この記事では、ドメイン生成アルゴリズムを使用して生成されたドメイン名を検出する方法を紹介します。 例えば、moqbwfijgtxi.info、nraepfprcpnu.com、ocfhoajbsyek.net、pmpgppocssgv.biz、qwujokiljcwl.ru、bucjbprkflrlgr.org、cqmkugwwgccuit.info、pohyqxdedbrqiu.com、dfhpoiahthsjgv.net、qdcekagoqgifpq.biz。 そのようなドメイン名は、違法行為に関連するサイトにしばしば与えられます。
DGAを使用するシナリオの1つは、マルウェアにコンピューターシステムが感染した場合に観察できます。 侵害されたマシン上の悪意のあるソフトウェアは、攻撃者の制御下にあるシステムに接続して、コマンドを受信したり、収集した情報を送り返したりします。
攻撃者はDGAを使用して、感染したマシンが接続しようとするドメイン名のシーケンスを計算します。 これは、コードに直接記述された攻撃者のドメインまたはIPアドレスがセキュリティシステムによってブロックされた場合に、ハッキングされたインフラストラクチャの制御が失われないようにするためです。
ブラックリストを使用して悪意のあるDGAドメインを特定する問題を解決することはできません;ここでは別のアプローチが必要です。 これらのアプローチの1つについて説明します。
基本的な考え方は、正当なドメインは人間が読めることが多く、意味的な意味を持つため、正当なドメイン名で使用される文字シーケンスはDGAを使用して取得されるドメイン名の文字シーケンスとは異なるというものです。
この問題を解決するために、機械学習とN-gram分析が使用されました。 Alexaの上位100万(白いドメイン)とbambenekconsulting.comの70万(悪意のあるドメイン)がトレーニングサンプルとして採用されました。
メソッドの説明
まず、ドメインのセット全体がトレーニングとテストのサンプルに分割されます。 ドメインのトレーニングサンプルに基づいて、多くのN-gramは一意性を考慮して構築されます。 固定長のドメイン部分文字列は、N-gramとして取得されます。
DGAドメインCryptolocker vzdzrsensinaix.comの例を検討してください。 4文字の長さで11個のN-gramを作成します。
 図 1.ドメインをN-gramに分割する
図 1.ドメインをN-gramに分割するトレーニングサンプルに基づいて構築された一意のN-gramのセットは、多くの悪意のないN-gram(正当なドメインでのみ検出)、多くの悪意のあるN-gram(悪意のあるドメインでのみ検出)、および多くの中立のN-gram(検出)の3つの部分に分かれています両方のタイプのドメインで)。 一意の各N-gramは、数値係数に関連付けられています。
- 1-正当な
- −1-悪意のある、
- {−1.0..1.0}の数値は中立です。
訓練されたモデルにより、多くのペアを理解できます
{( q, Ng(q))} 、ここで
Ng(q) = p 、
pはN-gram qの数値係数、qはQに属し、Qはトレーニングセット内のすべてのN-gramのセットです。
サンプリング
このタスクのために、特定のサンプリング方法を開発しました。 その主なアイデアは、トレーニングサンプルとして、利用可能なすべてのドメインに関する最大情報を含むセットを、さまざまな悪意のあるホワイトドメインからコンパイルすることです。 本質的に、これは、モデル内のテストサンプルの任意のドメインに対して、このドメインに属する少なくともk個のN-gramが存在することを意味します。kは事前定義された自然数です。
この場合、トレーニングのために、本質的にサンプルのコアをモデルとして使用します。 これにより、テストセットの次のドメインにモデルとの単一の一致がなく、したがって、それが1つのクラスに属しているか別のクラスに属しているかを判断できない場合のトレーニング段階での状況を回避できます。
