ヘーゲルは、ニュースが宗教に取って代わると、社会は現代になると信じていました。
ニュース:ユーザーマニュアル、Alain de Botton
すべてのニュースを読むことは著しく不可能になりました。 そしてポイントは、スティーブン・ブシェミがレボウスキとボウリングの間にそれらを書いただけでなく、むしろそれらが多すぎるということです。 ここで、ニュースアグリゲーターが私たちの助けになり、当然、誰がどのようにアグリゲートするのかという疑問が生じます。
人気のニュースサイトMeduzaのAPIとデータ収集に関するHabré の 興味深い記事に気付いたので、 Perseusのシールドを明らかにし、輝かしいビジネスを続けることにしました。 Meduzaは多くのさまざまなニュースサイトを監視しており、今日では、どのソースが普及しているか、それらを有意義にグループ化できるかどうか、ニュースフィードのバックボーンを構成するコアがあるかどうかを把握します。
メデューサとは何かの簡単な定義:
「いつも愚かな人々が「テープ」と呼んでいたことを覚えていますか? 彼らは、「テープ」はアグリゲーターだと言いました。 そして、実際にアグリゲーターを作成しましょう」( Forbesインタビュー )
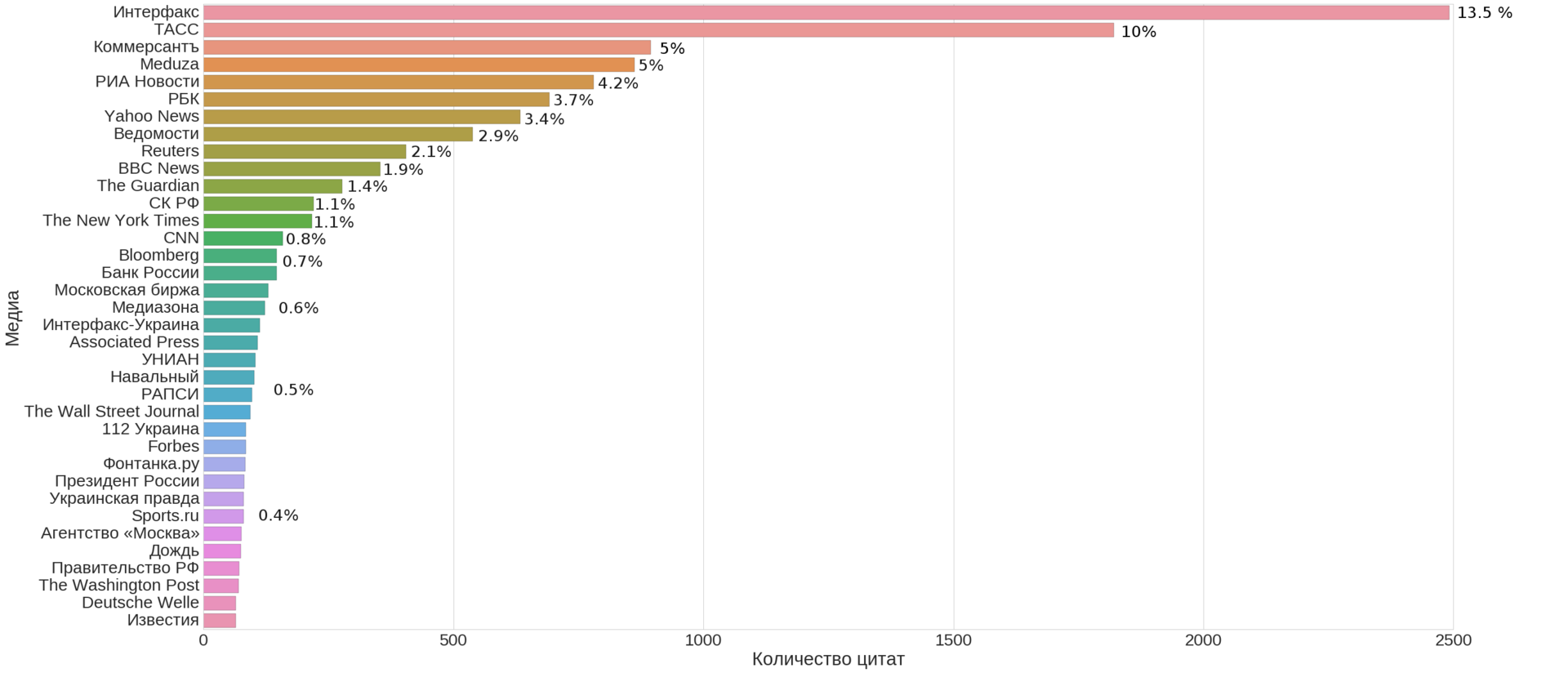
(これはKDPVだけでなく、メデューサのWebサイトに掲載されているニュースソースの数(彼女自身を含む)の上位35のメディアです)
質問を指定して形式化します。
- Q 1 :ニュースフィードの主要なソースは何ですか?
