
テキストデータ交換フォーマットの問題は何ですか? 彼らは遅いです。 そして、遅いだけでなく、途方もなく遅いです。 はい、それらはバイナリプロトコルと比較して冗長であり、理論的には、テキストシリアライザは冗長とほぼ同じくらい遅いはずです。 しかし、実際には、テキストシリアライザーは、バイナリカウンターよりも桁違いに劣ることがあります。
バイナリ形式に対するJSONの利点については説明しません。各形式には、それぞれに適した応用分野があります。 しかし、多くの場合、最初の壊滅的な非効率性のために非常に快適ではないため、便利な何かを放棄せざるを得ません。 開発者はJSONを拒否します。JSONが問題の解決に最適であっても、それがシステムのボトルネックであることが判明したからです。 もちろん、責任があるのはJSONだけではなく、対応するライブラリの実装です。
この記事では、一般的なテキスト形式パーサー、特にJSONの問題だけでなく、最も負荷の高いプロジェクトで長年使用してきたライブラリーについても説明します。 速度と使いやすさの両方の点で非常に適しているため、より適切な場合はバイナリ形式を拒否することもあります。 もちろん、私はいくつかの境界条件を意味します。
悲劇の規模を評価するために、よく知られているいくつかのJSONライブラリgoogle :: protobuf、「手動」JSONシリアル化、および
wjsonライブラリのあまり複雑ではないオブジェクトのシリアル化時間を測定しました。
結果を図に示します。
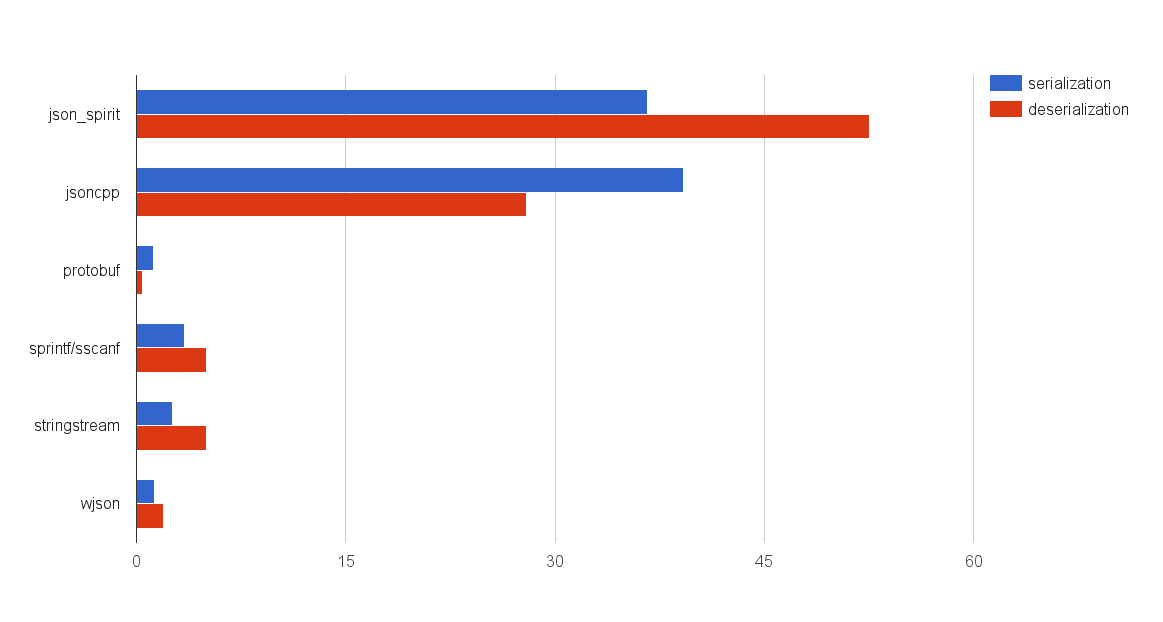
私は、これらの結果がやがて、控えめに言っても、少し驚いたことを認めます。
jsoncppとjson_spirit(boost :: spiritに基づく)のパフォーマンスは、壊滅的にgoogle :: protobufに負けます。 sprintf / sscanfまたはstd :: stringstreamを使用した「手動」シリアル化の状況は、はるかに優れています。 ただし、最初の2つのツールを使用する場合は、急いですべてをドロップせず、「自分で何をする必要があるかを伝えました!」-プロジェクトをやり直してください。 グラフでは、測定はsprintf / sscanfの1回の呼び出しに対するものであり、JSONオブジェクトのフィールドを並べ替えたりスキップしたりすることなく、シリアル化可能なオブジェクトを詰め込みました。 オブジェクトのシリアル化に関するセクションで、より詳細な数値を示します。
この記事では、JSONをパフォーマンスに焦点を当てたメッセージング形式として見ています。 したがって、このコンテキストで特定のテクノロジーを比較します。 また、開発(コンパイル)段階でのメッセージ構造がわかっていることも意味します。 提案されているwjsonライブラリも、これらのタスク専用に開発されています。 もちろん、未知のJSONドキュメントを使用して調べることができます。おそらく、wjsonは多くのライブラリ(いずれの場合もjsoncppとjson_spirit)よりも効果的です。
実際、wjsonは、たとえば上記のライブラリよりも概念的にprotobufに近いです。 同様に、メタ記述に従ってシリアル化/逆シリアル化コードを生成します。 しかし、protobufとは異なり、外部アプリケーションではなく、C ++コンパイラを使用します。 以前の記事で、
tic-tac-toeを再生するようコンパイラーに教える方法を示しました。また、シリアル化コードを生成する方法を教えることはテクニックの問題です。
しかし、私が最も気に入っているのは、シリアライズ可能なデータ構造に追加機能を実装する必要がないことです。個別にフライ、個別にカツレツを。 さらに、多重継承、ネストの集約、列挙型のシリアル化などのいくつかの利点を含む、継承がサポートされています。
当初、wjsonは、プログラマが多くの必要なチェックを伴う実行時コードを記述しないようにするために、c ++テンプレートのJSON構造の宣言的な記述のためだけに考案されました。 しかし、コンパイラーが積極的にインライン・イットのような構成であることがすぐに明らかになりました。 そして、これらの設計を十分に効率的に動作させて、許容可能なパフォーマンスレベルに到達するには、かなりの労力が必要でした。
では、なぜJSONはそんなに遅いのでしょうか?XMLを使用した場合、デシリアライズには2つのアプローチがあることに気づきます-これらはDOM(Document Object Model)とSAX(Simple API for XML)です。 DOMの場合、テキストはノードのツリーに変換され、対応するAPIを使用して調べることができます。 また、SAXパーサーの動作は異なります。ドキュメントをスキャンし、ユーザーコードによって処理される特定のイベントを生成します。これは通常、コールバック関数として実装されます。 何らかの方法で、ほとんどのテキストデシリアライザーはこれらのアプローチのいずれかを使用するか、または組み合わせます。
DOMの主な欠点は、常に高価なツリーを構築する必要があることです。 逆シリアル化の段階でそのようなツリーを構築するプロセスは、適用されたアルゴリズムの実行よりもかなり時間がかかる場合があります。 ただし、これに加えて、必要なフィールドを検索し、それらを内部データ構造に変換する必要があります。 そして、このタスクはすでにプログラマーの肩にかかっており、非常に非効率的に実装できます。 実際、これは主要なリソースを食い尽くすのはDOMツリーの構築であるため、それほど重要ではありません。
SAXパーサーははるかに高速です。 概して、彼らは対応するハンドラーを呼び出して、テキストを一度通過します。 JSONにこのようなパーサーを実装するのは簡単な作業です。JSON自体は不名誉に簡単であり、これがその魅力です。 しかし、データを抽出するためにそれを使用するプログラマーからのより多くの努力が必要です。 そして、これはプログラマにとってより多くの作業であり、より多くのエラーと非効率的なコードであり、SAXの有効性を無効にする可能性があります。
一般的に、効果的なシリアル化のトピックは、普遍的なソリューションを開発するという観点から非常に興味深いものです。 しかし、応用プログラミングの観点から見ると、これは非常に退屈で退屈であり、その結果、膨大な量の効果のないたわごとです。 プログラマがアプリケーションコードを最適化することは非常に興味深いことです。逆シリアル化は1桁遅く、このコンテキストでの最適化はあまり意味がなく、あまり気にしません。
しかし、何らかの理由で既存のソリューションのほとんどが私たちに合わない場合は、手動でやってみましょう。JSONの利点は非常にシンプルなフォーマットです。 そして、ここで私は非常に興味深い話を数回観察しました。 プログラマがバイナリプロトコルを使用する場合、ビットを慎重にシフトし、コードを最適化して楽しんでいます。 しかし、彼が同じコンテキストでテキスト形式で作業するように申し出られた場合、何かが彼の脳で切断されているようです。 より正確には、逆に、彼は高次の自転車の構築に対する保護をオンにします。これにより、バイナリ形式で作業するときに特に苦労することはありませんでした。 彼は、JSONで動作するコードを何らかの方法で高貴にするために、ライブラリのヒープを接続して、いくつかの美しい(ただし、原則としてあまり効果的ではない)関数のテキストを操作します。 そして、結果はまだ嘆かわしいです。
atoiの実装を書くことを考えている人はほとんどいませんが、私たちはまだ試みます:
template<typename T, typename P> P my_atoi( T& v, P beg, P end) { if( beg==end) return end; bool neg = ( *beg=='-' ); if ( neg ) ++beg; if ( beg == end || *beg < '0' || *beg > '9') return 0; if (*beg=='0') return ++beg; v = 0; for ( ;beg!=end; ++beg ) { if (*beg < '0' || *beg > '9') break; v = v*10 + (*beg - '0'); } if (neg) v = static_cast<T>(-v); return beg; }
実際、すべてはシンプルですが、古典的なatoiよりも普遍的で便利です(私の意見では)。 しかし、最も興味深いのは、2倍の速度で動作することです。 はい、もちろん、大部分はインライン置換のためですが、それはポイントではありません。 ちなみに、sscanf / sprintfは、%dよりも速く%sパラメーターを実行し、同等の行の長さを持ちます。
sscanf / sprintfの危険性については今からお話ししません。既に何度も書いており、さらに安全な代替手段、たとえばstd :: stringstreamまたはboost :: lexical_cast <>があります。 残念ながら、C ++を含む多くのプログラマーは、真のCはより高速で、that望の永続性を備えたsscanf / sprintfを使い始めるという神話に導かれています。 しかし、この文脈では、問題は言語にあるのではなく、1つまたは別の機能の実装にあります。 たとえば、std :: stringstreamを正しく使用すると、Cの選択肢より悪くなることはありませんが、たとえば、boost :: lexical_cast <>はこの点で著しく劣ることがあります。
したがって、サードパーティのライブラリだけでなく、使い慣れたツールのパフォーマンスについても慎重にテストする必要があります。 ただし、インターネット上の必要な実装を確認することにより、多くの場合、サイクルが速くなります。
