
みなさんこんにちは。 多くの人は入力ラグに精通しています。 これは、コンピューターゲームでもう一度殺されたときに起こります。「まあ、ブロック/攻撃/回避を押しました。」 さて、ジョイスティックは壁に飛び込みます。 おなじみですか? これは、キーストロークと結果が画面に表示されるまでにかなりの時間が経過するために発生します。 実際、画面を見ると、現実をまったく反映していない過去の状態が表示されます。
独自のゲームを開発している場合、またはレンダリングしている場合でも、入力の遅延を減らしたい場合は、猫の下を見るように強くお勧めします。
したがって、すべてのゲームの入力ラグは次のもので構成されます。
- コントローラーの遅延
- ネットワーク遅延(これがオンラインゲームの場合)
- ラグレンダリング。
この記事では、レンダリングに関連する3番目のラグのみを検討します。 現代のコンピューターでレンダリングがどのように行われるかについて、もう少し詳しく説明する必要があります。
CPU + GPU
最新のGPUは非同期デバイスです。 CPUはビデオドライバーに指示を出し、その業務に取りかかります。 ドライバーはコマンドをバッチで蓄積し、ビデオカードにバッチで送信します。 ビデオカードが描画され、この時点でCPUがそのビジネスに取りかかります。 このシステムで取得できる最大FPSは、次のいずれかの条件によって制限されます。
1.ビデオカードは非常に高速に描画されるため、CPUにはビデオカードにコマンドを発行する時間がありません。 そして、このような強力なグラフィックカードを購入した理由は何ですか?
2.ビデオカードには、CPUが提供するものを描画する時間がありません。 これでCPUは無料になりました...