つまり、ニュースフィード全体を十分にカバーする少数のソースを選択できますか?
- Q 2 :それらに単純で解釈可能な構造はありますか?
簡単に言えば、ソースを意味のあるグループにクラスター化できますか?
- Q 3 :この構造からアグリゲーターの一般的なパラメーターを決定することは可能ですか?
ここでの一般的なパラメーターの下では、時間内のニュースの数などの量を意味します
ソースは何ですか?
例として、各ニュースサイトには、以下に赤でマークされた特定のソースがあります。
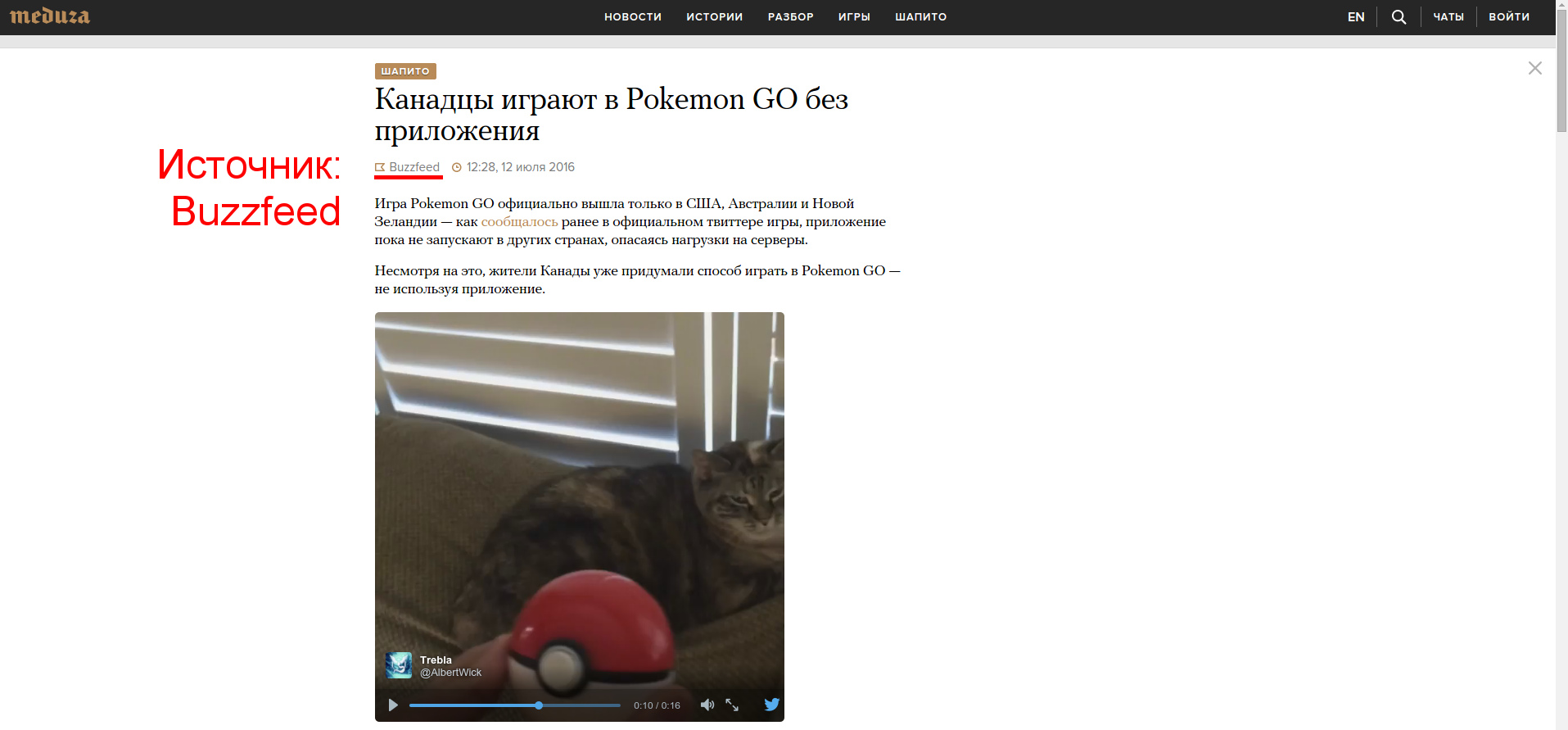
今日私たちにとって特に興味深いのは、このパラメーターです。 分析のために、すべてのニュースのメタデータを収集する必要があります。 これを行うために、Meduzaにはお客様のニーズに使用できる内部APIがあります。以下のリクエストでは、最新の10のロシア語ニュースが返されます。
https://meduza.io/api/v3/search?chrono=news&page=0&per_page=10&locale=ru
このHabraの記事とAPIの簡単な説明と同様のリクエストに基づいて、データをダウンロードするためのコードを取得します
ParsimおよびAPIを介してMeduza.ioから投稿をダウンロード import requests import json import time from tqdm import tqdm stream = 'https://meduza.io/api/v3/search?chrono=news&page={page}&per_page=30&locale=ru' social = 'https://meduza.io/api/v3/social' user_agent = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.3411.123 YaBrowser/16.2.0.2314 Safari/537.36' headers = {'User-Agent' : user_agent } def get_page_data(page):
調査のデータがどのように見えるかの例:
ニュース投稿のいずれかのメタデータの例 affiliate NaN authors [] bg_image NaN chapters_count NaN chat NaN document_type news document_urls NaN full False full_width False fun_type NaN hide_header NaN image NaN keywords NaN layout_url NaN live_on NaN locale ru modified_at NaN one_picture NaN prefs NaN pub_date 2015-10-23 00:00:00 published_at 1445601270 pushed False second_title NaN share_message NaN social {'tw': 0, 'vk': 148, 'reactions': 0, 'fb': 4} source sponsored NaN sponsored_card NaN table_of_contents NaN tag {'name': '', 'path': ''} thesis NaN title topic NaN updated_at NaN url news/2015/10/23/rostrud-ob-yavil-o-prekraschen... version 2 vk_share_image /image/share_images/16851_vk.png?1445601291 webview_url NaN with_banners True fb 4 reactions 0 tw 0 vk 148 trust 3 Name: news/2015/10/23/rostrud-ob-yavil-o-prekraschenii-rosta-bezrabotitsy, dtype: object
この記事のデータは2016年7月中旬に収集され、{git}から入手できます 。
ドキュメントの種類とソースの信頼性
次の簡単な質問から始めましょう。利用可能なすべてのドキュメントの中でニュースの割合はどのくらいで、どのような種類のドキュメントがあるのでしょうか?