my_atoiのコードはwjsonからほぼ完全に変更されていないため、誰かが役に立つかもしれません。 シリアル化のコードはもう少し混乱しています。
JSONの残りの部分およびインライン置換の構成要素に対するこのようなバイトごとの並べ替えにより、より高速な逆シリアル化を実現できます。 何らかの方法でそれらを1つのデザインにアセンブルすると、一種のSAXパーサーが得られますが、これも非常に高速です。
単純型
シリアル化の例をすぐに見てみましょう。
int value = 12345; char bufjson[100]; char* ptr = wjson::value<int>::serializer()(value, bufjson); *ptr = '\0'; std::cout << bufjson << std::endl;
ここで、wjson :: value <int>は、この型のシリアライザー定義を含む整数型のJSON記述です。 次に、シリアライザーオブジェクトを作成し、オーバーロードされた演算子()を呼び出します。 一部の人にとっては、そのようなエントリは奇妙に見えるかもしれませんが、JSONシリアライザオブジェクトには状態がなく、そのインスタンスを作成する意味がないことを強調するために使用します。
シリアライザが静的関数ではない理由の質問にすぐに答えます。 第一に、コンパイラーはコンパイル時間の点で静的要素を本当に好きではありません。第二に、とにかく、私にとってより便利です。 実際、上記のネタバレの下に示したコードは、my_itoaを例に使用して完全に置き換えられます。
値<>コンストラクトは、整数だけでなく、実際のもの、文字列、およびブール値にも使用されます。 定義:
template<typename T, int R = -1> struct value { typedef T target; typedef implementation_defined serializer; };
ブール型および整数型の場合、引数Rは使用されません。 std :: stringまたはstd :: vector <char>などの文字列の場合、これは予約のサイズであり、実際の文字列の場合は表示形式です。
シリアライザークラスは、シリアル化に加えて、逆シリアル化機能を提供します。 2つのオーバーロード演算子():
template<typename T> class implementation_defined { public: template<typename P> P operator()( const T& v, P itr); template<typename P> P operator() ( T& v, P beg, P end, json_error* e ); };
シリアル化関数は、シリアル化可能な型への参照に加えて、たとえば次のような出力反復子を受け入れます。
int value = 12345; std::string strjson; wjson::value<int>::serializer()(value, std::back_inserter(strjson)); std::cout << strjson << std::endl; std::stringstream ssjson; wjson::value<int>::serializer()(value, std::ostreambuf_iterator<char>(ssjson)); std::cout << ssjson.str() << std::endl; wjson::value<int>::serializer()(value, std::ostreambuf_iterator<char>(std::cout)); std::cout << std::endl;
デシリアライザは、入力へのランダムアクセスイテレータを受け入れ、バッファの開始と終了を示すとともに、エラーオブジェクトへのポインタ(ゼロの場合もある)を示します。
value = 0; char bufjson[100]=”12345”; wjson::value<int>::serializer()(value, bufjson, bufjson + strlen(bufjson), 0 ); std::cout << value << std::endl; value = 0; std::string strjson=”12345”; wjson::value<int>::serializer()(value, strjson.begin(), strjson.end(), 0 ); std::cout << value << std::endl;
シリアライザーとデシリアライザーの両方がイテレーターを返します。 最初のケースでは、シリアル化が終了した場所を示し、2番目のケースでは、エラーがなければ、シリアル化が終了した入力バッファ内の場所を示します。 エラーが発生した場合、バッファの末尾へのポインタを返します。null以外のポインタが渡された場合はエラーコードを返します。 少し後でエラー処理について説明します。そして、単純な型を完成させます。
サポートされる整数:char、unsigned char、short、unsigned short、int、unsigned int、long int、unsigned long、long long、unsigned long long。 ブール値(bool)を使用すると、すべてが同じであり、「true」または「false」にシリアル化されます。 デシリアライズ中の他のタイプからの自動変換はサポートされていません。
パフォーマンスに関して特に気にしなかった唯一のタイプは実際のタイプ(float、double、long double)で、通常のstd :: stringstreamがあります。 これは主に、実際に作業したプロジェクトで、整数型(ミリメートル単位の転送メーターなど)、またはCPUコアごとに10K以内の負荷に置き換えることができるという事実によるものです。これは重要ではありません。 トラフィックの大部分がある場合-それが現実であり、どのような方法でもそこから逃れることができない場合、最適化と混同することは理にかなっています。 デフォルトでは、実際のものは仮数でシリアル化されます。 R> = 0の場合、固定コンマの場合:
double value = 12345.12345; std::string json; wjson::value<double>::serializer()(value, std::back_inserter(json)); std::cout << json << std::endl; json.clear(); wjson::value<double, 4>::serializer()(value, std::back_inserter(json)); std::cout << json << std::endl;
結果:
1.234512e+04 12345.1234
utf-8を使用する場合、一見するとすべてが文字列でシンプルになりますが、次の点に注意する必要があります。
- 連載
- 32(スペース)のコードを持つすべてのutf-8文字はそのままコピーされます
- 文字 '' '、' \ '、' / '、' \ t '、' \ b '、' \ r '、' \ n '、' \ f 'はJSON仕様に従ってエスケープされた' \ '
- コードが32未満の残りの文字は、16進形式(\ uXXXX)でシリアル化されます
- utf-8は\ xXX形式でシリアル化されたバイトではなく、utf-8でのみ動作するJSON仕様に準拠していませんが、wjsonデシリアライザーはこの形式を理解します
- デシリアライゼーション
- エスケープされた文字はエスケープされません
- \ uXXXX形式の組み合わせは、32未満の値を除き、utf-8に変換されます(XXXXが '\ t'、 '\ b'、 '\ r'、 '\ n'、 '\ f'をエンコードしない場合、変換なし)
- \ xXXの形式の組み合わせは、チェックなしで非表示になります
- 他のすべてのutf-8文字はそのままコピーされます
一部のサードパーティライブラリは、特に負担をかけることなく、ASCII範囲(コード> 127)以外のすべてを\ uXXXX形式でシリアル化します。 ただし、wjsonを使用して同様の文字列を逆シリアル化すると、utf-8でデコードされます。 wjsonが再シリアル化されると、このエスケープ処理はなくなります。
通常、ソフトウェアエラーが原因で、行の中央が '\ 0'であり、wjsonを含むほとんどのシリアライザーによって\ u0000に変換されますが、逆シリアル化された場合、\ 0に変換されず、そのまま残ります。
\ xXX形式のサポートは、無効なデータ(シリアル化またはコンパイルされていない)を意味しないwjsonシリアル化の概念の制限によってのみ決定されます。 バイナリデータをシリアル化するには、たとえばBase64を使用します。
