活用し、ストレージを簡素化するように設計されています。 ハイブリッドクラウドに必要なコンポーネントは2つだけです。
- クラウドに情報を送信するためのデバイス
- クラウドプロバイダー
簡単に言えば、クラウドを使用すると、日常的に必要な情報だけをランク付けしてローカルアクセスに保存できます。 オンプレミスのアプリケーションはそのままです-クラウドは既存のネットワークに統合されます。 仮想マシンのようなビッグコンテンツを保存するシンプルさを保証するものは何もありません。 小さな惑星が巨大な惑星を中心に回転するため、「ビッグコンテンツ」はスマートな仮想マシンを引き付け、コンテンツおよびコンテンツを制御するクラウドプロバイダーに向かって移動させます。
ビッグコンテンツは新しい魅力の中心になり、アプリケーションはクラウドにそれに従います。