前回
、「本の見開き写真の背線を検索する」という記事で、その後見開きの本の写真で何が起こるか、つまり遠近法の歪みをなくし、テキストの曲線をまっすぐにすることについてお話しすることを約束しました。 これがなければ、OCR品質の結果を得るのはほとんど不可能です。
そのため、写真の背骨線はすでに見つかっていると考えられます。この知識を使用して、消失点の消失点を決定します。 消失点は、画像平面への本の透視投影での平行線の収束点です。 どちらもこの行の続きに配置する必要がありますが、ページごとにポイントの位置が異なる場合があります。 これを次の図に示します(実際、これはデバッグ用のログです)。 背骨線は赤で強調表示され、消失点で交差する線は緑です。

原則として、2ページの消失点は互いに遠くはありませんが、上記の例はこれが常に起こるとは限らないことを示しています:このスプレッドの左ページでは、緑色の線は非常に弱く収束し、消失点ははるか下にあり、右側では-上部に、比較的画像の端に近い。

画像でこれらの線を見つけるにはどうすればよいですか? 繰り返しになりますが、
ハフ変換は私たちを救います。それに応じて準備する必要があるのはイメージだけです。 画像内のテキストブロックの境界をできるだけ簡単な方法で強調表示しようとします。 これを行うには、次の簡単な手順を実行します。
1)二値化;
2)画像のサイズの正規化。たとえば、長辺で最大800ピクセル。
3)形態的建物(膨張、r = 6);
4)形態的勾配(r = 1)。



結果の画像に高速ハフ変換を適用すると、次のようになります。


ページとテキストブロックの境界に対応するいくつかの極大値は、明確に区別できます。 ルート行はこれらのセットを2つに分割し(それぞれ「左」と「右」と呼びます)、それぞれがハフの空間の線でよく説明されています。 ご存知のように、ハフの空間の線は画像空間の点に対応しています。 これらは、望ましい消失点です。
ハフ空間でラインを検索するには、最初に
非最大抑制アルゴリズムを使用して局所最大値を選択することをお勧めします。 最大値の0.2より弱い最大値はすべて破棄します。 原則として、ノイズは別の方法でフィルタリングできます。グラデーション画像では、かなり長い輪郭に対応するポイントのみを残すことが重要です。 ルートラインに対応するポイントの近傍からの最大値のグループ(記事の冒頭で赤で強調表示されます)、このクラスターの中心を平均化して、重みが増加した「左」および「右」のポイントセットに追加します。 最小二乗法(
OLS )を使用して、ポイントのセットを説明する線を検索します(図では、緑色で強調表示されています)。 したがって、元の画像の空間に消失点ができました。 残念なことに、彼らはそれをはるかに超えて横たわっているので、彼らにそれを描くことはできません。 これらのポイントの位置を知って、それらと交差する仮想線を描きました-最初の画像をもう一度見て、それらは緑色で強調表示されています。
これで、元の画像の垂直方向の遠近感を修正することで、元の画像を平坦化できます。 元の画像上にページの仮想四角形を構築しましょう。 何らかの方法でドキュメントの四隅の座標を設定する必要があり、その座標に射影変換を構築できます。 観察されたものの性質に基づいて、このような構造が一意ではないことに注意する価値があります:私たちは次のオプションを選択しました:私たちの四角形は台形であり、その基部はルートラインに垂直であり、これは側面の1つであり、反対側は消失点を通過しますそして、画像の側面の中央。 そのため、一方では画像からあまりカットしすぎず、他方では四角形を大きくしすぎません。 ここで、たとえば、別の写真ですが、原則はこれから変わりません:

もちろん、台形の基部を上下に配置し、外側を外側または内側に移動して、同時に他の射影変換を取得することもできますが、この段階では、脊椎が垂直になり、同じ長さの線になることが重要です。 取得した射影変換を各ページに個別に適用すると、次のようになります。


垂直の遠近法は修正されたと考えることができます。 次に、曲線の延長線に目を向けます。
画像内の単語の斜めの「断片」を選択します(このために、画像が2進化され、連結されたコンポーネントが強調表示され、相対的な位置を表すグラフが構築され、単語が事前に組み立てられます)。 色は、フラグメントの勾配を示します。<0-緑、if> 0-赤、0に等しい(1度に丸められる)-青。