文字列のシリアル化の例 #include <wjson/json.hpp> #include <iostream> #include <cstring> int main() { const char* english = "\"hello world!\""; const char* russian = "\"\\u041F\\u0440\\u0438\\u0432\\u0435\\u0442\\u0020\\u043C\\u0438\\u0440\\u0021\""; const char* chinese = "\"\\u4E16\\u754C\\u4F60\\u597D!\""; typedef char str_t[128]; typedef wjson::value< std::string, 128 >::serializer sser_t; typedef wjson::value< std::vector<char> >::serializer vser_t; typedef wjson::value< str_t >::serializer aser_t; std::string sstr; std::vector<char> vstr; str_t astr={'\0'}; // sser_t()( sstr, english, english + std::strlen(english), 0); vser_t()( vstr, russian, russian + std::strlen(russian), 0); aser_t()( astr, chinese, chinese + std::strlen(chinese), 0); // std::cout << "English: " << sstr << "\tfrom JSON: " << english << std::endl; std::cout << "Russian: " << std::string(vstr.begin(), vstr.end() ) << "\tfrom JSON: " << russian << std::endl; std::cout << "Chinese: " << astr << "\tfrom JSON: " << chinese << std::endl; // english stdout std::cout << std::endl << "English JSON: "; sser_t()( sstr, std::ostream_iterator<char>( std::cout) ); std::cout << "\tfrom: " << sstr; // russian stdout std::cout << std::endl << "Russian JSON: "; vser_t()( vstr, std::ostream_iterator<char>( std::cout) ); std::cout << "\tfrom: " << std::string(vstr.begin(), vstr.end() ); // chinese stdout std::cout << std::endl << "Chinese JSON: "; aser_t()( astr, std::ostream_iterator<char>( std::cout) ); std::cout << "\tfrom: " << astr; std::cout << std::endl; }
結果:
English: hello world! from JSON: "hello world!"
Russian: ! from JSON: "\u041F\u0440\u0438\u0432\u0435\u0442\u0020\u043C\u0438\u0440\u0021"
Chinese: 世界你好! from JSON: "\u4E16\u754C\u4F60\u597D!"
English JSON: "hello world!" from: hello world!
Russian JSON: " !" from: !
Chinese JSON: "世界你好!" from: 世界你好!
配列
JSON配列を記述するために、wjson :: valueに似た構造が使用されます。
template<typename T, int R = -1> struct array { typedef T target; typedef implementation_defined serializer; };
ここで、Tはシリアル化可能なコンテナーであり、Rはこのメソッドをサポートするstlコンテナーの予約のサイズです。 すべてが単純に思えますが、次の形式のレコード:wjson :: array <std :: vector <int >>は機能しません。 コンテナ要素(この場合はint)をシリアル化する方法はわかりません。 正しいエントリは次のようになります。
typedef wjson::array< std::vector< wjson::value<int> > > vint_json;
パラメーターTとして、必要なコンテナーを渡しますが、コンテナー要素のタイプの代わりに、JSON記述を渡します。 以下がサポートされています。
- V [N]
- std ::ベクトル
- std :: deque
- std ::配列
- std ::リスト
- std ::セット
- std ::マルチセット
- std :: unordered_set
- std :: unordered_multiset
もちろん、最初の4つのオプションは最大のパフォーマンスを提供します。 リストと連想コンテナの入力は、それ自体が高すぎます。
古典的なs-arrayの例:
typedef wjson::value<int> int_json; typedef int vint_t[3]; typedef wjson::array< int_json[3] > vint_json;
もちろん、次の例に示すように、多次元配列がサポートされています(たとえば、ベクトルのベクトルなど)。
ベクトルベクトルの例 #include <wjson/json.hpp> #include <wjson/strerror.hpp> #include <iostream> int main() { // typedef wjson::value<int> int_json; typedef std::vector<int> vint_t; typedef wjson::array< std::vector<int_json> > vint_json; std::string json="[ 1,\t2,\r3,\n4, /**/ 5 ]"; vint_t vint; vint_json::serializer()(vint, json.begin(), json.end(), NULL); json.clear(); vint_json::serializer()(vint, std::back_inserter(json)); std::cout << json << std::endl; // ( ) typedef std::vector< vint_t > vvint_t; typedef wjson::array< std::vector<vint_json> > vvint_json; json="[ [], [1], [2, 3], [4, 5, 6] ]"; vvint_t vvint; vvint_json::serializer()(vvint, json.begin(), json.end(), NULL); json.clear(); vvint_json::serializer()(vvint, std::back_inserter(json)); std::cout << json << std::endl; // ( ) typedef std::vector< vvint_t > vvvint_t; typedef wjson::array< std::vector<vvint_json> > vvvint_json; json="[ [[]], [[1]], [[2], [3]], [[4], [5, 6] ] ]"; vvvint_t vvvint; vvvint_json::serializer()(vvvint, json.begin(), json.end(), NULL); json.clear(); vvvint_json::serializer()(vvvint, std::back_inserter(json)); std::cout << json << std::endl; }
ここでは、JSON文字列を取得し、それをコンテナにデシリアライズし、クリアし、同じ文字列と出力にシリアル化します。
[1,2,3,4,5] [[],[1],[2,3],[4,5,6]] [[[]],[[1]],[[2],[3]],[[4],[5,6]]]
json行は、ラインフィードやCスタイルのコメントなど、配列の要素間に空白が存在する可能性があることを示しています。これはjson構成を実装するときに非常に便利です。
動的コンテナの最大サイズに制限はありません。s-arraysおよびstd :: arrayの場合、配列の実際のサイズは制限です。 着信JSON要素の数が少ない場合、残りの要素にはデフォルト値が入力され、それ以上の場合、余分な要素は単純に破棄されます。
JSON配列に異なるタイプの要素が含まれる場合JSON配列にさまざまなタイプの要素が含まれる場合、それらは2段階でシリアル化および非シリアル化されます。 まず、次のように、任意の非シリアル化されていないJSON構造を含む文字列のコンテナを記述する必要があります。
typedef std::vector<std::string> vstr;
生のJSONを記述するには:
template<typename T = std::string, int R = -1> struct raw_value;
JSON文字列をそのままコンテナTにコピーします。そして、パーサーを使用して、JSON要素のタイプを判別し、それに応じてデシリアライズする必要があります。 以下の例では、数値の配列[1、 "2"、[3]]を読み取って、すべての要素をインクリメントし、フォーマットを維持しながらそれをシリアル化しようとしています。
