
夏の最後の2か月で、キッチン紛争に関する新しいトピックが、Tinkoff BankのDWHのデータウェアハウスの管理に登場しました。
今回は、いくつかのインメモリDBMSの大規模なテストを実施しました。 現時点でのDWH管理者との会話は、「さて、どのように、誰がリードしますか?」というフレーズから始まります。 それに応じて、人々はテストの難しさ、これまで知られていないベンダーとのコミュニケーションの知恵、個々の被験者の欠点について、長くて非常に感情的な刺激を受けました。
詳細、結果、およびテストからの結論の一部の類似性-削減中。
テストの目的は、当社の要件を満たす高速分析インメモリデータベースを確認し、他のデータストレージシステムとの統合の複雑さを評価することです。
また、テストではインメモリソリューションとして位置付けられていない2つのDBMSを含めました。 データ量がサーバーのRAMメモリとほぼ同等であれば、これらのDBMSでパフォーマンスが従来のメモリ内ソリューションに近づくことができるという条件で、キャッシュメカニズムを使用できるという事実に頼りました。
ユースケースの説明
テストの結果として選択されたDBMSは、選択データセットのフロントエンドストレージデータベースとして機能すると想定されます(ただし、2〜4 TB、ただし、データの量は時間とともに増加する可能性があります):BIシステム(SAP BusinessObjects)および一部からの要求を受け入れます一部のユーザーからのアドホックリクエスト。 クエリは、90%のケースで、平等の条件(場合によっては間隔に含まれる日付の条件)に応じた1〜10の結合を持つSELECTです。
現在、メインストレージデータベースであるGreenplumで処理するよりもはるかに高速に処理するために、このような要求が必要です。
また、同時に実行されるリクエストの数が各リクエストの実行時間に大きく影響しないことも重要です。これはほぼ一定である必要があります。
私たちの意見では、ターゲットデータベースには次の機能が必要です。
- 水平方向のスケーラビリティ。
- ローカル結合を実行する機能-テーブルで「正しい」配布キーを使用する
- バルクデータストレージ。
- キャッシュと大量の利用可能なメモリを操作する機能。
ターゲットシステムへのデータのロードは、メインストレージデータベースであるGreenplumから行われることになっているため、Greenplumからターゲットデータベースにデータを(好ましくは増分で)迅速かつ確実に配信する方法を持つことも重要です。
SAP BOと統合できることも重要です。 幸いなことに、Windows用の安定したODBCドライバーを備えたほぼすべてのものがこのシステムでうまく機能します。
小さいながらも重要な要件のうち、ウィンドウ機能、冗長性(異なるノードにデータの複数のコピーを保存する機能)、さらなるクラスター拡張のシンプルさ、および並列データロードを区別できます。
試験台
各データベースに2つの物理サーバーが割り当てられました。
- 16個の物理コア(HTで32個)
- 128 GB OP
- 3.9 TBのディスクスペース(8つのディスクのうちRAID 5)
- サーバーは10 Gbネットワークで接続されています。
- 各データベースのOSは、このデータベースをインストールするための推奨事項に基づいて選択されました。 OS、カーネルなどについても同じことが言えます。
試験基準
- テストリクエストの実行速度
- SAP BOと統合する機能
- データをインポートするための高速で適切な方法を持つ
- 安定したODBCドライバーの存在
- 製品が自由に配布されていない場合は、適切な時間内にメーカーの会社の担当者に連絡し、テストに必要なデータベースのインストール(配布)を取得することができました。
テストに含まれるDB
みどり
Greenplumに馴染みの古くて優しい。 彼に関する別の
記事があります。
厳密に言えば、Greenplumはインメモリデータベースではありませんが、データを格納するXFSの特性により、特定の条件下でそのように動作することが実験的に証明されています。
したがって、たとえば、読み取り時にメモリの量が十分であり、要求によって要求されたデータが既にメモリにある場合(キャッシュされている場合)、データを受信するディスクはまったく影響を受けません-Greenplumはすべてのデータをメモリから取得します。 この動作モードはGreenplumに固有のものではないことを理解しておく必要があります。したがって、特殊なインメモリDBは(理論的には)そのようなタスクによりよく対処する必要があります。
テスト用に、Greenplumはデフォルトでインストールされ、ミラーなし(プライマリセグメントのみ)。 すべての設定はデフォルトで、テーブルはzlib圧縮されています。
ヤンデックスクリックハウス
有名な検索大手の分析およびリアルタイムレポート用の列化されたDBMS。
製造元の推奨事項を考慮してDBMSがインストールされ、ローカルテーブルのエンジンはMergeTreeであり、分散テーブルはローカルテーブルの上に作成され、クエリに参加しました。
SAP HANA
HANA(高性能ANalyticsアプライアンス)は、分析およびトランザクションのワークロード用の汎用ツールとして位置付けられています。 データを行ごとに保存できます。 製品ベースに必要な災害復旧、ミラーリング、および複製があります。 HANAを使用すると、ハッシュと値の範囲の両方で、テーブルのパーティション(シャード)を柔軟に構成できます。
