 パーサーの平均品質(7つのサイト)
パーサーの平均品質(7つのサイト)私は提案する:
- Apache.JMeter htmlパーサーを使用して、埋め込みリソースへのリンクを抽出する完全性の平均品質を計算します。
- Apache.JMeter 3.0のリンク抽出がより完全になったかどうかを確認してください。
- CsvLogWriterプラグインを試してください。
人気のある知恵が言うように:信じるが...
プロジェクトの説明
Apache.JMeter 3.0がリリースされたとき、それはまだ開発中であり、同僚であり、私はそれをテストし、仕事でそれを使用し始めました。 Artyom
zetsigemonは、新しいサービス
pgu.mos.ruのいずれかの戦闘テストで最初に新しいバージョンを使用しました
。Apache.JMeter3.0を使用すると、組み込みリソースの解析の品質が前のバージョンに比べて大幅に向上しました。
そして、疑問が生じました。この品質とは何ですか、異なるサイトでどのように測定するのか、それは何で、何になったのですか?
研究の資料と結果は、現在の記事に反映されています。
テスト対象
HtmlParsersは、
Apache.JMeter 2.13および
Apache.JMeter 3.0でテストされています。
パーサー
Apache.JMeter 2.13 :
- LagartoBasedHtmlParser;
- HtmlParserHTMLParser;
- JTidyHTMLParser;
- RegexpHTMLParser;
- JsoupBasedHtmlParser。
Apache.JMeter
3.0を解析し
ます 。
- LagartoBasedHtmlParser;
- JTidyHTMLParser;
- RegexpHTMLParser;
- JsoupBasedHtmlParser。
パーサーは、さまざまなWebサイトの開始ページを解析します。
- stackoverflow.com;
- habrahabr.ru;
- yandex.ru;
- mos.ru;
- jmeter.apache.org;
- google.ru;
- linkedin.com;
- github.com。
テストの基礎
基礎は
Apache.JMeter 3.0の変更
でした。http : //jmeter.apache.org/changes.htmlを参照してください。
変更のリストからの抜粋:コアの改善
依存関係の更新
廃止されたライブラリは、最新のものにドロップまたは置き換えられました:
- htmllexer、htmlparserが削除されました
- 削除されたjdom
htmlparserパーサーとより多くの未使用のjdomライブラリを削除しました。
プロトコルと負荷テストの改善
並列ダウンロードが現実的になり、スケールが大幅に改善されました。
- CSSインポートされたファイル( インポートを介して)または埋め込みリソース(背景、画像など)の解析