コード #include <wjson/json.hpp> #include <wjson/strerror.hpp> #include <iostream> int main() { typedef std::vector< std::string > vect_t; typedef ::wjson::array< std::vector< ::wjson::raw_value<std::string> > > vect_json; vect_t inv; vect_t outv; std::string json = "[1,\"2\",[3]]"; std::cout << json << std::endl; vect_json::serializer()( inv, json.begin(), json.end(), 0 ); for ( auto& v : inv ) { outv.push_back(""); if ( wjson::parser::is_number(v.begin(), v.end()) ) { int num = 0; wjson::value<int>::serializer()( num, v.begin(), v.end(), 0); ++num; wjson::value<int>::serializer()( num, std::back_inserter(outv.back()) ); } else if ( wjson::parser::is_string(v.begin(), v.end()) ) { std::string snum; wjson::value<std::string>::serializer()( snum, v.begin(), v.end(), 0); int num = 0; wjson::value<int>::serializer()( num, snum.begin(), snum.end(), 0); ++num; snum.clear(); wjson::value<int>::serializer()( num, std::back_inserter(snum) ); wjson::value<std::string>::serializer()( snum, std::back_inserter(outv.back()) ); } else if ( wjson::parser::is_array(v.begin(), v.end()) ) { std::vector<int> vnum; wjson::array< std::vector< wjson::value<int> > >::serializer()( vnum, v.begin(), v.end(), 0); ++vnum[0]; wjson::array< std::vector< wjson::value<int> > >::serializer()( vnum, std::back_inserter(outv.back()) ); } else { outv.back()="null"; } } json.clear(); vect_json::serializer()( outv, std::back_inserter(json) ); std::cout << json << std::endl; }
結果:
[1,"2",[3]] [2,"3",[4]]
これは、後で説明するオブジェクトと辞書でも機能します。 数字を文字列または実際には数字の2つのオプションでしか表現できない場合は、ラッパーを使用できます。
template<typename J, bool SerQ = true, bool ReqQ = true, int R = -1> struct quoted;
- J-ソースJSONの説明
- SerQ-文字列に事前シリアル化
- ReqQ-入力JSONは「文字列」でなければなりません
- 中間バッファー(行)のR予約
このコンストラクトは、実際にはどのJSON記述でも機能します。 SerQパラメーターは、デュアルシリアル化を有効にします。 たとえば、数値の場合、これは単に引用符を意味します。 ReqQパラメーターには、二重逆シリアル化が含まれます。 入力にJSON文字列が必要です。 オフの場合、ルールはもう少し複雑です。 入力がJSON文字列でない場合は、事前の逆シリアル化を行わずに、Jデシリアライザーを単に開始します。 入力がJSON文字列の場合、中間のstd ::文字列に逆シリアル化されます。 Jが非文字列エンティティを記述する場合、中間std ::文字列からの再シリアル化解除。 文字列エンティティの場合、逆シリアル化を繰り返す必要があると判断します。 これは、最初の逆シリアル化の後、中間行が引用符で始まる場合、これは二重シリアル化された行であり、再び逆シリアル化されることを意味します。
wjson :: quoted <>は追加のオーバーヘッドを与えることは明らかであり、何らかの理由で、クライアントが期限までに番号を「だまし」、シリアル化するか、ネストされたオブジェクトの二重シリアル化を行う場合、一時的な松葉杖と見なされる必要があります。
パーサー
wjsonには、2つのタイプに分類できる静的メソッドのみを含むパーサークラスがあります。 これは特定のJSONタイプへの準拠のチェックであり、したがって、メソッドはパーサーです。 各JSONタイプには独自のメソッドがあります。
方式リスト class parser { public: template<typename P> static P parse_space( P beg, P end, json_error* e); template<typename P> static P parse_null( P beg, P end, json_error* e ); template<typename P> static P parse_bool( P beg, P end, json_error* e ); template<typename P> static P parse_number( P beg, P end, json_error* e ); template<typename P> static P parse_string( P beg, P end, json_error* e ); template<typename P> static P parse_object( P beg, P end, json_error* e ); template<typename P> static P parse_array( P beg, P end, json_error* e ); template<typename P> static P parse_value( P beg, P end, json_error* e ); };
デシリアライザーと同様に、ここでのbegはバッファーの始まり、バッファーの終わり、およびnullptrでない場合は「e」でエラーコードが書き込まれます。 成功した場合、現在のエンティティの最後の文字に続く文字へのポインタが返されます。 エラーが発生した場合、endが返され、eが初期化されます。
特定の構造の複数のJSONオブジェクトを含む文字列があり、それらが改行または他の空白で区切られている場合、次のように処理できます(エラー処理なし)。
for (;beg!=end;) { beg = wjson::parser::parse_space(beg, end, 0); beg=my_json::serializer()(dict, beg, end, 0); }
すべてのシリアライザは、最初の文字がデシリアライズ可能なオブジェクトの文字でなければならないことを前提としています。そうしないとエラーが発生します。 しかし、すでに述べたように、オブジェクトと配列の内部には、デシリアライザーが同じparse_spaceで解析するコメントを含む空白文字が含まれる場合があります。 複数のJSONエンティティで文字列を解析する例:
wjson::json_error e; for (;beg!=end;) { beg = wjson::parser::parse_space(beg, end, &e); beg = wjson::parser::parse_value(beg, end, &e); if ( e ) abort(); }
ここで、parse_valueはJSONエンティティの妥当性をチェックします。 入力parse_spaceが空白でない場合、単純にbegを返します。 たとえば、閉じられていないCスタイルのコメントが見つかった場合、エラーを返すことがありますが、ここでは追加のチェックは不要です。 初期化されたエラーオブジェクトがパーサーへの入力に到着した場合(デシリアライザーと同様)、単にendを返します。
特定のJSONエンティティを定義するには、次のメソッドセットがあります。
方式リスト class parser { public: template<typename P> static bool is_space( P beg, P end ); template<typename P> static bool is_null( P beg, P end ); template<typename P> static bool is_bool( P beg, P end ); template<typename P> static bool is_number( P beg, P end ); template<typename P> static bool is_string( P beg, P end ); template<typename P> static bool is_object( P beg, P end ); template<typename P> static bool is_array( P beg, P end ); };