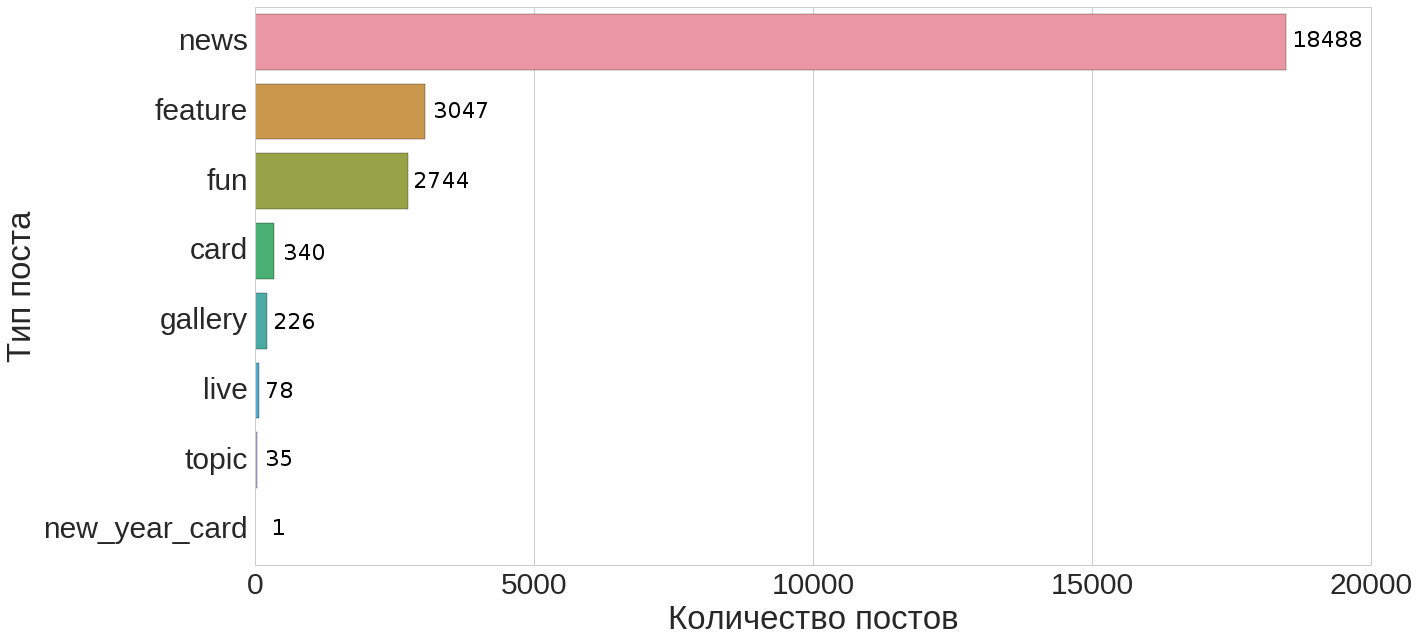
この配布から(便宜上、以下にこの配布の表形式のプレゼンテーションがあります)、ニュースが全文書の約74%を占めていることがわかります。
次に、ニュースに焦点を当て、例として、ニュースのみに適用される「ソースの信頼性」パラメーターを検討します。
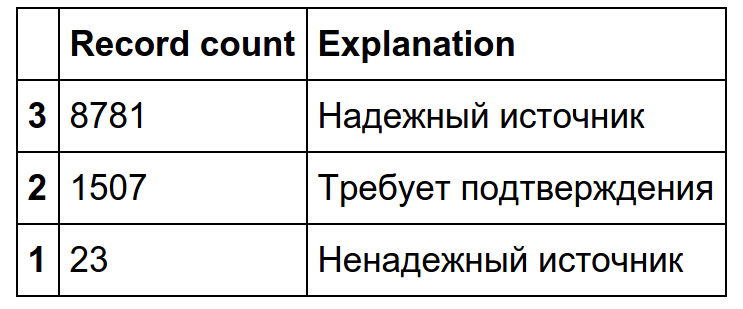
ご覧のように、事実上すべてのニュースは「信頼できるソース」または「確認が必要」のカテゴリに分類されます。
ソース分析とクラスタリング
最初のグラフ(記事の冒頭)で、いくつかのトップソースが重要な貢献をしていることがわかります。 約100個のリンクを占めるソースを取得し、それらの構造を見つけようとします。