CSSファイル用の新しいパーサーが追加され、他のCSSファイルへのリンク( インポートを介して)およびCSSファイルで指定されたリソースへのリンクが抽出されます:背景画像、画像、...
互換性のない変更
- バージョン3.0以降、htmlparserライブラリ(HtmlParserHTMLParser)に依存していた埋め込みリソースのパーサー(2.10以降はLagartoベースの実装に置き換えられました)は、その依存関係とともに削除されました。
- 次のjarは削除されました。
htmlparserパーサーと、未使用のhtmllexerおよびjdomライブラリーを 削除しました 。
改善点
HTTPサンプラーとテストスクリプトレコーダー
- バグ59036 -FormCharSetFinder:非推奨のHTMLParserの代わりにJSoupを使用
- バグ59033-並列ダウンロード:異なるMIMEタイプのプラグインパーサーを許可するようにパーサークラスの階層を作り直しました
- Bug 59140-並行ダウンロード:CSSファイルからリンクを抽出するCSS解析を追加
formタグのaccept-charset属性を検索するために、リモートHTMLParserの代わりにJSoupが使用されるようになりました [バグ59036]。 CSSファイルパーサー[バグ59140]を実装し、デフォルトでこのパーサーが使用されます[バグ59033]。
テストの目的
利用可能なすべてのパーサーの作業を比較します。 特に、バージョン2.13と3.0のパーサーを相互に比較し、組み込みリソースのロードがより現実的で良くなっていることを確認してください。
戦略
ステージ1:
- 5つのApache.JMeter 2.13パーサーをすべて使用して、サイトリストの開始ページをダウンロードし 、ログを記録します。
- 4つのApache.JMeter 3.0パーサーをすべて使用してサイトリストの開始ページをダウンロードし、ログを書き込みます。
- Apache.JMeterログを分析し、互いに比較します。 埋め込みリソースの読み込みが改善されたかどうか、読み込まれた埋め込みリソースのリストが拡張されたかどうかを評価します。
ステージ2:
- Google Chromeとwebpagetest.orgサービスを使用して、人気サイトのリストの開始ページをダウンロードします。
- webpagetest.orgからのレポートを分析し、 Apache.JMeterログの分析結果と比較します。 組み込みリソースのロードのリアリズムを評価します。
テストアプローチ
Apache.JMeterからサイトページを開くときに送信されるリクエストの正確な数を判断するために
、すべてのリクエストがログに記録されます。
- 結果ツリーの表示 -標準ロガー、サブクエリのロギングを伴うXML形式でのロギング、XMLログを使用してリクエスト/レスポンス/エラーの詳細を確認します。
