歴史的に、Yandexの多くの部分では、特定のプロジェクトの詳細を考慮して、大量のデータを保存および処理するシステムが開発されてきました。 この開発では、効率、拡張性、および信頼性が常に優先事項でした。したがって、原則として、このようなシステムを使用するための便利なインターフェースのための時間はありませんでした。 1年半前、大規模なインフラストラクチャコンポーネントの開発は、製品チームから別の方向に選ばれました。 目標は次のとおりでした:より速く動き始め、同様のシステム間の重複を減らし、新しい内部ユーザーのしきい値を下げます。

すぐに、ここで共通の高レベルクエリ言語が役立ち、既存のシステムへの均一なアクセスを提供し、これらのシステムで採用されている低レベルプリミティブの典型的な抽象化を再実装する必要もなくなることに気付きました。 したがって、データストレージおよび処理システム用の汎用宣言型クエリ言語であるYandex Query Language(YQL)の開発が始まりました。 (これはYQLと呼ばれる世界で最初のものではないことがわかっているとすぐに言いますが、これが問題を妨げないことを決定し、名前を残しました。)
Yandexインフラストラクチャに特化した
会議を期待して、Habrahabrの読者にYQLについて伝えることにしました。
建築
もちろん、HadoopやSparkなど、世界で人気のあるオープンソースエコシステムの方向を見ることができます。 しかし、彼らは真剣に考慮されませんでした。 実際には、Yandexですでに普及しているデータウェアハウスとコンピューターシステムのサポートが必要でした。 このため、YQLはあらゆるレベルで拡張可能に設計および実装されました。 以下のすべてのレベルを順番に見ていきます。
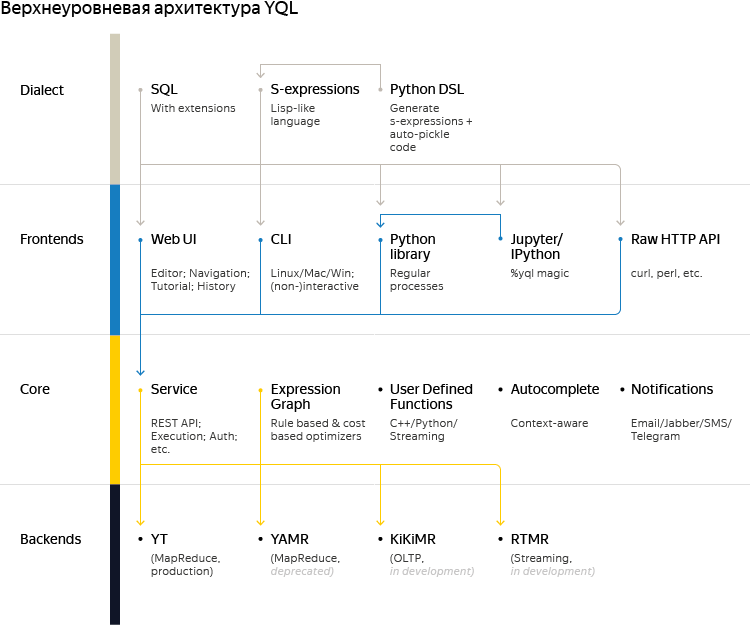
図では、ユーザークエリは上から下に移動しますが、ストーリーがよりつながりやすくなるように、影響を受ける要素を下から上に逆の順序で説明します。 開始するには、現在サポートされているバックエンドまたは私たちが呼んでいるデータプロバイダーに関するいくつかの言葉:
- 5年以上にわたり、YandexはMapReduceパラダイムの2つの実装、YaMRとYTを開発してきました。これらについては、 最近の投稿で詳しく読むことができます。 技術的には、それらはお互いにもHadoopにもほとんど共通点はありません。 このクラスのシステムの開発は非常に高価な喜びであるため、1年前に「MapReduce-tender」を開催することが決定されました。 YTが勝ち、現在、YaMRユーザーは切り替えを終えています。 YQLの開発は入札の開始とほぼ同時に始まりました。そのため、主要な要件の1つは、YTとYaMRの両方のサポートであり、移行期間のユーザーの生活を楽にするために実装する必要がありました。
- RTMR(Real Time MapReduce)については、かつて別の投稿もありました 。 彼のサポートは開発の初期段階にあります。 まず、この統合プロジェクトにより、新しいユーザーは特別なトレーニングなしでRTMRを実装できます。 次に、新しいデータのストリームと、長期間にわたって収集され、分散YTファイルシステムにあるアーカイブの両方を均一に分析できるようになります。
