なぜそれが必要ですか
Zipfの法則は、任意の自然言語でテキスト内の単語の頻度分布の法則を説明しています[1]。 言語学に加えて、これらの法律は経済学にも適用されます[2]。 Zipfの法則に従うオブジェクトの統計データを近似するには、次の形式の双曲線関数が使用されます。
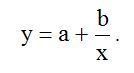
(1)
ここで、abは定数係数です。xは関数引数の統計データ(リスト形式)です。yは、最小二乗法で得られた実データに対する関数の値の近似値です[3]。
通常、双曲線関数を対数法で近似するには、線形化され、係数a、bが決定され、逆変換が行われます[4]。 直接変換および逆変換により、追加の近似誤差が生じます。 したがって、最小二乗法の古典的な実装のための単純なPythonプログラムを提供しています。
アルゴリズム
ソースデータは2つのリストで設定されます。
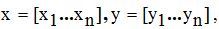
ここで、
nはリスト内のデータの量です。
係数を決定する関数を取得します

次の連立方程式から係数a、bを見つけます。

(3)
このようなシステムの解決策は特に難しくありません:

(4)

(5)。
平均近似誤差

式によって:
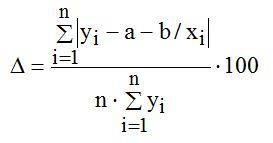
(6)
Pythonコード
結果
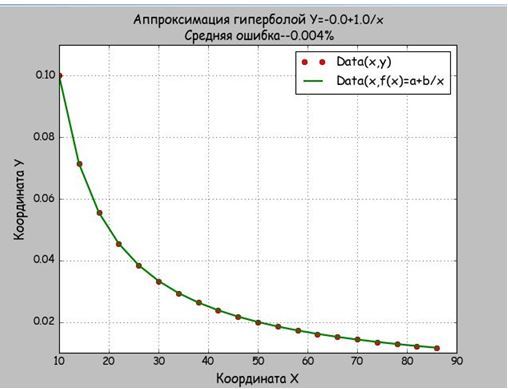
等辺双曲線の関数からデータを取得したため、a = 0、b = 10、絶対誤差0.004%を取得しました。 したがって、関数mnkGP(x、y)は正しく機能し、アプリケーションプログラムに挿入できます。
べき関数の近似
Pythonにはこのためのscipyモジュールがありますが、多項式の負の次数dはサポートしていません。 多項式によるデータ近似を実装するコードを考えます。
結果

グラフからわかるように、放物線が双曲線に沿って変化するデータを近似すると、平均誤差が増加し、二次方程式の自由項が消滅します。
取得した関数は、Zipfの法則(Zipf)の分析に使用されますが、これは次の記事で行われます。
参照:
1. Zipfの法則(Zipf)
tpl-it.wikispaces.com/Laws+ Zipf
+%28Zipf%292. Zipfの法則はこれです。
dic.academic.ru/dic.nsf/ruwiki/241053. Zipfの法律。
wiki.webimho.ru/zipfaの法律4.講義5.最小二乗法による関数の近似。
mvm-math.narod.ru/Lec_PM5.pdf5.平均近似誤差。
math.semestr.ru/corel/zadacha.php