- CsvLogWriter-カスタムロガーhttps://github.com/pflb/Jmeter.Plugin.CsvLogWriter 、サブクエリのロギングを伴うCSV形式でのロギング、CSVログはさまざまなパーサーの動作に関する統計をプログラムで計算するために使用されます。
- 定量的評価のみが実行され、サブクエリのアドレスは参照によって計算されません。
Apache.JMeterのバージョン、パーサー、およびサイトごとにリクエストをグループ化できるように、各リクエストの追加変数がログに記録されます。
- siteKey-テスト中のサイト。
- jmeterVersion - Apache.JMeterのバージョン。
- htmlParser-現在使用中のhtmlパーサーの名前。
結果
バージョン2.13と比較したバージョン3.0のパーサーの改善の評価
htmlページの解析の完全性に根本的な改善はありませんが、劣化があります。
重要な違いは、Apache.JMeter 3.0のパーサーでは、Yandexブラウザーブラウザーのプロモーションページの再帰的な読み込みがあることです。 これは
https://yandex.ru/をダウンロードするときに現れ
ます 。
コンテンツの量が少ないサイト-良い結果
jmeter.apache.orgのような単純なサイトでは、すべてのパーサーが同じように機能します。 ブラウザが作成するサブクエリと同じ数を作成します。
jmeter.apache.orgのパーサーの品質は完璧で、100%です。
コンテンツが多いサイトは悪い結果です
しかし、mos.ruのようなサイトでは、パーサーは埋め込みリソースへの平均22リンクを見つけますが、すべてのブラウザー埋め込みリソースが読み込まれたページ全体の読み込みには144のリクエストがあります。 品質が悪い。
同様に、
habrahabr.ru Webサイトでは、
Apache.JMeter 3.0の
Lagardoパーサーは55個のリンクを見つけ、ブラウザーは117個のサブクエリを作成します。 品質-47.01%。 埋め込みリソースへのリンクを抽出するための十分な品質。
さまざまなパーサーを使用するときのサブクエリの数
Googleドキュメントの表:
JMeter.HtmlParser.Compare(上の表)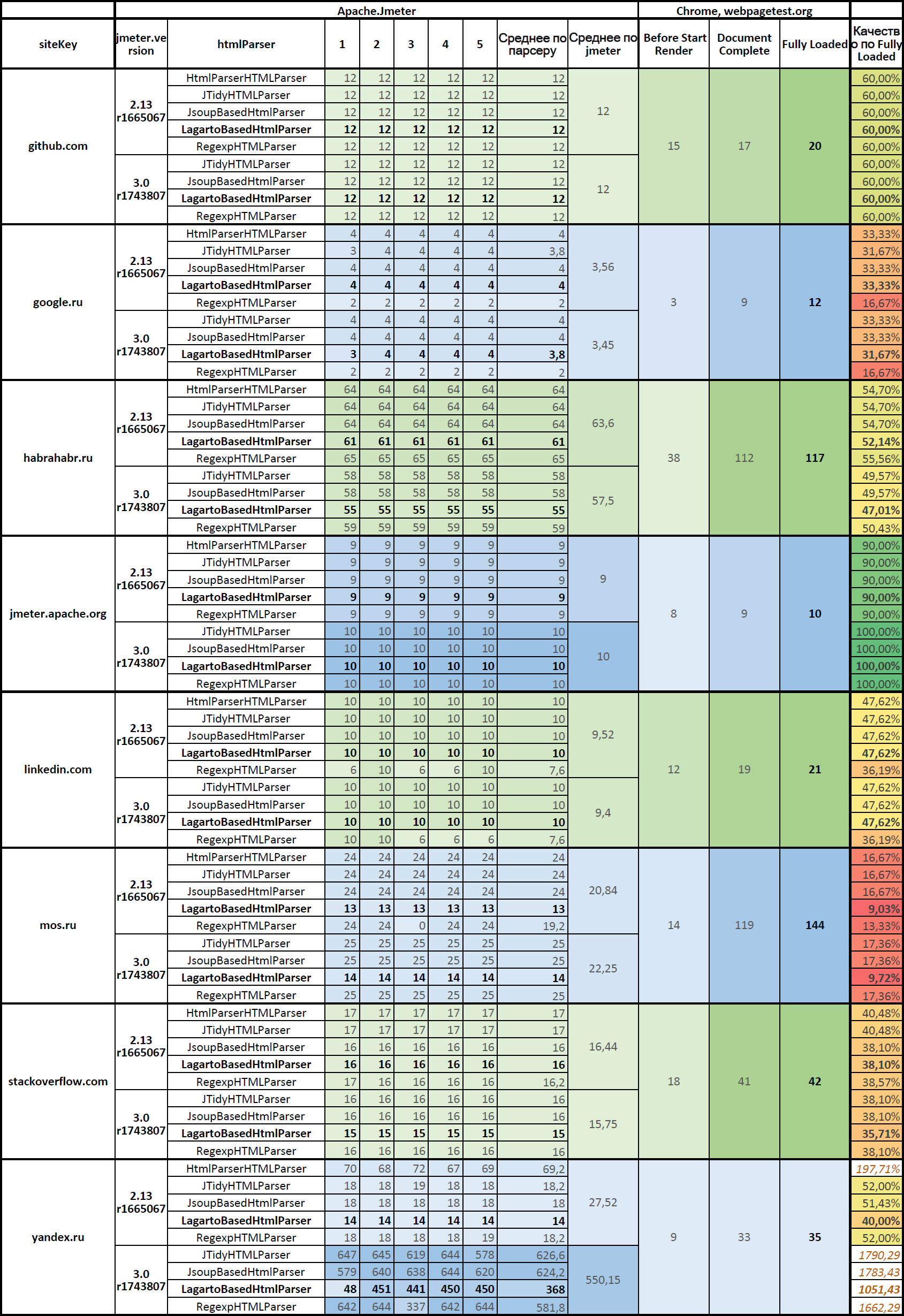 バージョンおよびhtmlパーサーのコンテキストでのApache.JMeterの動作の統計、およびGoogle Chromeの動作との比較
バージョンおよびhtmlパーサーのコンテキストでのApache.JMeterの動作の統計、およびGoogle Chromeの動作との比較列の説明:
- レンダリングの開始前 -ページのコンテンツの表示を開始する前にブラウザによって行われたサブクエリの数。 これらは、htmlマークアップ、メインのjsおよびcssファイル、メインの画像です。
- ドキュメントの完了 -ドキュメントが完全にロードされたときにブラウザが作成したサブクエリの数。 ここでは、すべてのページリソースが既にロードされています。
