新しい仕事を得たとき、最初のタスクは私のために設定されました-SQLインスタンスの1つが非常に重いディスクをロードする理由を理解するために。 そして、この恐ろしい問題を解消するために必要な措置を講じてください。 ディスクプールが1つしかないこと、および続編のすべてのインスタンスがディスクの負荷に苦しんだことはまだ言っていません。 それで終わりました。 最も重要なことは、判明したように、Zabbixの人の監視は必要なメトリックを収集せず、それらを追加するには要求を開始して待機する必要があったことです。 待って、ディスクアレイがどのように「燃える」かを確認します。 または...
官僚機構のギアを介して旅行のリクエストを送信し、独自の一時的な監視を行うことが決定されました。
最初に、SQLサーバーのパフォーマンスメトリックの収集に必要なデータベースとオブジェクトを作成します。
簡単にするために、スクリプトでデータベースを作成するためのオプションを指定しませんでした。
create database monitor
パフォーマンスカウンターの値は、sys.dm_os_performance_countersシステムビューから取得されます。 スクリプトは、最も人気のある重要なカウンターを説明していますが、もちろん、リストは拡張できます。 ケースについて明確にしたいと思います。 「何か」/秒で測定されるカウンターは増分です。 つまり SQLサーバーは毎秒、現在のカウンター値を既存のカウンター値に追加します。 現在の平均値を取得するには、ビューの値をサーバーの稼働時間で秒単位で割る必要があります。 リクエストにより稼働時間を確認できます。
select DATEDIFF(SS, (select create_date from sys.databases where name = 'tempdb'), getdate())
つまり 現在の瞬間とtempdbの作成時間との差を見つけます。tempdbは、ご存知のように、サーバーの起動時に作成されます。
Granted Workspace Memory(KB)メトリックをすぐにメガバイトに変換します。
収集プロセスは、手順の形式で発行されます。
CREATE procedure sp_insert_perf_counters AS insert into perf_counters select getdate() as Collect_time, Counter = CASE WHEN counter_name = 'Granted Workspace Memory (KB)' then 'Granted Workspace Memory (MB)' ELSE rtrim(counter_name) END, Value = CASE WHEN counter_name like '%/sec%' then cntr_value/DATEDIFF(SS, (select create_date from sys.databases where name = 'tempdb'), getdate()) WHEN counter_name like 'Granted Workspace Memory (KB)%' then cntr_value/1024 ELSE cntr_value END from sys.dm_os_performance_counters