自然言語とテキストの言語分析を扱う場合、多くの場合、独自の短い短い行で作業する必要があります。 法案は数千億に及ぶ-それは、例えば、言語に存在する2つの単語の意味のある組み合わせです。 私たちの主なプラットフォームはJavaであり、非常に多くの小さなオブジェクトを操作するときのそのボラシティについて直接知っています。
災害の規模を評価するために、Javaで1億行の空白行を作成し、それらに必要なRAMの量を確認するという簡単な実験を行うことにしました。
注意:記事の最後にアンケートがあります。 記事を読む前に、自制のために答えようとすると面白いでしょう。
測定を行う際の適切なルールは、仮想マシンのバージョンとテストを開始するためのパラメーターを公開することです。
> java -version java version "1.8.0_101" Java(TM) SE Runtime Environment (build 1.8.0_101-b13) Java HotSpot(TM) 64-Bit Server VM (build 25.101-b13, mixed mode)
ポインター圧縮が有効(読み取り:ヒープサイズが32 GB未満):
java -Xmx12g -Xms12g -XX:+UseConcMarkSweepGC -XX:NewSize=4g -XX:+UseCompressedOops ... ru.habrahabr.experiment.HundredMillionEmptyStringsExperiment
ポインター圧縮オフ(読み取り:32 GBを超えるヒープサイズ):
java -Xmx12g -Xms12g -XX:+UseConcMarkSweepGC -XX:NewSize=4g -XX:-UseCompressedOops ... ru.habrahabr.experiment.HundredMillionEmptyStringsExperiment
テスト自体のソースコード:
package ru.habrahabr.experiment; import org.apache.commons.lang3.time.StopWatch; import java.util.ArrayList; import java.util.List; public class HundredMillionEmptyStringsExperiment { public static void main(String[] args) throws InterruptedException { List<String> lines = new ArrayList<>(); StopWatch sw = new StopWatch(); sw.start(); for (int i = 0; i < 100_000_000L; i++) { lines.add(new String(new char[0])); } sw.stop(); System.out.println("Created 100M empty strings: " + sw.getTime() + " millis");
プロセスjpsユーティリティを使用してプロセス識別子を
検索し、
jmapを使用して
ヒープダンプを
取得します。
> jps 12777 HundredMillionEmptyStringsExperiment > jmap -dump:format=b,file=HundredMillionEmptyStringsExperiment.bin 12777 Dumping heap to E:\jdump\HundredMillionEmptyStringsExperiment.bin ... Heap dump file created
Eclipse Memory Analyzer(MAT)を使用してヒープスナップショットを分析します。

ポインター圧縮をオフにした2回目のテストでは写真を撮りませんが、正直に実験を行い、単語を撮るようにお願いします(最適:テストをして、自分で確かめてください)。
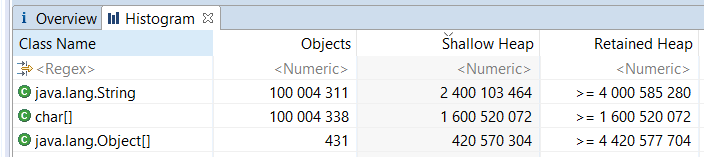
結論- 2.4 GBは、Stringクラスのオブジェクトのバインド+文字の配列へのポインター+ハッシュによって占有されます。
- 1.6 GBは文字配列にバインドされています。
- 400 MBはラインポインターによって占有されます。
32GBを超えるヒープサイズを使用している場合(ポインターの圧縮がオフになっている場合)、ポインターのコストはさらに高くなります。 したがって、次のような結果があります。
- 3.2 GBは、Stringクラスのオブジェクトと文字の配列へのポインター+ハッシュのバインディングで占められます。
- 2.4 GBは文字配列にバインドされています。
- 800 MBはラインポインターによって占有されます。
合計で、行ごとに、文字配列のサイズに加えて、44バイト(ポインター圧縮なしの64バイト)を支払います。 平均文字列の長さが15文字の場合、各文字についてほぼ5バイトが取得されます。 それがホーム腺になると法外に高価。
戦う方法リソースを節約するには、主に2つの戦略があります。
- 重複する行が多数ある場合は、文字列インターンまたは重複排除を使用できます。 メカニズムの本質は次のとおりです。Javaの行は不変であるため、新しい行を作成する代わりに、それらを別のプールに格納し、繰り返すときに既存のオブジェクトを参照できます。 このアプローチは無料ではありません。プール構造を保存して検索するのにメモリとプロセッサの両方の時間がかかります。
インターンと重複排除の違い、後者のバリエーション、およびString.intern()メソッドを使用することの危険性については 、 31: 52からのAlexei Shipilevによる優れたレポート( link )を参照してください。
- この場合のように、行が一意である場合、さまざまなアルゴリズムトリックを使用する以外に何もする必要はありません。 ミニアナウンスメント:近い将来に語るタスクで、何億ものバイグラム(単語:単語+ 15文字)をどのように扱うか。
残念ながら、Javaで個々の行をよりコンパクトに格納する組み込みメカニズムはありません。 将来、状況は個々のシナリオでわずかに改善する可能性があります
。JEP254を参照してください。
見るためにOracleのAlexei Shipilevによる大声での名前「Catechism java.lang.String」でレポートを参照することを強くお勧めします(
ヒントはperiskopに感謝します)。 そこで彼は、4:26の記事の問題と、31:52から始まる文字列の抑留/重複排除について話しています。
結論として問題の解決策は、その範囲の評価から始まります。 これでこれらのスケールがわかったので、プロジェクトで多数の行を操作する際のオーバーヘッドを考慮することができます。