- Yandexでは、MapReduceパラダイムに基づいたものよりも多くのOLTPパターンを持つストレージシステムがあります。 KiKiMRは、YQLと統合するためのパイロットプロジェクトとしてそれらの中から選ばれました。 多くの点で、YQLの人気が高まると同時にフレンドリーなKiKiMRインターフェイスの必要性が形成されたため、この選択が行われました。 もう1つの理由は、このプロジェクトのためのKiKiMRチームのリソースでした。 KiKiMRの詳細な話はここでは適切ではありませんが、要するに、それはデータセンター間での分散を含む分散フォールトトレラントの厳密で一貫性のあるデータストレージです。 複数のマシンと数千のノードで構成されるインストールで使用できます。 KiKiMRストレージの特徴的な機能は、個々のオブジェクト(単一行トランザクション)と分散ストレージオブジェクトのグループ(クロス行/クロステーブルトランザクション)の両方で、シリアル化可能な分離レベルで操作を効率的かつトランザクション的に実行する組み込み機能です。
- このリストには、すでに実装されているものまたは進行中のもののみが含まれます。 YQLでサポートされるシステムの範囲をさらに拡大する計画です。 たとえば、 ClickHouseのサポートは非常に論理的なイベントの開発になりますが、現在はリソースの制限と緊急の必要性の不足により、やや遅れています。
コア
技術的には、YQLは比較的分離されたコンポーネントとライブラリで構成されていますが、主にサービスとして内部ユーザーに提供されます。 これにより、彼らは「シングルウィンドウサービス」としての観点から見て、各バックエンドのアクセスの発行やファイアウォールの設定などの組織の問題に対する人件費を最小限に抑えることができます。 さらに、Yandexの従来のMapReduceの両方の実装では、トランザクションの完了を同期的に待機するクライアントプロセスが必要であり、YQLサービスがそれを処理し、ユーザーが「後で結果を求めて実行」モードで作業できるようにします。 ただし、サービスのモデルをライブラリ形式の配布と比較すると、欠点もあります。 たとえば、互換性のない変更やリリースにはさらに注意を払う必要があります。そうでない場合は、最も不適切な瞬間にユーザープロセスが中断される可能性があります。
YQLサービスの主なエントリポイントはHTTP REST APIです。これは
Nettyの Javaアプリケーションとして実装され、計算のための着信要求の起動を処理するだけでなく、幅広い補助的な役割も持ちます。
- いくつかの認証オプション。
- バックエンドを含む使用可能なクラスターのリストと、テーブルおよびスキームのリストを表示し、それらをナビゲートします。
- ユーザーが保存したリクエストのリポジトリ、およびすべての起動の履歴(歴史的にはMongoDBに存在しますが、これは将来変更される可能性があります)。
- 完了したリクエストの通知:
- REST APIの横にあるWebSocketエンドポイントは、どのユーザーインターフェイス(後でそれらについて説明します)を使用してポップアップメッセージをリアルタイムで表示できます。
- Jabberにレター、SMS、メッセージを送信するための内部サービスとの統合。
- Telegramのボット経由の通知。
Javaを使用すると、必要なすべてのシステムで既製の非同期クライアントを使用できるため、このすべてのビジネスロジックを迅速に実装することができました。 あまりにも厳密な遅延要件はまだないので、ガベージコレクションにはほとんど問題がなく、
G1に切り替えた後、それらはほとんどなくなりました。 上記に加えて、ノード間の同期のために、
ZooKeeperが使用されます。これには、通知を送信するときのパブリッシャー-サブスクライバーパターンも含まれます。
