この記事の著者は、MVP-Cloud and Datacenter ManagementのRoman Levchenko( www.rlevchenko.com )です。
みなさんこんにちは! 最近では、Windows Server 2016がグローバルに利用可能になりました。つまり、インフラストラクチャで新しいバージョンの製品の使用を開始できるようになりました。 イノベーションのリストは非常に広範囲であり、それらの一部については既に説明しています(
ここと
ここ )が、この記事では、(特に仮想化環境で)最も興味深く使用されている高可用性サービスを分析します。

クラスタOSのローリングアップグレード
以前のバージョンのWindows Serverでのクラスターの移行は、元のクラスターにアクセスできず、ノード上の更新されたOSに基づいて新しいクラスターを作成し、その後クラスター間で役割を移行するため、大幅なダウンタイムを引き起こしました。 このようなプロセスでは、スタッフの資格、特定のリスク、および人件費が管理されないという要件が増加します。 この事実は、CSPまたはSLA内のサービスの利用不可に時間制限がある他の顧客に特に当てはまります。 リソースプロバイダーにとってSLAの重大な違反が意味することを説明しないでください)
Windows Server 2016は、アップグレード中に同じクラスター内のノードでWindows Server 2012 R2とWindows Server 2016を組み合わせる可能性を通じて状況を修正します(クラスターOSローリングアップグレード(以下、CRU))。

名前から、クラスター移行プロセスは主にサーバーへのOSの段階的な再インストールにあると推測できますが、これについては後ほど詳しく説明します。
最初に、CRUが提供する「グッズ」のリストを定義します。
- WS2012R2 Hyper-V / SOFSクラスターをアップグレードする際の完全なダウンタイムの欠如。 他のクラスターロール(たとえば、SQL Server)では、1回限りのフェールオーバーを実行するために必要な、使用不可(5分未満)が可能です。
- 追加のハードウェアは不要です。 原則として、クラスターは1つ以上のノードがアクセスできない可能性を考慮して構築されます。 CRUの場合、ノードの使用不可が計画され、段階的に行われます。 したがって、少なくとも1つのノードが一時的に存在しなくてもクラスターが簡単に生き残ることができる場合、ゼロダウンタイムを達成するために追加のノードは必要ありません。 一度に複数のノードをアップグレードする予定がある場合(これはサポートされています)、使用可能なノード間の負荷分散を事前に計画する必要があります。
- 新しいクラスターを作成する必要はありません。 CRUは現在のCNOを使用します。
- 移行プロセスは可逆的です(クラスターレベルが増加するまで)。
- インプレースアップグレードサポート。 ただし、クラスターノードを更新するための推奨オプションは、データを保存せずにWS2016を完全にインストールすることです(クリーンOSインストール)。 インプレースアップグレードの場合、各ノード(イベントログなど)を更新した後、完全な機能を確認する必要があります。
- CRUはVMM 2016で完全にサポートされており、PowerShell / WMIを介してさらに自動化できます。
2ノードのHyper-Vクラスターの例を使用したCRUプロセス:
- クラスター(DB)と実行中のリソースの予備バックアップをお勧めします。 クラスターは操作可能でなければならず、ノードはアクセス可能です。 必要に応じて、移行前に既存の問題を修正し、移行を開始する前にバックアップタスクを一時停止します。

- Cluster Aware Updating(CAU)を使用するか、WU / WSUSを使用して手動でWindows Server 2012 R2のクラスターノードを更新します。
- 構成されたCAUでは、移行中に役割の配置とノードの状態に影響を与える可能性があるため、一時的に無効にする必要があります。

- WS2016内での仮想マシンの実行をサポートするには、ノード上のCPUにSLATサポートが必要です。 この条件は必須です。
- ノードの1つで、ロールの転送(ドレインロール)とクラスターからの除外(排除)を実行します。