CPUとGPUがペアでどれほど美しく機能するかを確認するために、さまざまなプロファイラーがあります。 Windows Performance Toolkitに付属のGPUViewを使用します。
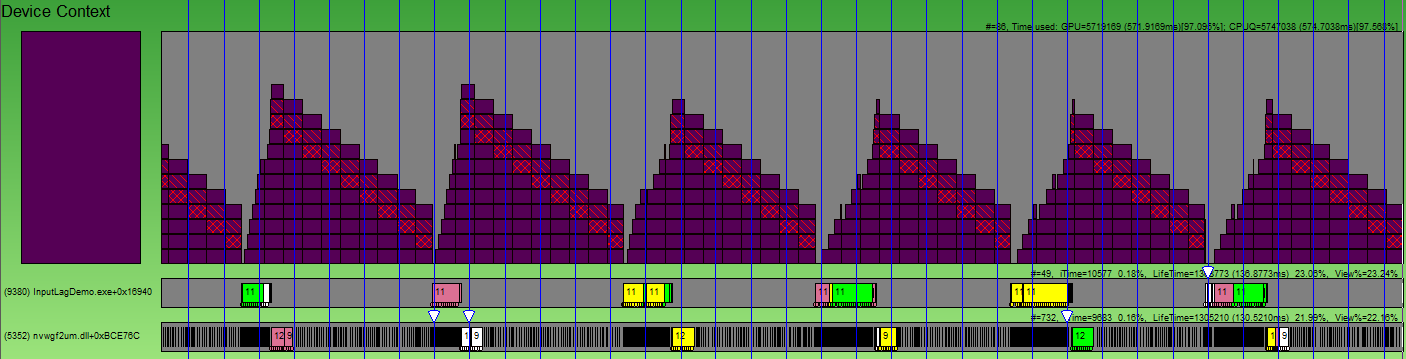
GPUViewログは次のようになります。
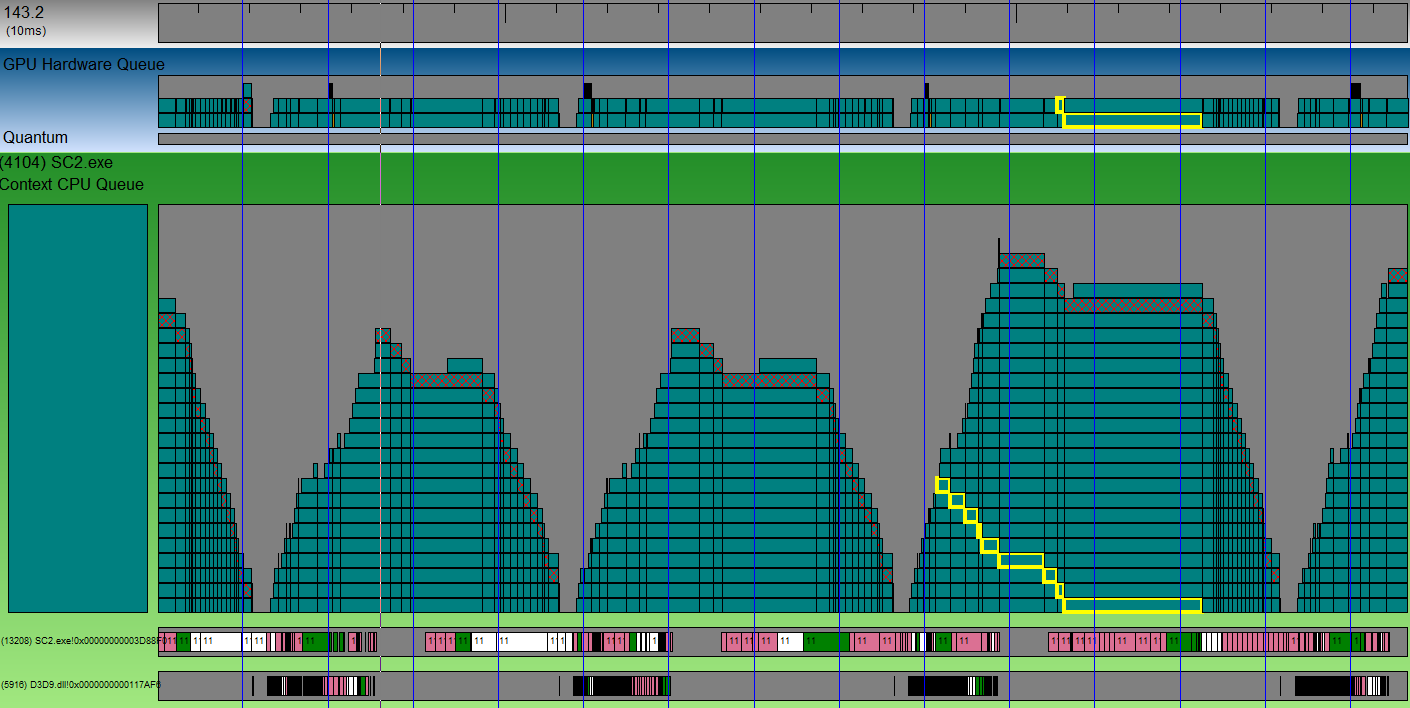
青い縦線はVSyncです。 積み上げられたキューブの山は、無料のビデオカードに行くパッケージの山です。 ハッチングされたキューブは、バッファスイッチングを含むパケットです。 つまり、フレームの終わり。 任意のキューブを選択し、それが徐々に山に落ち、ビデオカードに送信される様子を確認できます。 スクリーンショットで黄色い線の付いた立方体をご覧ください。 3つのvsync-sですでに処理されています。 また、フレーム全体で約4 VSync-sがかかります(異なるハッチングされたキューブ間の距離で判断します)。 異なるフレームからのパッケージの2つの山の間には小さなギャップがあります。 これはGPUが休止した時間です。 このギャップは小さく、CPU側の最適化では大きな利点は得られません。
ただし、大きなギャップがあります。

これは、World of Warcraftのレンダリングの例です。 キュー内のパケット間の距離は単純に大きいです。 より強力なビデオカードでは、FPSは増加しません。 ただし、CPU側でレンダリングを最適化すると、このGPUでFPSが2倍以上向上する可能性があります。
ここでもう少し読むことができます。さらに先に進みます。
それで、遅れはどこにありますか?