複数レベルのパーティションが存在する場合、異なるレベルで異なるタイプのパーティションを適用できます。 1つのパーティションに最大20億のレコードを記録できます。
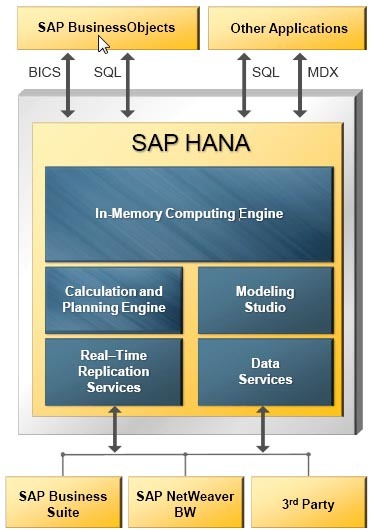 SAP HANAソリューションアーキテクチャ
SAP HANAソリューションアーキテクチャこのDBMSの興味深い機能の1つは、表形式の「アンロード優先度」設定です。1から10までのメモリからのアンロードの優先度です。これにより、メモリリソースとテーブルへのアクセス速度を柔軟に管理できます。テーブルがほとんど使用されない場合、最も低い優先度に設定されます。 この場合、テーブルがメモリにロードされることはほとんどなく、リソース不足でアンロードされる最初のテーブルの1つになります。
エクサソル
ロシアの製品はほとんど知られていない、ダークホースです。 このDBMSを使用している大企業のうち、Badoo(Habré
についての記事があります)と、名前がよく知られている非IT企業の数社のみが稼働しています-完全なリストは公式Webサイトにあります。
ベンダーは、魅力的な高速分析、森の中の石の安定性、コーヒーグラインダーレベルでの管理の容易さを約束します。
ExasolはそのOS-ExaOS(CentOS / RHELに基づいた独自のGNU / Linuxディストリビューション)で実行されます。 DBMSのインストールは、既成のOSに個別のソフトウェアをインストールするのではなく、ダウンロードされたイメージと最小限のセットアップ(パーティションディスク、ネットワークインターフェイス、PxEブートを許可する)から個別のライセンスマシン(この場合は仮想マシン)にOSをインストールするため、少なくとも珍しいことですノード
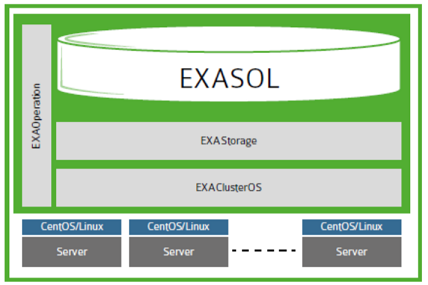 簡素化されたExasolアーキテクチャ
簡素化されたExasolアーキテクチャこのシステムの利点は、ノード(OS、カーネルパラメーター、またはその他の喜び)に何もインストールする必要がないため、クラスターへの新しいノードの追加が非常に高速であることです。 サーバーがインストールされ、切り替えられた瞬間(ベアメタル、OSなし)から、30分以内にノードをクラスターに入れることができます。 すべてのデータベース管理は、Webコンソールを介して実行されます。 過剰な機能でオーバーロードされていませんが、切り捨てられたと呼ぶこともできません。
データはメモリに連続して保存され、適切に圧縮されます(圧縮設定は見つかりませんでした)。
要求を処理するときにRAMよりも多くのデータが必要な場合、データベースはディスク上のスワップ(スピル)の使用を開始します。 クエリは失敗せず(こんにちはHanaとmemSQL)、動作が遅くなります。
Exasolは、インデックスを自動的に作成および削除します。 初めてクエリを作成するときに、クエリがインデックスでより高速に機能するとDBMSが判断した場合、クエリの処理プロセスでインデックスが作成されます。 このインデックスが30日間必要なユーザーがいない場合、データベース自体が削除します。
これはとても賢い馬です。Memsql
mySQLに基づくインメモリDBMS。 クラスター、分析機能があります。 デフォルトでは、データを行ごとに保存します。
バッチストレージを作成するには、テーブルの作成時に特別なインデックスを追加する必要があります。
KEY `keyname` (`fieldaname`) USING CLUSTERED COLUMNSTORE
同時に、行ストアデータは常にメモリに格納されますが、メモリが不足している場合、列ストアデータは自動的にディスクにフラッシュできます。
配布キーは、SHARD KEYと呼ばれます。 シャードキーの各フィールドに対してbtreeインデックスが自動的に作成されます。
基本バージョンは完全に無料で、データとRAMの量に制限はありません。 有料版には、高可用性、オンラインバックアップと復元、データセンター間のレプリケーション、ユーザー権利管理があります。
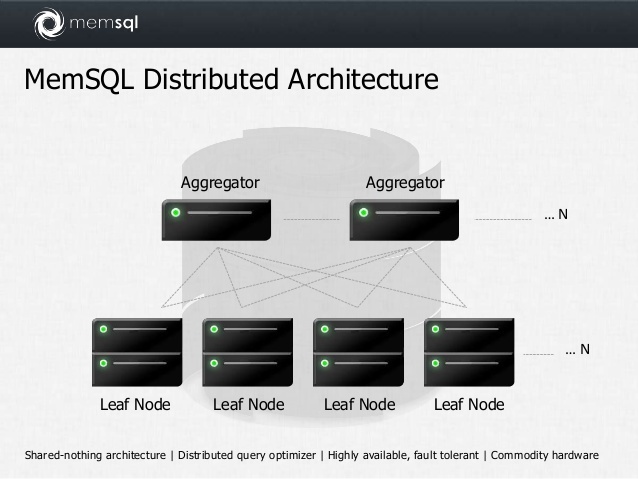 簡略化されたMemsqlアーキテクチャインパラ
簡略化されたMemsqlアーキテクチャインパラ
C ++で開発されたSQLエンジンであるClouderaは、Apache Hadoopエコシステムの一部です。 HDFSおよびHBaseに保存されたデータを処理します。 メタデータリポジトリとして、Hive DBMSの一部であるHiveMetastoreを使用します。 Hiveとは異なり、MapReduceは使用しません。 頻繁に使用されるデータブロックのキャッシュをサポートします。
迅速な応答を必要とする分析クエリを処理するためのDBMSとして位置付けられています。 基本的なBIツールを使用できる。 ANSI SQLの完全サポート、ウィンドウ関数があります。
Impalaは、Clouderaリポジトリのパッケージおよびパーセルとして利用できます。 テスト中、配布キットCloudera CDH 5.8.0が使用されました。 インストールには、Impalaの最小限のサービスセット(Zookeeper、HDFS、Yarn、Hive)が選択されました。 ほとんどの設定はデフォルトで使用されていました。 Impalaの場合、合計160 GBのメモリが両方のサーバーから割り当てられました。 Cgroupsは、コンテナによるサーバーリソースの使用率を制御するために使用されました。