where counter_name = N'Checkpoint Pages/sec' or counter_name = N'Processes Blocked' or (counter_name = N'Lock Waits/sec' and instance_name = '_Total') or counter_name = N'User Connections' or counter_name = N'SQL Re-Compilations/sec' or counter_name = N'SQL Compilations/sec' or counter_name = 'Batch Requests/sec' or (counter_name = 'Page life expectancy' and object_name like '%Buffer Manager%') or counter_name = 'Granted Workspace Memory (KB)' GO
次に、論理テーブルからデータを選択するプロシージャを作成します。
endおよび
startパラメーターは、値を表示する時間間隔を指定します。 パラメータが設定されていない場合は、過去3時間の情報を表示します。
create procedure sp_select_perf_counters @start datetime = NULL, @end datetime = NULL as if @start is NULL set @start = dateadd(HH, -3, getdate()) if @end is NULL set @end = getdate() select collect_time, counter_name, value from monitor..perf_counters where collect_time >= @start and collect_time <= @end go
SQLエージェントジョブでsp_insert_perf_countersをラップします。 起動頻度は1分に1回です。
テキストが乱雑にならないように、ジョブを作成するためのスクリプトをスキップします。 最後に、すべてを1つのスクリプトでレイアウトします。
将来的には、これもRAMの不十分なせいによるものだと思うので、すぐにバッファプールのデータベースの「戦い」を確認できるスクリプトを提供します。 データを置くプレートを作成しましょう。
CREATE TABLE BufferPoolLog( [collection_time] [datetime], [db_name] [nvarchar](128), [Size] [numeric](18, 6), [dirty_pages_size] [numeric](18, 6) )
個別のデータベースごとにバッファプールの使用を出力するプロシージャを作成しましょう。
CREATE procedure sp_insert_buffer_pool_log AS insert into Monitor.dbo.BufferPoolLog SELECT getdate() as collection_time, CASE WHEN database_id = 32767 THEN 'ResourceDB' ELSE DB_NAME(database_id) END as [db_name], (COUNT(*) * 8.0) / 1024 as Size, Sum(CASE WHEN (is_modified = 1) THEN 1 ELSE 0 END) * 8 / 1024 AS dirty_pages_size FROM sys.dm_os_buffer_descriptors GROUP BY database_id