たまたまハイエンドとローエンドのグラフィックスカードのパフォーマンスのギャップが非常に大きいことが起こりました。 したがって、間違いなく両方の状況になります。 しかし、最も悲しい状況は、GPUが対処できない場合です。 次のようになります。
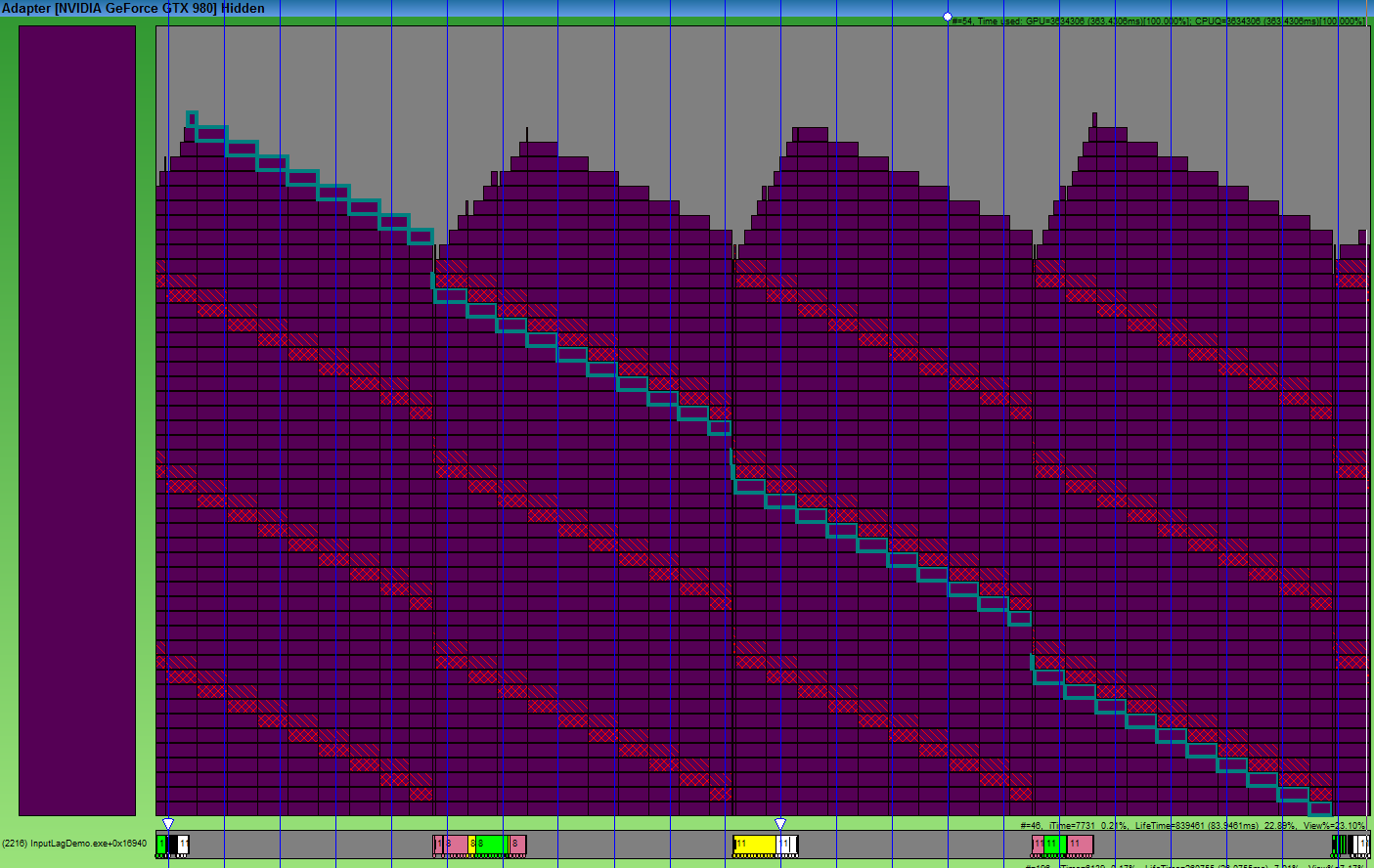
1つのパッケージの処理にかかった時間に注意してください。 フレームには4つのVSyncが必要で、パッケージの処理には4倍の時間がかかります! DirectX(OpenGLは同じように動作します)は、最大3フレームのデータを蓄積します。 ただし、新しいフレームをキューに入れると、以前のすべてのフレームは関連しなくなり、ビデオカードはレンダリングに時間を費やします。 したがって、アクションは最大3フレーム後に画面に表示されます。 何ができるか見てみましょう。
1.正直な決定。 IDXGIDevice1 :: SetMaximumFrameLatency(1)
正直なところ、バッファに3フレームのデータを保存する必要がある理由がわかりません。 しかし、MSは明らかにエラーを理解しており、DX10.1から、特別なメソッドIDXGIDevice1 :: SetMaximumFrameLatencyを介してこのフレーム数を設定する機会を得ました。 これがどのように役立つか見てみましょう:
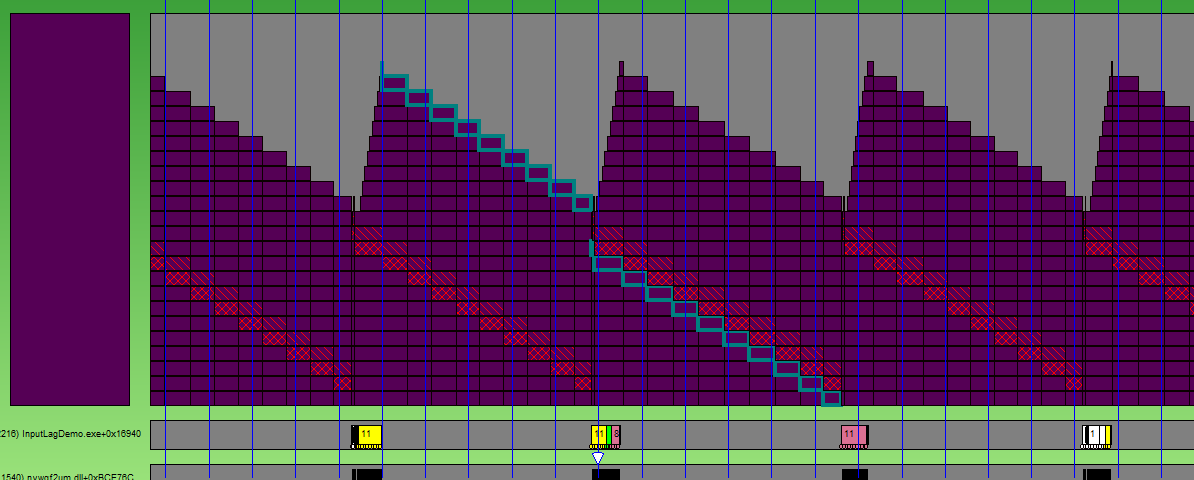
じゃあ ずっと良くなりました。 しかし、まだ完璧ではありません。なぜなら まだ2フレーム待機しています。 このソリューションのもう1つの欠点は、DirectXでのみ機能することです。
2. ID3D11Queryを使ったトリック
アイデアは、フレームの最後にD3D11_QUERY_EVENTを設定することです。 次のフレームの開始時に待機し、イベントを常にチェックし、イベントが合格した場合にのみ、レンダリング用のコマンドを発行し、最新の入力データを使用します。
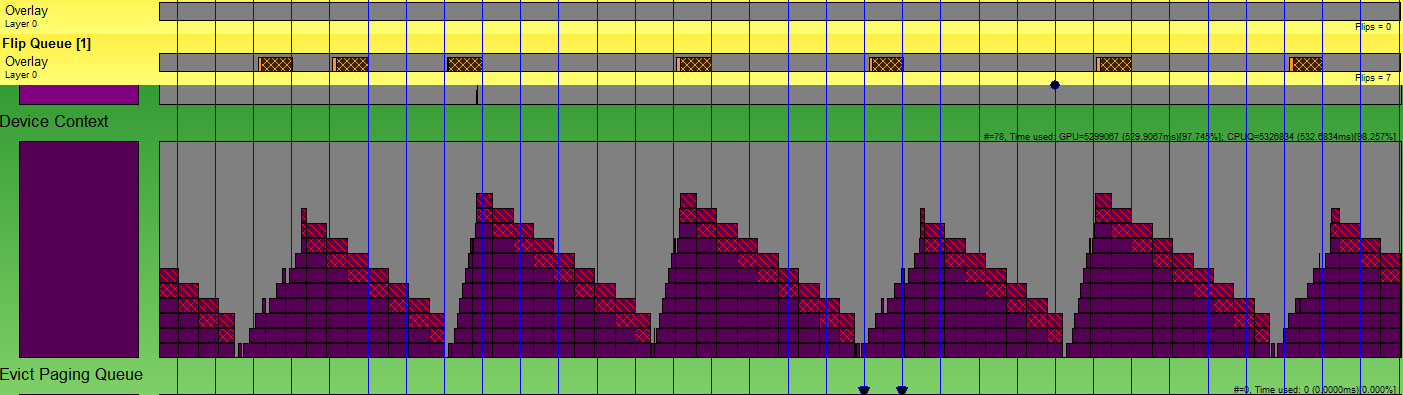
写真はほぼ完璧ですよね? 次のように待機を実装しました。
procedure TfrmMain.SyncQueryWaitEvent; var qDesc: TD3D11_QueryDesc; hRes: HRESULT; qResult: BOOL; begin if FSyncQuery = nil then
イベントのインストールは簡単です。