この
記事で推奨されている最適化はすべて実行されました。
-テーブルをHDFSに保存する形式として、寄木細工が選択されました。
-これが可能な最適化されたデータ型;
-各テーブルの以前に収集された統計(計算統計)。
-すべてのテーブルのデータがHDFSキャッシュに記録された(テーブル...がキャッシュされた...に設定);
-最適化された結合(可能な限り)。
計画のテストと参加のためのDBMSの決定の初期段階で、Impalaは数年前に既に作業しており、その時点では本番用に見えなかったため、Impalaは破棄されました。 もう一度、業界の同僚は、アンテロープの方向に目を向けるように私たちを説得し、過去に彼女は非常にきれいになり、記憶を適切に操作することを学んだと確信しました。
Impalaに関する詳細情報構成:
Impala Daemonは、クラスター全体での受け入れ、処理、調整、配布、および要求の実行に役立つメインサービスです。 ODBCおよびJDBCインターフェースをサポートします。 また、CLIインターフェースとHue(Hadoopでのデータ分析用のWeb UI)を操作するためのインターフェースも備えています。 各クラスターワーカーでデーモンとして実行されます。
Impala Statestore-クラスターで実行されているImpala Daemonインスタンスのステータスを確認するために使用されます。 Impala Daemonがいずれかのワーカーで失敗すると、Statestoreは残りのワーカーのインスタンスに通知するため、出発したオフラインインスタンスへのリクエストは送信されません。 原則として、クラスターのマスターノードで動作しますが、オプションです。
Impala Catalog Server-このサービスは、HiveMetastore、HDFS Namenode、HBaseからImpala Daemonがサポートする構造の形式でメタデータを受信および集約するために使用されます。 このサービスは、たとえばユーザー定義関数など、Impala自体が排他的に使用するメタデータの保存にも使用されます。 原則として、クラスタマスターノードで動作します。
Googleドキュメントの1つのテーブルに収集された、私たちにとって重要なすべてのデータベースの特性太字の場合-Habr形式の同じテーブル(注意して、Habrの再設計により、幅の広いテーブルが少しでも読めなくなりました) | みどり | エクサソル | クリックハウス | Memsql | 樹花 | インパラ |
| 仕入先 | EMC | エクサソル | ヤンデックス | Memsql | 樹液 | Apache / cloudera |
| バージョンで 使用 | 4.3.8.1 | 5.0.15 | 1.1.53988 | 5.1.0 | 1.00.121.00.1466466057 | 2.6.0 |
| マスターノード | マスターセグメント。 予約済み。
| エントリポイント-任意のノード。 ライセンスノードがあり、予約されています。 | エントリポイント-任意のノード | エントリポイント-任意のノード | マスターノードがあります。 予約済み。 | エントリポイント-任意のノード。 ただし、Hiveメタストアサーバーが必要です。 |
| 使用 OS | RHEL 6.7 | EXA OS(専有) | Ubuntu 14.04.4 | RHEL 6.7 | RHEL 6.7 | RHEL 6.7 |
| 可能な鉄 | どれでも | PXEブートをサポートしている人 | どれでも | どれでも | SAPリストからのみ | どれでも |
| Greenplumからのインポート | 外部httpテーブル | 外部httpテーブルJDBCインポート | 外部httpテーブル | ローカルサーバーSPARKからのCSV | ローカルサーバーからのCSV | 外部GPHDFSテーブル |
| SAP BOとの統合 (ユニバースのソース) | はいODBC | はいODBC | データなし | データなし | はい | はいODBCSIMBA |
| SAS統合 | はい、SAS ACCESS | はいODBC | データなし | データなし | データなし | はい、SAS ACCESS |
| ウィンドウ関数 | あります | あります | いや | あります | あります | あります |
| ノードによる配布 | フィールドごと/フィールドごと | フィールドごと/フィールドごと | フィールドごと/フィールドごと | フィールドごと/フィールドごと | フィールドごと/ fieldsChardsはノードによって手動で分散されます | ランダムに |
| カラム収納 | あります | あります | あります | ディスク上にある | あります | はい(寄木細工) |
| リクエストの実行時に 十分なメモリがない場合 | データはディスクにカットされます | データはディスクにカットされます | リクエストが落ちる | リクエストが落ちる | リクエストが落ちる | データはディスクにカットされます |
| 耐障害性 | ミラー機構があります | ミラー機構があります | はい、テーブルレベルで | あります | あります | はい、HDFSによる |
| 配布方法 | オープンソース、APACHE-2 | クローズドコード、有料 | オープンソース、APACHE-2 | クローズドコード、無料 | クローズドコード、有料 | オープンソース、APACHE-2 |