バッファの先頭と末尾へのポインタを取得するという事実にもかかわらず、これらのメソッドは最初の文字でエンティティを決定します。{はオブジェクト、[は配列、 "は文字列、数字は数字、t、fまたはnはtrue 、falseまたはnull。 したがって、たとえばis_objectがtrueを返す場合、これが有効なオブジェクトであることを確認するには、parse_objectを呼び出してエラーがないことを確認する必要があります。
エラー処理
逆シリアル化中のエラーチェックはほとんどの場合必要です。 例では、明確にするためだけにこれを行いません。 外部の文字が元の配列に埋め込まれている例を考えてみましょう。
#include <wjson/json.hpp> #include <wjson/strerror.hpp> #include <iostream> int main() { typedef wjson::array< std::vector< wjson::value<int> > >::serializer serializer_t; std::vector< int > value; std::string json = "[1,2,3}5,6]"; wjson::json_error e; serializer_t()(value, json.begin(), json.end(), &e ); if ( e ) { std::cout << "Error code: " << e.code() << std::endl; std::cout << "Error tail of: " << e.tail_of() << std::endl; if ( e.type() == wjson::error_code::ExpectedOf ) std::cout << "Error expected_of: " << e.expected_of() << std::endl; std::cout << "Error position: " << wjson::strerror::where(e, json.begin(), json.end() ) << std::endl; std::cout << "Error message: " << wjson::strerror::message(e) << std::endl; std::cout << "Error trace: " << wjson::strerror::trace(e, json.begin(), json.end()) << std::endl; std::cout << "Error message & trace: " << wjson::strerror::message_trace(e, json.begin(), json.end()) << std::endl; } }
実際には、wjson :: json_errorエラーオブジェクト自体には、エラーコードに関する情報と、パーサーが不整合を検出したバッファーの末尾に対する位置が含まれています。 特別なタイプ「Expected of」のエラーの場合、彼が期待したキャラクター。
読み取り可能なメッセージを取得するには、wjson :: strerrorクラスを使用します。 上記の例では、JSON配列で}文字が検出され、パーサーはコンマ(ウェル、または角括弧)を予期し、それを報告します。 この例は、エラー分析に使用可能なすべてのメソッドを示しています。 結果は次のとおりです。
Error code: 3 Error tail of: 5 Error expected_of: , Error position: 6 Error message: Expected Of ',' Error trace: [1,2,3>>>}5,6] Error message & trace: Expected Of ',': [1,2,3>>>}5,6]
したがって、エラーコード、読み取り可能なメッセージだけでなく、それが発生した場所も取得できます。トレース時には、「>>>」の組み合わせが使用されます。JSONオブジェクト
JSONオブジェクトをデータ構造に直接デシリアライズすることが、wjsonの設計目的です。単純な構造を考えてみましょう。 struct foo { bool flag = false; int value = 0; std::string string; };
JSONタイプでシリアル化する必要があります: { "flag":true, "value":42, "string":" !"}
JSONオブジェクトは、コロンで区切られた名前と値(任意のJSON)で構成されるフィールドのリストの単なる列挙です。単一のフィールドをシリアル化するには、コンパイル段階で既知の名前をコピーし、コロンを追加して、値をシリアル化する必要があります。設計はこの概念を実装します。 template<typename N, typename T, typename M, MT::* m, typename J = value<M> > struct member;
- N-フィールド名
- T-構造のタイプ
- M-フィールドタイプ
- m-構造体フィールドへのポインター
- J-JSONフィールドの説明
ただし、テンプレートパラメータを使用して文字列を明示的に渡すことには問題があります。したがって、次のトリックを使用します。構造フィールド名ごとに、次の形式の構造を作成します。旗の名前 struct n_flag { const char* operator()() const { return “flag”; } };
テンプレートパラメータで渡すことができます。もちろん、名前ごとにこのような構造を作成することはあまり便利ではないため、まれにマクロ置換を許可した場合があります。これを行うには、マクロを使用できます。 JSON_NAME(flag)
ほぼ同じ構造が作成されます。n_プレフィックスは歴史的な理由で使用されます。ただし、気に入らない場合は、2番目のオプションを使用できます。 JSON_NAME2(n_flag, “flag”)
これにより、任意の名前と文字列で構造体を作成できます。単一のフィールドを説明する例: wjson::member< n_flag, foo, bool, &foo::flag>
単純型の場合、JSONの説明(wjson :: value <>)は省略できますが、他のすべての場合は必須です。構造体フィールド自体のシリアル化はあまり意味がないため、次のようにすべてのフィールドの説明をリストにまとめる必要があります。 wjson::member_list< wjson::member<n_flag, foo, bool, &foo::flag>, wjson::member<n_value, foo, int, &foo::value>, wjson::member<n_string, foo, std::string, &foo::string> >
C ++ 11の場合、フィールドの数は制限されません。c++ 03の場合、26個の要素の制限があり、ネストされたmember_listを使用して簡単に回避できます。JSONオブジェクトを構造にシリアル化するための規則は、次の構成によって提供されます。 template<typename T, typename L> struct object { typedef T target; typedef implementation_defined serializer; typedef implementation_defined member_list; };
ここで、Tはデータ構造のタイプ、Lはシリアル化可能なフィールドのリスト(member_list)です。JSONオブジェクトのシリアライズおよびデシリアライズの例 #include <wjson/json.hpp> #include <wjson/strerror.hpp> #include <iostream> struct foo { bool flag = false; int value = 0; std::string string; }; JSON_NAME(flag) JSON_NAME(value) JSON_NAME(string) typedef wjson::object< foo, wjson::member_list< wjson::member<n_flag, foo,bool, &foo::flag>, wjson::member<n_value, foo,int, &foo::value>, wjson::member<n_string, foo,std::string, &foo::string> > > foo_json; int main() { std::string json="{\"flag\":false,\"value\":0,\"string\":\" \"}"; foo f; foo_json::serializer()( f, json.begin(), json.end(), nullptr ); f.flag = true; f.string = " "; std::cout << json << std::endl; foo_json::serializer()( f, std::ostream_iterator<char>(std::cout) ); }
結果:
{"flag":false,"value":0,"string":" "} {"flag":true,"value":0,"string":" "}
私があなたに注意を引きたいのは:- 元の構造(foo)には永続的であるという記述はありません。
- フィールドは、member_listに記述されている順序で正確にシリアル化されます。
- JSON , member_list
- .
