 Spark
Sparkは、クラスターコンピューティング用の
Apacheプロジェクトであり、機械学習を含むデータ処理用の高速で汎用性の高い環境です。
Sparkには
Rの API (
SparkRパッケージ)もあり、これは
Sparkディストリビューション自体の一部です。 ただし、この
APIでの作業に加えて、
Rで
Sparkを使用するためのさらに2つの方法があります
。 合計で、Sparkクラスターと対話する3つの異なる方法があります。 この投稿では、各方法の主な機能の概要を説明し、いずれかのオプションを使用して、
Azure HDInsightにデプロイされた
Sparkクラスター上の少量のテキストファイル(3.5 GB、1400万行)で最も単純な機械学習モデルを構築します。
Sparkインタラクションの概要
機械学習機能が弱い公式の
SparkRパッケージ(バージョン1.6.2には1つのモデルのみがあり、バージョン2.0.0には4つのモデルがあります)に加えて、
Sparkへのアクセスにはさらに2つのオプションがあります。
最初のオプションは、
Microsoftの製品
-Microsoft R Server for Hadoopを使用することです。これは、最近
Sparkサポートを統合しました。 この製品を使用すると、ローカルコンピューティング、
Hadoop (
map-reduce )または
Sparkのコンテキストで同じR関数を使用して計算を実行できます。 Rのローカルインストールと
Sparkクラスターへのアクセスに加えて、
Microsoft Azure HDInsightクラウドサービスを使用
すると、既製のクラスターを展開でき、通常の
Sparkクラスターに加えて、
RサーバーをSparkクラスターに展開できます。 このサービスは、追加の境界ノードに
Hadoop用Rサーバーがプリインストールされた
Sparkクラスターです。これにより、このサーバー上でローカルに計算を実行するか、
Sparkまたは
Hadoopコンテキストに切り替えることができます。 この製品の使用については、
Microsoft Webサイトの
HDInsightの公式ドキュメントに
詳しく説明されてい
ます 。
2番目のオプションは、まだ開発中の新しい
sparklyrパッケージを使用することです。 この製品は、最も有用で必要なパッケージの一部がリリースされている
RStudio(knitr、ggplot2、tidyr、lubridate、dplyrなど)の後援の下で開発されているため、このパッケージは別のリーダーになります。 このパッケージはまだ正式にリリースされていないため、まだ十分に文書化されていません。
これらの
Sparkの各作業方法に関するドキュメントと実験に基づいて、各メソッドの一般化された機能を備えた次の表(表1)を準備しました(もう少し可能性があった
SparkR 2.0.0も追加しました)。
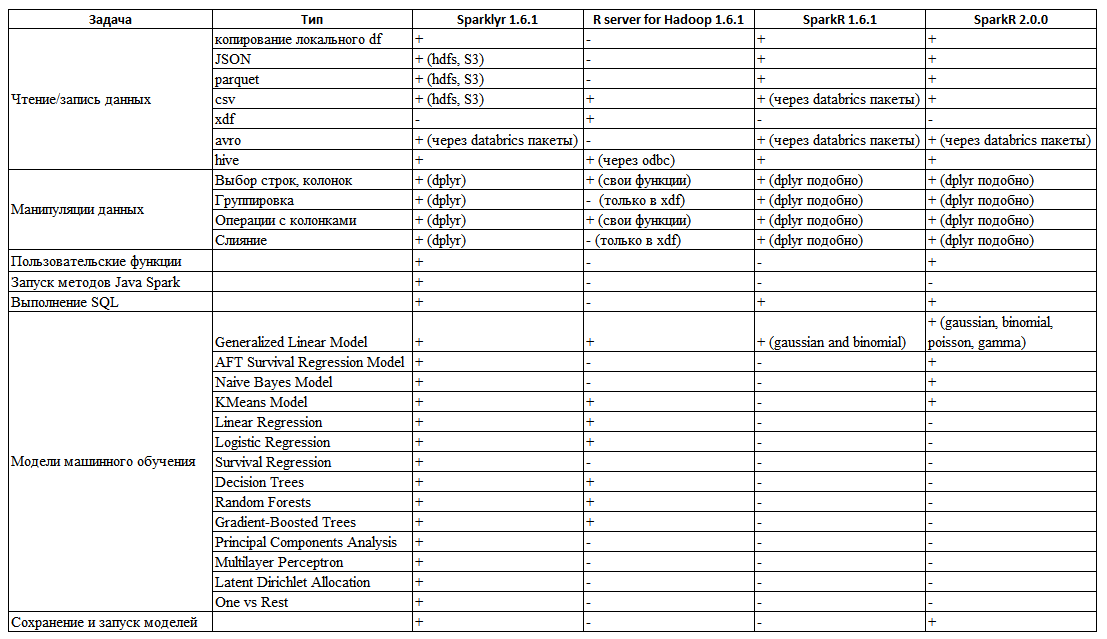 表1. Sparkと対話するさまざまな方法の可能性の概要
表1. Sparkと対話するさまざまな方法の可能性の概要表からわかるように、すぐに必要なニーズを完全に実現するツールはありませんが、
sparklyrパッケージは
SparkRおよび
R Serverと
比較して有利です。 その主な利点は、
csv 、
json 、
hdfsから
寄木細工のファイルを
読み取ることです。
dplyrデータ操作構文と完全に互換性があります-フィルタリング操作、列選択、集約関数、データのマージ、列名の変更などを実行する機能など。 これらのタスクの一部が実行されないか、非常に不便な
Hadoopの SparkRまたは
Rサーバーとは異なり(
HadoopのRサーバーでは、オブジェクトのデータマージはまったくなく、組み込みのxdfデータタイプでのみサポートされます)。 このパッケージのもう1つの利点は、Rコードから直接
Javaメソッドを実行する関数を作成できることです。