- ノードがクラスターから除外された後、WS2016の推奨される完全インストールを実行します(クリーンOSインストール、 カスタム:Windowsのみをインストール(高度) )

- 再インストール後、ネットワーク設定を*戻し、ノードを更新し、必要な役割とコンポーネントをインストールします。 私の場合、Hyper-Vの役割と、もちろんフェールオーバークラスタリングが必要です。
New-NetLbfoTeam -Name HV -TeamMembers tNIC1,tNIC2 -TeamingMode SwitchIndependent -LoadBalancingAlgorithm Dynamic
Add-WindowsFeature Hyper-V, Failover-Clustering -IncludeManagementTools -Restart
New-VMSwitch -InterfaceAlias HV -Name VM -MinimumBandwidthMode Weight -AllowManagementOS 0
* Switch Embedded Teamingの使用は、WS2016への移行が完了した後にのみ可能です。 - 適切なドメインにノードを追加します。
Add-Computer -ComputerName HV01 -DomainName domain.com -DomainCredential domain\rlevchenko
- ノードをクラスターに戻します。 クラスターは混合モードで動作を開始し、新しいWS2016機能をサポートせずにWS2012R2機能をサポートします。 残りのサイトのアップグレードは4週間以内に完了することをお勧めします。

- クラスターの役割をHV01ノードに戻し、負荷を再分散します。
- 残りのノード(HV02)に対してステップ(4-9)を繰り返します。
- ノードをWS2016にアップグレードした後、クラスターの機能レベル(混合モード-8.0、完全-9.0)を上げて、移行を完了する必要があります。
PS C:\ Windows \ system32> Update-ClusterFunctionalLevel
クラスターhvclの機能レベルを更新します。
警告:この操作を取り消すことはできません。 続行しますか?
[Y]はい[A]すべてはい[N]いいえ[L]いいえ[すべて]いいえ[S]サスペンド[?]ヘルプ(デフォルトはY):a
お名前
-hvcl
- (オプションおよび注意して)新しいHyper-V機能を含むようにVM構成バージョンを更新します。 VMのシャットダウンが必要であり、予備バックアップが望ましいです。 2012R2のVMバージョンは5.0で、2016 RTMでは8.0です。この例は、クラスター内のすべてのVMを更新するコマンドを示しています。
Get-ClusterGroup|? {$_.GroupType -EQ "VirtualMachine"}|Get-VM|Update-VMVersion
2016 RTMでサポートされているVMバージョンのリスト:

クラウド監視
任意のクラスター構成で、追加の音声と全体的なクォーラムを提供するために、Witness配置の機能を考慮する必要があります。 2012 R2の監視は、各クラスターノードにアクセス可能な共有外部ファイルリソースまたはディスクに基づいて構築できます。 2012 R2(動的クォーラム)以降、任意の数のノードでWitness構成の必要性が推奨されることを思い出させてください。
Windows Server 2016では、新しいCloud Witnessベースのクォーラム構成モデルを使用して、Windows Serverおよびその他のシナリオに基づいてDRを構築できます。
Cloud Witnessは、Microsoft Azureリソース(Azure Blob Storage、HTTPS経由、ノード上のポートにアクセスできる必要があります)を使用して、クラスターノードのステータスが変化すると変化するサービス情報を読み書きします。 BLOBファイル名はクラスターの一意の識別子に従って作成されます。したがって、1つのストレージアカウントを一度に複数のクラスターに提供できます(自動作成されたmsft-cloud-witnessコンテナー内のクラスターごとに1つのBLOBファイル)。 クラウドストレージのサイズ要件は、監視するために最小限であり、大きなメンテナンスコストを必要としません。 また、Azureでホストすることにより、ストレッチクラスターと災害復旧ソリューションを構成する際に3番目のサイトが不要になります。

