Graylogで
VPSVilleの 3つのビデオを書くと、ハブにはレビュー
記事が1つしかなく、ソフトウェアのバージョンが異なるとコンポーネントが異なるため、どの言語のマニュアルも混乱していることがわかりました。 このすべての美しさを消化するのに1日を費やしてから、WindowsとLinuxからイベントを収集するためにGraylogサーバーを構成する方法というマニュアルを作成します。
本当にLinuxを理解したいが、どこから始めればよいのかわからない-私の
チャンネルに来てください。

導入する代わりに:Graylogは、さまざまな方法で膨大な数のソースから巨大ネットワークのログを収集するように設計されたオープンソースソフトウェアです。 イベント、フィルタリング、検索、自動化(あらゆる種類のアラート)などのコレクションを便利に整理できます。 同様のツールは多数ありますが、Graylogは最新のコンポーネント、便利な分析、美しいインターフェイスを使用して非現実的なパフォーマンスを提供します。
彼は動作するために
Javaを必要とし
ます 、彼はログを検索して保存するために
MongoDBに設定を保存します
-ElasticSearchを使用し
ます 。 WIndowsからの情報収集については低くなりますが、ネタバレ-エージェントはもはやJavaを必要としません。
そのため、Graylogを収集するための公式
マニュアルがあります。 しかし、多くのものが見逃されていましたが、これらは単なる情報の一部であるため、一歩一歩進んでいきましょう(開発者が現在アドバイスしているので、Ubuntu 14.04を使用しています)。 Graylogはもともと巨大なネットワークを対象としていたため、データベース、検索エンジン、Graylog自体を異なるサーバーに配置し、これからクラスター、ノードなどを作成することをお勧めします。 私は、すべてが同じマシン上で回転する最も単純な構成を取ります。
最初の部分:Graylogのインストール。 ( ビデオ命令 )最初のJava(8番目のバージョン以上):
sudo add-apt-repository ppa:webupd8team/java sudo apt-get update sudo apt-get install oracle-java8-installer
その後、MongoDB(突然変更されるもの、ここに
マニュアルがあり
ます ):
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv EA312927 echo 'deb http://downloads-distro.mongodb.org/repo/debian-sysvinit dist 10gen' | sudo tee /etc/apt/sources.list.d/mongodb.list sudo apt-get update sudo apt-get install mongodb-org
次のElasticSearch(独自の
マニュアルもあり
ます ):
sudo wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add - echo "deb http://packages.elastic.co/elasticsearch/2.x/debian stable main" | sudo tee -a /etc/apt/sources.list.d/elasticsearch-2.x.list sudo apt-get update sudo apt-get install elasticsearch
弾力性のニーズ:
自動起動設定:
sudo update-rc.d elasticsearch defaults 95 10
構成ファイルの編集:
sudo vi /etc/elasticsearch/elasticsearch.yml
つまり、クラスター名を指定します。例:
cluster.name: graylog
cluster.name: graylog
ネットワーク経由でのアクセスを拒否します(システム全体が同じマシン上にあるため):
network.bind_host: localhost
network.bind_host: localhost
また、動的スクリプトを無効にすることを推奨していますが、私の弾力性はこのオプションを誓います:
script.disable_dynamic: true
script.disable_dynamic: true
Elasticの再起動:
sudo service elasticsearch restart
そしてチェック
curl -XGET 'http://localhost:9200/_cluster/health?pretty=true'
出力に率直なエラーがない場合、すべてが正常です。
Graylogのインストールと試用:
sudo apt-get install apt-transport-https wget https://packages.graylog2.org/repo/packages/graylog-2.0-repository_latest.deb sudo dpkg -i graylog-2.0-repository_latest.deb sudo apt-get update sudo apt-get install graylog-server sudo rm -f /etc/init/graylog-server.override sudo start graylog-server
次に、アクセスするためのパスワードを設定します(「123456789」を持っています)。暗号化されています。大人(以下のコマンドの意味がわからない場合:
ビデオを見る、または質問を書く)
sudo apt-get install pwgen SECRET=$(pwgen -s 96 1) sudo -E sed -i -e 's/password_secret =.*/password_secret = '$SECRET'/' /etc/graylog/server/server.conf PASSWORD=$(echo -n 123456789 | shasum -a 256 | awk '{print $1}') sudo -E sed -i -e 's/root_password_sha2 =.*/root_password_sha2 = '$PASSWORD'/' /etc/graylog/server/server.conf
同じ設定ファイルで、将来のGraylogサーバーのIPとプレフィックス(上記のElasticクラスターの名前でもあります)を示します。
sudo vi /etc/graylog/server/server.conf rest_listen_uri = http://10.0.1.10:12900/ web_listen_uri = http://10.0.1.10:9000/ elasticsearch_index_prefix = graylog
Graylogを再起動し、Webインターフェースから入力を試みます。
10.0.1.10:9000 /
(設定自体で指定されたすべてのポートが開いている必要があります)。 起動時に、Graylogは数分間だまして、すべてが悪いことをWebインターフェースに書き込み、パスワードを受け入れずにメインページにスローします。 彼に時間をかけて回復してみてください。
第二部:LinuxからGraylogでログ受信を設定します。 ( ビデオ命令 )ログを受信するためにサーバーのコンソールにアクセスする必要はもうありません。 Webフェイスに移動して、ログの入力を作成します。
ビデオがあるので、Webインターフェースでナビゲーションをペイントするのは良くあり
ません 。 要するに:
- UDP入力は[システム]メニューで作成されます。
- syslog udpが示されます。
- ポートは指定されています(デフォルトでは512ですが、グレイログで1024未満のポートを使用するには多くのトラブルが必要です)。たとえば、1234;
- 着信メッセージを聞くためのアドレスが示されています。10.0.1.10があります。
- 起動をクリックします。
入力の動作を確認するには、同じグレイログサーバーのコンソールで実行できます
echo "Hello Graylog" | nc -w 1 -u 10.0.1.10 1234
また、入力で受信したメッセージのWebインターフェイスを確認します。
ログを送信するためのLinuxマシンの構成は、基本的に簡単です。 ほとんどすべての場所で、syslogdリリースの動作は同じです。 誰がデーモンのロギングについて何も覚えていない-私の
チャンネルで私の記憶をリフレッシュする。 debianとredhatです。
rsyslogジョブファイルが作成されます。
sudo vi /etc/rsyslog.d/90-graylog2.conf
テキスト付き(アドレスとポートは設定された入力から取得されます):
$template GRAYLOGRFC5424,"<%PRI%>%PROTOCOL-VERSION% %TIMESTAMP:::date-rfc3339% %HOSTNAME% %APP-NAME% %PROCID% %MSGID% %STRUCTURED-DATA% %msg%\n"
*.* @10.0.1.10:1234;GRAYLOGRFC5424
ログデーモンはコマンドによって再起動されます
sudo service rsyslog restart
(または、OS上にあるものは何でも)。
また、Graylog Webインターフェースで受信したメッセージを見ることができます。
第三部:WindowsからGraylogでログ受信を設定します。 ( ビデオ命令 )Graylogの2番目のバージョンは、javaで使用されるgraylogコレクターよりも新しいバージョンです。 2番目(関連)では、単に無視され、エラーが発生します(これに気付くまで半日修正しようとしました)。 代わりに、
