
ノンブロッキングハッシュテーブルは、両面メダルです。 場合によっては、他の方法では得られないパフォーマンスを実現できます。 一方、それらは非常に複雑です。
私が聞いた最初の非ブロッキングテーブルは、クリフクリック博士によってJavaで書かれました。 その
コードは 2007年
にリリースされ、同じ年に著者
が Googleで
プレゼンテーションを行いました。 このプレゼンテーションを初めて見たとき、私はそれのほとんどを理解していなかったことを告白します。 私が気づいた主なことは、クリフ・クリック博士が何らかの魔術師でなければならないということです。

幸いなことに、この問題でCliffに(ほぼ)追いつくには6年で十分でした。 結局のところ、最も単純なものを理解して実装するために魔術師である必要はありませんが、同時に完全に機能する非ブロッキングハッシュテーブルです。 ここで、そのうちの1つのソースコードを共有します。 C ++でのマルチスレッド開発の経験があり、このブログの以前の投稿を注意深く研究する準備ができている人なら誰でも問題なく理解できると確信しています。
ハッシュテーブルは、
先月リリースしたC / C ++でブロックせずに開発するためのポータブルライブラリである
Mintomicを使用して記述されています。 いくつかのx86 / 64、PowerPC、およびARMプラットフォームで、すぐにビルドおよび起動できます。 また、すべてのMintomic関数にはC ++ 11で同等の機能があるため、このテーブルをC ++ 11に変換するのは簡単な作業です。
制限事項
私たちプログラマーは、データ構造をできるだけ普遍的に書くという本能を持っているので、それらを再利用するのが便利です。 これは悪いことではありませんが、最初から目標に変えてしまうと、ひどく役立つことがあります。 この投稿では、他の極端な方法を使用して、できる限り限定的で狭く専門化されたノンブロッキングハッシュテーブルを作成しました。 その制限は次のとおりです。
- 32ビット整数キーと32ビット整数値のみを格納します。
- すべてのキーはゼロ以外でなければなりません。
- すべての値はゼロ以外でなければなりません。
- テーブルには、保存できるレコードの最大数が固定されており、この数は2のべき乗でなければなりません。
- SetItemとGetItemの2つの操作のみがあります。
- 削除操作はありません。
このハッシュテーブルの限定バージョンを習得するときは、アプローチを根本的に変更することなく、すべての制限を一貫して削除できるようにしてください。
アプローチ
ハッシュテーブルを実装するには多くの方法があります。 私が選んだアプローチは、前回の投稿
「ロックフリー...線形検索?」で説明した
ArrayOfItemsクラスの単純な修正
です。 続行する前に、それに慣れることを強くお勧めします。
ArrayOfItemsと同様に、このハッシュテーブルクラス(私は
HashTable1と呼び
HashTable1 )は、キーと値のペアの単純な巨大な配列を使用して実装されます。
struct Entry { mint_atomic32_t key; mint_atomic32_t value; }; Entry *m_entries;
HashTable1 、テーブル外のハッシュ衝突を解決するためのリンクリスト
HashTable1ません。 配列のみがあります。 配列内のヌルキーは空のエントリを示し、配列自体はゼロで初期化されます。 そして、
ArrayOfItemsと同様に、線形検索を使用して
ArrayOfItemsに値が追加および配置されます。
ArrayOfItemsと
HashTable1の唯一の違いは、
ArrayOfItems常にゼロインデックスで線形検索を開始するのに対し、
HashTable1は
キーハッシュとして計算されたインデックスですべての線形検索を開始することです。 ハッシュ関数として
MurmurHash3の整数ファイナライザーを選択
しました。これは十分に高速で、整数データを適切にエンコードするためです。
inline static uint32_t integerHash(uint32_t h) { h ^= h >> 16; h *= 0x85ebca6b; h ^= h >> 13; h *= 0xc2b2ae35; h ^= h >> 16; return h; }
その結果、同じキーで
SetItemまたは
GetItemを呼び出すたびに、同じインデックスから線形検索が開始されますが、異なるキーを渡すと、ほとんどの場合、検索は完全に異なるインデックスで開始されます。 したがって、値は
ArrayOfItemsよりも配列全体にはるかによく分散され、複数の並列スレッドから
SetItemと
GetItemを呼び出すことが安全になります。
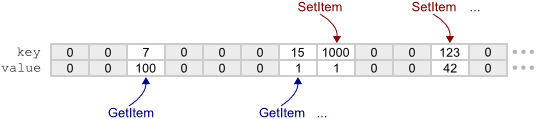
HashTable1は循環検索を使用します。つまり、
SetItemまたは
GetItemが配列の最後に達すると、ゼロインデックスに戻り、検索を続行します。 配列がいっぱいになることはないため、各検索は、検索キーの検出またはキー0のレコードの検出のいずれかで終了することが保証されています。つまり、検索キーはハッシュテーブルに存在しません。 この手法は、
線形探査による オープンアドレッシングと呼ばれ、私の意見では、これは既存のハッシュテーブルの中で最もロックフリーに適したハッシュテーブルです。 実際、クリック博士は彼のJavaノンブロッキングハッシュテーブルで同じトリックを使用しています。