例count_lines <- function(sc, file) { spark_context(sc) %>% invoke("textFile", file, 1L) %>% invoke("count") } count_lines(sc, "/text.csv")
これにより、
Sparkの既存の
javaメソッドを使用するか、自分で実装することで、パッケージにない機能を実装できます。
そして、もちろん、機械学習モデルの数は、
SparkR (バージョン2.0であっても)および
Hadoop用Rサーバーの数よりもはるかに多くなってい
ます 。 したがって、このパッケージを最も有望で使いやすいものとして選択しましょう。
Sparkクラスターは、5種類のクラスター(
HBase 、
Storm 、
Hadoop 、
Spark 、
Rpark on Spark )の展開を提供する
Azure HDInsightクラウドサービスを使用して、最小限の労力でさまざまな構成で展開されました。
使用したリソース
- Linux上のHDInsight Apache Spark 1.6クラスター(クラスターの展開については、Microsoft Azureのドキュメントで詳細に説明されています)
- R 3.3.2がヘッドユニットにインストールされている
- RStudioプレビュー版(sparklyrの追加機能)、ヘッドノードにもインストール
- Puttyクライアント。クラスターのヘッドノードとのセッションを確立し、 RStudioポートをローカルホストポートにトンネリングします( RStudioとそのトンネリングの構成については、 Microsoft Azureのドキュメントで説明されています )
環境設定
最初に、
Sparkクラスターを展開します-2つのD12v2ヘッドノードと4つのD12v2作業ノードを含む構成を選択しました。 (D12v2:4コア/ 28 GBのRAM、200 GBのディスク。この構成は完全に最適ではありませんが、
sparklyrは構文のデモに適しています)。 さまざまな種類のクラスターを展開する方法とそれらを操作する方法の説明は、
HDInsightのドキュメントに記載されています。 作業ノードへのSSH接続を使用してクラスターを正常にデプロイした後、RとRStudioを必要な依存関係とともにそこにインストールします。 sparklyrパッケージの追加機能(Sparkの元のデータフレームを表示する追加のウィンドウ、およびプロパティまたは自身を表示する機能)があるため、RStudioのプレビューエディターを使用することをお勧めします。 R、R Studioをインストールした後、
localhost:8787へのトンネリングを使用して接続をリセットします。
したがって、
localhost:8787のブラウザーで
、 RStudioに接続し、作業を続行します。
データ準備
このタスクのすべてのコードは、この投稿の最後に記載されています。このテストタスクでは、
NYC Taxi Tripsにある
NYC Taxiデータセットの
csvファイルを使用します。 データは、タクシーの乗車とその支払いに関する情報です。 情報提供を目的として、1か月に制限します。 同じ完全なデータセット上で、
Rad for Hadoopを使用して(
Hadoopのコンテキストで)モデルを構築する方法については、
Microsoft R ServerとHDInsightを使用したNYCタクシーデータの探索を参照
してください 。 ただし、ファイルの読み取り、すべての前処理(データフィルタリング、テーブルマージ)は
Hiveで実行され、Rサーバーではモデルを作成したばかりで、ここではすべてが
sparklyrを使用して通常のRで実行されます。
両方のファイルを
Sparkクラスターの
hdfsに移動し、
sparklyr関数を使用して、これらのファイルを読み取ります。
データ操作
旅行と運賃のファイルはキーで接続されています-「
メダリオン 」、「
hack_licence 」、「
pickup_datetime 」の列なので、
データデータフレームの左側、つまり