カスタム計算クエリの実行自体は、yqlworkerと呼ばれる別個のC ++プロセスによって調整されます。 これらは、REST APIと同じマシン上でもリモートでも実行できます。 実際には、Yandexで開発され広く使用されているMessageBusプロトコルを使用して、ネットワーク上で通信が行われています。 yqlworkerのコピーは、forkシステムコール(execなし)を使用して、リクエストごとに作成されます。 このようなスキームにより、
コピーオンライトメカニズムのおかげで、初期化に時間を無駄にせずに、異なるユーザーからのリクエストを十分に分離することができます。
高度なアーキテクチャの図からわかるように、Yandexクエリ言語には2つの表現があります。
- 基本的な構文はSQLに基づいており、ユーザーが作成するためのものです。
- s-expressions構文は、コード生成にとってより便利です。
選択された構文に関係なく、クエリから、関数型プログラミングで一般的なプリミティブを使用して必要なデータ処理を論理的に記述する式グラフが作成されます。 このようなプリミティブには、λ関数、表示(MapおよびFlatMap)、フィルタリング(Filter)、畳み込み(Fold)、ソート(Sort)、アプリケーション(Apply)などが含まれます。 SQL構文の場合、
ANTLR v3に基づくレクサーとパーサーが抽象構文ツリーを構築し、それを使用して計算グラフを構築します。 s-expression構文の場合、文法は非常に単純であり、プログラムはいずれにせよこれらの抽象化で動作するため、パーサーはほとんど自明です。
さらに、必要な結果を得るために、要求はいくつかの段階を経て、必要に応じて、すでに完了した状態に戻ります。
- 入力します。 YQLは基本的に強く型付けされた言語です。 これを支持する多くの議論がありました。SQLのルートから始まり、スキーマ化が暗示されており、たとえば、ネイティブコードをオンザフライで生成することにより、より広い加速範囲で終わりました。 単純なデータ型に加えて、いくつかのタイプのコンテナー(オプション、リスト、辞書、タプル、および構造体)および特殊タイプ(不透明ポインター(リソース)など)がサポートされています。
- 最適化 。 この段階では、実行時間を短縮するために設計された同等の変換だけが発生するわけではありません。 それらに加えて、アクションプランは、バックエンドが実行できる形式になります。 特に、バックエンドがネイティブに実行できる論理操作は物理操作に置き換えられます。 したがって、YQLにはオプティマイザー用の独自のフレームワークがあり、条件付きで3つのカテゴリーに分けることができます。
- 論理的な最適化の一般的なルール。
- 特定のバックエンドに固有の一般的なルール。
- 実行時に特定の実行戦略を選択する最適化(後でそれらに戻ります)。
- フルフィルメント 。 最適化後にエラーが残っていない場合、グラフはバックエンドAPIを使用して実行できる形式になります。 ほとんどの場合、yqlworkerはまさにそれを行います。 計算グラフに残っている論理演算は、バックエンドの計算能力で、可能であれば高度に専門化されたインタープリターを使用して実行されます。
リクエストのライフサイクルのどの段階でも、s-expressions構文にシリアル化することができます。これは、何が起こっているかを診断して理解するのに非常に便利です。
インターフェース
はじめに述べたように、YQLの重要な要件の1つは使いやすさでした。 したがって、パブリックインターフェイスには特別な注意が払われており、非常に積極的に開発されています。