- JSON
- member_list
- , ( )
入力JSONでフィールドの順序がJSON記述の順序と一致する場合、実際には1回のパスで逆シリアル化が可能な限り迅速に行われます。不足しているフィールドやパフォーマンス上の余分な要素は、大きな影響を与えません(それらは単に無視されます)。しかし、JSONのフィールドがランダムな順序で来るとどうなりますか?もちろん、これはパフォーマンスに影響します。これは、パーサーが混乱し、最初にフィールドを反復処理するためです。しかし、フィールドオーダーのトピックをまったく気にしないことをお勧めします。実際に感じ始める前であっても、デシリアライズの時間ではなく、JSONの冗長性の問題に遭遇し、データ交換フォーマットの変更について考える必要があります。これは、必ずしもバイナリプロトコルに切り替えることを意味しません。たとえば、JSON配列の形式でオブジェクトを転送することができます。この場合、位置は構造の特定のフィールドに厳密に対応します。特別な場合、多くのゼロが送信される場合、そのような形式はprotobufよりもコンパクトで高速になります。根拠にならないように、パフォーマンスのために次の構造デシリアライゼーションを実行しました。 struct foo { int field1 = 0; int field2 = 0; int field3 = 0; std::vector<int> field5; };
fooのJSON記述 JSON_NAME(field1) JSON_NAME(field2) JSON_NAME(field3) JSON_NAME(field5) typedef wjson::object< foo, wjson::member_list< wjson::member<n_field1, foo, int, &foo::field1>, wjson::member<n_field2, foo, int, &foo::field2>, wjson::member<n_field3, foo, int, &foo::field3>, wjson::member<n_field5, foo, std::vector<int>, &foo::field5, ::wjson::array< std::vector< ::wjson::value<int> > > > > > foo_json;
入力JSONのフィールドの順方向および逆方向(最も失敗した)シーケンス。しかし、その後、彼はフィールド名が完全に正直ではないことに気づきました、最後の文字の例外と一致するため、オプションの測定も行いました。 JSON_NAME2(n_field1, "1field") JSON_NAME2(n_field2, "2field") JSON_NAME2(n_field3, "3field") JSON_NAME2(n_field5, "5field")
すべてのフィールドが最初の文字で区別される場合。JSONの要約: {"field1":12345,"field2":23456,"field3":34567,"field5":[45678,56789,67890,78901,89012]} {"5field":[45678,56789,67890,78901,89012],"1field":12345,"2field":23456,"3field":34567} {"field5":[45678,56789,67890,78901,89012],"field1":12345,"field2":23456,"field3":34567}
次の結果を得ました:- シリアル化時間:151321 ns(6608468 persec)、今では重要ではありません
- 「最適な」JSONの逆シリアル化:204113 ns(4899246毎秒)
- 最適な名前を持つ「最悪」のフィールド順序:221140 ns(4522022 persec)
- 「悪い」名前を持つフィールドの「最悪の」順序:237616 ns(4208470パーセク)
明確にするために、また記事の冒頭で取り上げたトピックsprintf / sscanfを閉じるために、このような構成の実行時間も測定しました。 sscanf( str, "{\"field1\":%d,\"field2\":%d,\"field3\":%d,\"field5\":[%d,%d,%d,%d,%d]}", &(f.field1), &(f.field2), &(f.field3), &(f.field5[0]), &(f.field5[1]), &(f.field5[2]),&(f.field5[3]), &(f.field5[4]) );
ここでは、本格的なデシリアライゼーションの話ができないことは明らかです-パターンとの矛盾は悲惨な結果につながる可能性があります。ただし、結果は2477942 ns(403560 persec)であり、これはすべてのチェックでwjsonよりも10倍悪く、「悪い」順序と「良くない」フィールド名で: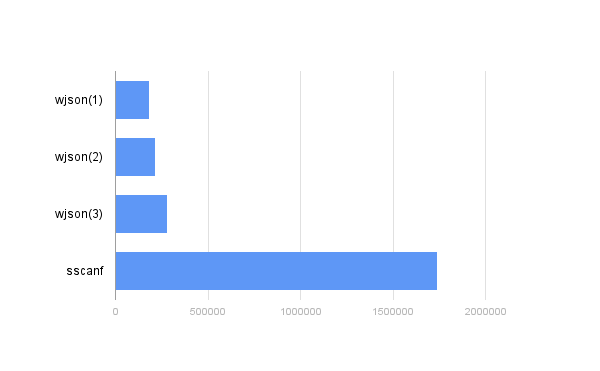 目を信じていなかった、確認したい人のためにこれらの数字(称賛に値する)、記事を読むことなく(これは歓迎しにくい)、これは最適化がオンになっている場合にのみ機能することをすぐに警告します。デバッグモードでは、数値をまったく逆に、さらに悪い値に変更します。常に何かを犠牲にしなければなりません。このようなエンティティのシリアル化の速度に関する質問は数年前からありましたが、JSONの冗長性の問題が時々浮上します。この問題を解決するために、インデックスにフィールドが厳密に関連付けられている配列に構造体をシリアル化することができます。
目を信じていなかった、確認したい人のためにこれらの数字(称賛に値する)、記事を読むことなく(これは歓迎しにくい)、これは最適化がオンになっている場合にのみ機能することをすぐに警告します。デバッグモードでは、数値をまったく逆に、さらに悪い値に変更します。常に何かを犠牲にしなければなりません。このようなエンティティのシリアル化の速度に関する質問は数年前からありましたが、JSONの冗長性の問題が時々浮上します。この問題を解決するために、インデックスにフィールドが厳密に関連付けられている配列に構造体をシリアル化することができます。 typedef wjson::object_array< foo, wjson::member_list< wjson::member_array<foo, int, &foo::field1>, wjson::member_array<foo, int, &foo::field2>, wjson::member_array<foo, int, &foo::field3>, wjson::member_array<foo, std::vector<int>, &foo::field5, ::wjson::array< std::vector< ::wjson::value<int> > > > > > foo_json;
その結果、同じ構造体が配列にシリアル化されます。 [12345,23456,34567,[45678,56789,67890,78901,89012]]
139856 ns(7150211 persec)で、131282 nsでデシリアライゼーションが発生します(7617190) はい、速度に違いはありますが、まずはよりコンパクトです。サーバーがグラフ作成用のデータを返すプロジェクトの1つでは、各ポイントは8つのフィールドで記述され、各グラフで約3000であり、グラフ自体は画面上で数十になることがあり、結果のJSONは数メガバイトになる可能性があります。元の構造を8つの要素の配列にシリアル化することにより、送信されるトラフィックの量を大幅に削減するだけでなく、読みやすくします。しかし、一般に、もちろん、すべてのAPIを配列に変換することはお勧めできません。
はい、速度に違いはありますが、まずはよりコンパクトです。サーバーがグラフ作成用のデータを返すプロジェクトの1つでは、各ポイントは8つのフィールドで記述され、各グラフで約3000であり、グラフ自体は画面上で数十になることがあり、結果のJSONは数メガバイトになる可能性があります。元の構造を8つの要素の配列にシリアル化することにより、送信されるトラフィックの量を大幅に削減するだけでなく、読みやすくします。しかし、一般に、もちろん、すべてのAPIを配列に変換することはお勧めできません。継承
例として次の構造を使用して継承を検討します。 struct foo { bool flag = false; int value = 0; std::string string; }; struct bar: foo { std::vector<int> data; };
継承を記述する方法は2つあります。 typedef ::wjson::array< std::vector< ::wjson::value<int> > > vint_json; typedef wjson::object< bar, wjson::member_list< wjson::member<n_flag, foo,bool, &foo::flag>, wjson::member<n_value, foo,int, &foo::value>, wjson::member<n_string, foo,std::string, &foo::string>, wjson::member<n_data, bar, std::vector<int>, &bar::data, vint_json> > > bar_json;
ここで、親(または親)と相続人のフィールドを任意の順序で配置できます。オプション2、より直感的: typedef wjson::object< foo, wjson::member_list< wjson::member<n_flag, foo,bool, &foo::flag>, wjson::member<n_value, foo,int, &foo::value>, wjson::member<n_string, foo,std::string, &foo::string> > > foo_json; typedef wjson::object< bar, wjson::member_list< wjson::base<foo_json>, wjson::member<n_data, bar, std::vector<int>, &bar::data, vint_json> > > bar_json;
基本クラスの個別のJSON記述を作成し、リスト内の任意の場所でfoo_json :: member_listのエイリアスであるwjson :: base <foo_json>構成を使用して実装します。すべての要素を持つ素晴らしい例。 #include <wjson/json.hpp> #include <wjson/strerror.hpp> #include <iostream> struct foo { bool flag = false; int value = 0; std::string string; }; struct bar: foo { std::shared_ptr<foo> pfoo; std::vector<foo> vfoo; }; struct foo_json { JSON_NAME(flag) JSON_NAME(value) JSON_NAME(string) typedef wjson::object< foo, wjson::member_list< wjson::member<n_flag, foo,bool, &foo::flag>, wjson::member<n_value, foo,int, &foo::value>, wjson::member<n_string, foo,std::string, &foo::string> > > type; typedef type::serializer serializer; typedef type::target target; typedef type::member_list member_list; }; struct bar_json { JSON_NAME(pfoo) JSON_NAME(vfoo) typedef wjson::array< std::vector< foo_json > > vfoo_json; typedef wjson::pointer< std::shared_ptr<foo>, foo_json > pfoo_json; typedef wjson::object< bar, wjson::member_list< wjson::base<foo_json>, wjson::member<n_vfoo, bar, std::vector<foo>, &bar::vfoo, vfoo_json>, wjson::member<n_pfoo, bar, std::shared_ptr<foo>, &bar::pfoo, pfoo_json> > > type; typedef type::serializer serializer; typedef type::target target; typedef type::member_list member_list; }; int main() { std::string json="{\"flag\":true,\"value\":0,\"string\":\" \",\"vfoo\":[],\"pfoo\":null}"; bar b; bar_json::serializer()( b, json.begin(), json.end(), nullptr ); b.flag = true; b.vfoo.push_back( static_cast<const foo&>(b)); b.pfoo = std::make_shared<foo>(static_cast<const foo&>(b)); std::cout << json << std::endl; bar_json::serializer()(b, std::ostream_iterator<char>(std::cout) ); std::cout << std::endl; }