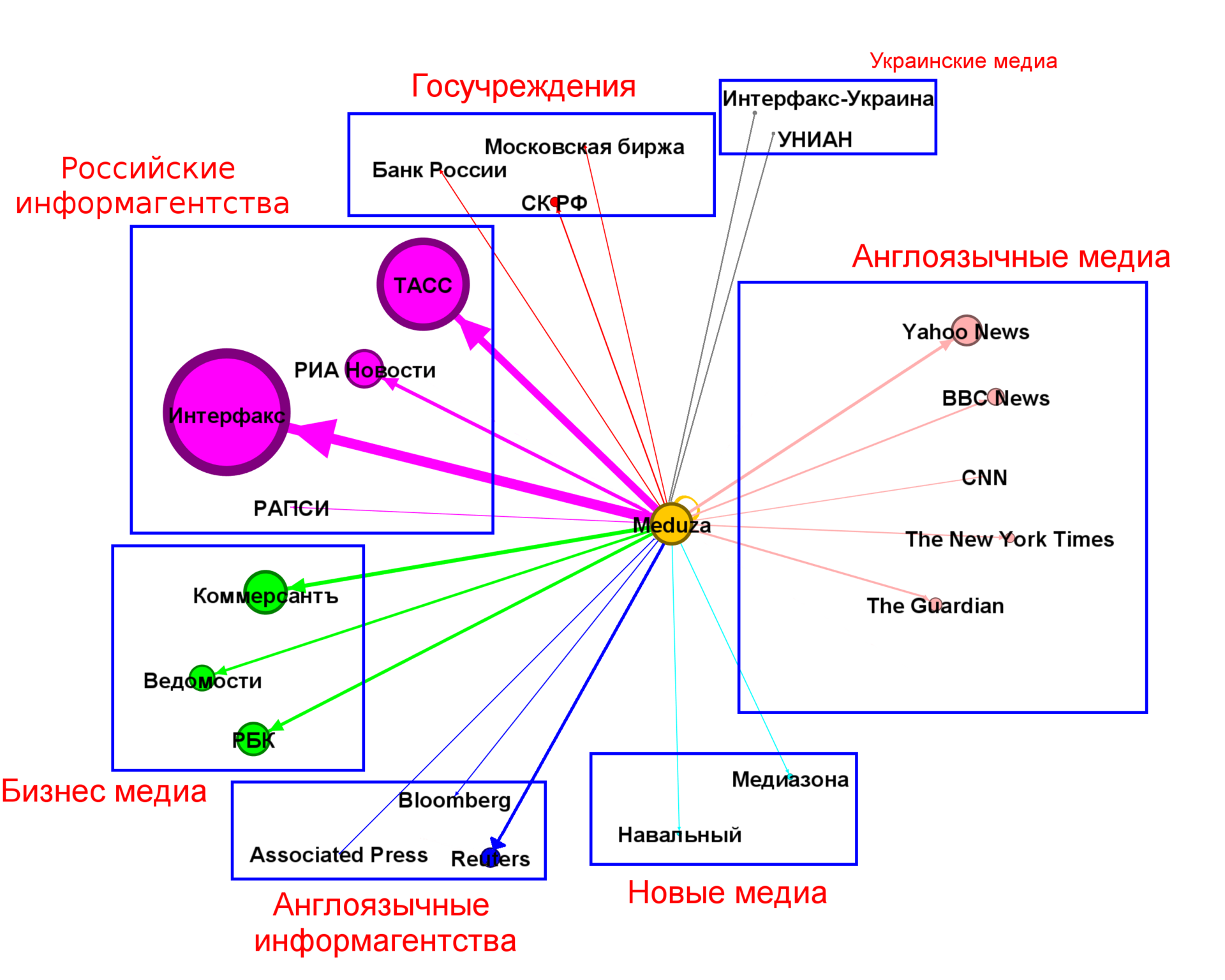
(頂点と弧のサイズはリンクの数に比例します)
もちろん、クラスターの数とパーティション自体は異なる場合があり、主に主観的です。
上記のグラフから、最大の貢献はロシアの報道機関が全ニュースの約30%を占め、次にビジネスメディアが約11.5%、次に英語メディアの翻訳が約8.5%、世界の報道機関が約3.5%であることがわかります。 合わせて、これらの4つのクラスターはほとんどのニュースをカバーしています(50%+)。 残りのクラスターは3%未満です。 著者の資料(出典:Meduza自体)は約5%です。
出版物の総数の分析
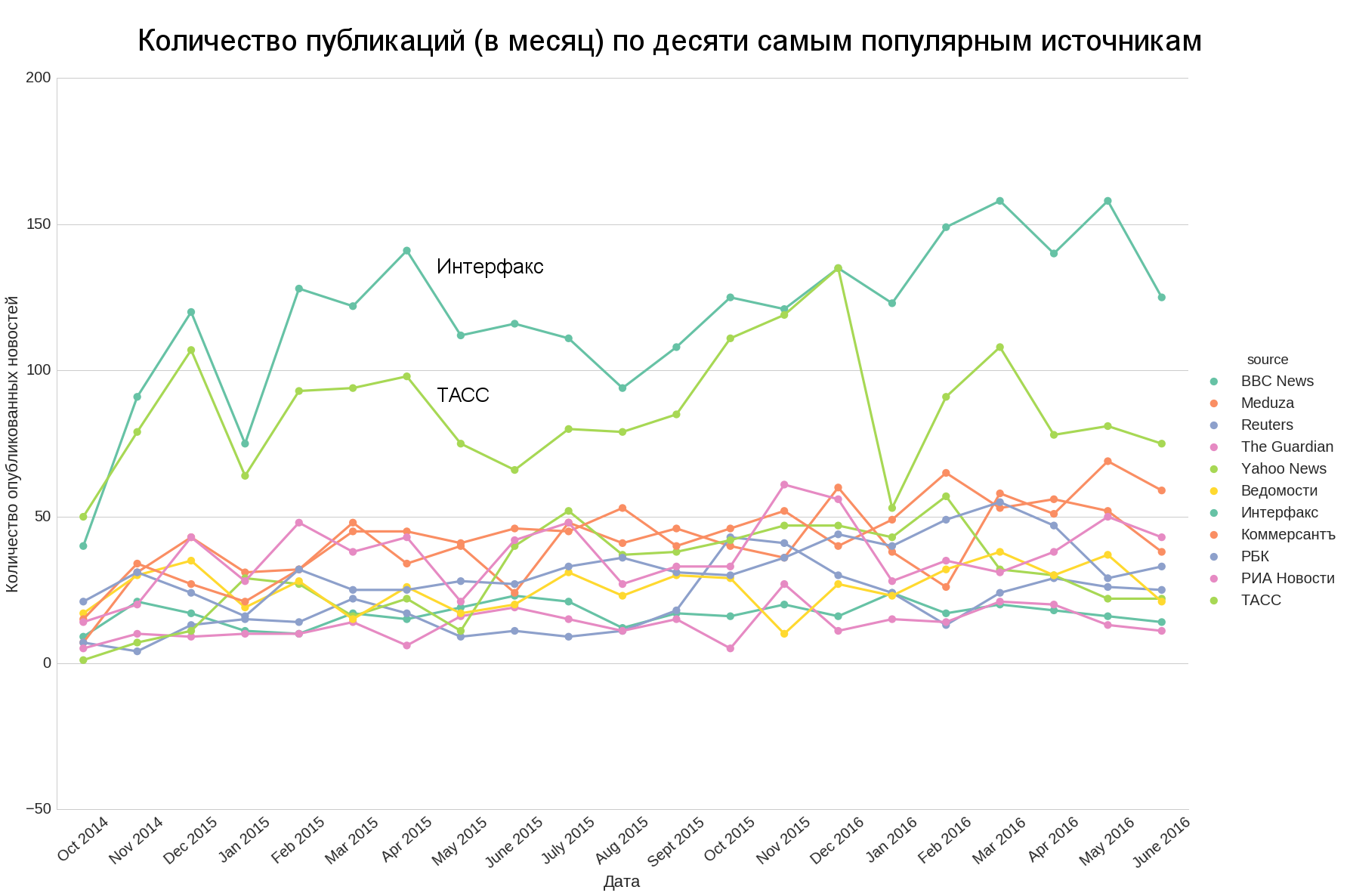