コンソールクライアント
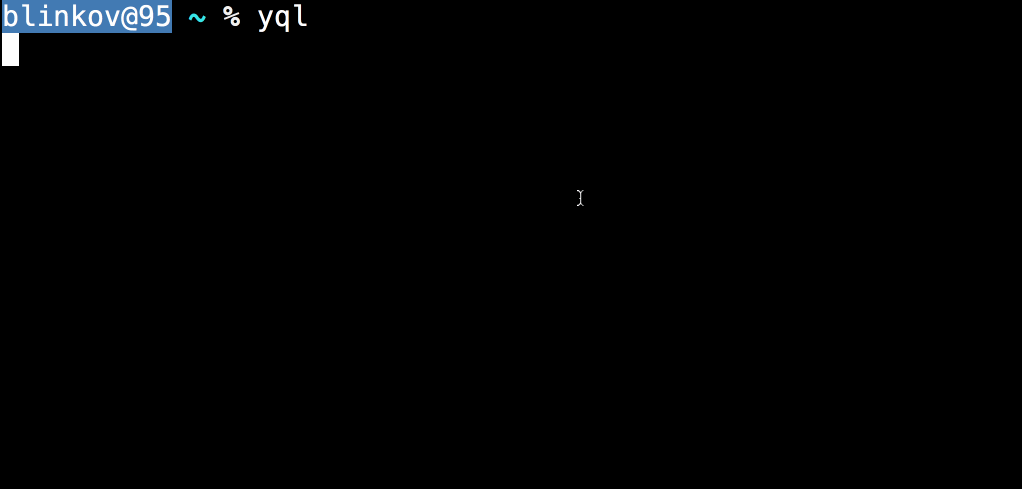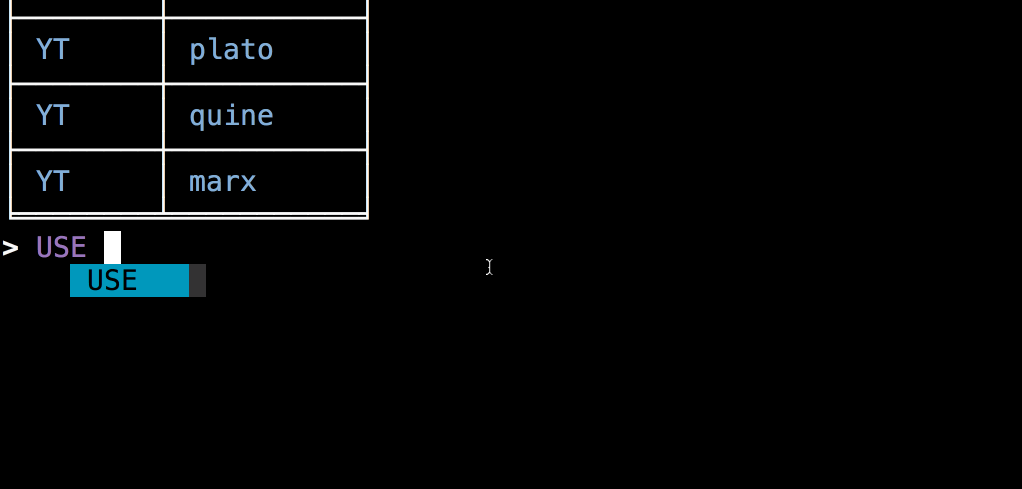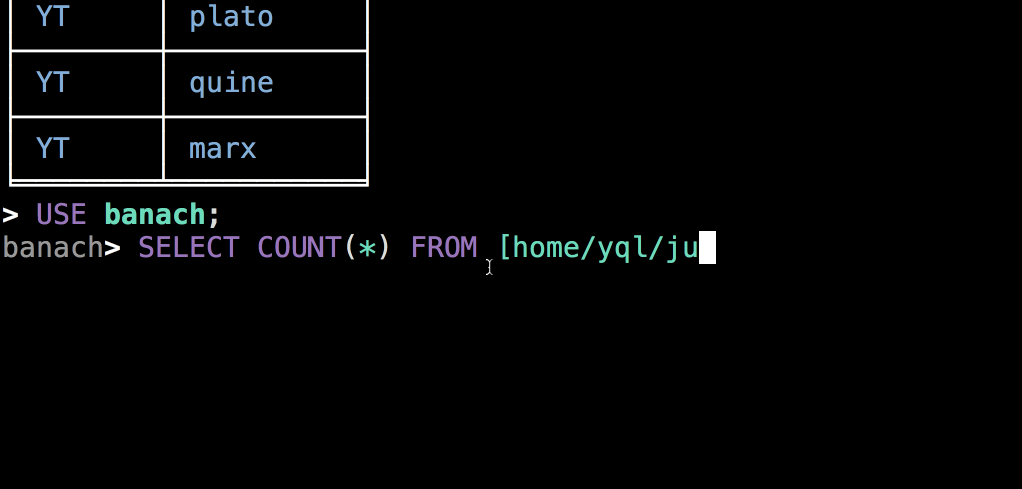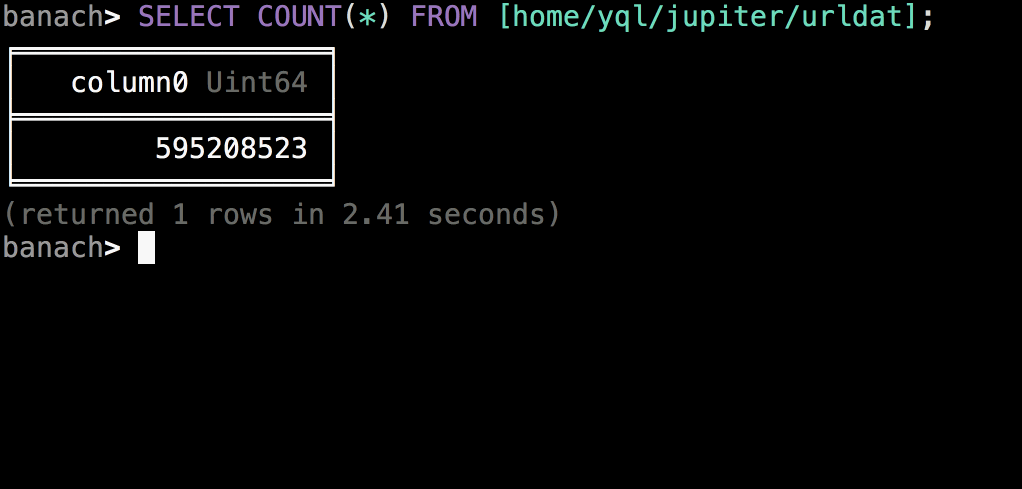
この図は、自動補完、構文の強調表示、色のテーマ、通知、その他の装飾を備えたインタラクティブモードを示しています。 ただし、コンソールクライアントは、ファイルまたは標準ストリームからI / Oモードで起動することもできます。これにより、コンソールクライアントを任意のスクリプトや通常のプロセスに統合できます。 操作の同期および非同期の両方の起動、クエリプランの表示、ローカルファイルの添付、クラスターおよびその他の基本機能のナビゲートがあります。
このような豊富な機能は、2つの理由で登場しました。 一方で、主にコンソールで作業することを好むYandexの人々の顕著な層があります。 一方、これは、フル機能のWebインターフェイスの開発に時間をかけるために行われました。これについては後で説明します。
興味深い技術的ニュアンス:コンソールクライアントはPythonで実装されますが、Linux、OS X、およびWindows用にコンパイルされる組み込みインタープリターを使用して、依存関係のない静的にリンクされたネイティブアプリケーションとして配布されます。 さらに、最新のブラウザのような自動更新も可能です。 コードを構築してリリースを準備するためのYandexの内部インフラストラクチャのおかげで、これらはすべて非常に簡単に整理できました。
Pythonライブラリ
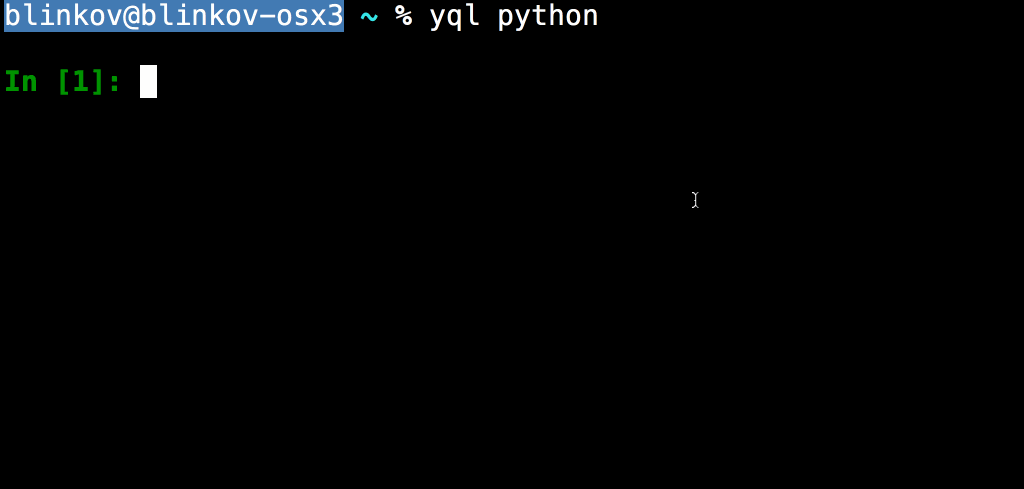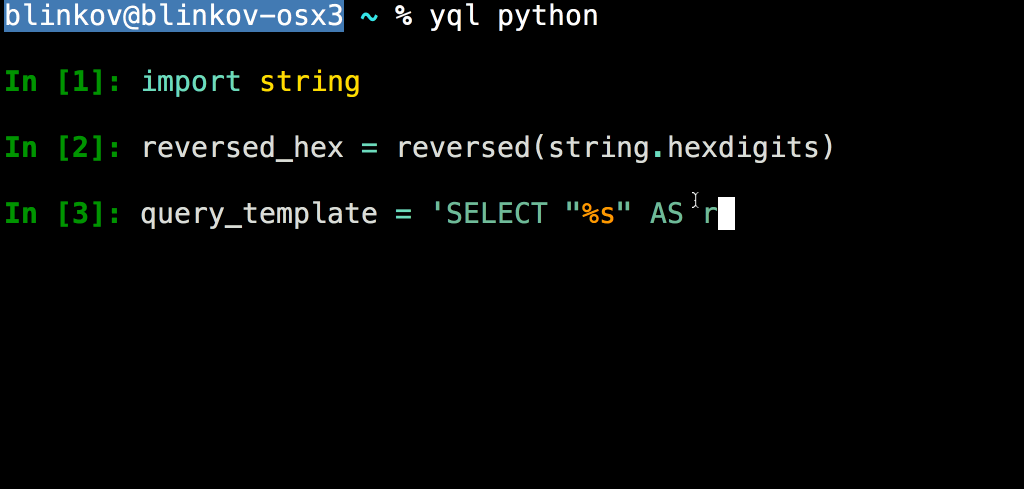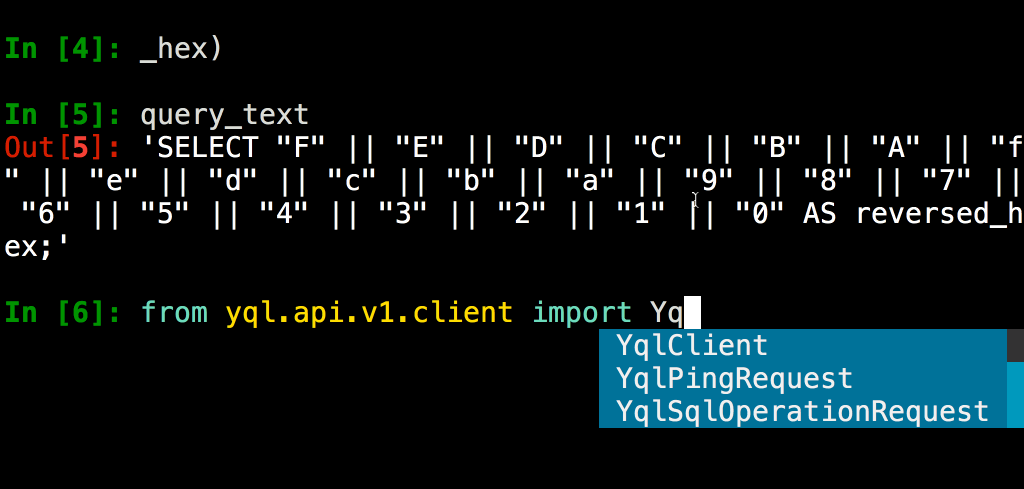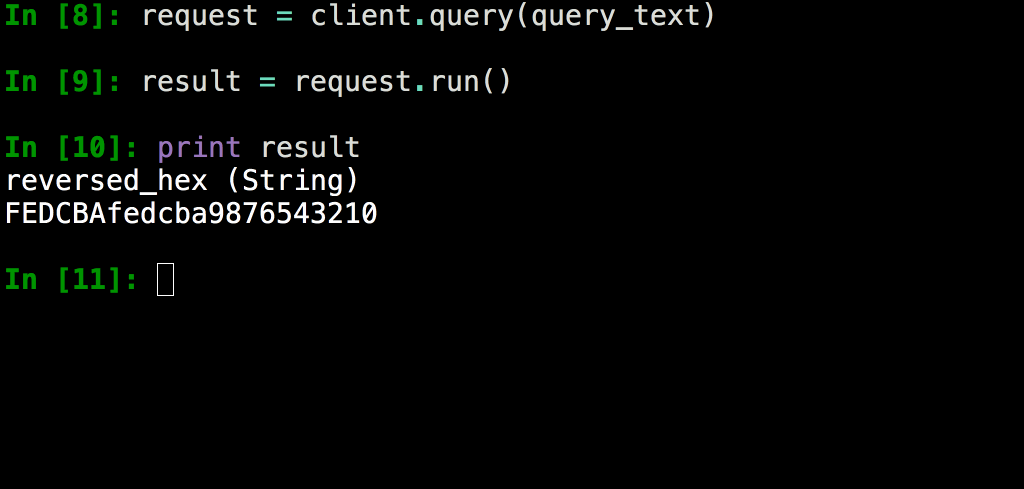
PythonはYandexでC ++に次いで2番目に広く使用されているプログラミング言語です。その
ため、YQLクライアントライブラリが実装されています。 実際、最初はコンソールクライアントの一部として開発された後、独立した製品として分離されたため、同じコードを再発明することなく他のPython環境で使用できるようになりました。
たとえば、多くのアナリストは
Jupyter環境での作業を好むため、いわゆる%yqlマジックがこのクライアントライブラリに基づいて作成されています。
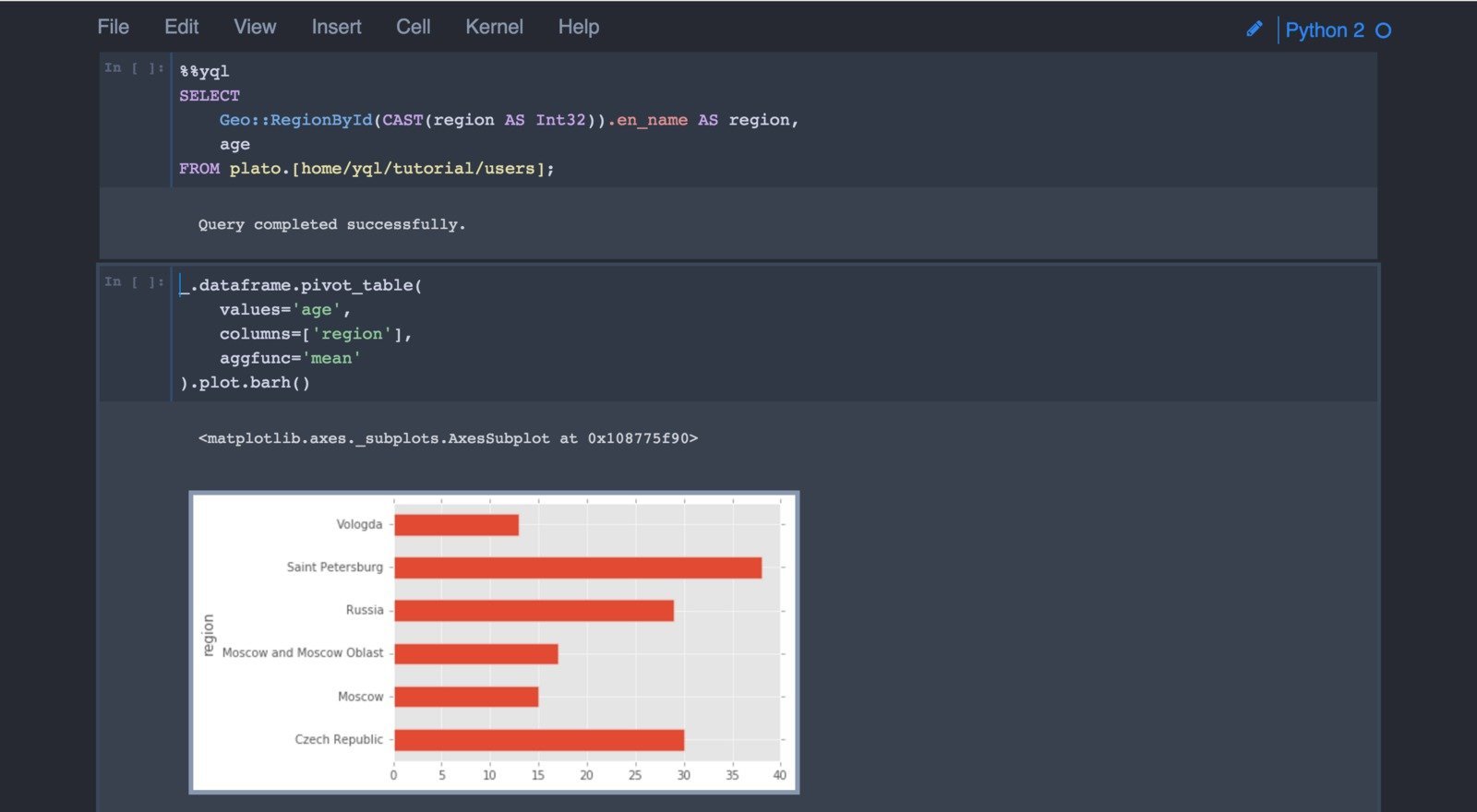
コンソールクライアントとともに、事前に構成されたJupyterまたは
IPythonを実行する2つの特別なルーチンが提供され、クライアントライブラリが既に利用可能です。 それらは上に示されています。
Webインターフェース
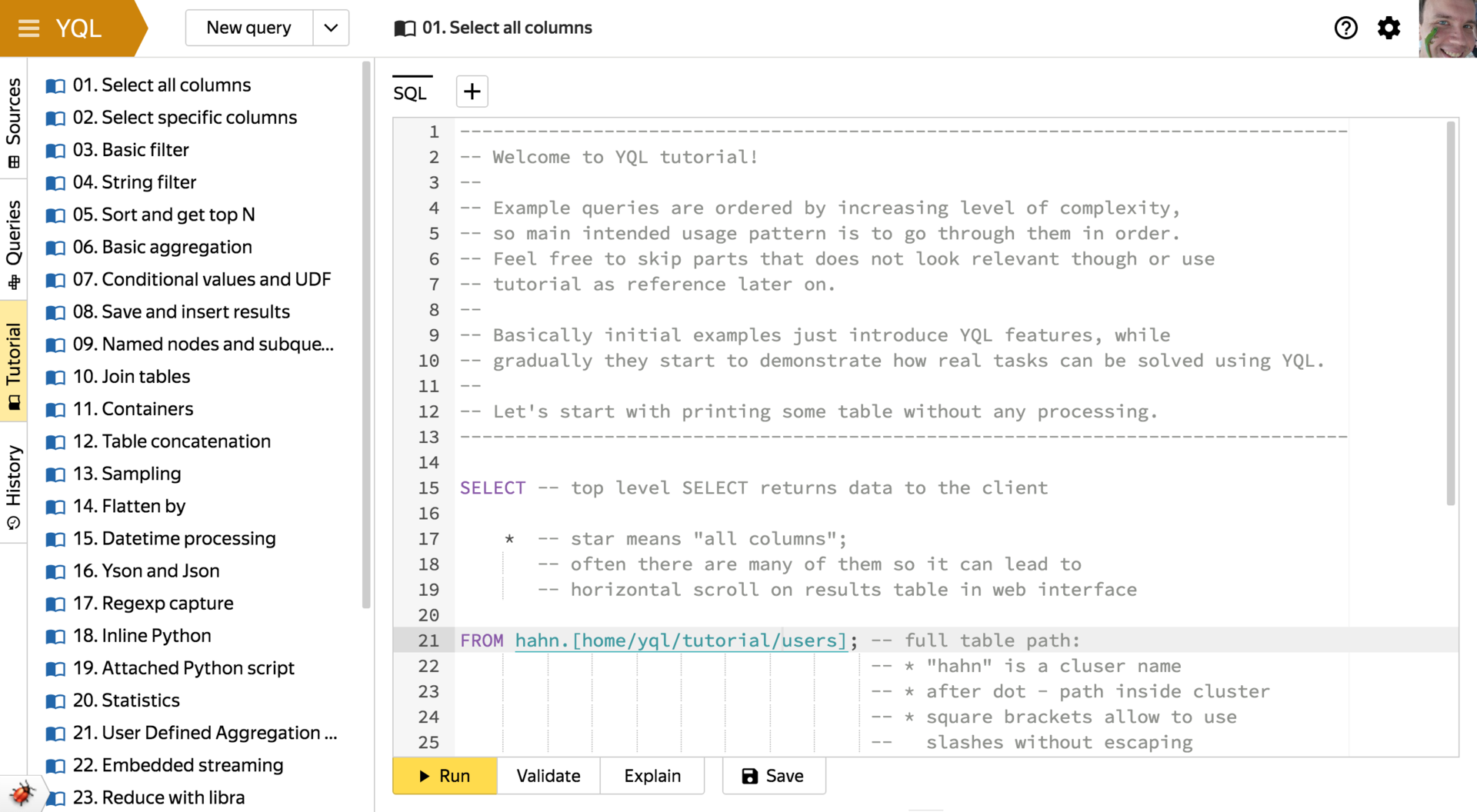
YQL言語、クエリ開発、および分析を学習するための主要なツールは、初心者向けに残しました。 Webインターフェースでは、コンソールの技術的な制限がないため、すべてのYQL機能はより視覚的な形式で利用でき、常に手元にあります。 インターフェース機能の一部は、他の画面の例に示されています。
- オートコンプリートとビューテーブルスキーマ