graylog sidecarを使用します。これは、Graylogサーバーから設定を受け取り(設定を編集するためにWindowsサーバーを登る必要がないため非常に便利です)、
nxlog (またはお
好みの )に送信し、イベントを収集して送信します。
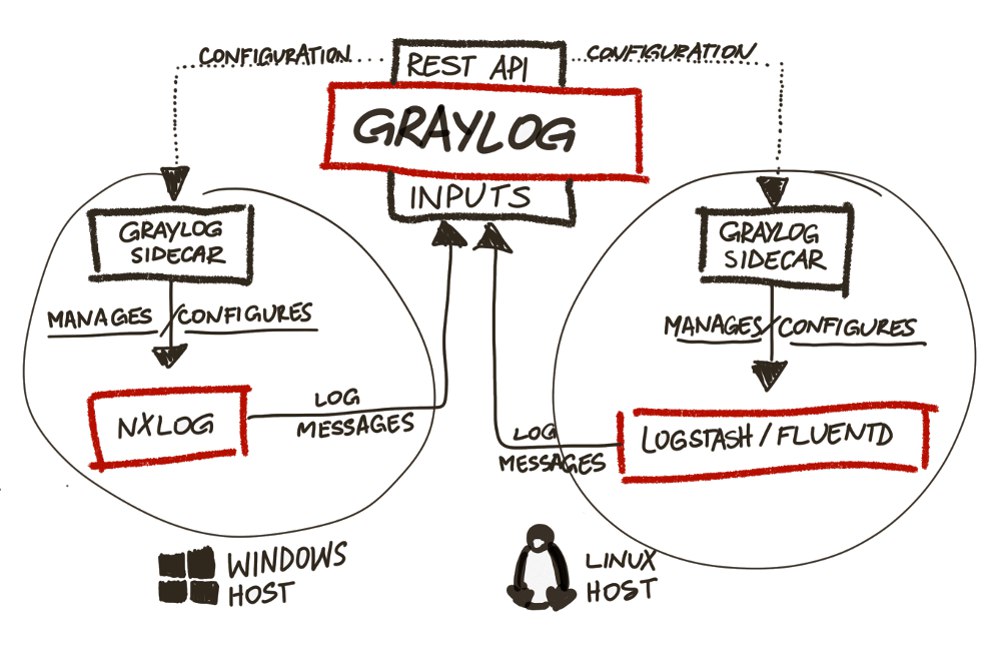
Windowsからメッセージを受信するには、Webインターフェイスを介して別の入力を作成する必要があります。
- GELF UDPを選択します。
- ノード、graylogサーバーのIPアドレスを指定します。
- メッセージを受信するためのポートを記憶または編集します(デフォルトでは12201)。
Windowsでnxlogのログを送信するための構成を作成するには、graylogのWebインターフェースを介してコレクターを作成する必要があります。
- コレクターを選択します。
- [構成の管理]を選択します。
- 構成を作成します。
- ラベルを指定します(Windowsのサイドカーラベルによって、nxlogの設定を自分のマシンにダウンロードする必要があることを理解します)。
- nxlogの出力を作成します(前のステップからの入力設定を指定するだけです:GELF UDP出力、IP、ポート)。
- nxlogの入力を作成します(最も単純なオプションを指定します:Windowsイベントログ)。
Windowsに移動し、
nxlogと
graylog- sidecarをダウンロードしてインストールします。
nxlogサービスとして削除し、サイドカーサービスとして設定します。
'C:\Program Files (x86)\nxlog\nxlog.exe' -u
'C:\Program Files (x86)\graylog\collector-sidecar\graylog-collector-sidecar.exe' -service install
サイドカー構成ファイル(
C:\ Program Files(x86)\ graylog \ collector-sidecar \ collector_sidecar.yml)を編集します。つまり、グローバルリスニングポート(12900)、IPサーバー、そして最も重要なのは、構成を受け取るラベルです。 私にとってはこのように見えます:
server_url: http://10.0.1.10:12900
node_id: graylog-collector-sidecar
collector_id: file:C:\Program Files (x86)\graylog\collector-sidecar\collector-id
tags: windows
log_path: C:\Program Files (x86)\graylog\collector-sidecar
update_interval: 10
backends:
- name: nxlog
enabled: true
binary_path: C:\Program Files (x86)\nxlog\nxlog.exe
configuration_path: C:\Program Files (x86)\graylog\collector-sidecar\generated\nxlog.conf
サイドカー
'C:\Program Files (x86)\graylog\collector-sidecar\graylog-collector-sidecar.exe' -service start
'C:\Program Files (x86)\graylog\collector-sidecar\graylog-collector-sidecar.exe' -service start
イベントの作成
eventcreate /l Application /t INFORMATION /id 1 /d “Suck it”
eventcreate /l Application /t INFORMATION /id 1 /d “Suck it”
そのディレクトリ内のログ(
C:\ Program Files(x86)\ graylog \ collector-sidecar \ )を確認し、すべてが問題なければ、Webフェイスにアクセスして入力のWindowsログを確認します。
ニュアンス:- 構成ファイルは、空のCを手動で作成する必要がありますC:\ Program Files(x86)\ graylog \ collector-sidecar \ generated \ nxlog.conf;
- すべてのサービスがすべてを取得するために、Windowsを再起動する必要がある場合があります。
- ラベルの名前に誤植があり、1時間殺して整理していた。
- ラベル自体はWebインターフェースでフレーム化する必要があります。それ以外の場合はラベルではありません。
それでは、Webインターフェースでの作業が始まります。どこからログを取得するか、どのイベントにどのように応答するか、何をフィルタリングするかなどです。 掘り始める-あなたはそれを把握します。 念のため、もう一度、
マニュアル 。