また、興味深いのは、さまざまなソースからのニュースの数が時間的にどれだけ匹敵するか、トップ(たとえばトップ10)を取得し、そこからのニュース全体の一般的な傾向を推定できるかどうかです。
TASSとInterfaxだけがトップの他の部分と定量的に大きく異なり、他のソースは互いに定量的にかなり近いことがわかります。
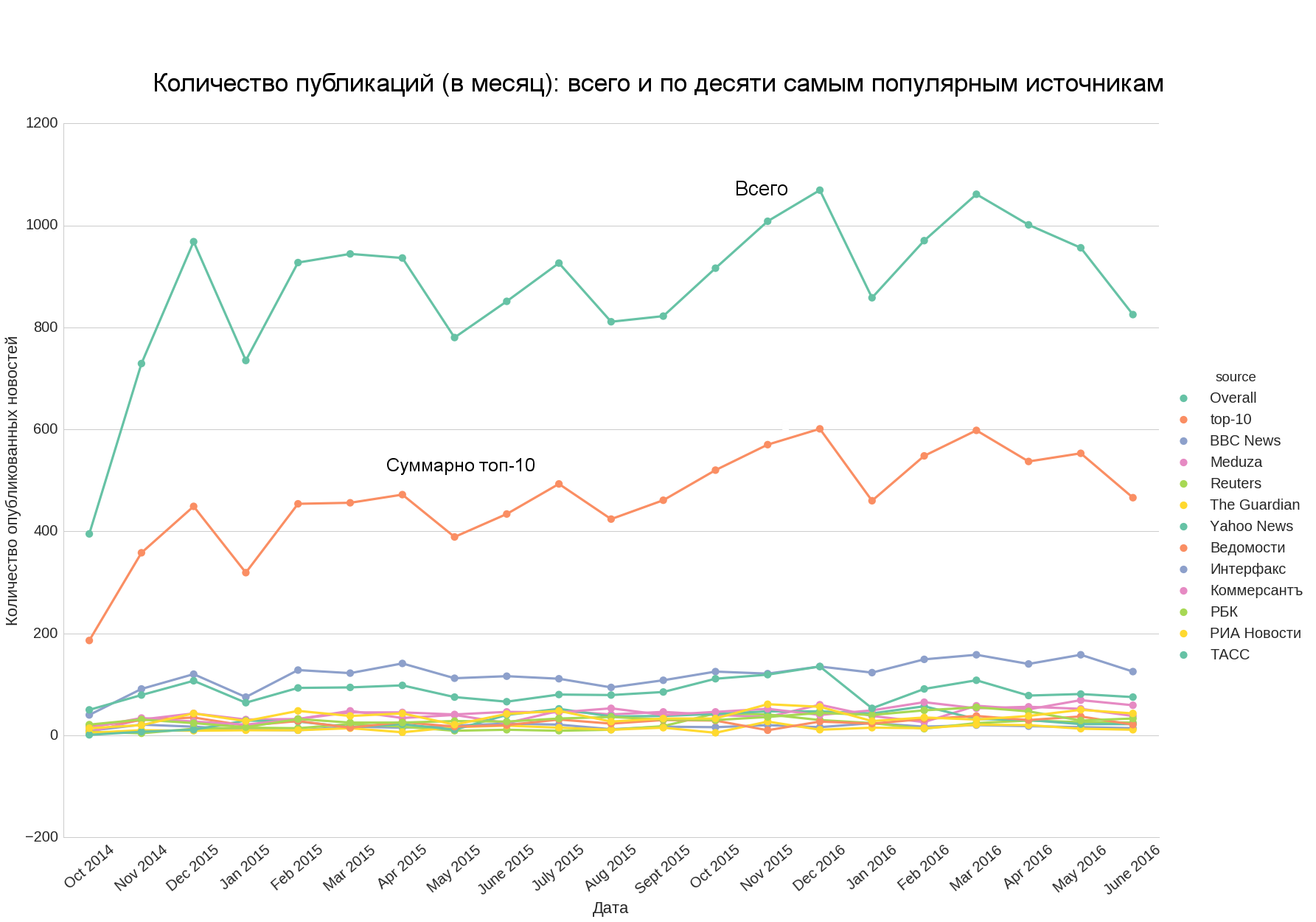
トップ10とニュースの総数を追加すると、最初のニュースが2番目のウェルに近似していることに気付くでしょう。つまり、トップ10のニュースの数がニュースの総数の良いアイデアを与えています。
Medialogyとの比較
この部分のデータとグラフはここから取得されます 。