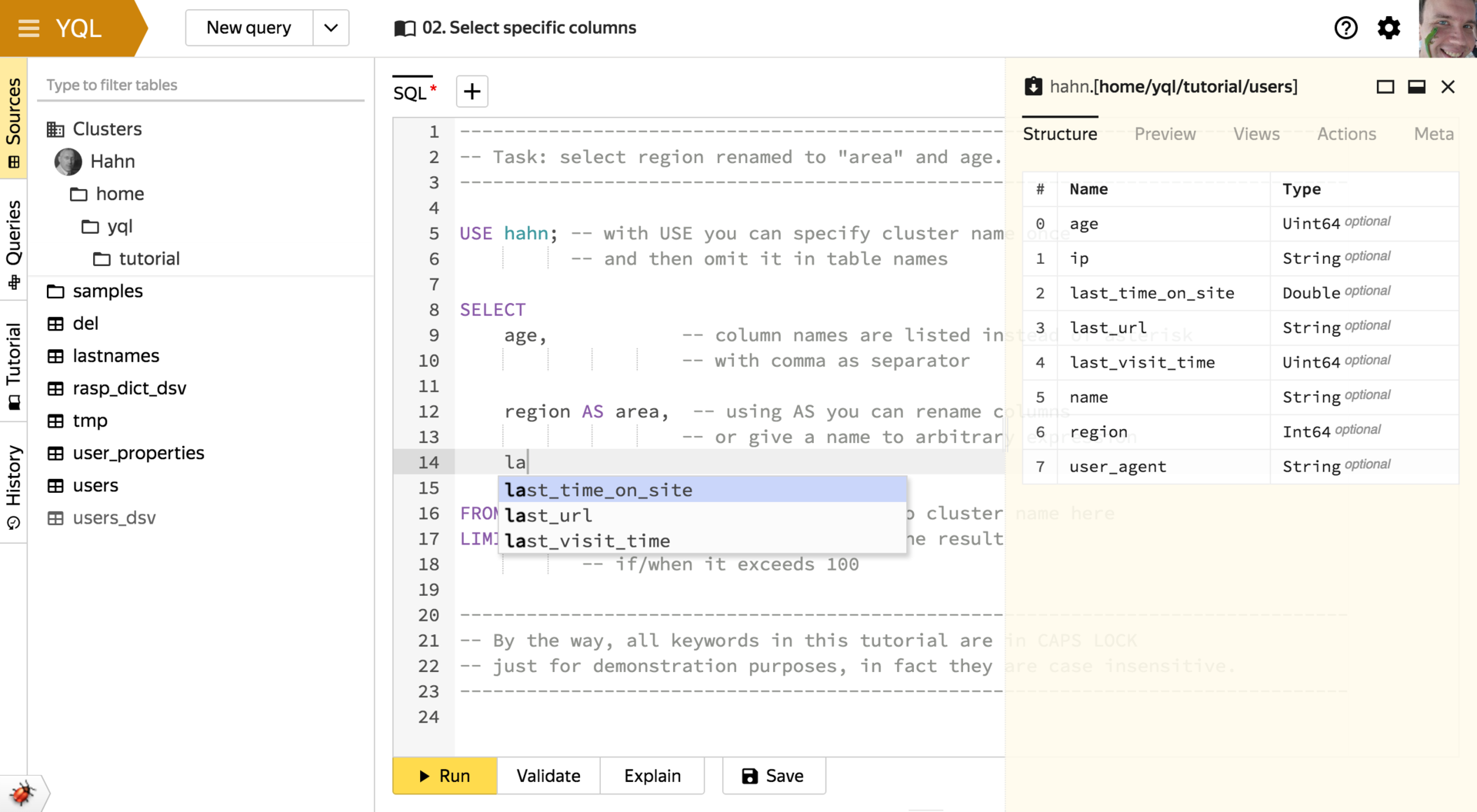
コンソールクライアントとWebインターフェイスからの要求の自動完了のロジックは一般的です。 彼女は、入力が発生するコンテキストを正確に考慮する方法を知っています。 これにより、すべての行ではなく、関連するキーワードまたはテーブル、列、関数の名前のみを入力することができます。
- 保存されたクエリを操作する
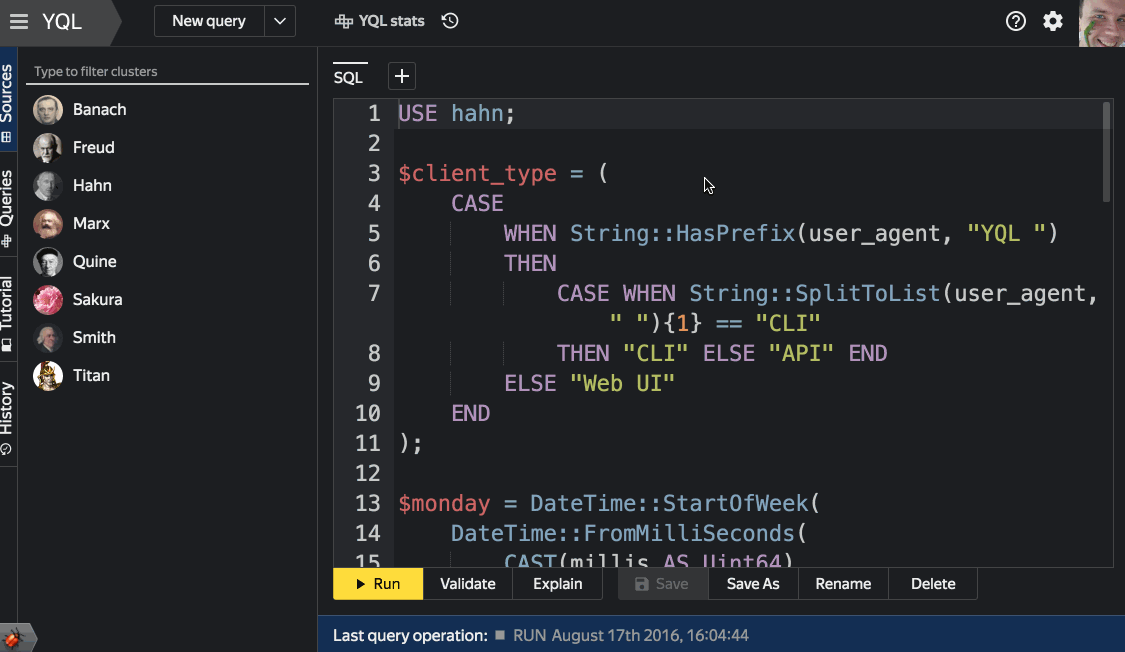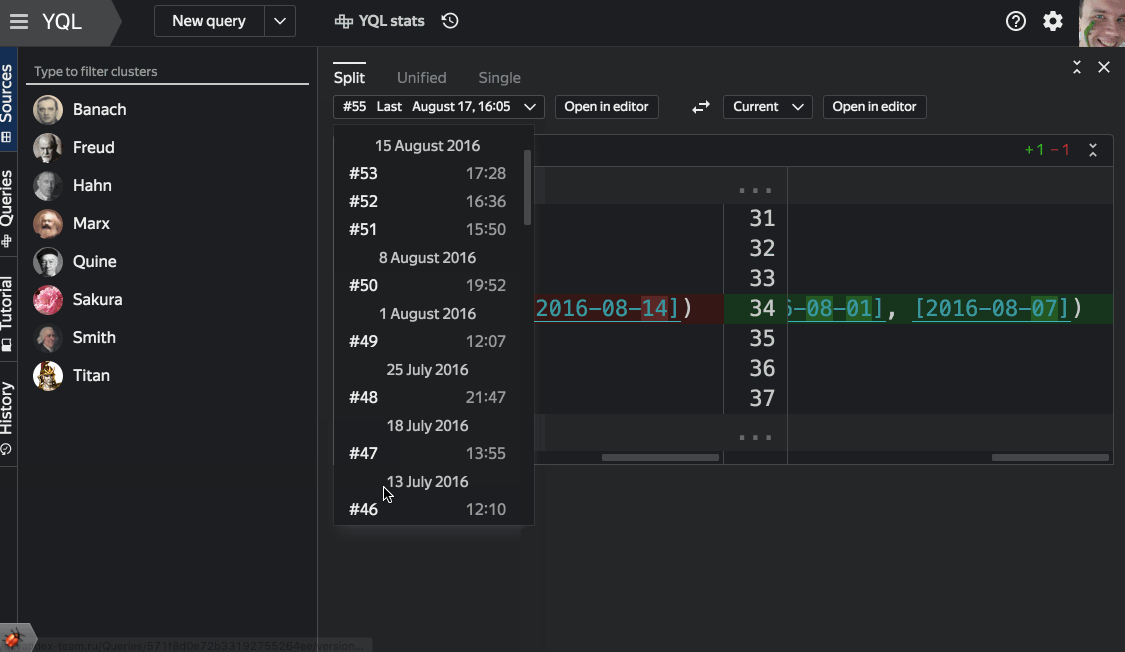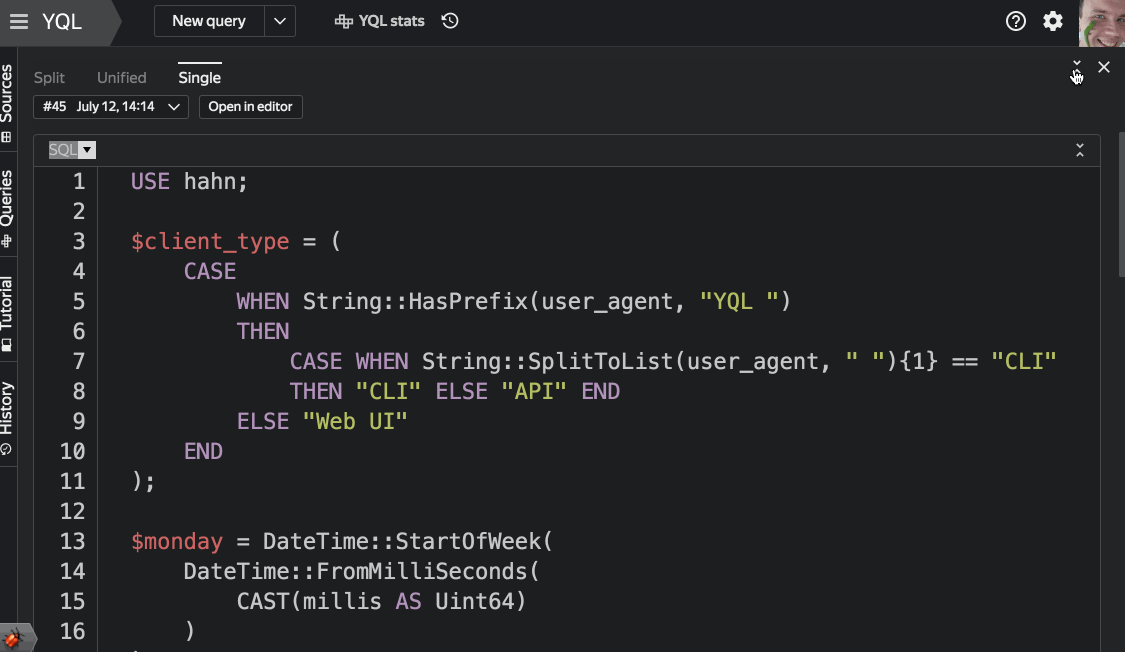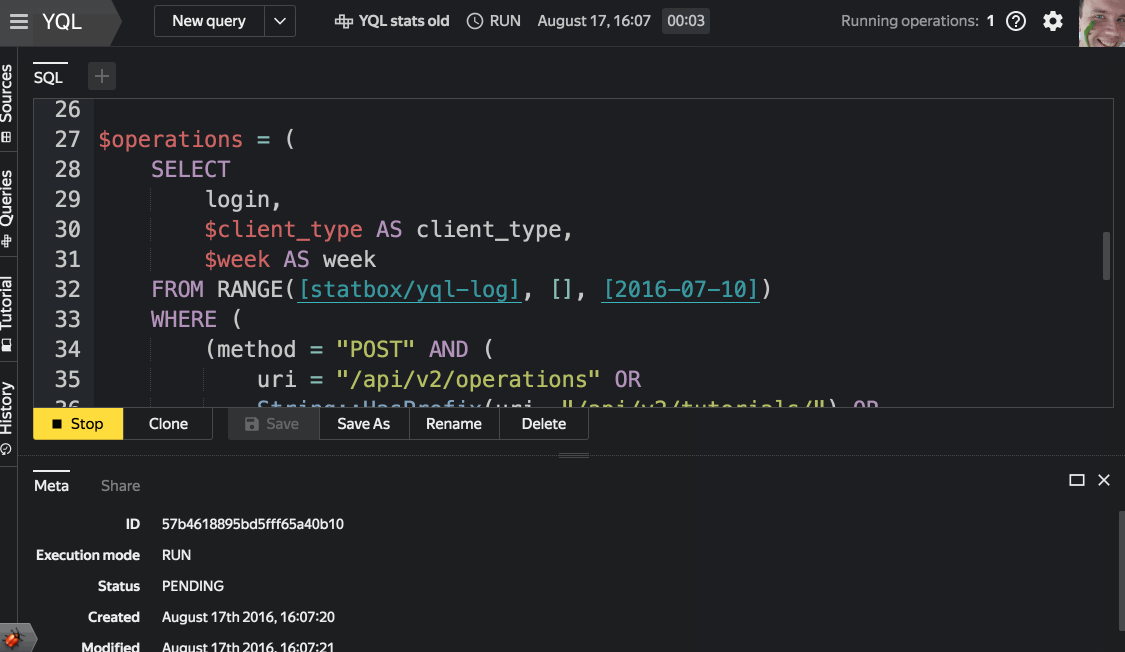
要求を名前で保存すると、履歴を表示して以前のバージョンに戻る機能を備えたコードリポジトリのミニアナログになります。
- リクエスト実行計画
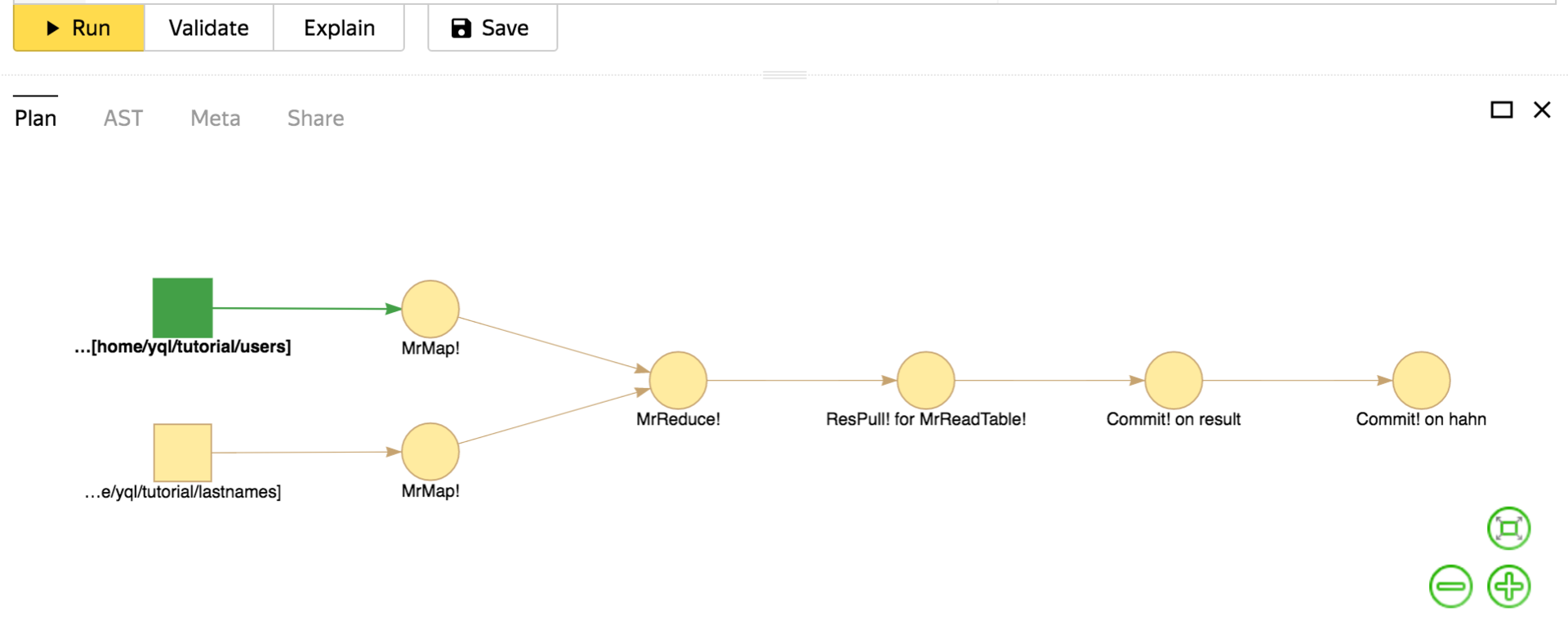
MapReduceに関するJOINの最も単純で最も普遍的な実装を以下に示します。
...だけでなく
REST API自体のすべてのペンにはコードで注釈が付けられ、Swaggerを使用してこれらの注釈を使用して詳細なオンラインドキュメントが自動的に生成されます。 それから、コードを1行も使わずにリクエストを試みることができます。 これにより、何らかの理由で上記の既製のオプションが適合しなかった場合でも、YQLを簡単に使用できます。 たとえば、Perlが好きな場合。
特徴
Yandex Query Languageを使用して解決できるタスクプランの種類と、ユーザーに提供される機会についてお話します。 すでに長いポストを延長しないように、この部分はむしろ論文です。
SQL
- メインのYQL方言はSQL:1992標準に基づいており、新しいエディションが散在しています。 すべての主要な設計がサポートされていますが、あまり人気がなかった複雑さの完全な互換性はまだ開発中です。 これにより、以前にSQLインターフェイスを使用してデータベースを操作していた多くの新しいユーザーは、言語を一から学ぶ必要があります。
- MapReduceパラダイムで実行されているバックエンドでは、ターゲットテーブル(簡単にするため)が自動的に作成されます。 ほとんどの場合、クエリ
SELECT任意の複雑さのSELECT構成され、オプションでINSERT INTO含みます。 - フル機能のDDL(
CREATE TABLE )およびCRUD(およびUPDATE 、 REPLACE 、 UPSERTおよびDELETE )は、OLTPスクリプトで使用できます。 - 標準SQLでサポートされていないか、面倒すぎると思われる多くの状況に対して、YQLにさまざまな構文拡張機能が追加されました。次に例を示します。
- 名前付き式
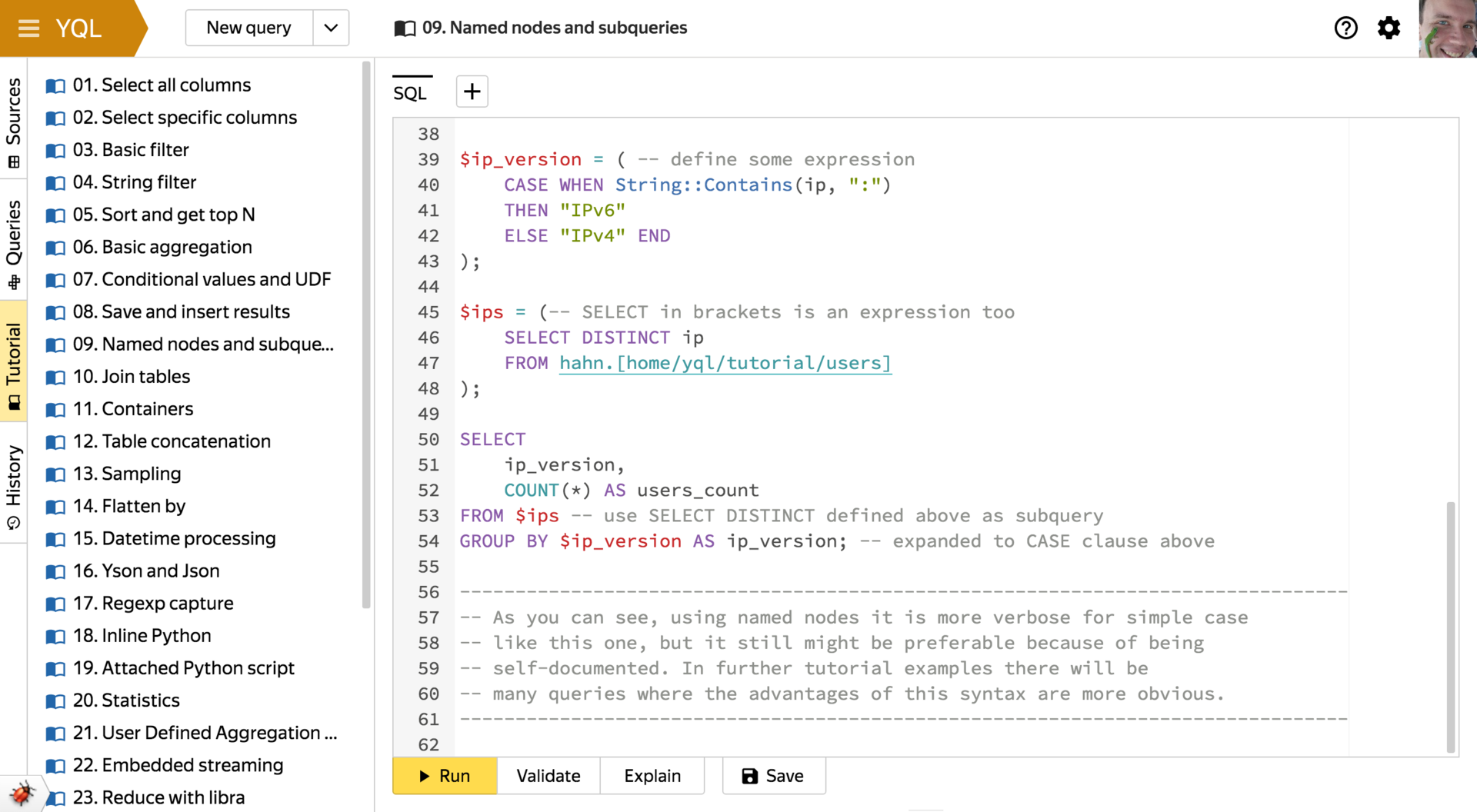
サブクエリのネストレベルが多数あるため、標準に従って互いに書き込むことはできません。 また、一般的に使用される式をコピーアンドペーストしないことも可能です。
- コンテナタイプの操作

キーまたはインデックス、および一連の特殊な組み込み関数によって要素を取得するために使用可能な構文。
FLATTEN BY
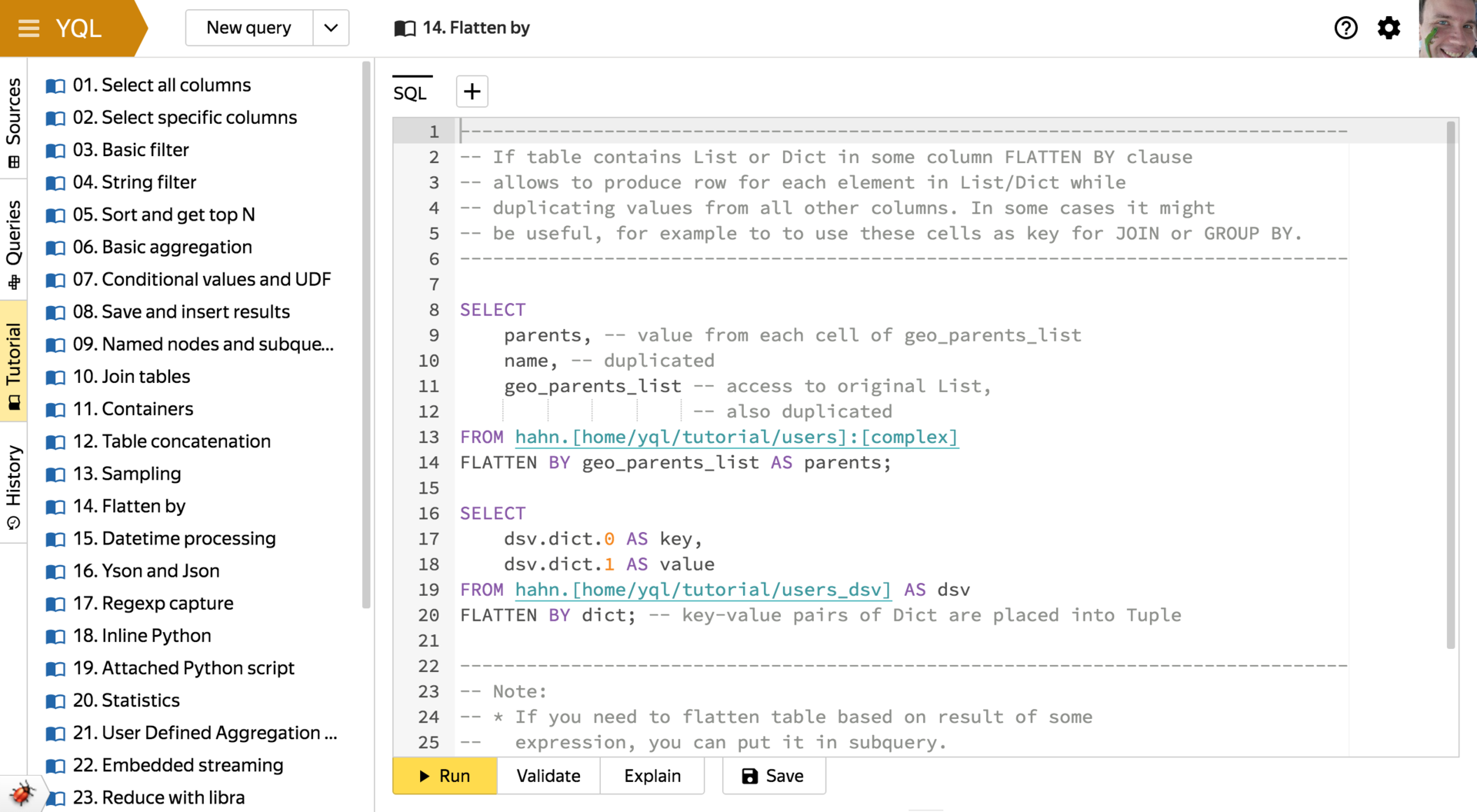
このキーワードには、対応するデータ型の列から可変長のコンテナ(リストまたはディクショナリ)を垂直方向に展開してソーステーブルの行を伝播する機能があります。
