この記事では、ドキュメントがない場合や公式に公開されていない場合に、サイトAPIを取得して使用する方法について説明します。 このガイドは、単純なAPIを元に戻そうとしていない初心者向けに書かれています。 同様のことに従事していた人たちにとって、ここには新しいものは何もありません。
Microsoftが最近オープンしたAPIサービスhttps://www.captionbot.ai/を使用して分析します(これに感謝します)。 多くの人がGeektimesの記事で彼について読むことができました 。 このサイトはJSON形式のajaxリクエストを使用しているため、それらをコピーするのは簡単で快適です。 行こう!
リクエストを分析します
まず、開発者ツールを開き、サイトがサーバーに送信するリクエストを分析します。
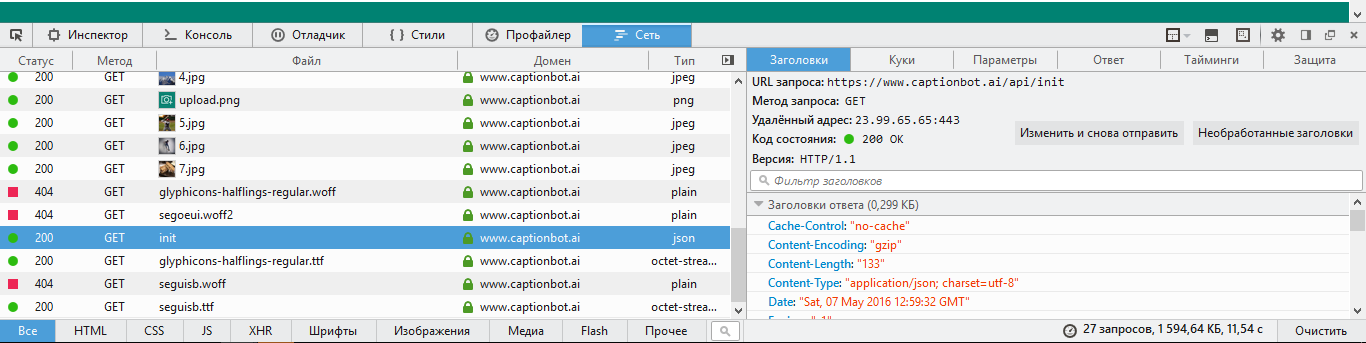
私たちの場合、私たちに興味があるすべてのリクエストはベースURL https://www.captionbot.ai/apiを持っています
初期化
最初にサイトを開くと、パラメーターなしでGETリクエストが/api/init送信されます。
応答にはContent-Type: application/jsonがありますが、応答本文には次の形式の行があります:
"54cER5HILuE"
これを覚えて、次に進んでください。
URL送信
画像をアップロードするには、URLを使用する方法とファイルをアップロードする方法の2つがあります。 テストのために、WikiからLena画像のURLを取得して送信します。 ネットワークアクティビティでは、 /api/message POST要求が次のパラメーターとともに表示されます。
{ "conversationId": "54cER5HILuE", "waterMark": "", "userMessage": "https://upload.wikimedia.org/wikipedia/ru/2/24/Lenna.png" }
そうです、 initメソッドがconversationId文字列を返し、リンクがuserMessageに入ったことをuserMessageます。 waterMarkとはまだ明確ではありません。 応答データを確認します。
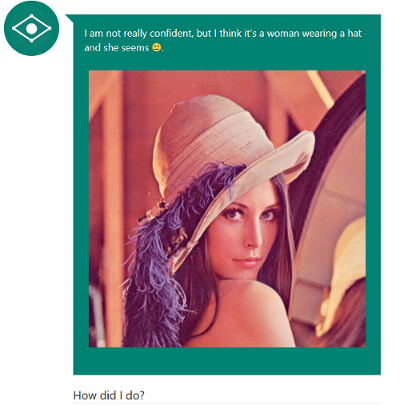
"{\"ConversationId\":null,\"WaterMark\":\"131071012038902294\",\"UserMessage\":\"I am not really confident, but I think it's a woman wearing a hat\\nand she seems . \",\"Status\":null}"
何らかの理由で、JSONを2回エンコードしましたが、まあまあです。 人間の形では、次のようになります。
{ "ConversationId": null, "WaterMark": "131071012038902294", "UserMessage": "I am not really confident, but I think it's a woman wearing a hat\\nand she seems .", "Status": null }
途中のすべてのパラメーターは書き方を変えましたが、これらは人生の些細なことです。 そのため、何らかの理由で、値がWaterMarkに返され、空のConversationId 、 UserMessageフィールドの写真の実際のキャプション、および空のステータスがUserMessageれました。
画像のアップロード
さらに、タブを閉じずに、ローカルファイルから写真をダウンロードして同じ操作を試みます。 fileフィールド名を/api/upload 、 /api/upload multipart/form-data形式でのPOSTリクエストが表示されfile 。
-----------------------------50022246920687 Content-Disposition: form-data; name="file"; filename="Lenna.png" Content-Type: image/png
応答として、ダウンロードしたファイルのURL文字列を取得し、それを確認してこれを確認できます。
"https://captionbot.blob.core.windows.net/images-container/2ogw3q4m.png"
次に、 /api/message既知のリクエストを送信し/api/message 。
{ "conversationId": "54cER5HILuE", "waterMark": "131071012038902294", "userMessage": "https://captionbot.blob.core.windows.net/images-container/2ogw3q4m.png" }
そのwaterMark 、前の回答のwaterMark 、URLはuploadメソッドから返されたものです。 応答データは以前のものと似ています。
ラッパーを書く
この知識を便利に使用するために、お気に入りのプログラミング言語で簡単なラッパーを作成します。 Pythonで行います。 サイトへのリクエストには、リクエストを使用します。これは便利で、Cookieを保存するセッションがあるためです。 サイトはSSLを使用しますが、デフォルトでは、リクエストは証明書を誓います:
hostname 'www.captionbot.ai' doesn't match either of '*.azurewebsites.net', '*.scm.azurewebsites.net', '*.azure-mobile.net', '*.scm.azure-mobile.net'
これは、各リクエストにverify = Falseフラグを設定することで解決されます。
完全なソース import json import mimetypes import os import requests import logging logger = logging.getLogger("captionbot") class CaptionBot: BASE_URL = "https://www.captionbot.ai/api/" def __init__(self): self.session = requests.Session() url = self.BASE_URL + "init" resp = self.session.get(url, verify=False) logger.debug("init: {}".format(resp)) self.conversation_id = json.loads(resp.text) self.watermark = '' def _upload(self, filename): url = self.BASE_URL + "upload" mime = mimetypes.guess_type(filename)[0] name = os.path.basename(filename) files = {'file': (name, open(filename, 'rb'), mime)} resp = self.session.post(url, files=files, verify=False) logger.debug("upload: {}".format(resp)) return json.loads(resp.text) def url_caption(self, image_url): data = json.dumps({ "userMessage": image_url, "conversationId": self.conversation_id, "waterMark": self.watermark }) headers = { "Content-Type": "application/json" } url = self.BASE_URL + "message" resp = self.session.post(url, data=data, headers=headers, verify=False) logger.debug("url_caption: {}".format(resp)) if not resp.ok: return None res = json.loads(json.loads(resp.text)) self.watermark = res.get("WaterMark") return res.get("UserMessage") def file_caption(self, filename): upload_filename = self._upload(filename) return self.url_caption(upload_filename)
ソースコードはGithubにあり、完成したパッケージはpipにあります。