ダーティページ=変更されたページ。 この手順はジョブにラップされています。 3分ごとに1回実行するように設定します。 そして、選択のための手順を作成します。
CREATE procedure sp_select_buffer_pool_log @start datetime = NULL, @end datetime = NULL AS if @start is NULL set @start = dateadd(HH, -3, getdate()) if @end is NULL set @end = getdate() SELECT collection_time AS 'collection_time', db_name, Size AS 'size' FROM BufferPoolLog WHERE (collection_time>= @start And collection_time<= @end) ORDER BY collection_time, db_name
さて、データは収集されており、歴史的基盤は蓄積されており、表示するための便利な方法を思い付くことが残っています。 そして、ここで古き良きExcelが助けになります。
パフォーマンスカウンターの例を示します。バッファープールを使用する場合は、類推によって構成できます。
Excelを開き、[データ]-[他のソースから]-[Microsoft Queryから]に移動します。
新しいデータソースを作成します。ドライバーはSQL ServerまたはSQL Serverネイティブクライアント用のSQL ServerまたはODBCで、「接続」をクリックしてサーバーを登録し、パラメーターでデータベースを選択します。ステップ4では、テーブルを選択します(必要ありません)。
作成したデータソースをクリックし、[キャンセル]をクリックし、[Microsoft Queryでクエリを変更し続けますか?]の質問で[はい]をクリックします。
[テーブルの追加]ダイアログを閉じます。 次に、「ファイル」→「SQLクエリの実行」に進みます。 exec sp_select_perf_countersを作成します。 [OK]をクリックして、[ファイル]-[Microsoft Excelにデータを返す]に移動します。
結果を配置する場所を選択します。 パラメーターの上部に2行残すことをお勧めします。
「データ」-「接続」に進み、接続のプロパティに移動します。 [定義]タブに移動し、exec sp_select_perf_counters?、?..を記述します。
[OK]をクリックすると、Excelからこれらのパラメーターを取得するセルを選択できます。 これらのセルを彼に示し、「デフォルトで使用する」チェックボックスと「セルが変更されたときに自動的に更新する」チェックボックスをオンにします。 個人的には、これらのセルに数式を入力しました。
パラメーター1 = TDATE()-3/24(現在の日時から3時間を引いた時間)