少しわかりにくいかもしれませんが、例を使って表示する方が簡単です。 次の形式の表を使用します。
左列にFLATTEN BYを適用すると、次の表が得られます。
このような変換は、コンテナ列のセルで統計を計算する必要がある場合(たとえば、 GROUP BYを介して)、またはセルにJOINを作成する別のテーブルの識別子が含まれている場合に便利です。
FLATTEN BYの面白い点はこれです。これを行うことができるすべてのシステムで異なる方法で呼び出されます。 私たちが発見したことから、単一の繰り返しはありません:
ARRAY JOIN -ClickHouse、unnest 、$unwind戻し-MongoDB、LATERAL VIEW -ハイブ、FLATTEN -Google BigQuery。
- 明示的な
PROCESS (マップ)およびREDUCE (リデュース)。
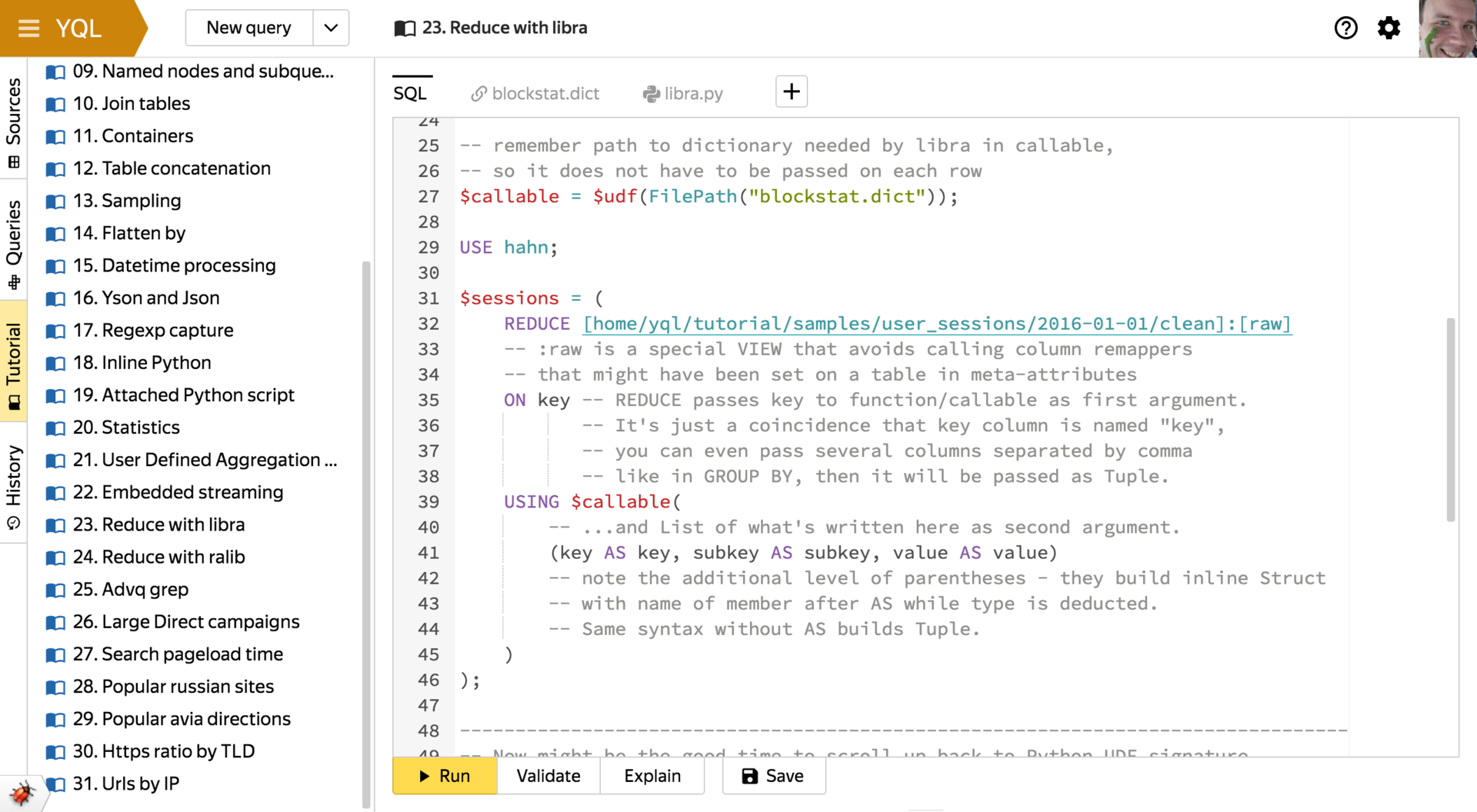
MapReduceパラダイムで記述された既存のコードを、以下で説明するユーザー定義関数メカニズムと組み合わせてYQLクエリに埋め込むことができます。
ユーザー定義関数
すべてのタイプのデータ変換が宣言的に便利に表現されるわけではありません。 ループを書いたり、既製のライブラリを使用したほうが簡単な場合があります。 このような状況に対して、YQLはユーザー関数のメカニズムを提供します。これらはユーザー定義関数であり、UDFでもあります。
- C ++ UDF
- すぐに使用できるC ++関数は100個以上あり、15個以上のモジュールに分かれています。 モジュールの例:String、DateTime、Pire、Re2、Protobuf、Jsonなど。
- 物理的に、C ++ UDFは、関数を呼び出して登録するためのABIセーフプロトコルを備えた動的にロードされるライブラリ(.so)です。
- C ++ UDFを記述し、ローカルでアセンブルすることができます(ビルドシステムにはUDFのビルド設定の既製セットがあります)、それを標準的な方法でリポジトリにロードし、URLで添付することでリクエストですぐに使用を開始できます。
- 単純なUDFの場合、詳細を隠す既製のC ++マクロを使用すると便利です。必要に応じて、さまざまなニーズに合わせて作成された柔軟なインターフェースを使用できます。
- Python UDF
- パフォーマンスがそれほど重要ではない場合、および命令型ビジネスロジックで挿入をすばやく行う必要がある問題を解決するには、宣言型クエリをPythonコードで希釈すると非常に便利です。 ほとんどのYandexの従業員はPythonを知っています。誰かが基本レベルで知らない場合は、数日で研究されます。
- Pythonスクリプトは、SQLまたはs-expressionsと組み合わせてインラインで作成するか、別のファイルとしてリクエストに添付することができます。 一般に、クライアントからまたはURLを介して計算の場所にファイルを配信するためのメカニズムは汎用的であり、辞書ファイルなど、必要なものすべてに使用できます。
- Pythonは動的型付けを使用し、YQLは静的型付けを使用するため、ユーザーは境界で関数シグネチャを宣言する必要があります。 これは、追加のミニ言語を使用して外部的に説明されています。事実、タイピング段階では、インタープリターを起動したくないということです。 将来的には、おそらくPython 3型のヒントのサポートを台無しにするでしょう。