運賃 データフレームに添付します。 データと操作を組み合わせた後、データフレームを寄せ木細工の形式で保存します。 モデルを構築する前に、データを見てみましょう。このために、2000個のランダムな観測値のサンプルを作成し、collectを使用してRに渡します。 この小さなサンプルを使用して、標準ダイアグラム
ggplot2 (チップ対料金、ポイントのサイズを示します-乗客の数によってルートの距離とポイントの色を示し、支払いタイプとタクシーオペレーターによってグリッドパネルに分割されます)(図1)。
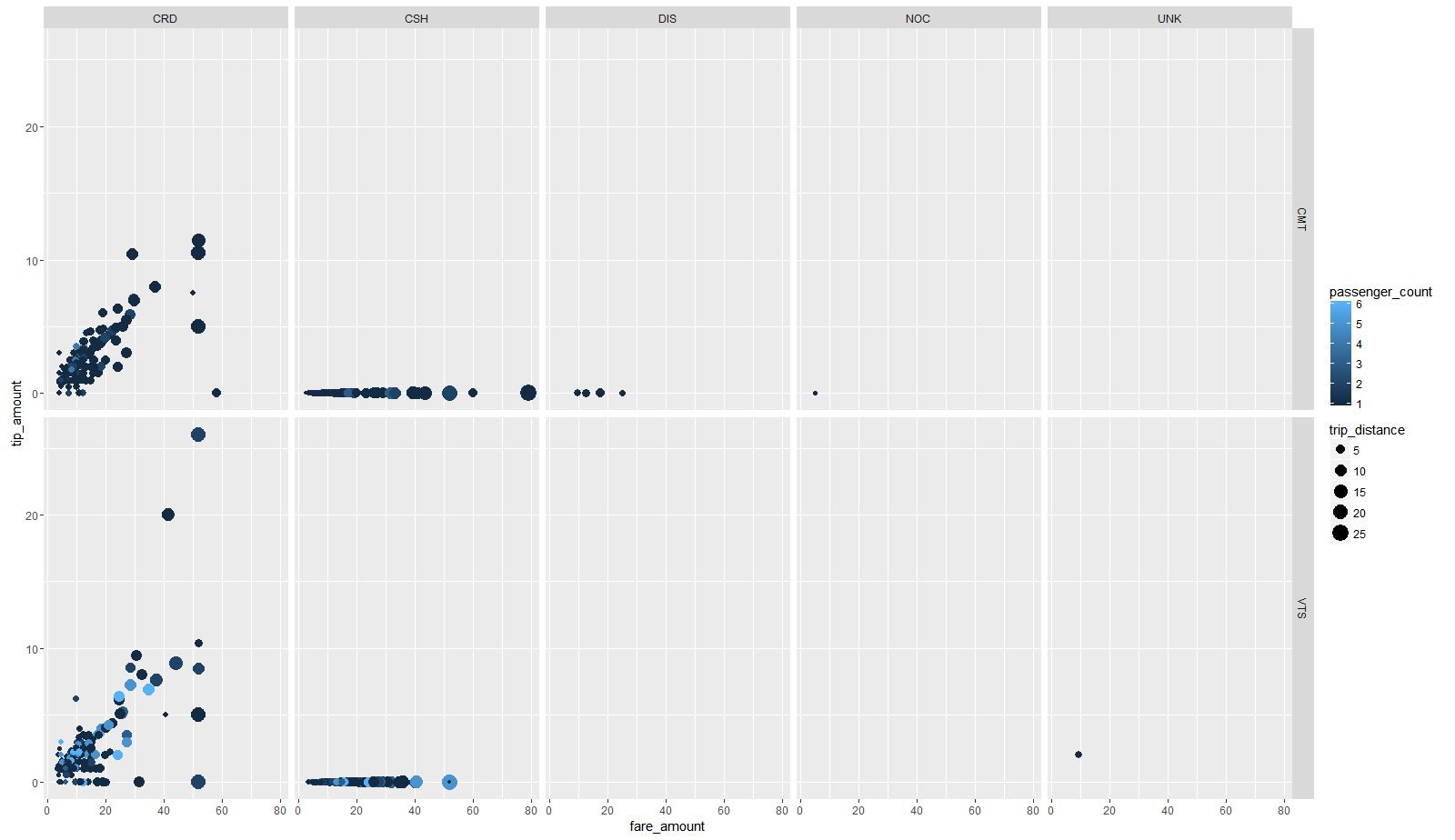 図1主な依存関係を示す図
図1主な依存関係を示す図運賃のチップサイズには依存性(請求書の「標準」%として線形)があり、ほとんどの支払いはクレジットカード(CRDパネル)と現金(CSHパネル)を使用して行われ、現金で支払う場合、チップは常に欠席(これはおそらく、現金で支払う場合、チップはすでに価格に含まれていますが、カードで支払う場合は含まれていないためです)。 したがって、トレーニングのサンプルでは、クレジットカードで支払われた旅行のみを残しています。 便利な
dplyr構文とmagrittr
パイピングを使用して、結合されたデータフレームはチェーンに
渡されます:行(外れ値と非論理値を除く)と列(モデルの構築に必要なものだけを残して)の後続の選択、最終的なデータセットを線形回帰関数に渡します。 モデルをトレーニングするために、すべてのデータの70%を使用し、テストでは残りの30%を使用します。 このタスクでは、単純な線形回帰を使用します。 検出したい依存関係は、トリップのパラメーターに対するチップサイズです。 このデータのこのモデルはかなり退化しており、まったく正確ではありません(多数のヒントが0にあります)が、単純であり、モデルの解釈された係数を表示し、
sparklyrの基本的な機能を示すことができます。 モデルでは、次の予測変数を使用します
。vendor_id-タクシーオペレーターの識別子、
パッセンジャー_count-乗客数、
trip_time_in_secs-トリップ時間、
trip_distance-トリップ距離、
payment_type-支払タイプ、
fare_amount-トリップ価格、
surcharg e-料金 トレーニングの結果、モデルは次の形式になります。
Call: ml_linear_regression(., response = "tip_amount", features = c("vendor_id", "passenger_count", "trip_time_in_secs", "trip_distance", "fare_amount", "surcharge")) Deviance Residuals: (approximate): Min 1Q Median 3Q Max -27.55253 -0.33134 0.09786 0.34497 31.35546 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 3.2743e-01 1.4119e-03 231.9043 < 2e-16 *** vendor_id_VTS -1.0557e-01 1.1408e-03 -92.5423 < 2e-16 *** passenger_count -1.0542e-03 4.1838e-04 -2.5197 0.01175 * trip_time_in_secs 1.3197e-04 2.0299e-06 65.0140 < 2e-16 *** trip_distance 1.0787e-01 4.7152e-04 228.7767 < 2e-16 *** fare_amount 1.3266e-01 1.9204e-04 690.7842 < 2e-16 *** surcharge 1.4067e-01 1.4705e-03 95.6605 < 2e-16 *** --- Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 R-Squared: 0.6456 Root Mean Squared Error: 1.249
このモデルを使用して、テストサンプルの値を予測します。
結論