Cloud Witnessは、次のシナリオで使用できます。
- 異なるサイト(マルチサイト)でホストされるDRクラスターを提供するため。
- 共有ストレージのないクラスター(Exchange DAG、SQL Always-Onなど)。
- Azureとオンプレミスの両方で実行されているゲストクラスター。
- 共有ストレージ(SOFS)の有無にかかわらず、ストレージクラスター。
- ワークグループ内またはドメイン全体のクラスター(新しいWS2016機能)。
Cloud Witnessを作成および追加するプロセスは非常に簡単です。
- 新しいAzureストレージアカウント(ローカル冗長ストレージ)を作成し、アカウントプロパティでアクセスキーの1つをコピーします。

- クォーラム構成ウィザードを実行し、[クォーラム監視の選択-クラウド監視の構成]を選択します。

- 作成したストレージアカウントの名前を入力し、パスキーを挿入します。

- 構成ウィザードが正常に完了すると、コアリソースにウィットネスが表示されます。

- コンテナ内のBLOBファイル:

簡単にするために、PowerShellを使用できます。

ワークグループとマルチドメインクラスター
Windows Server 2012 R2以前では、クラスターを作成する前にグローバル要件を満たす必要があります。ノードは同じドメインのメンバーである必要があります。 2012 R2で導入されたActive Directory Detachedクラスターには同様の要件があり、それほど単純化されていません。
Windows Server 2016では、ワークグループ内または異なるドメインのメンバーであるノード間でADにバインドせずにクラスターを作成できます。 このプロセスは、2012 R2で切り離されたクラスターを作成することに似ていますが、いくつかの機能があります。
- WS2016環境内でのみサポートされます。
- フェールオーバークラスタリングの役割が必要です。
Install-WindowsFeature Failover-Clustering -IncludeManagementTools
- 各ノードで、Administratorsグループのメンバーシップを持つユーザーを作成するか、ビルトインアカウントを使用する必要があります。 記録。 パスワードとユーザー名は同一でなければなりません。

net localgroup administrators cluadm /add
「要求されたレジストリアクセスが許可されていません」 エラーが発生した場合は、 LocalAccountTokenFilterPolicyポリシー値を変更する必要があります 。
New-ItemProperty -Path HKLM:\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\System -Name LocalAccountTokenFilterPolicy -Value 1
- ホスト上のプライマリDNSサフィックスを定義する必要があります。

- クラスターの作成は、PowerShellとGUIの両方でサポートされています。
New-Cluster -Name WGCL -Node rtm-1,rtm-2 -AdministrativeAccessPoint DNS -StaticAddress 10.0.0.100
- ウィットネスとしては、前述のディスクウィットネスまたはクラウドウィットネスのみを使用できます。 残念ながら、ファイル共有監視はサポートされていません。
サポートされているユースケース:
| 役割 | サポート状況 | 解説 |
|---|
| SQLサーバー | でサポート | SQL Server統合認証の使用を推奨 |
| ファイルサーバー | サポートされているが推奨されていない | SMBの基本であるKerberos認証の欠如 |
| ハイパーv | サポートされているが推奨されていない | クイック移行のみが利用可能です。 ライブ移行はサポートされていません |
| メッセージキュー(MSMQ) | サポートされていません | MSMQ ADDSが必要です |
仮想マシンの負荷分散/ノードの公平性
VMMで利用可能なDynamic Optimizationは、Windows Server 2016に部分的に移行され、自動モードのノードで基本的な負荷分散を提供します。 リソースを移動するには、ライブマイグレーションとヒューリスティックを使用します。これに基づいて、クラスターは30分ごとにバランスをとるかどうかを決定します。
- ノードの現在のメモリ使用率。
- 5分間隔の平均CPU負荷。
最大許容負荷値は、
AutoBalancerLevel値によって決定されます。
get-cluster| fl *autobalancer* AutoBalancerMode : 2 AutoBalancerLevel : 1
| AutoBalancerLevel | 積極性のバランス | 解説 |
|---|
| 1(デフォルト) | 低い | ヒューリスティックの1つに従って、80%を超えるノードをロードするときにバランスをとる |
| 2 | 中 | 70%以上をロードする場合 |
| 3 | 高い | 60%以上をロードする場合 |
バランサーのパラメーターは、GUI(cluadmin.msc)でも定義できます。 デフォルトでは、低攻撃性レベルとコンスタントバランシングモードが使用されます。