procedure TfrmMain.SyncQuerySetEvent; begin if Assigned(FSyncQuery) then FRawDeviceContext._End(FSyncQuery); end;
さて、最初にレンダー自体に待機を追加します。 次に、描画自体の前に新鮮な入力データを収集し、現在の前にイベントを設定します。
if FCtx.Bind then try case WaitMethod of
メソッド
松葉杖不足
-DirectXでのみ動作します。 ただし、別の独自の方法で同期を待つことができます。
3.テクスチャによる回避策
これが私たちの仕事です。 ビデオリソースからデータを読み取るメカニズムがあります。 ビデオカードに強制的に何かを描画させ、それを拾おうとすると、GPU-CPU間で自動的に同期します。 描画される前にデータを収集することはできません。 したがって、イベントをインストールする代わりに、ビデオカードで2 * 2テクスチャのmipesを生成し、イベントを待つのではなく、このテクスチャからシステムメモリにデータを取り込むことをお勧めします。 その結果、アプローチは次のようになります。
これがイベントの予想です。
procedure TfrmMain.SyncTexWaitEvent; var SrcSubRes, DstSubRes: LongWord; TexDesc: TD3D11_Texture2DDesc; ViewDesc: TD3D11_ShaderResourceViewDesc; Mapped: TD3D11_MappedSubresource; begin if FSyncTex = nil then begin TexDesc.Width := 2; TexDesc.Height := 2; TexDesc.MipLevels := 2; TexDesc.ArraySize := 1; TexDesc.Format := TDXGI_Format.DXGI_FORMAT_R8G8B8A8_UNORM; TexDesc.SampleDesc.Count := 1; TexDesc.SampleDesc.Quality := 0; TexDesc.Usage := TD3D11_Usage.D3D11_USAGE_DEFAULT; TexDesc.BindFlags := DWord(D3D11_BIND_SHADER_RESOURCE) or DWord(D3D11_BIND_RENDER_TARGET); TexDesc.CPUAccessFlags := 0; TexDesc.MiscFlags := DWord(D3D11_RESOURCE_MISC_GENERATE_MIPS); Check3DError(FRawDevice.CreateTexture2D(TexDesc, nil, FSyncTex)); TexDesc.Width := 1; TexDesc.Height := 1; TexDesc.MipLevels := 1; TexDesc.ArraySize := 1; TexDesc.Format := TDXGI_Format.DXGI_FORMAT_R8G8B8A8_UNORM; TexDesc.SampleDesc.Count := 1; TexDesc.SampleDesc.Quality := 0; TexDesc.Usage := TD3D11_Usage.D3D11_USAGE_STAGING; TexDesc.BindFlags := 0; TexDesc.CPUAccessFlags := DWord(D3D11_CPU_ACCESS_READ); TexDesc.MiscFlags := 0; Check3DError(FRawDevice.CreateTexture2D(TexDesc, nil, FSyncStaging)); ViewDesc.Format := TDXGI_Format.DXGI_FORMAT_R8G8B8A8_UNORM; ViewDesc.ViewDimension := TD3D11_SRVDimension.D3D10_1_SRV_DIMENSION_TEXTURE2D; ViewDesc.Texture2D.MipLevels := 2; ViewDesc.Texture2D.MostDetailedMip := 0; Check3DError(FRawDevice.CreateShaderResourceView(FSyncTex, @ViewDesc, FSyncView)); end else begin SrcSubRes := D3D11CalcSubresource(1, 0, 1); DstSubRes := D3D11CalcSubresource(0, 0, 1); FRawDeviceContext.CopySubresourceRegion(FSyncStaging, DstSubRes, 0, 0, 0, FSyncTex, SrcSubRes, nil); Check3DError(FRawDeviceContext.Map(FSyncStaging, DstSubRes, TD3D11_Map.D3D11_MAP_READ, 0, Mapped)); FRawDeviceContext.Unmap(FSyncStaging, DstSubRes); end; end;