ここで、「フラグメント」とは、「単語に接着」された接続コンポーネントを意味します。 それは単語全体、または単語の一部に対応することができます。これは予備分析の結果であり、真実を主張するものではありません。 すべての単語が目立ったわけではないことがわかりますが、ページモデルを構築するにはこれで十分です。
次のページモデルを使用します。
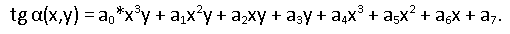
この式は何を教えてくれますか? 行のローカル傾斜角の正接は、水平3次、垂直1次の多項式です(以降、平面上の通常のデカルト座標を使用します)。 実際、空間内のページの歪みが円筒状であると仮定すると(シートの曲げ半径はx座標のみに依存します)、画像平面に投影したときの垂直傾斜角の依存性は線形になります。 水平方向では、3次多項式が十分な精度で変化する傾斜角を表すと考えられます。 もちろん、より小さな次数とより大きな次数の多項式を試しました。 一般に、モデルの選択はいくぶんarbitrary意的です。角度の観測値を十分に説明することが重要です。 そして、どこからそれらを取得しますか? それらの同じ斜めの断片。 ページの線のローカルチルト角に関するデータのサンプルがあります。各フラグメントには、その中心の座標とチルト角の値があります。これは、接着された接続コンポーネントのセットによって決定されます。
よく知られているMNCを使用して、パラメーターのベクトルを見つけます
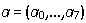
。 次に、単語の断片ではなく間違って何かを選択した可能性があるため、排出を除外します(大まかな予備的な分析がありました)。

ここに
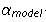 -i
-i番目のフラグメントの中心の座標を持つポイントでモデルによって計算された角度の値、
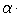
-フラグメントの傾斜の値(ソースデータ)、角度の値はラジアンで指定されます。 フィルタリングの結果として、指定されたエラーでモデルによって記述された十分な数のフラグメントがまだある場合、残りのデータにOLSを適用することでそれを改良できます。 したがって、予備的なページモデルを取得します。 十分な数の単語の断片を割り当てた画像の部分で曲線を非常によく説明していますが、脊柱領域では解は不正確です。 これを使用して線を真っ直ぐにすると、この領域が歪んでしまいます。
モデルを使用して、行を最後まで「トレース」してみましょう。 単語の断片の中心は、追跡アルゴリズムの「シード」として機能します。
曲線をトレースするための画像を準備しましょう:
-二値化、
-水平閉鎖(行アセンブリ)、
-水平方向の開口部(大文字のリモート要素を取り除きます)、
-ガウス平滑化(線を少し垂直にぼかします)。
幅
R = w / 100のウィンドウで開閉を実行します。ここで、
wは画像の幅です。
σ= h / 400で平滑化を実行します。ここで、
hは画像の高さです。
単語の各フラグメントの中心から両方向に線をトレースします。
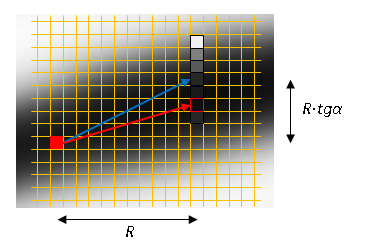
固定水平ピッチ
Rにシフトするたびに、
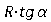
垂直に。 角度の値はモデルによって決定されます。 高さ±3ピクセルの垂直列で極大検索を行います。 指定された位置からプロセスを続行します。 停止基準は、極大値がないこと、または最大値がノイズしきい値
(T = 30)を超えないことです。

追跡の結果、より多くのデータ、つまり傾斜角の更新された値を持つセグメントを取得します。 このデータを使用してモデルを改良します。
モデルから取得した角度のマップを使用して、局所変位のマップを作成します。 現在の点での水平遠近法の角度を考慮します。
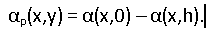
任意のポイントでの変位に乗算されます

。 これにより、ルート領域の文字を「伸ばす」ことができます。

►►►

すでにOCR入力にフィードできる画像が得られます。 見栄えの良い画像を作成するには、まだ作業が必要です。 次のようなものを取得したいと思います。

これを(もちろん、自動的に)行う方法は、読者に反映させることです。 結論として、このアルゴリズムは既に
ABBYY FineScannerモバイルアプリケーションでアプリケーションを発見しており、現在では本の見開き写真を処理できることに注意してください。