検証には、次のパラメーターを使用します。
AutoBalancerLevel:2 (Get-Cluster).AutoBalancerLevel = 2
AutoBalancerMode:2 (Get-Cluster).AutoBalancerMode = 2
まず、CPU(約88%)の負荷をシミュレートし、次にRAM(77%)の負荷をシミュレートします。 なぜなら バランスを決定する際に平均レベルの積極性が決定され、負荷ノード上の特定の値(70%)を超える仮想マシンは空きノードに移動する必要があります。 スクリプトは、ライブマイグレーションの瞬間を予期し、経過時間(ダウンロードがノードに開始された時点からVMのマイグレーションまで)を表示します。
CPUの負荷が高い場合、バランサーは1 VMを超えて移動しましたが、RAM負荷-1 VMは指定された30分間隔内で移動し、その間にノード負荷がチェックされ、VMが他のノードに転送されてリソース利用率が70%以下になりました

VMMを使用する場合、ノード上の組み込みのバランシングは自動的に無効になり、動的最適化に基づいたより推奨されるバランシングメカニズムに置き換えられます。これにより、最適化モードと間隔をさらに構成できます。
仮想マシンの開始順序
2012 R2でクラスター内でVMを起動するためのロジックの変更は、優先度(低、中、高)の概念に基づいています。タスクの目的は、残りの「依存」VMを起動する前に、より重要なVMの包含とアクセシビリティを確保することです。 これは通常、たとえばActive Directory、SQL Server、IISに基づいて構築された多層サービスに必要です。
機能と効率を向上させるために、Windows Server 2016には、VMまたはVMグループ間の依存関係を判断して、クラスターグループのセットを使用して正しく起動するかどうかを決定する機能が追加されました。 これらは主にVMと組み合わせて使用することを目的としていますが、他のクラスターの役割にも使用できます。

たとえば、次のスクリプトを使用します。
1 VM
Clu-VM02は、仮想で実行されているActive Directoryの可用性に依存するアプリケーションです。 カー
Clu-VM01 そして、VM
Clu-VM03は 、VM
Clu-VM02にあるアプリケーションの可用性に依存します。
PowerShellを使用して新しいセットを作成します。
 Active Directoryを備えたVM:PS C:\> New-ClusterGroupSet -Name AD -Group Clu-VM01
Active Directoryを備えたVM:PS C:\> New-ClusterGroupSet -Name AD -Group Clu-VM01
名前:AD
GroupNames:{Clu-VM01}
ProviderNames:{}
StartupDelayTrigger:遅延
StartupCount:4294967295
IsGlobal:False
StartupDelay:20アプリケーション:New-ClusterGroupSet -Name Application -Group Clu-VM02アプリケーション依存サービス:New-ClusterGroupSet -Name SubApp -Group Clu-VM03セット間に依存関係を追加します。Add-ClusterGroupSetDependency -Name Application -Provider AD
Add-ClusterGroupSetDependency -Name SubApp -Provider Application必要に応じて、
Set-ClusterGroupSetを使用して設定パラメーターを変更できます。 例:
Set-ClusterGroupSet Application -StartupDelayTrigger Delay -StartupDelay 30
StartupDelayTriggerは、グループの開始後に実行する必要があるアクションを定義します。
- 遅延-20秒待機します(デフォルト)。 StartupDelayと組み合わせて使用します。
- オンライン-セットのグループ可用性ステータスを待ちます。
StartupDelay-秒単位の遅延時間。 デフォルトでは20秒。
isGlobal-他のクラスターグループのセットを開始する前にセットを実行する必要性を決定します(たとえば、Active Directory VMのグループを持つセットはグローバルにアクセス可能である必要があるため、他のコレクションよりも早く開始する必要があります)。
VM Clu-VM03を起動してみましょう。
Clu-VM01でのActive Directoryの可用性の待機(StartupDelayTrigger-遅延、StartupDelay-20秒)