- 技術的には、YQLのPythonサポートは、組み込みのPythonインタープリターとそれを呼び出すSQLパーサーの小さな構文シュガーを備えたC ++ UDFを介して実装されます。
- ストリーミングUDF。 そのため、他のテクノロジーからスムーズに切り替えることができ、特別な場合には、ストリーミングモードで任意のスクリプトまたは実行可能ファイルを実行する方法があります。 その結果、文字列のリストを別のリストに変換するUDFを取得します。
集計関数
内部では、集計関数は、
DISTINCTサポートし、最上位と
GROUP BY両方で実行される共通フレームワークを使用し
DISTINCT (SQL:1999標準の
ROLLUP/CUBE/GROUPING SETSを含む)。 そして、これらの機能はビジネスロジックのみが異なります。 以下に例を示します。
- 標準:
COUNT 、 SUM 、 MIN 、 MAX 、 AVG 、 VARIANCE 、 VARIANCE ; - 追加:
COUNT_IF 、 SOME 、 LIST 、 MIN_BY/MAX_BY 、 BIT_AND/OR/XOR 、 BOOL_AND/OR ; - 統計:
- ユーザー定義の集計関数:非常に特定のタスクの場合、たとえばPythonで上記のUDFメカニズムを使用して特定のシグネチャで複数の呼び出し値を作成することにより、ビジネスロジックを集計関数フレームワークに転送できます。
パフォーマンス上の理由から、集計関数のMapReduceの観点から、Mapサイドコンバイナーが自動的に作成され、Reduceの中間集計結果の集計が行われます。
DISTINCTは常に(近似計算なしで)正確に機能するようになったため、一意の値をマークするには追加のReduceが必要です。
テーブルを結合する
キーによるテーブルのマージは、問題を解決するためにしばしば必要とされる最も一般的な操作の1つですが、MapReduceの観点から正しく実装されるのはほとんど科学です。 論理的に、Yandexクエリ言語では、すべての標準モードに加えて、いくつかの追加モードが利用できます。
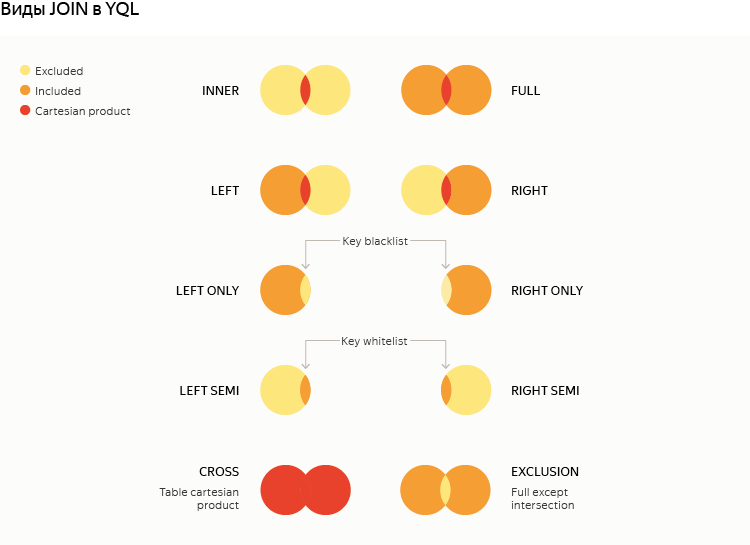
ユーザーから詳細を隠すために、MapReduceに基づくバックエンドの場合、参加テーブルの必要な論理タイプと物理プロパティに応じて、JOIN実行戦略がオンザフライで選択されます(これはいわゆるコストベースの最適化です)。
| 戦略 | 簡単な説明 | ブール型に利用可能 |
| 共通参加 | 1-2マップ+削減 | 全部 |
| マップ側の結合 | 1地図 | 内側、左、左のみ、左セミ、クロス |
| シャードマップ側の結合 | k並列マップ(デフォルトではk <= 4) | 内側、左セミ、ユニークな右、クロス |
| ソートせずに削減 | 1削減しますが、事前にソートされた入力が必要です | 開発中 |
開発方向
Yandex Query Languageの中期および中期計画の中で:
- 本番ステータスのバックエンドが増えました。
- 特殊なインタープリターではなく、ネイティブコードの生成とベクトル化。
- テーブルの物理的特性に応じて、I / Oの継続的な最適化とオンザフライでの実行戦略の選択。
- SQL:2003標準に基づくウィンドウ関数。
- SQLのサポート:1992年、ODBC / JDBCドライバーの作成、それに続いて一般的なORMおよびビジネスインテリジェンスツールとの統合。
- 操作の進捗状況の明確なデモンストレーション。
- UDFで利用可能なプログラミング言語の範囲の拡大-JavaScript( V8 )、Lua( LuaJIT )、Python 3を見てください。