試験結果
テストで使用されるテストリクエストの説明とテキスト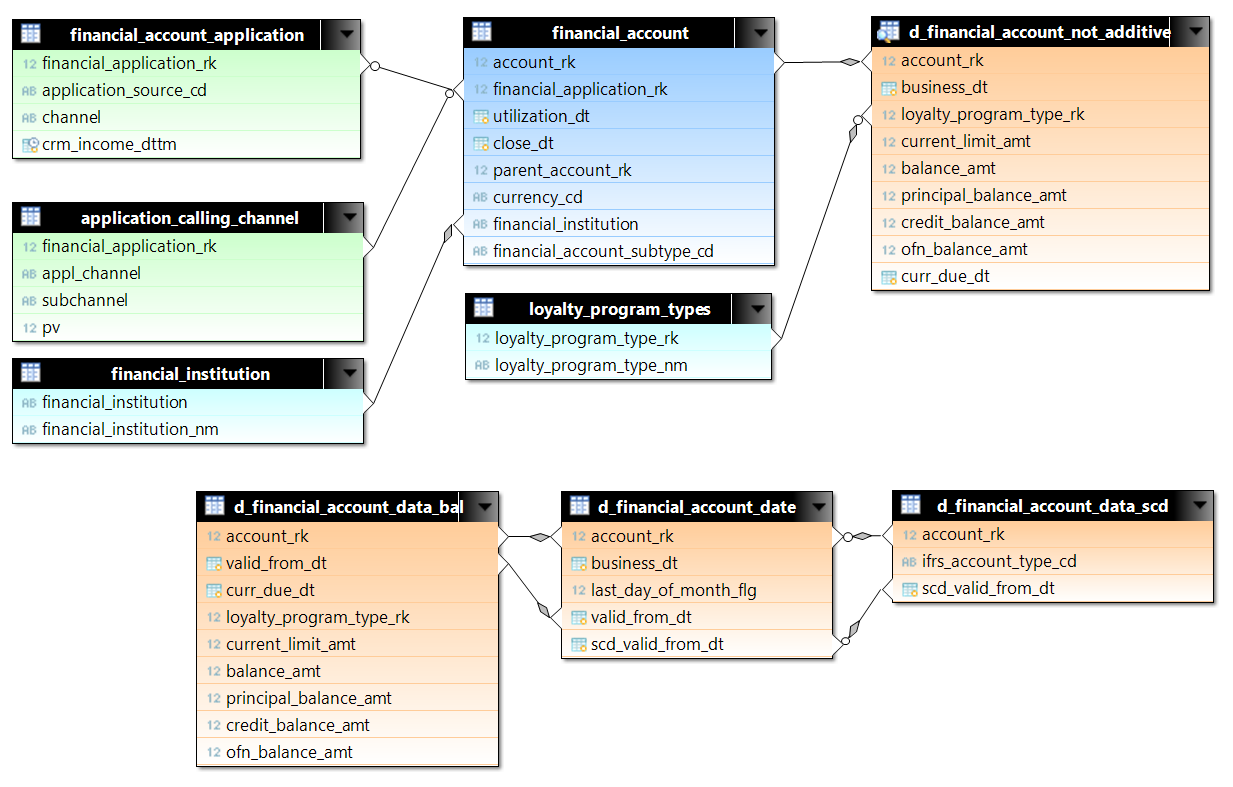
d_financial_account_not_additiveのクエリがテスト用に選択されました。 d_financial_account_not_additiveは、毎日の各アカウントのデータを含むビューです。 ビューは、ディスクスペースを最適化し、それに応じてディスクから読み取るために、3つのテーブルに基づいて作成されます。 テストでは、2015年の初めから最初の100万アカウントのデータの一部が選択されました。 これは5億2200万行をわずかに超えています。 not_additiveには、アカウント(financial_account)およびリクエスト(financial_account_applicationおよびapplication_calling_channel)のデータを添付します。 Greenplum(たとえば)では、セグメントの分布のキーがテーブルに設定されます。アカウントの場合、これはaccount_rk、アプリケーションの場合、financial_application_rkです。 クエリでは、メインテーブル間の結合が均等に発生するため、異なるテーブルの行ごとの多数の行を比較する必要がある場合、ネストされたループなしでハッシュ結合が期待できます。
データの総量は、非圧縮形式で約200 GBでした(わずかなマージンのあるこのボリュームはすべてメモリに収まると予想されます)。
使用されるテーブルの行数:
| テーブル | 行数 |
| d_financial_account_date | 522726636 |
| d_financial_account_data_bal | 229255701 |
| Financial_account_application | 52118559 |
| application_calling_channel | 28158924 |
| d_financial_account_data_scd | 3494716 |
| Financial_account | 2930425 |
| currency_rates | 3948 |
| dds_calendar_date | 731 |
| loyalty_program_types | 35 |
| 金融機関 | 5 |
リクエストN1 SELECT date_trunc('year', d_financial_account_not_additive.business_dt) || '-' || date_trunc('month',d_financial_account_not_additive.business_dt) as yymm, d_financial_account_not_additive.business_dt, financial_account.financial_account_subtype_cd, case when d_financial_account_not_additive.ofn_balance_amt <0 then 1 else 0 end, loyalty_program_by_day.loyalty_program_type_nm, financial_account.currency_cd, sum(d_financial_account_not_additive.balance_amt*Table__14.rate), sum(d_financial_account_not_additive.balance_amt) FROM prod_emart.loyalty_program_types loyalty_program_by_day RIGHT OUTER JOIN prod_emart.d_financial_account_not_additive d_financial_account_not_additive ON (d_financial_account_not_additive.loyalty_program_type_rk=loyalty_program_by_day.loyalty_program_type_rk AND loyalty_program_by_day.valid_to_dttm > now()) INNER JOIN prod_emart.financial_account financial_account ON (financial_account.account_rk=d_financial_account_not_additive.account_rk) INNER JOIN ( SELECT r.currency_from_cd, r.currency_to_cd, r.rate, r.rate_dt FROM prod_emart.currency_rates r WHERE ( r.currency_to_cd='RUR' ) union all SELECT 'RUB', 'RUR', 1, d.calendar_dt FROM prod_emart.dds_calendar_date d ) Table__14 ON (Table__14.currency_from_cd=financial_account.currency_cd) WHERE ( Table__14.rate_dt=d_financial_account_not_additive.business_dt ) AND ( d_financial_account_not_additive.business_dt >= to_date(( 2016 - 2)::character varying ||'-01-01', 'YYYY-MM-DD') AND d_financial_account_not_additive.business_dt <= (current_date-1) AND financial_account.financial_account_subtype_cd IN ( 'DEP','SAV','SVN','LEG','CUR' ) ) GROUP BY date_trunc('year', d_financial_account_not_additive.business_dt) || '-' || date_trunc('month',d_financial_account_not_additive.business_dt), d_financial_account_not_additive.business_dt, financial_account.financial_account_subtype_cd, case when d_financial_account_not_additive.ofn_balance_amt <0 then 1 else 0 end, loyalty_program_by_day.loyalty_program_type_nm, financial_account.currency_cd
リクエストN2 select count(*) from (SELECT date_trunc('year', d_financial_account_not_additive.business_dt) || '-' || date_trunc('month',d_financial_account_not_additive.business_dt) as yymm, d_financial_account_not_additive.business_dt, financial_account.financial_account_subtype_cd, loyalty_program_by_day.loyalty_program_type_nm, application_calling_channel.appl_channel, case when ( financial_account_application.application_product_type )='010222' then 'Y' else 'N' end , case when ( financial_account_application.application_product_type )='020202' then 'Y' else 'N' end, case when financial_account.parent_account_rk is null then 'N' else 'Y' end, prod_emart.financial_institution.financial_institution_nm, sum(d_financial_account_not_additive.principal_balance_amt), sum(d_financial_account_not_additive.interest_balance_amt), sum(d_financial_account_not_additive.f2g_balance_amt), sum(d_financial_account_not_additive.f2n_balance_amt), sum(d_financial_account_not_additive.overdue_fee_balance_amt), sum(d_financial_account_not_additive.pastdue_gvt_balance_amt), sum(d_financial_account_not_additive.annual_fee_balance_amt), sum(d_financial_account_not_additive.sim_kke_balance_amt) FROM prod_emart.loyalty_program_types loyalty_program_by_day RIGHT OUTER JOIN prod_emart.d_financial_account_not_additive d_financial_account_not_additive ON (d_financial_account_not_additive.loyalty_program_type_rk=loyalty_program_by_day.loyalty_program_type_rk AND loyalty_program_by_day.valid_to_dttm > now()) INNER JOIN prod_emart.financial_account financial_account ON (financial_account.account_rk=d_financial_account_not_additive.account_rk) LEFT OUTER JOIN