Active Directoryの起動後、依存アプリケーションはClu-VM02で起動します(この段階でStartupDelayが適用されます)。

最後のステップは、VM Clu-VM03自体を起動することです。

VMコンピューティング/ストレージの復元力
Windows Server 2016では、ノードとVMの新しい動作モードにより、クラスターノード間の問題のある相互作用のシナリオでの安定性が向上し、グローバルな問題が発生する前の「小さな」問題への反応によるリソースへの完全なアクセス不能が回避されます(予防措置)。
分離モード(分離プロセス)ホストHV01で、クラスタリングサービスが突然利用できなくなりました。 ノードには、クラスター内相互作用の問題があります。 このシナリオでは、ノードは分離(ResiliencyLevel)状態になり、クラスターから一時的に除外されます。

分離されたノード上の仮想マシンは引き続き実行され、監視されなくなります(つまり、クラスターサービスはVMデータを「気にしません」)。

* SMBでVMを実行する場合:オンラインステータスと正しい実行(SMBはアクセスに「クラスターID」を必要としません)。 VMストレージのブロックタイプの場合、分離ノードのクラスター共有ボリュームにアクセスできないため、ステータスは一時停止クリティカルです。
ResiliencyDefaultPeriod(デフォルトでは240秒)中にノードがクラスタリングサービスをシステムに返さない場合(この場合)、ノードはDown状態に移行します。
隔離モードHV01ノードがクラスター化サービスを正常に動作状態に戻し、分離モードを終了したが、1時間以内に状況が3回以上繰り返されたと想定します(QuarantineThreshold)。 このシナリオでは、WSFCはノードを既定の2時間(QuarantineDuration)隔離モードにし、このノードのVMを既知の「正常な」ものに移動します。


問題の原因が取り除かれたことを確信して、ノードをクラスターに戻すことができます。

検疫では、同時にクラスターノードの25%しか見つけることができないことに注意することが重要です。
カスタマイズするには、上記のオプションとコマンドレットGet-Clusterを使用します。
(Get-Cluster). QuarantineDuration = 1800
ストレージの復元力Windows Serverの以前のバージョンでは、virtのr / w操作が利用できないことを解決しました。 ディスク(ストレージへの接続の喪失)はプリミティブです-VMがオフになり、その後の起動時にコールドブートが必要になります。 Windows Server 2016では、このような問題が発生すると、VMは一時的にクリティカル(AutomaticCriticalErrorAction)ステータスに切り替わり、以前は動作状態が「凍結」されていました(アクセス不能のままになりますが、予期しないシャットダウンはありません)。
タイムアウト中に再接続すると(AutomaticCriticalErrorActionTimeout、デフォルトでは30分)、VMは一時停止-クリティカルを終了し、問題が特定された「ポイント」からアクセス可能になります(アナロジーは一時停止/再生)。
ストレージが動作を再開する前にタイムアウトに達すると、VMはシャットダウンします(アクションをオフにします)