そのようなサンプルがネットワーク上のニュースの全体的な引用評価とどのように相関するかを見るのは興味深いです。 2016年5月のメディアロジーの利用可能なデータを考慮してください。
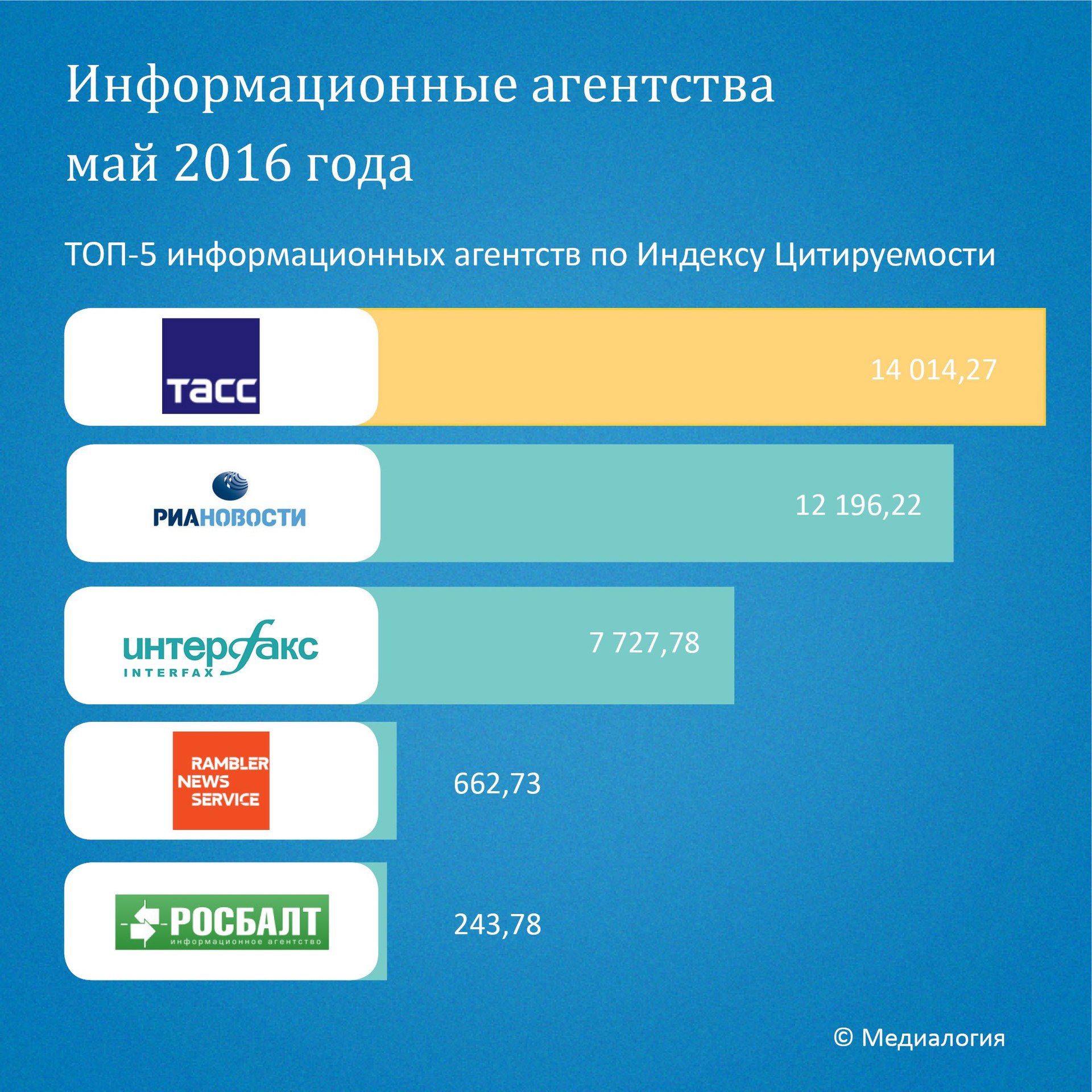
一般的に、3つは最上部で同じ順序で表示されますが、順序は異なります(非常に自然なことですが、アグリゲーターは、それ自体がバイラルであり、重要な注目に値しないと考えられるため、必ずしも引用されたニュースをそれ自体にもたらすとは限りません) 、または信頼性の低いソースに起因する-これはニュースの信頼性の分布と一致しています)。
結論とデータ参照
論文、対処された問題に関する結論:
Q 1 :大部分のニュースを構成する上位10〜15のニュースソース:ロシアの報道機関とビジネスメディア、および有名な国際報道機関とメディアの翻訳(すべてのニュースの半分以上)-最初のチャートを参照してください。
Q 2 : 7つのクラスターがトップソースで識別されます。上記の4つの主要クラスター( Q 1 )は、ほとんどのトップソースとほとんどのニュース自体をカバーします。「ソースの分析とクラスタリング」セクションのチャートを参照してください。
- Q 3 :上位10のソースを使用すると、ニュースアグリゲーターの数の全体的な傾向を時間内に評価できます-セクション「パブリケーションの総数の分析」のグラフを参照してください。
データ(関連性-2016年7月中旬)はgitリポジトリで利用可能です 。