サンプルを分割するこの方法により、たとえばランダムな分割と比較して、ドメインの分類の精度を向上させることができました。 両方の方法のテスト結果を以下に示します。
 図 2.各ドメイン名には、トレーニングセットと空でない交差点が含まれています。 各ドメインの最小交差数は、分割アルゴリズムのパラメーターで設定されます
図 2.各ドメイン名には、トレーニングセットと空でない交差点が含まれています。 各ドメインの最小交差数は、分割アルゴリズムのパラメーターで設定されますモデルトレーニング
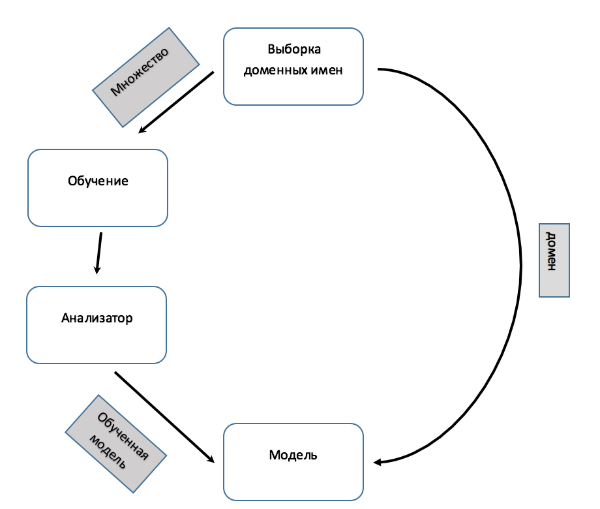 図 3.分類子のスキーム
図 3.分類子のスキーム分析されたドメインの有害性を判断するために、アルゴリズムは再帰関数を計算します:
I(i) = I(i-1) * α + Ng(q i ) 、ここでq
iはドメインのi番目のN-gram、Ng(qi)は考慮されたNの係数です-grams、αは軟化係数、I(0)= 0です。再帰関数の許容値については、境界Tが定義されます。再帰関数の次の反復の計算結果がこの境界より小さくなると、対応するドメインは悪意があると宣言されます。
悪意のある(プッシュボット)ドメインの例を使用して、アナライザーの動作を説明しましょう。
jrgxmwgwjz.com(α= 0.9; T = −1.5)
表1.アナライザーの例:
| N-gram番号 | Nグラム | 係数
モデルからのN-gram | 価値
再帰関数 |
|---|
| 1 | jrgx | -1 | −1 |
| 2 | rgxm | 0 | −0.9 |
| 3 | gxmw | 0 | −0.81 |
| 4 | xmwg | 0 | −0.73 |
| 5 | mwgw | 0.06 | −0.6 |
| 6 | wgwj | −0.92 | -1.45 |
| 7 | gwjz | −0.68 | -1.99 |
−1.99 <Tしたがって、ドメインは悪意のあるものです。 Tのしきい値は、研究に基づいて経験的に決定されます(図4を参照)。
ここで、ニュートラルNグラムの係数をより詳細に検討します。 これらの係数を取得するには、進化アルゴリズムが使用されます(進化アルゴリズムは、自然進化の原理に基づいて最適化問題を解決するために設計されたアルゴリズムのファミリーです)。
この進化的アルゴリズムの実装の目的は、ニュートラルNグラムの最適な数値を計算することです。 進化的アルゴリズムの結果として得られた解は、ニュートラルNグラムの係数の値のベクトルであり、分類器の最高の精度を保証します。 分類器の精度は、実験的テストの結果として選択された非減少目的関数の値によって推定されます。
Fitness = P/TP + N/TN + FP/P + FN/NFitness値が2に近いほど、分類精度が高くなります。
結果
提案の有効性を評価するために、ドメインのサンプルで一連の実験が行われました。 ドメインのセット全体は、トレーニングサンプルとテストサンプルの2つの部分に分割されました。
表2.調査したサンプルのサイズ:
| 数量
悪意のあるドメイン | 数量
正当なドメイン |
|---|
教育的
サンプリング | 60,000 | 70,000 |
テスト
サンプリング | 640,000 | 830,000 |
 図 4.最適なしきい値の選択
図 4.最適なしきい値の選択図のグラフから 4は、最適なしきい値が-1.5であることを示しています。これは、偽陽性と偽陰性の間でバランスが取れているためです(両方のエラーは1%程度です)。
メソッドの品質評価
 図 5.サンプル分割の比較
図 5.サンプル分割の比較実験により、私たちが提案した方法は分類精度がかなり高く、開発された分割方法を使用するとさらに向上することが示されました。
投稿者 Alexander Kolokoltsev、Positive Technologies