この記事では、Rで
Sparkを操作する3つの方法の主な機能について説明し、
sparklyrパッケージを使用してファイルの読み取り、その前処理、操作、および単純な機械学習モデルの構築を実装する例を
示します。
ソースコード devtools::install_github("rstudio/sparklyr") library(sparklyr) library(dplyr) spark_disconnect_all() sc <- spark_connect(master = "yarn-client") data_tbl<-spark_read_csv(sc, "data", "taxi/data") fare_tbl<-spark_read_csv(sc, "fare", "taxi/fare") fare_tbl <- rename(fare_tbl, medallionF = medallion, hack_licenseF = hack_license, pickup_datetimeF=pickup_datetime) taxi.join<-data_tbl %>% left_join(fare_tbl, by = c("medallion"="medallionF", "hack_license"="hack_licenseF", "pickup_datetime"="pickup_datetimeF", )) taxi.filtered <- taxi.join %>% filter(passenger_count > 0 , passenger_count < 8 , trip_distance > 0 , trip_distance <= 100 , trip_time_in_secs > 10 , trip_time_in_secs <= 7200 , tip_amount >= 0 , tip_amount <= 40 , fare_amount > 0 , fare_amount <= 200, payment_type=="CRD" ) %>% select(vendor_id,passenger_count,trip_time_in_secs,trip_distance, fare_amount,surcharge,tip_amount)%>% sdf_partition(training = 0.7, test = 0.3, seed = 1234) spark_write_parquet(taxi.filtered$training, "taxi/parquetTrain") spark_write_parquet(taxi.filtered$test, "taxi/parquetTest") for_plot<-sample_n(taxi.filtered$training,1000)%>%collect() ggplot(data=for_plot, aes(x=fare_amount, y=tip_amount, color=passenger_count, size=trip_distance))+ geom_point()+facet_grid(vendor_id~payment_type) model.lm <- taxi.filtered$training %>% ml_linear_regression(response = "tip_amount", features = c("vendor_id", "passenger_count", "trip_time_in_secs", "trip_distance", "fare_amount", "surcharge")) print(model.lm) summary(model.lm) predicted <- predict(model.lm, newdata = taxi.filtered$test) actual <- (taxi.filtered$test %>% select(tip_amount) %>% collect())$tip_amount data <- data.frame(predicted = predicted,actual = actual)