Parameter2 = DATE()(現在の日付と時刻)
次に、テーブルをクリックして、[挿入]-[ピボットテーブル]-[ピボットグラフ]に移動します。
ピボットテーブルを設定します。
凡例フィールド-counter_name、
軸フィールド-collect_time、
値は値です。
出来上がり! パフォーマンスメトリックグラフを取得します。 チャートのタイプを「チャート」に変更することをお勧めします。 まだいくつかのストロークがあります。 データのあるページに移動し、接続プロパティに移動して、必要に応じて「X minごとに更新」値を設定します。 SQLサーバーでのジョブの頻度に等しい頻度を設定することは論理的だと思います。
これで、テーブル内のデータが自動的に更新されます。 スケジュールを強制的に更新する必要があります。 「開発者」タブ-「Visual Basic」に移動します。
左側にソースデータがあるシートをクリックし、次のコードを入力します。
Private Sub Worksheet_Change(ByVal Target As Range) Worksheets("").PivotTables("1").PivotCache.Refresh End Sub
どこで
「ピボットテーブル」-ピボットテーブルを含むシートの名前。 VBエディターの括弧内に示される名前。
PivotTable1は、ピボットテーブルの名前です。 ピボットテーブルをクリックして、[パラメータ]セクションに移動すると確認できます。
これで、元のテーブルが更新されるたびにスケジュールが更新されます。 そのようなグラフの例:
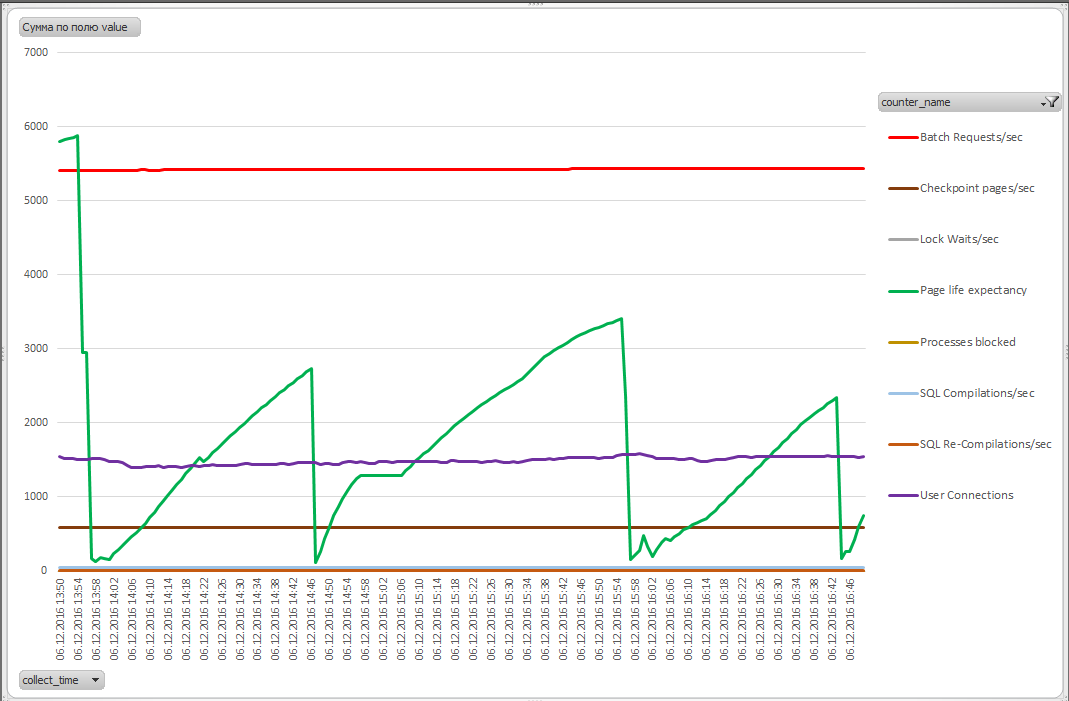
ファイルを複製するには、Excelの接続のプロパティで、新しいサーバー名を入力して接続文字列を変更するだけで十分です。
バッファプールのベースの「ファイト」と推奨されるRAMの量の計算については、次のスクリプトを使用してこのファイトを最小限に抑えることができます。 各データベースの最大メモリ使用量と、サーバーに割り当てられたRAMの合計サイズに対するバッファープールのサイズの平均割合を計算し、これらのデータに基づいて、サーバーに必要な「理想的な」RAMサイズを計算します。
DECLARE @ram INT, @avg_perc DECIMAL, @recommended_ram decimal
これらの計算は、サーバーで実行されているクエリが最適化されており、便利な(そうではない)場合に全テーブルスキャンを実行しないことが確実な場合にのみ意味があることに注意してください。 また、Maximum Granted Workspaceメトリックを監視して、並べ替えおよびハッシュ操作のためにバッファープールの一部を消費するサーバー上の要求がないことを確認する必要があります。
バッファキャッシュのベースの戦争の例(名前がずれる):
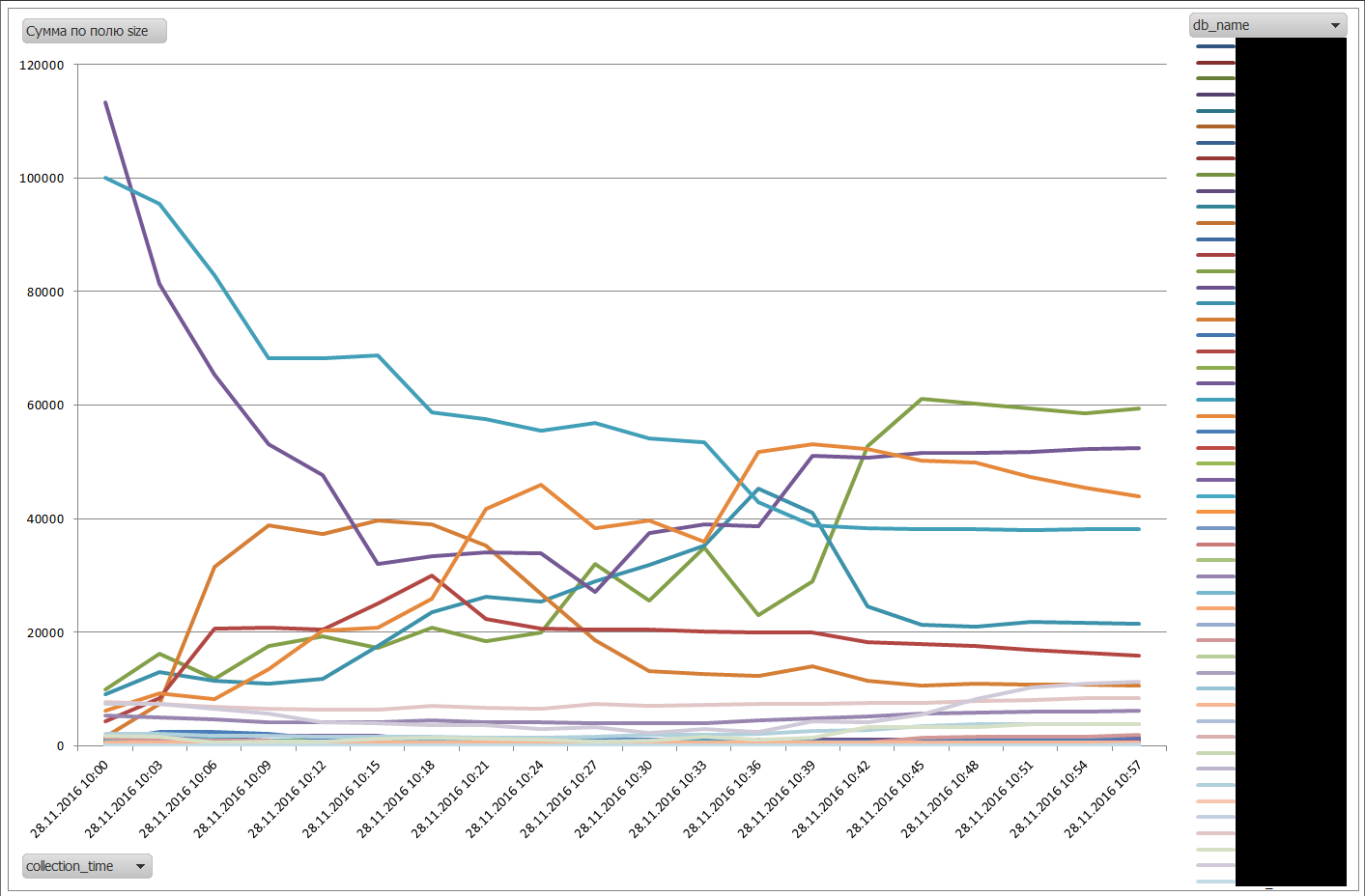
ちなみに、この方法は私たちのzabbiksaよりもはるかに速く動作することが判明したため、私はそれを武器庫に任せました。
約束どおり、T-sql全体が1つのスクリプトで:
中古品:
» SQL Serverメモリバッファープール:基本を理解する
» パラメータを使用してExcelでストアドプロシージャを実行する方法