次のようにインストールします。
procedure TfrmMain.SyncTexSetEvent; begin if Assigned(FSyncView) then FRawDeviceContext.GenerateMips(FSyncView); end;
それ以外のアプローチは、前のアプローチと完全に類似しています。 利点:DirectXだけでなくOpenGLでも動作します。 欠点は、テクスチャ生成とデータ転送のオーバーヘッドが非常に小さいことと、オペレーティングシステムのシェダーによるフローの「ウェイクアップ」に費やす可能性のある時間です。
しようとしている
もちろん、私はここで木に広がっていました...しかし、問題はどれほど深刻ですか? どう感じますか? 特別なデモプログラムを作成しました(DirectX11が必要です)。
ここから * .exeをダウンロードし
ます 。 不明なメーカーのビルドをダウンロードすることを恐れている人のために-lazarusプロジェクトのソースコードは
こちら (
こちらにあるAvalancheProjectフレームワークライブラリも必要
です )
プログラムは次のようなウィンドウです。

ここでは、40 * 40 * 40 = 64000が描画されます(ところで、各キューブは個別のdravkollです)。 GPUワークロードトラックバーは、GPUに負荷を提供します(頂点シェーダーで不要なループを使用)。 このトラックバーでFPSを低レベル(10〜20など)に下げてから、右クリックしてキューブをねじり、ラジオボタンを使用して入力遅延を減らす方法を切り替えてみてください。
応答速度の大きな違いだけを評価するでしょう。 C Query Eventは、20 fpsでもキューブを快適に回転させます。
結論として
この問題に苦労している人はほとんどいないことを知ったとき、正直驚いた。 大規模なAAAプロジェクトでさえ、このようなひどい入力遅延を許容します。 また、新しいグラフィカルAPIが次々と登場し、明らかに10年以上前の問題が松葉杖でまだ解決されていないことに驚きました。 一般に、この記事がアプリケーションの応答性を高め、満足するユーザーを追加するのに役立つことを願っています。