テストは間違いなくアプリケーション開発の柱の1つです。 一般的なクジラと同様に、テストはバグを引き起こす可能性があり、長期間停止しない可能性があります。 しかし、主な問題はテストカバレッジの妥当性です-書かれたテストケースのすべてのバグをキャッチできますか? おそらく、一部はユーザーの負荷の下でのみ表示されます。 これらを識別するために、原則として、ユーザーの訴えが起爆し、次の連鎖反応が起動します。ヘルプデスクスペシャリスト、2番目のサポートライン、そして運が良ければ、緊急操作メッセージが開発者の手に渡ります。 はい、APM監視システムからも発生する可能性があります(もしあれば)。 しかし、これらすべてのことから、例外が発生する前に変数がどの値をとったかを明確に決定することはできません。 投稿では、そのような状況で役立つように設計されたソリューションについて説明します。
自分を快適にします。 Java、Scala、Clojure、Groovyアプリケーションのエラーを検出するソリューションである
OverOpsについて
説明しましょう。 いくつかのスクリーンショットを表示し、製品の主な機能について説明します。 導入部では、偶然ではなく、テストについて話していました。 間違い 生産的環境で生じることは、必ずしも開発およびテスト環境に現れるとは限りません。 また、実際のユーザーアクティビティの負荷により、これまでにない例外が発生する可能性があります。
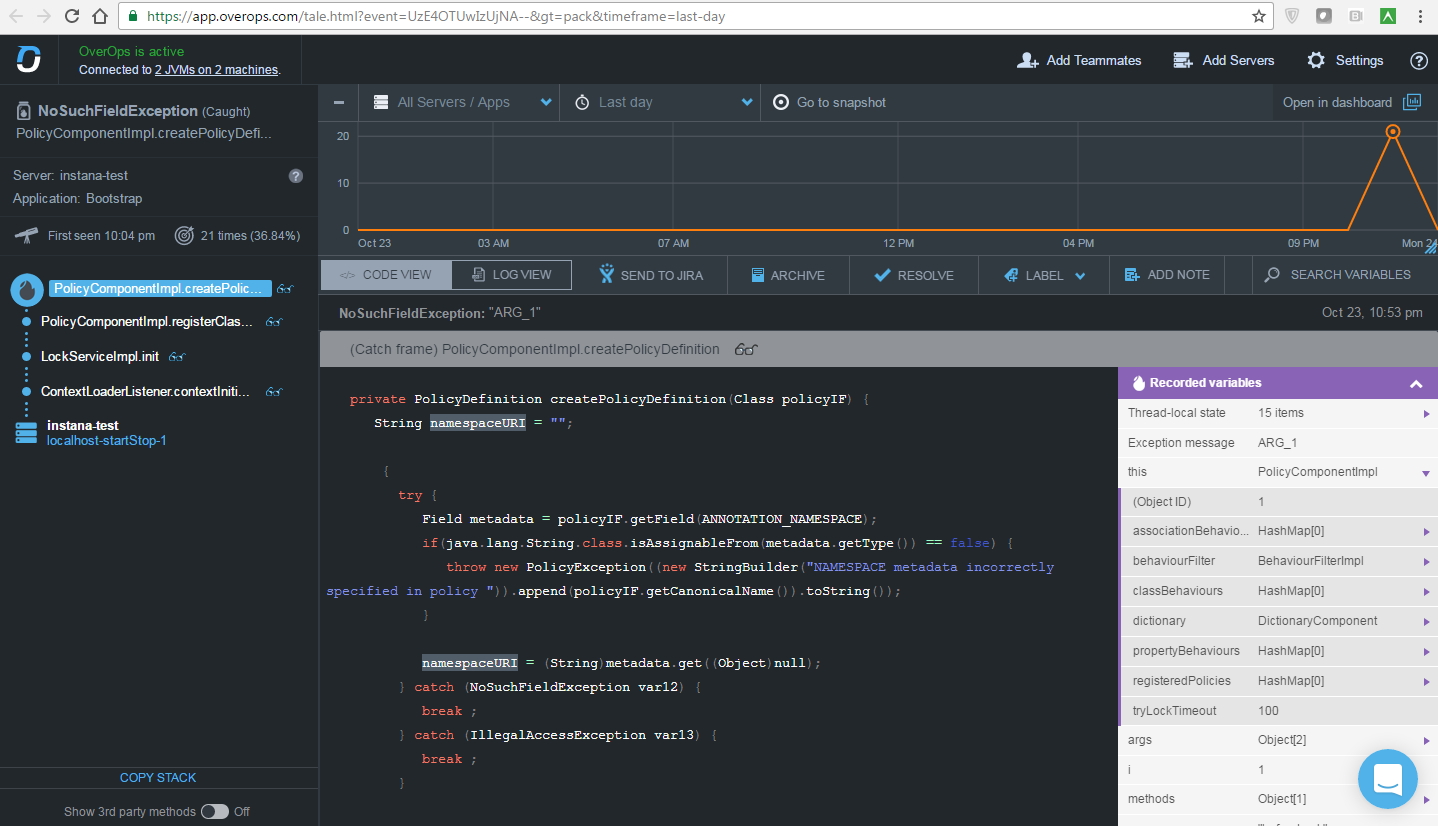
OverOpsの本質は次のとおりです。
1)JVMが起動すると、その横にOverOpsエージェントが起動します。
2)エージェントは、コード内の例外(処理済みと未処理の両方)の発生を監視できます。
3)エージェントは例外発生時にheapdumpを削除し、逆コンパイルされたバイトコードに課します。
その結果、例外が発生する前に変数が取った値を確認できます。 エージェントが機能すると、ベンダーは最大オーバーヘッド3%を要求します。 負荷の小さい実験室のベンチでは、この指標に近づくことができなかったので、今のところはそれを信じています。
誰にもわからないが、インターフェイスのあちこちで時々点滅するモンスターに特に満足している。 OverOpsに