- 完全にロード -すべてがロードされたときに、javascriptが機能したときにブラウザによって行われたサブクエリの数。
Document Completeの時点で
Google Chromeブラウザーと同じ数のサブクエリがあり、
Fully Loadedの時点で素晴らしい場合、パーサーはうまく
機能します。 特定のパーサーを使用する場合、
Apache.JMeterのリアリズムの尺度
として、Fully Loadedの時点でブラウザーが実行したサブクエリの数に対するサブクエリの数の近さを考慮します。
サイトyandex.ruのテスト結果を除外する場合、ここで:
- 解析は再帰に入り、再帰の深さが最大レベルに達して失敗するまでyandex.ruに何度もリクエストを行います。
> java.lang.Exception: Maximum frame/iframe nesting depth exceeded 。
そして、パーサーの品質の尺度として、
Fully Loadedの時点でサブクエリの数を取得し、パーサーの平均品質のこのようなテーブルを取得します。
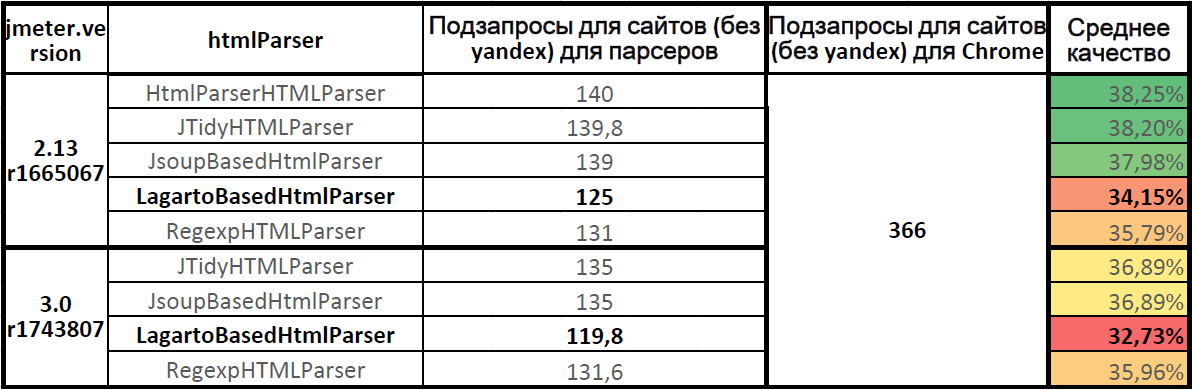
パーサーの平均品質
Googleドキュメントの表:
JMeter.HtmlParser.Compare(下の表) 。
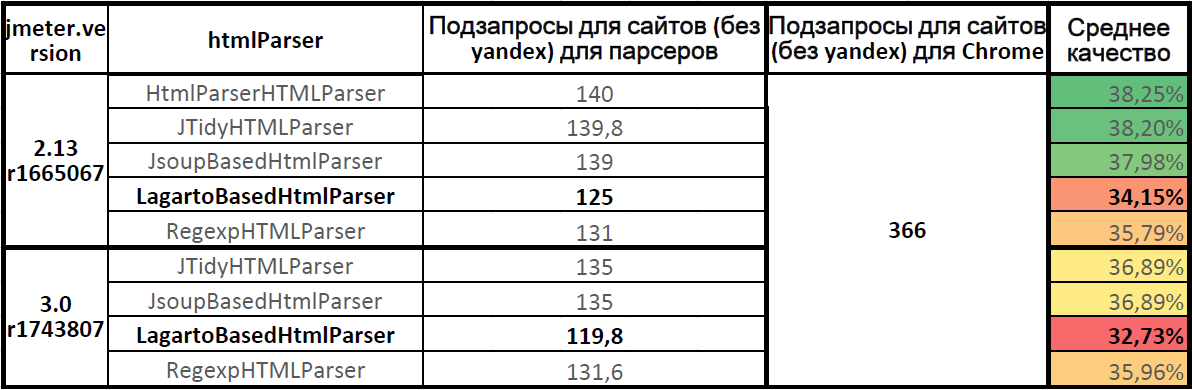 パーサーの平均品質(yandex.ruなしの7つのサイト)Apache.JMeter
パーサーの平均品質(yandex.ruなしの7つのサイト)Apache.JMeter 2.13で最も正確な
HTMLParserパーサー。
Apache.JMeter 3.0では、
Jsoupパーサーと
JTidyパーサーは同じ品質を示しました。
Lagartoパーサーはリーダーに遅れをとっています。
Apache.JMeter 3.0の
Lagartoパーサーの解析の完全性は、
Apache.JMeter 2.13と比較して低下しています。
Apache.JMeter 3.0の現在のバージョンでの
Lagartoパーサーの品質は32.73%で、すべてのサブクエリの3分の1のみが送信され、
静的関数の 3分の2の負荷は送信されませんでした。
habrahabr.ruのApache.JMeter 3.0を使用する場合のスキップされたリンクの詳細な分析
Googleドキュメントの表:
デフォルトのパーサーApache.JMeter 3.0にないhabrahabr.ruへのリンクの欠落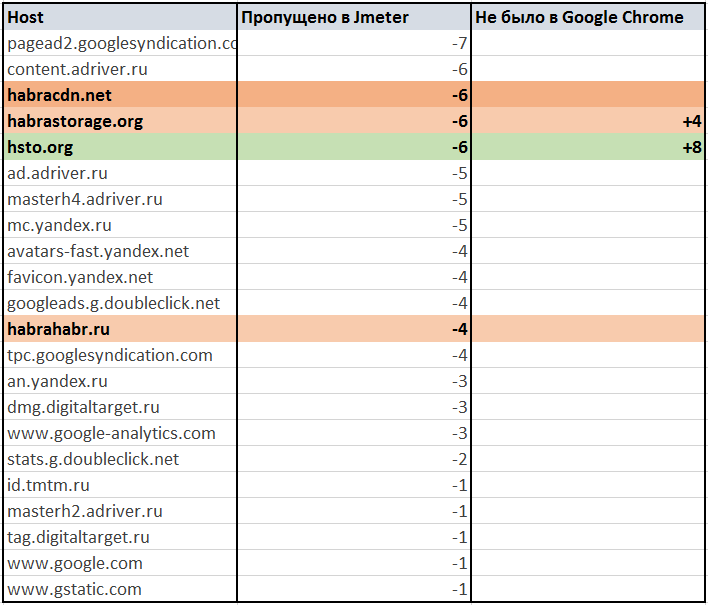 Apache.JMeter 3.0の解析リンクの欠落habrahabr.ru
Apache.JMeter 3.0の解析リンクの欠落habrahabr.ru多くの販促資料と統計を逃しました。 そしてそれは良いことです。