結果:
{"flag":true,"value":0,"string":" ","vfoo":[],"pfoo":null} {"flag":true,"value":0,"string":" ","vfoo":[{"flag":true,"value":0,"string":" "}],"pfoo":{"flag":true,"value":0,"string":" "}}
JSONオブジェクトの説明は少し異なりますが、最初はポインターについてです。任意のポインターをシリアル化できます。ゼロの場合、nullとしてシリアル化され、そうでない場合は値によってシリアル化されます。また、逆シリアル化はstd :: shared_ptr <>に対してのみ実装されます。JSONがnullの場合、nullptrになります。それ以外の場合、オブジェクトが作成され、逆シリアル化が発生します。wjson :: pointerとして記述しなかった要素については、nullが入力に到着すると、デフォルト値で作成されます。これは、配列と単純型にも適用されます。多数のパラメーターを持つスクリーンテンプレートクラスを選択する理由JSON- , , . , , . , :
template<typename J> struct deserealizer { typedef typename J::deserializer type; };
:
typedef deserealizer<bar_json>::type deser;
なぜなら deserializer , :
error: no type named 'deserializer' in 'struct bar_json'
foo_json bar_json typedef, :
error: no type named 'deserializer' in 'struct wjson::object<bar, fas::type_list<wjson::member<n_flag, foo, bool, &foo::flag>, fas::type_list<wjson::member<n_value, foo, int, &foo::value>, fas::type_list<wjson::member<n_string, foo, std::basic_string<char>, &foo::string>, fas::type_list<wjson::member<n_vfoo, bar, std::vector<foo>, &bar::vfoo, wjson::array<std::vector<wjson::object<foo, fas::type_list<wjson::member<n_flag, foo, bool, &foo::flag>, fas::type_list<wjson::member<n_value, foo, int, &foo::value>, fas::type_list<wjson::member<n_string, foo, std::basic_string<char>, &foo::string>, fas::empty_list> > > > > > >, fas::type_list<wjson::member<n_pfoo, bar, std::shared_ptr<foo>, &bar::pfoo, wjson::pointer<std::shared_ptr<foo>, wjson::object<foo, fas::type_list<wjson::member<n_flag, foo, bool, &foo::flag>, fas::type_list<wjson::member<n_value, foo, int, &foo::value>, fas::type_list<wjson::member<n_string, foo, std::basic_string<char>, &foo::string>, fas::empty_list> > > > > >, fas::empty_list> > > > > >'
, . , , ., , typeid(T).name(). , , , , . , , :
template<typename J> struct deserealizer { struct type: J::deserializer {}; };
, . . , , , ( ).
もちろん、同じfoo_jsonボイラープレートを作成し、テンプレート構造をシリアル化するために使用できる値フィールドのタイプなどのパラメーターを渡すことは誰も気にしません。辞書
連想配列(キー値)をシリアル化するには、std :: map <>などの辞書が必要です。ほとんどのJSONライブラリはこのスキームに従って動作します。オブジェクトはツリーにデシリアライズされ、それを調べて、必要なフィールドを検索するなどします。そして、シリアル化のために、動的にそれを埋める必要があります。パフォーマンスの点では、これは最も効率的な方法ではありません。したがって、そのstd :: map <>をデータ構造で使用する前に、それなしで何らかの方法で可能かどうかを考えてください。もちろん、設定にJSONを使用する場合、これは適用されません。 template<typename T, int R = -1> struct dict { typedef implementation_defined target; typedef implementation_defined serializer; };
ここで、概念は配列の概念と同じです-Tはキーと値のJSON記述をパラメーターとして持つ連想stlコンテナーです。 例:
typedef wjson::dict< std::map< wjson::value<std::string>, wjson::value<int> > > dict_json;
std :: map <std :: string、int>のシリアル化に使用できます。設計は非常に複雑ですが、文字列がキーとして最も頻繁に使用されるという事実を考慮すると、std :: map <std :: string、JSON>にはより簡単なオプションがあります。 typedef wjson::dict_map< wjson::value<int> > dict_json;
もちろん、この記事で上記で説明したJSONエンティティは、値として使用できます。パラメーターRは、タイプstd :: vector <std :: pair <>>またはstd :: deque <std :: pair <>>のペアの順次コンテナーの予約のサイズを決定します。フィールド構造は、キーと値のペアを記述するために使用されます。 template<typename K, typename V> struct field;
ここで、KとVはそれぞれキーと値のJSON記述です。 例:
typedef wjson::dict< std::vector< wjson::field< wjson::value<std::string>, wjson::value<int> > >, 128 > dict_json;
ペアstd :: vector <std :: pair <std :: string、int >>のベクトルをシリアル化する。この設計は、高いデシリアライゼーションレートが必要な場合に使用できます。ペアのベクトルは、std :: mapよりもはるかに高速で埋められます(もちろん、必要な予約が行われている場合)。この設計はさらに複雑ですが、より頻繁に使用されるため、簡単なオプションがあります。 typedef wjson::dict_vector< ::wjson::value<int> > dict_json; typedef wjson::dict_deque< ::wjson::value<int> > dict_json;
例:
int main() { typedef std::vector< std::pair<std::string, int> > dict; typedef wjson::dict_vector< wjson::value<int> > dict_json; dict d; std::string json = "{\"\":1,\"\":2,\"\":3}"; std::cout << json << std::endl; dict_json::serializer()( d, json.begin(), json.end(), 0 ); d.push_back( std::make_pair("",4)); json.clear(); dict_json::serializer()( d, std::back_inserter(json) ); std::cout << json << std::endl; }
結果:
{"":1,"":2,"":3} {"":1,"":2,"":3,"":4}
辞書は、構成に使用すると便利です。最も単純な場合、これは単純なキーと値の配列であり、キーには構成可能なコンポーネントの名前が含まれます。ただし、コンポーネントの構成を別の構造で取り出してJSON記述を作成するのが面倒ではない場合は、余分なランタイムコードを削除し、その結果、初期化エラーの説明を削除します。さらに、(開発段階で)自分とユーザーが喜ぶ最新のフィールドセットを使用して構成を生成することができます。これにより、ユーザーは廃止されたというプロパティを持つドキュメントの関連性を検証できます。列挙とフラグ
一般的にデータを表示するためのテキスト形式が作成されたのと同じ理由で、テキスト表現で列挙をシリアル化することは理にかなっています-これは読みやすいです。長い名前を乱用しない場合、少なくとも、数値としてのシリアル化よりも遅くなく、サイズもそれほど高くないことがわかります。これらの行まで読んだ場合、一般的な概念全体が理解できる可能性が高いので、たとえばすぐに:列挙型シリアル化の例 #include <wjson/json.hpp> #include <wjson/strerror.hpp> #include <iostream> struct counter { typedef enum { one = 1, four = 4, five = 5, two = 2, three = 3, six = 6 } type; }; struct counter_json { JSON_NAME(one) JSON_NAME(two) JSON_NAME(three) JSON_NAME(four) JSON_NAME(five) JSON_NAME2(n_six, " !") typedef wjson::enumerator< counter::type, wjson::member_list< wjson::enum_value< n_one, counter::type, counter::one>, wjson::enum_value< n_two, counter::type, counter::two>, wjson::enum_value< n_three,counter::type, counter::three>, wjson::enum_value< n_four, counter::type, counter::four>, wjson::enum_value< n_five, counter::type, counter::five>, wjson::enum_value< n_six, counter::type, counter::six> > > type; typedef type::serializer serializer; typedef type::target target; typedef type::member_list member_list; }; int main() { typedef wjson::array< std::vector< counter_json > > array_counter_json; std::vector< counter::type > cl; std::string json = "[\"one\",\"two\",\"three\"]"; std::cout << json << std::endl; array_counter_json::serializer()( cl, json.begin(), json.end(), 0 ); cl.push_back(counter::four); cl.push_back(counter::five); cl.push_back(counter::six); array_counter_json::serializer()(cl, std::ostream_iterator<char>(std::cout) ); std::cout << std::endl; }
例に示すように、列挙は1対1でシリアル化する必要はありませんが、任意の文字列に含めることができます。 結果:
["one","two","three"] ["one","two","three","four","five"," !"]