は全体のモンスターセットがあり、適切なエラーが発生するとその一部が具体化
されることがわかります。 おかしい?

インターフェイス自体では、次のようになります。
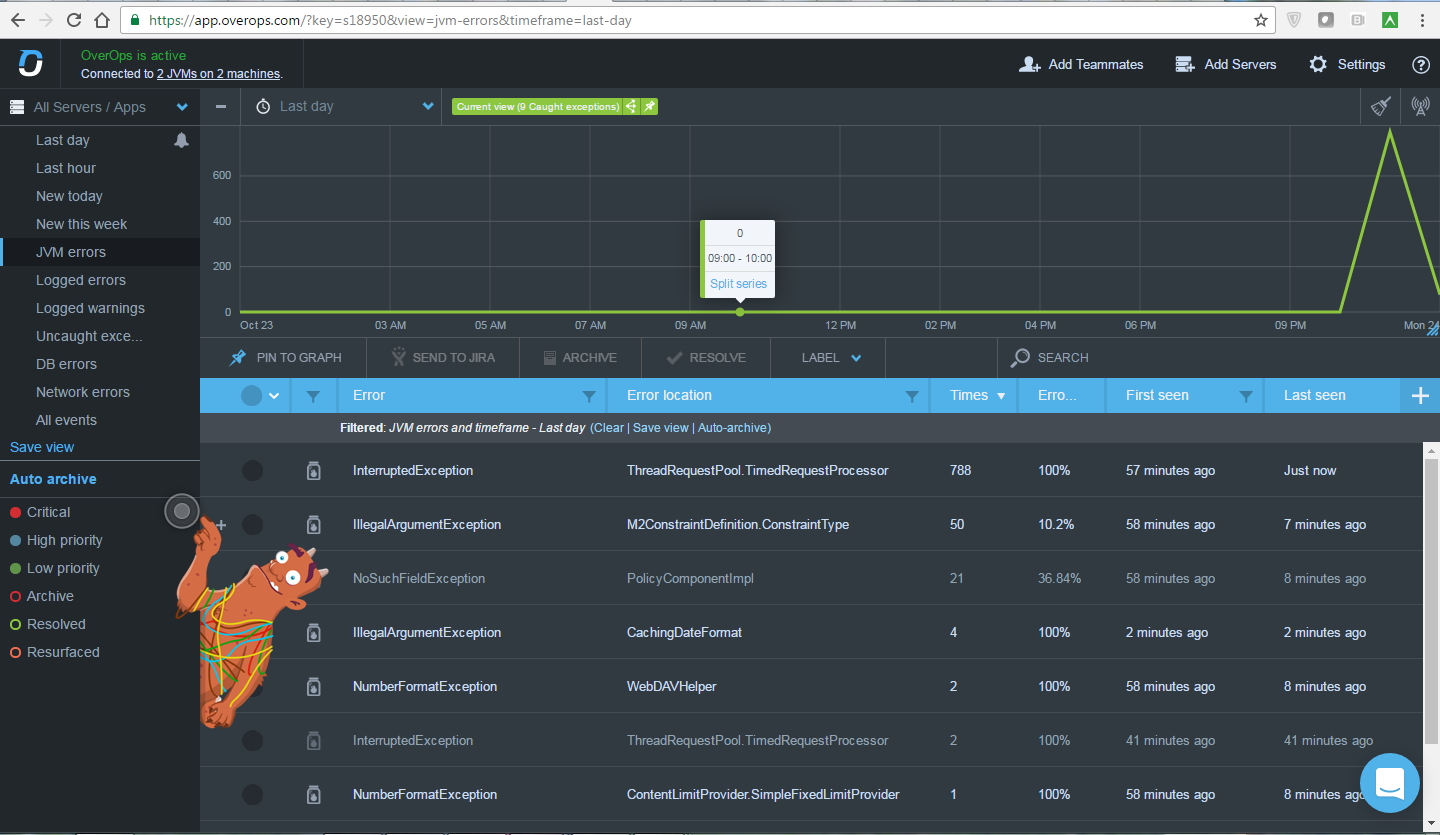
システムはスナップショットを定期的に収集します(つまり、すべてのエラーは表示されませんが、その数は表示されます)。 たとえば、「このタイプまたはそのタイプの10個のエラー」:「そこに報告」(「Jiraでバグを取得」、「Slackで落書き」、
「Twitterに投稿」など)ルールを作成できます。 統合の完全なリストは
ここにあります 。
NewRelicとのテスト統合の例を次に示します。 詳細は[プラグイン]タブに表示され、OverOpsの直接リンクが付いています。これは、率直に言って非常に便利です。
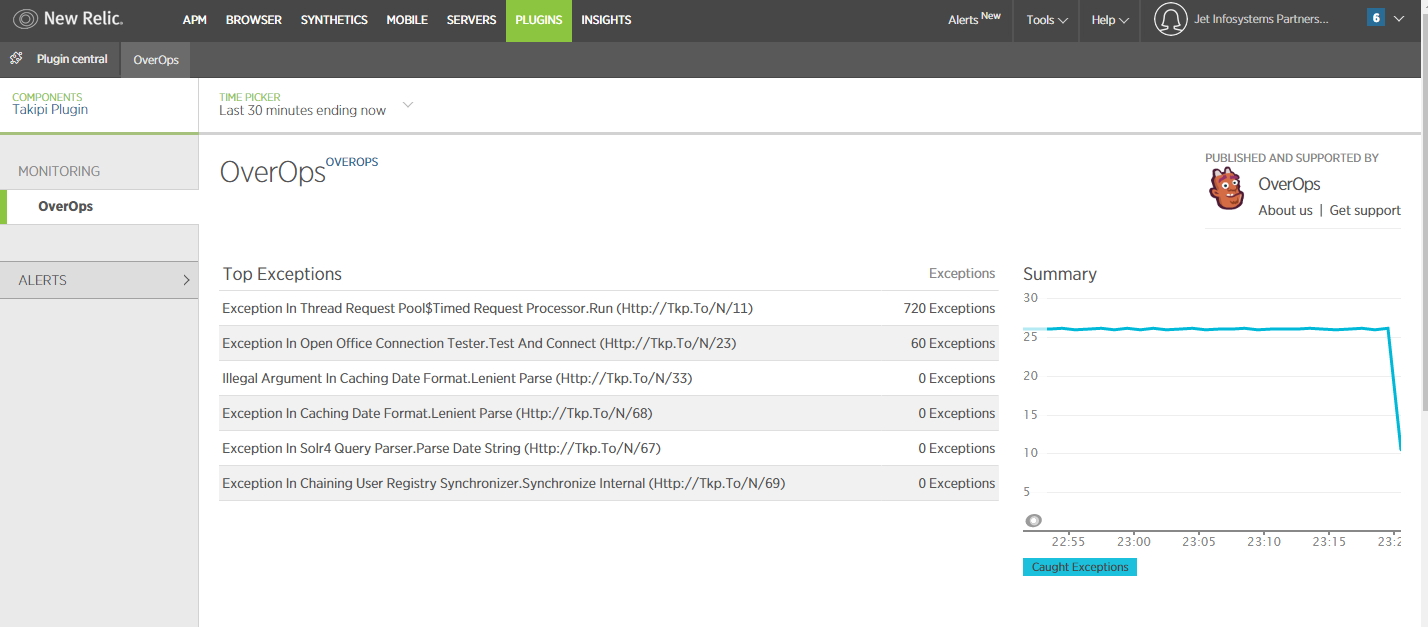
OverOpsは、サードパーティのライブラリをフィルタリングして、監視から除外することができます。 インターフェイス自体では、次のようになります。