量的特性のみを評価することはすでに上で述べました。 数字で見ると、埋め込みリソースへのリンクを抽出する品質が低いことがわかります。 詳細な分析により、正確に見逃されたものが示されることがあります。 これは、サードパーティのリソースからの広告とコンテンツであることが判明する場合がありますが、特定のサイトの負荷テストの一部として読み込む必要はありません。
ログとその処理
ソースデータ
すべてのログは
https://drive.google.com/drive/folders/0B5nKzHDZ1RIiVkN4dDlFWDR1ZGMで入手でき
ます 。
WebPageTest.orgレポート
レポート画像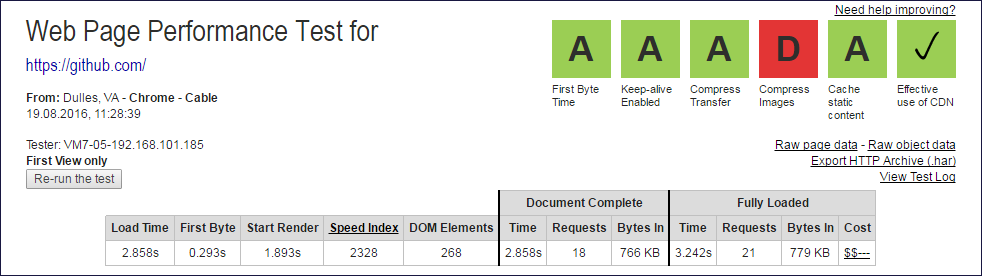
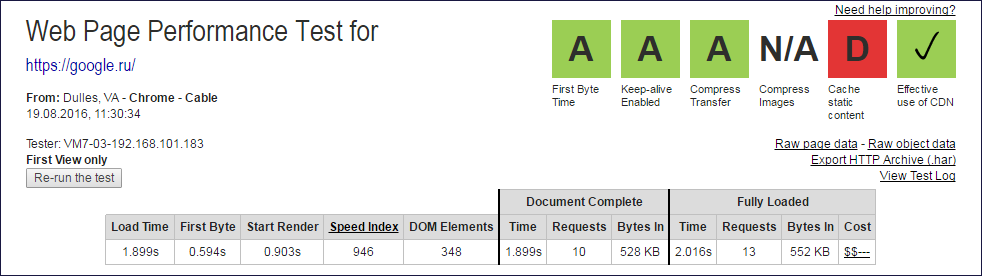
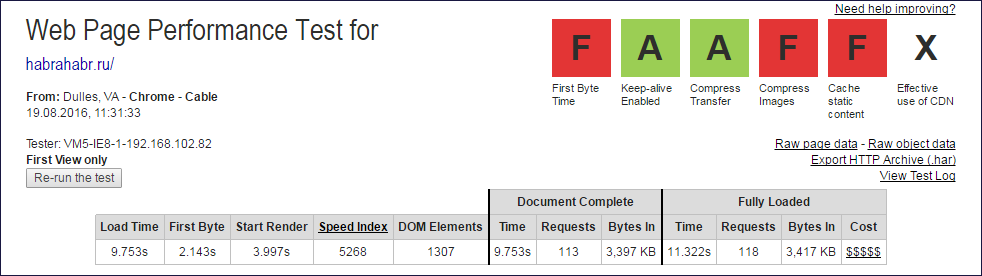
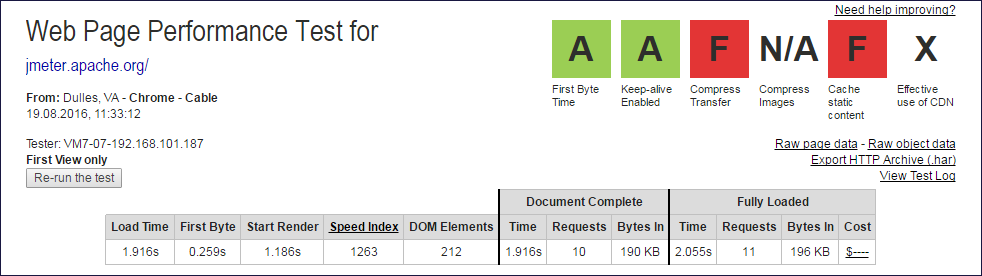

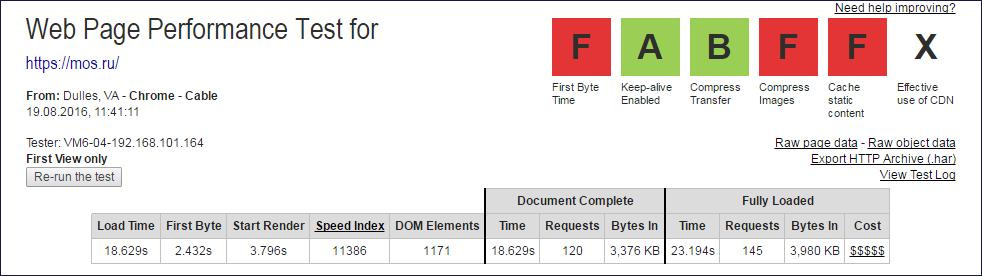

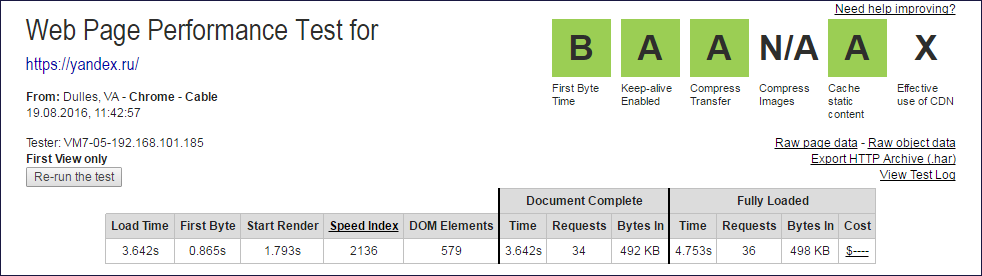 Document CompleteおよびFully Loadedデータが抽出されたWebpagetest.orgレポートの上限
Document CompleteおよびFully Loadedデータが抽出されたWebpagetest.orgレポートの上限 Document Complete列と
Fully Loaded列の値から、サブクエリの数を取得するために1つのクエリ(ルート)を除外する必要があります。
ログApache.JMeter
処理には、
CsvLogWriterプラグインによって生成されたcsvログが
使用されます。
サードパーティのプラグインを使用して、埋め込みリソースのリクエストがcsvログに記録されるようにします。
CsvLogWriter操作の結果、ログが生成され、その列のリストには以下が含まれます。
- timeStamp-特定時点;
- URL-リクエストアドレス;
- 経過 -要求に対する応答の期間。
- バイト -応答サイズ。
- siteKey-使用済みサイト。
- htmlParser-使用される名前。
- jmeterVersion - Apache.JMeterの使用バージョン。
- iはテストの反復回数です。
ログ処理の自動化
Apache.JMeter csvログの集約は、次の
Pythonコードで
パンダを使用して実行されます。
import pandas as pd import codecs from os import listdir import numpy as np
yandex.ruでの再帰的な読み込み
 yandex.ruのデフォルト設定(Lagarto htmlパーサー)を使用した現在のバージョンのApache.JMeter 3.0の埋め込みリソースの再帰的な読み込み
yandex.ruのデフォルト設定(Lagarto htmlパーサー)を使用した現在のバージョンのApache.JMeter 3.0の埋め込みリソースの再帰的な読み込み見られるように:
- Apache.JMeterは、
https://yandex.ru/clck/redir/dtype=stred....7004fcb3793e79bb1ac9e&keyno=12 //yandex.ru/clck/redir/dtype=stred....7004fcb3793e79bb1ac9e&keyno=12のリンクを見つけて追跡しhttps://yandex.ru/clck/redir/dtype=stred....7004fcb3793e79bb1ac9e&keyno=12 - 次に、新しい一意のリンク
https://yandex.ru/clck/redir/dtype=stred....cd1c46cad58fbfe2f61&keyno=12を見つけhttps://yandex.ru/clck/redir/dtype=stred....cd1c46cad58fbfe2f61&keyno=12 - など、再帰になります。
この場合、これはYandex Browserをダウンロードするためのリンク内の画像です。
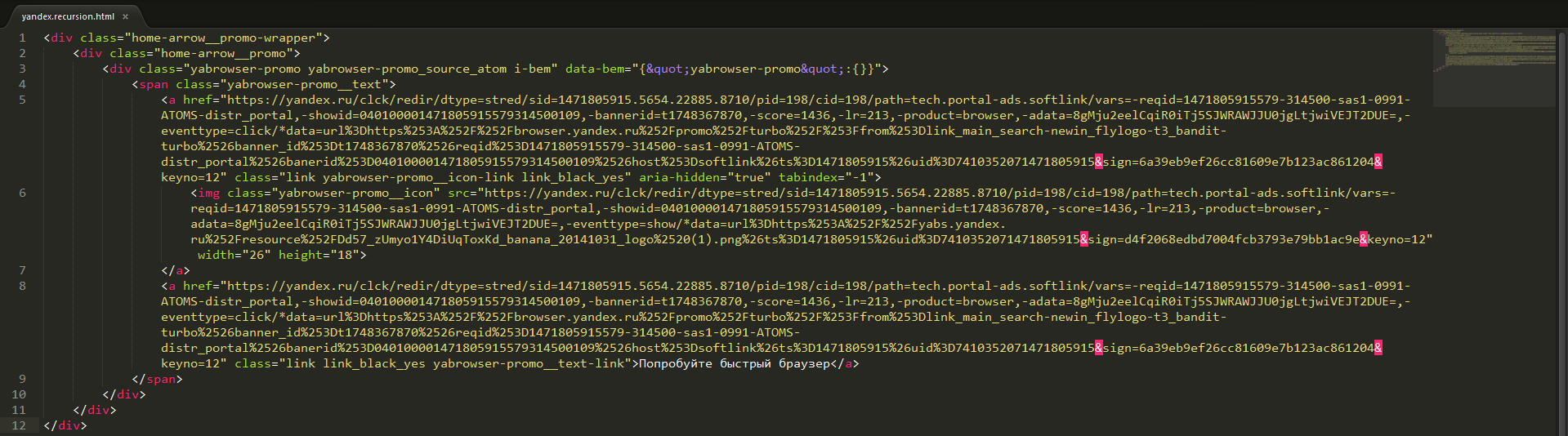 Yandex Browserをダウンロードするための再帰、リンク、および画像の新しいステップを追加するサイトyandex.ru処理のhtmlコードのフラグメント
Yandex Browserをダウンロードするための再帰、リンク、および画像の新しいステップを追加するサイトyandex.ru処理のhtmlコードのフラグメントパーサーは画像を見つけます。 JMeterはそれをダウンロードしようとしますが、それに応答してhtmlページを受信すると、再び写真へのリンクと他のリンクがあります。 そして、すべてが繰り返されます。
Apache.JMeterの動作
は正しいです。
また、
Apache.JMeter 2.13では、再帰は
HtmlParserパーサーでのみ発生し、他では発生しない理由を推測します。
- リンクの長さに制限があり、リンクの一意の端が切断されるため、再帰は発生しません。
- または、 Apache.JMeter 2.13では、パーサーで何かが正しく機能しません。
- またはApache.JMeter 2.13では、何かが正しく回避されます-Cookie 、他の何か、Yandexサーバー自体が応答し、再帰にならないようにします。たとえば、新しいhtmlページではなく、画像リクエストに画像で応答します。
推測しません それは絶望的な状況のようです。 しかし、そのような状況はありません。 常に解決策があります。
たとえば、Yandex Browserを
User-Agentとして指定してみてください。 サーバーは、おそらく、ブラウザをダウンロードするための画像を表示しないか、画像リクエストに画像で応答し、再帰はありません。 これは予感です、テストしませんでした。
これで、スクリプトはwebpagetest.orgの操作と同期するためにGoogle Chromeの