サイト対応/ストレッチクラスターとストレージレプリカ
別の投稿に値するトピックですが、ここで簡単にあなたを知るようにします。
以前は、本格的な分散クラスターを作成する(SAN間レプリケーションを提供する)ためのサードパーティソリューション(多くの$)からアドバイスを受けていました。 Windows Server 2016の出現により、予算を数倍削減し、そのようなシステムを構築する際の統合が増加しています。
Storage Replicaは、ストレージシステム(Storage Spaces Directを含む)間の同期(!)および非同期レプリケーションを可能にし、ワークロードをサポートします-マルチサイトクラスターまたは本格的なDRソリューションの基盤です。 SRはDatacenterエディションでのみ使用でき、次のシナリオで使用できます。
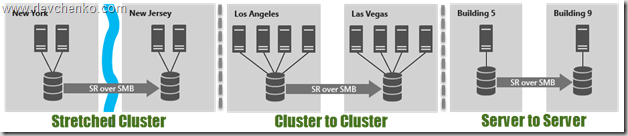
分散クラスター内でSRを使用することは、自動フェールオーバーの存在と、Windows Server 2016でも提示されたサイト認識のクローズ作業により特に可能です。サイト警告により、クラスターノードのグループを定義し、それらを物理的な場所(サイトフォールトドメイン/サイト)カスタムフェールオーバーポリシーの形成、記憶域スペースダイレクトデータの配置、およびVM配布ロジック。 さらに、サイトレベルだけでなく、より低いレベル(ノード、ラック、シャーシ)にバインドすることもできます。

New-ClusterFaultDomain –Name Voronezh –Type Site –Description “Primary” –Location “Voronezh DC” New-ClusterFaultDomain –Name Voronezh2 –Type Site –Description “Secondary” –Location “Voronezh DC2” New-ClusterFaultDomain -Name Rack1 -Type Rack New-ClusterFaultDomain -Name Rack2 -Type Rack New-ClusterFaultDomain -Name HPc7000 -type Chassis New-ClusterFaultDomain -Name HPc3000 -type Chassis Set-ClusterFaultDomain –Name HV01 –Parent Rack1 Set-ClusterFaultDomain –Name HV02 –Parent Rack2 Set-ClusterFaultDomain Rack1,HPc7000 -parent Voronezh Set-ClusterFaultDomain Rack2,HPc3000 -parent Voronezh2


マルチサイトクラスタ内のこのようなアプローチには、次の利点があります。
- フェールオーバー処理は、最初にフォールトドメイン内のノード間で発生します。 フォールトドメイン内のすべてのノードが使用できない場合は、別のノードにのみ移動します。
- 役割の排出(保守モード中の役割の移行など)は、最初にローカルサイト内のサイトに移動する可能性をチェックしてから、それらを別のサイトに移動します。
- CSV(ノード間のクラスターディスクの再配布)のバランスも、ネイティブフォールトドメイン/サイトのフレームワーク内でうまくいくように努力します。
- VMは、依存するCSVと同じサイトに配置されます。 CSVが別のサイトに移行する場合、VMは同じサイトへの移行を1分で開始します。
さらに、サイト認識ロジックを使用して、新しく作成されたすべてのVM /ロールの「親」サイトを決定できます。
(Get-Cluster).PreferredSite = < >
または、クラスターグループごとに詳細に構成します。
(Get-ClusterGroup -Name ).PreferredSite = < >
その他の革新
- 記憶域スペースダイレクトおよび記憶域QoSのサポート。
- ダウンタイムなしでゲストクラスターの共有vhdxのサイズを変更し、Hyper-Vレプリケーションと解像度をサポートします。 ホストレベルでのコピー。
- 階層化スペース、ストレージスペースの直接的な重複排除のサポートにより、CSVキャッシュのパフォーマンスとスケーリングが向上しました(キャッシュに数十GBのRAMを割り当てても問題ありません)。
- 問題の診断を簡素化するためのクラスターロギング(タイムゾーン情報など)の変更+アクティブメモリダンプ(フルメモリダンプの新しい代替)。
- これで、クラスターは同じサブネット内で複数のインターフェースを使用できます。 クラスターによる識別のために、アダプターに異なるサブネットを構成する必要はありません。 追加は自動的に行われます。
これで、Windows Server 2016の新しいWSFC機能の概要ツアーが完了しました。 この資料が役立つことを願っています。 読んでコメントをありがとう。
素晴らしい一日を!