実際、ここでの列挙は便宜上のものであり、任意の整数型を使用できます。次のJSONを検討してください。 {"code":1,"message":"Invalid JSON."}
これは、ある種のJSON-RPCスタイルのエラーメッセージです。明らかに、メッセージメッセージはコードに直接関連しています。したがって、テキストフィールドを含む構造を作成して入力する必要はありません。それで十分です。列挙型ではなく2つ #include <wjson/json.hpp> #include <wjson/strerror.hpp> #include <iostream> enum class error_code { ValidJSON = 0, InvalidJSON = 1, ParseError = 2 }; struct error { int code = 0; }; struct code_json { JSON_NAME2(ValidJSON, "Valid JSON.") JSON_NAME2(InvalidJSON, "Invalid JSON.") JSON_NAME2(ParseError, "Parse Error.") typedef wjson::enumerator< int, wjson::member_list< wjson::enum_value< ValidJSON, int, static_cast<int>(error_code::ValidJSON)>, wjson::enum_value< InvalidJSON, int, static_cast<int>(error_code::InvalidJSON)>, wjson::enum_value< ParseError, int, static_cast<int>(error_code::ParseError)> > > type; typedef type::serializer serializer; typedef type::target target; typedef type::member_list member_list; }; struct error_json { JSON_NAME(code) JSON_NAME(message) typedef wjson::object< error, wjson::member_list< wjson::member< n_code, error, int, &error::code>, wjson::member< n_message, error, int, &error::code, code_json> > > type; typedef type::serializer serializer; typedef type::target target; typedef type::member_list member_list; }; int main() { error e; e.code = static_cast<int>(error_code::InvalidJSON); error_json::serializer()(e, std::ostream_iterator<char>(std::cout) ); std::cout << std::endl; }
結果:
{"code":1,"message":"Invalid JSON."}
シリアル化はおかしく見えますが、逆シリアル化はどうですか?「コード」は2回デシリアライズされます。1回は「コード」フィールドから、2回目は「メッセージ」フィールドからです。error_jsonの個別のバージョンは、「メッセージ」フィールドなしで逆シリアル化専用に作成できますが、シリアル化中に解析されるため、パフォーマンスに大きな影響はありません。また、この機能を使用して、コードの厳密な整合性を再確認できます。たとえば、メッセージ内のポイントを疑問符に置き換えた場合: e = error(); std::string json = "{\"code\":1,\"message\":\"Invalid JSON?\"}"; wjson::json_error ec; error_json::serializer()(e, json.begin(), json.end(), &ec );
次に、エラーが表示されます。 Invalid Enum: {"code":1,"message":">>>Invalid JSON?"}
列挙は、あらゆる種類のフラグの組み合わせによく使用されますが、シリアル化することもできます。しかし、どのような形で?2つのメソッドが提供されます:配列として、または指定された区切り文字列として。区切り文字は、最後のフラグパラメーターによって指定されます。コンマ以外の文字は文字列にシリアル化され、コンマは配列にシリアル化されます。以下のユーモラスな例では、両方のオプションが使用されています:祖母は灰色のヤギと住んでいた #include <wjson/json.hpp> #include <wjson/strerror.hpp> #include <iostream> template<char S> struct flags_json { JSON_NAME2(w1, "") JSON_NAME2(w2, "") JSON_NAME2(w4, "") JSON_NAME2(w8, "") JSON_NAME2(w16, "") JSON_NAME2(w32, "") typedef ::wjson::flags< int, wjson::member_list< wjson::enum_value< w1, int, 1>, wjson::enum_value< w2, int, 2>, wjson::enum_value< w4, int, 4>, wjson::enum_value< w8, int, 8>, wjson::enum_value< w16, int, 16>, wjson::enum_value< w32, int, 32> >, S > type; typedef typename type::serializer serializer; typedef typename type::target target; typedef typename type::member_list member_list; }; int main() { std::string json = "\" \""; int val = 0; flags_json<' '>::serializer()(val, json.begin(), json.end(), 0 ); std::cout << json << " = " << val << std::endl; std::cout << 63 << " = "; flags_json<' '>::serializer()(63, std::ostream_iterator<char>(std::cout) ); std::cout << std::endl; std::cout << 48 << " = "; flags_json<','>::serializer()(48, std::ostream_iterator<char>(std::cout) ); std::cout << std::endl; std::cout << 49 << " = "; flags_json<'|'>::serializer()(49, std::ostream_iterator<char>(std::cout) ); std::cout << std::endl; }
ここでの考え方は簡単です。私たちは、子供の歌の行の各単語を、対応する意味を持つフラグとして使用します。フラグを組み合わせると、さまざまなオプションが得られます。また、スペースをセパレータとして使用する場合、これがフラグのセットであることはまったく明らかではありません。最初に、「灰色のヤギがありました」という行をデシリアライズします。これは、1 | 2 | 16 | 32 = 51の組み合わせに対応し、スペースとしてセパレーターを使用します。以下は、さまざまな区切り文字を使用したシリアル化の例です。明らかに、63までのすべての数字を使用できます-これはフレーズ全体です。結果:
" " = 51 63 = " " 48 = ["",""] 49 = "||"
おわりに
この創造の発展の歴史についての長くて退屈な無罪の物語を始めないように、誘惑に負けないことは非常に難しいです。したがって、簡単に。それが構築されているfaslibの概念のいくつかを解決するために、2008年にひざまずいて書かれました。 2009年、wjson(当時はコピーされたコードのコレクションでした)が実験プロジェクトで使用されました。それから、インターフェースが柔軟ではなく、一般的にひどいことが明らかになりました。 2011年には、グローバルで包括的かつ正しいことを行う試みがありました。そして、それはほとんど起こりましたが、放棄されました。同じ年に、私たちはすべてのプロジェクトをJSONに変換し始めました。現在の機能はすべてのニーズに対応しており、インターフェイスは初心者でも簡単で理解しやすいことがわかりました。 2013年以降、非常に負荷の高いプロジェクトを含むすべてのプロジェクトがwjsonと連携しています。例えばcometデーモンは最大100万の同時アクティブ接続をサポートでき、統計収集システムは1ホストで1.5 GBを超えるJSON-RPC通知をグラインドし、1秒あたり最大450万のさまざまなメトリックの値を登録します。私たちはJSONを構成、あらゆる種類のダンプ、そしてもちろん同じ原則で動作するJSON-RPCエンジンと一緒に使用します。これについてはすぐに次の記事で説明します。wjsonとfaslibは、wjsonが依存しており、ヘッダーのみのライブラリです。サンプルとテストをコンパイルするには: git clone https://github.com/migashko/faslib.git git clone https://github.com/mambaru/wjson.git
githubのwjson:github.com/mambaru/wjson