User-Agentを指定し、サーバーはブラウザではなく、独自のリンクを提供しているようです。
プロジェクト構成
- jmeter.testfile.jmx-入力としてパラメーターを取るApache.JMeter 2.13およびApache.JMeter 3.0のテストスクリプト:
URLテストされたサイトのアドレス、たとえばhttps://yandex.ru/ ;siteKey 、ログ内のエントリのグループ化が実行される行。loopCountテストの反復回数loopCountサイトの動作が不安定になる可能性があるため、いくつかの反復が使用されます。htmlParser.className埋め込みリソースへのリンクを抽出するパーサー。- スクリプトを機能させるには、追加のCsvLogWriterプラグインをダウンロードしてインストールする必要があります。
- jmeter.3.0.bat - Apache.JMeter 3.0のテストを実行するコマンドファイル、ここでは/bin/Apache.JMeter 3.0フォルダーへのパス、テストスクリプトjmeter.testfile.jmxへのパス、テストを開始するためのオプション、およびhtmlParsersチェックのリスト作業が実行されている人。
- jmeter.2.13.bat - Apache.JMeter 2.13のテストを実行するコマンドファイル、ここでは
/bin/ Apache.JMeter 2.13フォルダへのパス、テストスクリプトjmeter.testfile.jmxへのパス、テストを開始するためのオプション、およびhtmlParsersチェックのリストが設定されます作業が実行されている人。
- test.bat - Apache.JMeterの 2つのバージョン、2.13および3.0でテストを実行するコマンドファイル。このファイルには、テストの反復回数とテスト対象のサイトのアドレスが含まれています。 ファイルはjmeter.2.13.batおよびjmeter.3.0.batファイルを呼び出します 。
- jmeter.3.0.vs.jmeter.2.13.ipynb - Apache.JMeterのログを分析するためのjupyter用のメモ帳。
- statistics.xlsx-パーサーの作業に関する統計情報を含むテーブル、調査の結果。
テストは自分で簡単に変更でき、サイトと適切な反復回数を指定します。 すべての設定は
test.batファイルで設定されます。
CALL jmeter.2.13.bat http://stackoverflow.com/ 5 stackoverflow.com CALL jmeter.2.13.bat https://habrahabr.ru/ 5 habrahabr.ru CALL jmeter.2.13.bat https://yandex.ru/ 5 yandex.ru CALL jmeter.2.13.bat https://www.mos.ru/ 5 mos.ru