- との統合:
まとめると
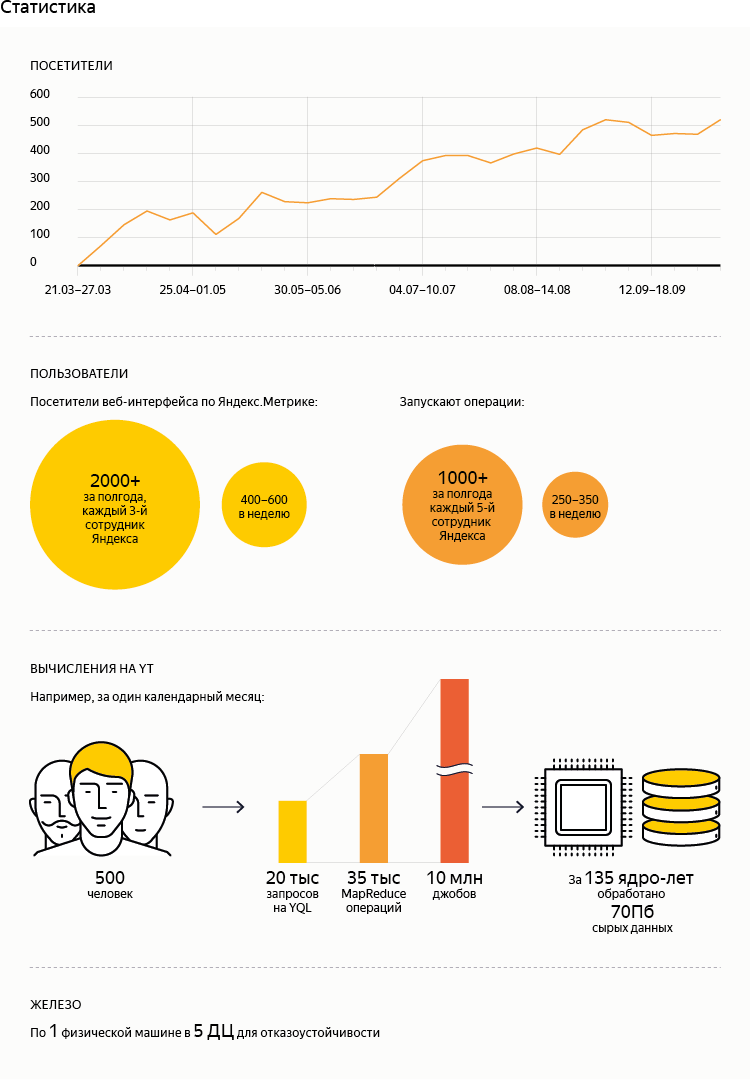
- 数字が示すように(統計を参照)、YQLはYandexの従業員の間で非常に人気のある製品になりました。 それでも、その助けを借りて処理されるデータの量はそれほど多くありません。 これは、歴史的にすべての生産プロセスが、それぞれのシステムの要件に適した低レベルのインターフェイスで動作するためです。 つまり、YQLへの段階的な移行は始まったばかりです。
- 当初、Yandex内では、次のタイプの抵抗に直面していました。MapReduceパラダイムで長年働いていたため、多くの人が慣れてしまい、再学習を望まなくなりました。 メインのモノリシックなYandexコードリポジトリであるArcadiaでは、各従業員が独自のコーナーを持っています。 歴史的に、文字通り何百ものC ++プログラムが存在し、特定のタスクのためにMapReduceの特定のログまたはテーブルのみを除外するためだけに記述されています。 しかし、満足のいくユーザーのクリティカルマスを獲得した後、そのような懐疑論は一般的ではなくなりつつあります。
- 「なぜHive 、 Spark SQL、またはその他の
SQL over ***はないのか」という質問に戻りSQL over *** 。まず、Yandexでアクティブに使用されるシステムのサポートに関心がありました。 プロジェクトの移行を簡素化したかったのです。つまり、投稿の最初の図にあるすべてのコンポーネントを開発および/または完成させる必要があります。 この場合、オープンソースコミュニティの基盤に適応する必要があります。 さらに、YandexのJava開発者はC ++開発者よりも桁違いに小さく、これらのオープンソースプロジェクトの中核を開発した経験のある人々は米国でも不足しているという事実には困難が伴います。 そして、結果として、それがより良くまたはより速くなるという事実はまったくありません。 YQLは、ほぼ10人のチームによって1年のどこかからゼロから作成されました。そのほとんどはフルタイムではありませんでした。 - SQLの方言だけに焦点を当てると、1つのプログラミング言語でデータマクロとビジネスロジックを統一された方法で説明することに慣れている、目立つクラスの人々への扉を閉じます。 Yandexには、既にNileというPython用のこのクラスのライブラリがありました。その中のランタイムではなく、s-expressionでのYQLクエリの生成と起動を実装しました(パブリックAPI用)。 現在、デフォルトで切り替えるための改善を進めています。 このようなインターフェイスが必要とされる他のプログラミング言語は、Yandexではあまり一般的ではありませんが、将来、たとえばJavaのアナログの出現は排除されません。
- Apache Software FoundationのエコシステムであるHadoopとSparkに対抗するために、オープンソースバックエンドのサブセットを使用してYQLをレイアウトすることは非常に興味深いでしょう。 残念ながら、これはさまざまな種類の困難により、近い将来には発生しません。たとえば、アルカディアの部分的な公開のためのツールの欠如、または内部インフラストラクチャとの多数の結びつきです。 しかし、私たちはすでにこの方向にゆっくりと動き始めています。
最後に、10月15日の次の土曜日に
オフィスでの会議に招待します。そこでは、Yandexインフラストラクチャのさまざまな側面について詳しく説明します。