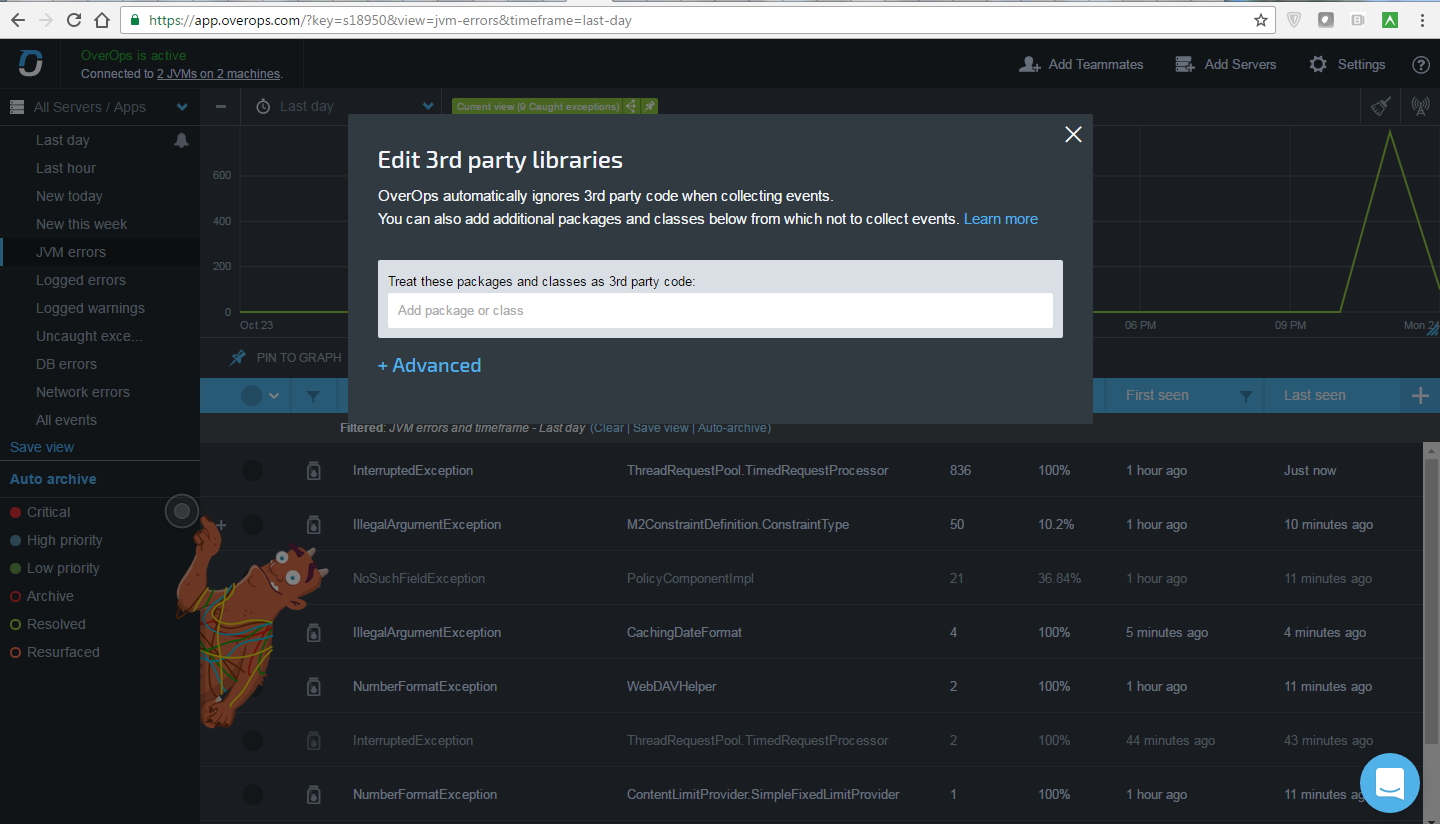
別の機能:外部からのソースコードの添付、個人データが含まれる場合のエラーのフィルタリング(正規表現で構成)。 小さいマイナスのうち、ベースタイプから継承されたオブジェクトのタイプは表示できず、メソッドシグネチャはベースタイプを取得します。
ソリューションのインストールの種類によって、考えられるすべてのシナリオが提供されます:SaaS、ハイブリッド、オンプレミス。
もちろん、ハイシーズンにOverOpsが非常に役立つと言うのは遅すぎます。結局、負荷が増加している期間中に、他の時点では現れなかったさまざまなエラーをキャッチする大きなチャンスがあります。 しかし、次の休日とそれらに関連するピーク出席者までに、小売システムを慎重に監視することはまだ検討する価値があります。 コメントで質問してください。 また、タスクに少し思慮深いアプローチが必要な場合、
吹雪や吹雪の窓などのコンサルティングサービスが常に適切なタイミングで表示されます。
記事の著者:
Anton Kasimov 、制御システムのアーキテクト、Jet Infosystems社。