CALL jmeter.2.13.bat http://jmeter.apache.org/ 5 jmeter.apache.org CALL jmeter.2.13.bat https://www.google.ru/ 5 google.ru CALL jmeter.2.13.bat https://www.linkedin.com/ 5 linkedin.com CALL jmeter.2.13.bat https://github.com/ 5 github.com CALL jmeter.3.0.bat http://stackoverflow.com/ 5 stackoverflow.com CALL jmeter.3.0.bat https://habrahabr.ru/ 5 habrahabr.ru CALL jmeter.3.0.bat https://yandex.ru/ 5 yandex.ru CALL jmeter.3.0.bat https://www.mos.ru/ 5 mos.ru CALL jmeter.3.0.bat http://jmeter.apache.org/ 5 jmeter.apache.org CALL jmeter.3.0.bat https://www.google.ru/ 5 google.ru CALL jmeter.3.0.bat https://www.linkedin.com/ 5 linkedin.com CALL jmeter.3.0.bat https://github.com/ 5 github.com
さらに、カスタマイズされた数式を使用して、Excelファイルから結果を挿入し、結果の視覚的な表を取得できます。
パーサーをファイナライズして、同様の手法で、埋め込みリソースの解析の品質の向上を監視できます。
結論
この記事には特に実用的な価値はありません。 しかし、いくつかの有用な結論を出すことができます。
- パーサーは、平均してリソースの3分の1へのリンクのみを取得します。
- パーサーはほぼ同じように機能します。つまり、任意のものを使用できます。
- パーサーは、jmeter.apache.orgなどの単純なサイトで動作するように調整されています。
- コンテンツが多いサイトでは、パーサーの動作は実際のブラウザーよりもはるかに悪くなります。
- JMeterの新しいバージョンでの埋め込みリソースのロードの完全性はわずかに低下しましたが、増加しませんでした(選択したサイト)。
- 私の同僚のAlexandra Sanchez92が作成したCsvLogWriterプラグインのアプリケーションでの使用例を示しました。 このプラグインは、埋め込みリソースへのリクエストをcsvログに記録します。
- batファイルを使用して、コマンドラインからJMeterパラメータを渡し、変数を記録し、 pandasを使用してcsvログを処理すると、テストツール自体をテストできます。方法論はうまくいきました。githubのプロジェクトを参照してください。