コード
SetItemを実装する関数を次に示します。 配列を通過し、キーが0または目的のキーと一致する最初のレコードに値を格納します。 そのコードは
、前の投稿で説明した ArrayOfItems::SetItemコードとほぼ同じです。 違いは、整数ハッシュと
idxに適用されるビット単位の「and」のみであり、配列の境界を超えることはできません。
void HashTable1::SetItem(uint32_t key, uint32_t value) { for (uint32_t idx = integerHash(key);; idx++) { idx &= m_arraySize - 1; uint32_t prevKey = mint_compare_exchange_strong_32_relaxed(&m_entries[idx].key, 0, key); if ((prevKey == 0) || (prevKey == key)) { mint_store_32_relaxed(&m_entries[idx].value, value); return; } } }
GetItemコードは、マイナーな変更を除いて
ArrayOfItems::GetItemほぼ一致します。
uint32_t HashTable1::GetItem(uint32_t key) { for (uint32_t idx = integerHash(key);; idx++) { idx &= m_arraySize - 1; uint32_t probedKey = mint_load_32_relaxed(&m_entries[idx].key); if (probedKey == key) return mint_load_32_relaxed(&m_entries[idx].value); if (probedKey == 0) return 0; } }
上記の関数は両方とも、
ArrayOfItems対応するものと同じ理由でロックせずにスレッドセーフ
ArrayOfItems :配列要素を使用するすべての操作は、アトミックライブラリ関数を使用して実行され、値はキーの比較とスワップ(CAS)を使用してキーにマップされます。すべてのコードはメモリの並べ替えに耐性があります。 繰り返しますが、より完全な理解のために、
前の投稿を参照することをお勧めします。
最後に、前回の記事と同様に、
SetItemを最適化し、最初にCASが本当に必要かどうかを確認し、必要でない場合は使用しません。 この最適化のおかげで、以下にあるサンプルアプリケーションはほぼ20%高速に動作します。
void HashTable1::SetItem(uint32_t key, uint32_t value) { for (uint32_t idx = integerHash(key);; idx++) { idx &= m_arraySize - 1;
すべて準備完了です! これで、世界で最も簡単なノンブロッキングハッシュテーブルができました。 ここに、
ソースコードと
ヘッダーファイルへのリンクがあり
ます 。
短い警告:
ArrayOfItemsと同様に、
ArrayOfItemsを使用したすべての操作
HashTable1 、弱い(緩和された)メモリ順序の制限で実行されます。 したがって、
HashTable1にフラグを書き込むことで他のストリームでデータを使用できるようにする場合、このレコードに「
リリースセマンティクス 」が必要です。これは、直前にリリースフェンス(「リリースバリア」)を配置することで保証できます命令。 同様に、データを受信するストリーム内の
GetItemにアクセスするには、取得フェンス(「取得バリア」)を提供する必要があります。
応用例
HashTable1で
HashTable1を評価するために、前の投稿の例と非常によく似た別の単純なアプリケーションを作成しました。 2つの実験から選択するたびに:
- 2つのストリームはそれぞれ、一意のキーで6,000個の値を追加し、
- 各スレッドは、同じキーで12,000の異なる値を追加します。
コードはGitHubにあるため、自分でコンパイルして実行できます。 アセンブリ手順は
README.mdにあります。

ハッシュテーブルがオーバーフローすることはないため(たとえば、配列の80%未満しか使用され
HashTable1は顕著なパフォーマンスを示します。 おそらく、測定でこれを確認する必要がありますが、
シングルスレッド ハッシュテーブルのパフォーマンスを測定した以前の経験に基づいて、
HashTable1よりも高速でノンブロッキングのハッシュテーブルを作成することはできないでしょう。 驚くかもしれませんが、その基礎となる
ArrayOfItemsはひどいパフォーマンスを示しています。 もちろん、ハッシュテーブルと同様に、配列の1つのインデックス内の多数のキーをハッシュするリスクはゼロではなく、パフォーマンスは
ArrayOfItemsの速度に等しくなります。 しかし、十分に大きなテーブルとMurmurHash3などの優れたハッシュ関数を使用すると、このようなシナリオの可能性は無視できます。
実際のプロジェクトでは、このような非ロックテーブルを使用しました。 あるケースでは、私が取り組んでいたゲームで、共有ロックをめぐるスレッドの激しい競争が、メモリ監視がオンになるたびにボトルネックを作成しました。 ノンブロッキングハッシュテーブルに切り替えた後、最悪のシナリオのフレームレートは4 FPSから10 FPSに改善されました。