prod_emart.financial_account_application ON financial_account.financial_application_rk=financial_account_application.financial_application_rk LEFT OUTER JOIN prod_emart.application_calling_channel on financial_account.financial_application_rk=application_calling_channel.financial_application_rk LEFT OUTER JOIN prod_emart.financial_account parent_account ON (financial_account.parent_account_rk=parent_account.account_rk) LEFT OUTER JOIN prod_emart.financial_institution ON (financial_account.financial_institution=financial_institution.financial_institution) WHERE ( d_financial_account_not_additive.business_dt >= to_date('2014-01-01', 'YYYY-MM-DD') AND d_financial_account_not_additive.business_dt <= (current_date-1) AND ( financial_account.financial_account_subtype_cd IN ( 'CCR','INS','CLN','VKR','EIC' ) OR ( financial_account.financial_account_subtype_cd IN ( 'PHX' ) AND ( parent_account.financial_account_subtype_cd Is Null OR parent_account.financial_account_subtype_cd NOT IN ( 'IFS' ) ) ) ) ) GROUP BY date_trunc('year', d_financial_account_not_additive.business_dt) || '-' || date_trunc('month',d_financial_account_not_additive.business_dt), d_financial_account_not_additive.business_dt, financial_account.financial_account_subtype_cd, loyalty_program_by_day.loyalty_program_type_nm, application_calling_channel.appl_channel, case when ( financial_account_application.application_product_type )='010222' then 'Y' else 'N' end , case when ( financial_account_application.application_product_type )='020202' then 'Y' else 'N' end, case when financial_account.parent_account_rk is null then 'N' else 'Y' end, financial_institution.financial_institution_nm) sq
リクエストN3 SELECT date_trunc('year', d_financial_account_not_additive.business_dt) || '-' || date_trunc('month',d_financial_account_not_additive.business_dt) as yymm, d_financial_account_not_additive.business_dt, financial_account.financial_account_subtype_cd, case when ( prod_emart.financial_account_application.application_product_type )='010222' then 'Y' else 'N' end , d_financial_account_not_additive.risk_status_cd, case when financial_account.utilization_dt<=d_financial_account_not_additive.business_dt then 1 else 0 end, case when ( d_financial_account_not_additive.current_limit_amt) > 0 then 1 else 0 end, prod_emart.financial_institution.financial_institution_nm,
リクエストT1 SELECT count(*) FROM ( SELECT * FROM prod_emart.d_financial_account_data_bal ) ALL INNER JOIN ( SELECT * FROM prod_emart.d_financial_account_date ) USING account_rk, valid_from_dt
リクエストT2 SELECT count(*) FROM prod_emart.d_financial_account_data_bal a JOIN prod_emart.d_financial_account_date b ON a.account_rk = b.account_rk AND a.valid_from_dt = b.valid_from_dt LEFT JOIN prod_emart.d_financial_account_data_scd sc ON a.account_rk = sc.account_rk AND b.scd_valid_from_dt = sc.scd_valid_from_dt;
D2(いくつかの列のデカルト積) select count(*) ,sum(t1.last_day_of_month_flg - t2.last_day_of_month_flg) as sum_flg ,sum(t1.business_dt - t2.valid_from_dt) as b1v2 ,sum(t1.valid_from_dt - coalesce(t2.scd_valid_from_dt,current_date)) as v1s2 ,sum(coalesce(t1.scd_valid_from_dt,current_date) - t1.business_dt) as s1b2 from prod_emart.D_FINANCIAL_ACCOUNT_DATE t1 INNER JOIN prod_emart.D_FINANCIAL_ACCOUNT_DATE t2 on t1.account_rk = t2.account_rk;
結果はクエリ実行の秒単位で表示されます。
リクエスト
| みどり
| エクサソル
| クリックハウス
| Memsql
| 樹花
| インパラ
|
N1
| 14
| <1
| -
| 108
| 6
| 78
|
N2
| 131
| 11
| -
| -
| 127
| エラー
|
N3
| 67
| 85
| -
| -
| 122
| 733
|
T1
| 14
| 1.8
| 64
| 70
| 20
| 100
|
T2
| 17
| 4.2
| 86
| 105
| 20
| 127
|
D1
| 1393
| 284
| -
| 45
| 1500
| -
|
D2
| > 7200
| 1200
| -
| > 7200
| エラー
| -
|
データベースで識別されたニュアンス
ヤンデックスクリックハウス
テスト中、このデータベースはタスクに適していないことが判明しました-データベースへの結合は名目上のみ表示されます。 たとえば、次のとおりです。
- JOINのみが適切な部分としてサブクエリでサポートされています。
- 結合の条件は、サブクエリ内にスローされません。
- 分散結合は非効率的です。
「重い」リクエスト(N1-N3)をClickhouse構文に書き換えることはほとんど不可能であることが判明しました。 メモリ制限も悲惨です-リクエスト内のサブクエリの結果は、クラスタの1つの(!)サーバーのメモリに収まるはずです。
このデータベースはBIタスクに適さないことが判明したという事実にもかかわらず、テスト結果によると、別のプロジェクトのリポジトリにアプリケーションが見つかりました。
それとは別に、公式Webサイトで入手できる非常に詳細で便利なドキュメント(残念ながら、データベースの使用に関するすべての側面を網羅しているわけではありません)に注意し、テスト中の質問に対する迅速な回答をしてくれたYandex開発者に感謝します。
SAP HANA
サーバー構成とクエリの最適化の大部分は、ロシアのSAPを代表するコンサルティング会社の同僚によって行われました。 それらがなければ、ベースを見てその利点を評価することはできません。実践が示しているように、HANAの経験が必要です。
HANAは、それ自体の結合テーブルの行数をカウントするのに非常に興味深いことが判明しました。
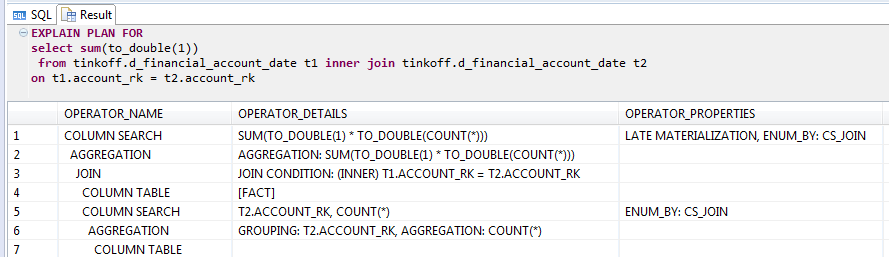 HANAの結合テーブル自体を使用したEXPLAINクエリ
HANAの結合テーブル自体を使用したEXPLAINクエリオプティマイザーは、結合を実行しなくても、統計を使用して結果を計算します。 これは良いトリックですが、たとえば「1 = 1」など、常にTrueである条件を追加すると、トリックは機能せず、Greenplumとほぼ同じ25分が得られます。
現時点では、HANAはリクエストの実行時に中間クエリ結果をディスクに配置できません。 したがって、十分なメモリがない場合、セッションは終了し、ユーザーは結果なしで残ります。
テストプロセス中に判明したように、結合に参加している2つのテーブルのデータがクラスターノード全体に正しく分散されている場合でも、実際には1つのクラスターノードのみで結合が実行されます。 要求を実行する前に、クラスター全体からのデータが1つのノードに単純に注がれ、そこで結合が既に計算されています。 テストに割り当てられた時間では、このロジックを無効にして、ローカルで結合を実行することは不可能でした。
ちなみに、メーカーは、可能であれば、テストの結果によって確認されるシングルモードデータベース構成を使用することを推奨しています。2台のマシンの構成を最適に機能させることは、1台の何倍も困難です。
エクサソル
データベースを使用する主な印象は、すぐに驚くほど安定して動作することです。 ほとんどすべてのテストは、他のDBMSと比較して速度が優れていることを示しています。 ただし、他の多くのDBMSとは異なり、これはブラックボックスです。sshを介してノードに接続し、iotop、htopなどを実行する機会さえありません。
もちろん、独自のサーバーを制御できないため、負担がかかります。 公平ではありますが、ベースの動作とアイロンの負荷に関するすべての必要なデータは、ベース内のシステムビューにあることに注意してください。
JDBC、ODBCドライバー、ANSI SQLの優れたサポート、およびOracleの特定の機能があります(例として、デュアルから1つを選択します)。 外部データベース(Oracle、PostgreSQL、MySQLなど)に接続するためのJDBCドライバーは既にデータベースに組み込まれているため、データのロードに非常に便利です。
EXASOLでは、完了したリクエストのみのプランを表示できます。 これは、中間結果を分析することにより、実行中に実行中に計画が作成されるためです。 古典的なExplainがなくても作業に干渉することはありませんが、より慣れ親しんでいます。
速く、便利で、安定しており、長いチューニングは必要ありません-設定して忘れてください。 一般に、一部はすべて正しいです。 しかし、ブラックボックスは驚くべきものです。
また、サポートの妥当性に留意したいと思います。これは、すべての質問に即座に回答しました。
Memsql
簡単かつ迅速に配置されます。 管理者は美しいですが、あまり賢くはありません。 例:クラスターにノードを追加することはできますが、管理パネルから削除することはできません/難しい/わかりにくい 現在および完了したリクエストを表示できますが、それらに関する詳細は表示できません。
 memsql adminでは、1秒あたりのレコード数をツイートできます
memsql adminでは、1秒あたりのレコード数をツイートできますMemSQLは作業中にプロセッサをロードするのが大好きで、メモリオーバーフローによるエラーはほとんどありませんでした。
MemSQLは、2つのテーブルを結合する前に、結合キーによる再パーティション化(ノードによるデータの再配布)を行います。
この場合、複雑なシャードキー(account_rk、valid_from_dt)を使用してdata_balおよびdateテーブルを保存できます。scdテーブルのシャーディングキーは(account_rk、scd_valid_from_dt)です。 この場合、data_balとdateの間の接続はすぐに発生し、リクエストが実行されると、データはaccount_rkとscd_valid_from_dtによって再配布され、次のステップではaccount_rkによってFinancial_accountテーブルに接続されます。 サポートによると、再パーティション化は非常に時間のかかる操作です。
したがって、多数の多様な結合のために、データベースに対するクエリは困難であることが判明しました。 Greenplumでは、リストされたテーブル間の結合はローカルで発生するため、ノードを介して再配布することなく、より高速に、いわゆる「再配布モーション」と呼ばれます。
一般に、MemSQLはMySQLからの移行に最適なDBMSであり、最も複雑な分析ではないようです。
インパラ
Impalaを含むClouderaクラスターのインストールは、非常にシンプルで、十分に文書化されています。
ただし、Impalaは他のデータベースと比較して速度に違いはないことに注意してください。たとえば、d_financial_account_not_additiveのcount(*)をカウントするクエリは、Impalaで3.5分間機能しました。数十秒以下。
また、興味深い実験も実施しました。前に書いたように、d_financial_account_not_additiveビューには2つの結合があります。 それぞれに、account_rkによるデータ型整数の接続と、データ型の日付を持つフィールドによる接続があります。 Impalaには日付データ型がないため、タイムスタンプを使用しました。 興味を引くために、タイムスタンプは、unixタイムスタンプを含むbigintに置き換えられました。 クエリ結果はすぐに改善されました。 次のステップでは、account_rkからのデータと日付フィールドvalid_from_dtおよびscd_valid_from_dtを組み合わせて、1つのフィールドのみに結合を提供しました。 これは簡単な方法で行われました。
account_valid_from = account_rk * 100000 + cast(unix_timestamp(valid_from_dt)/86400 as int)
1つのフィールドに参加すると、約30分のゲインが得られますが、いずれにしても、他のDBMSの数倍です。
基本的なクエリは数倍長く機能しました。 N2 - , .
Impala hash-, .
結論の代わりに
« - -, —
- -, », . , - ETL BI, - — .
, , , BI-.
, :
—
— (aka 4etvegr)
—
— (aka kapustor)
, , Virtua Hamster ( Sega 32).