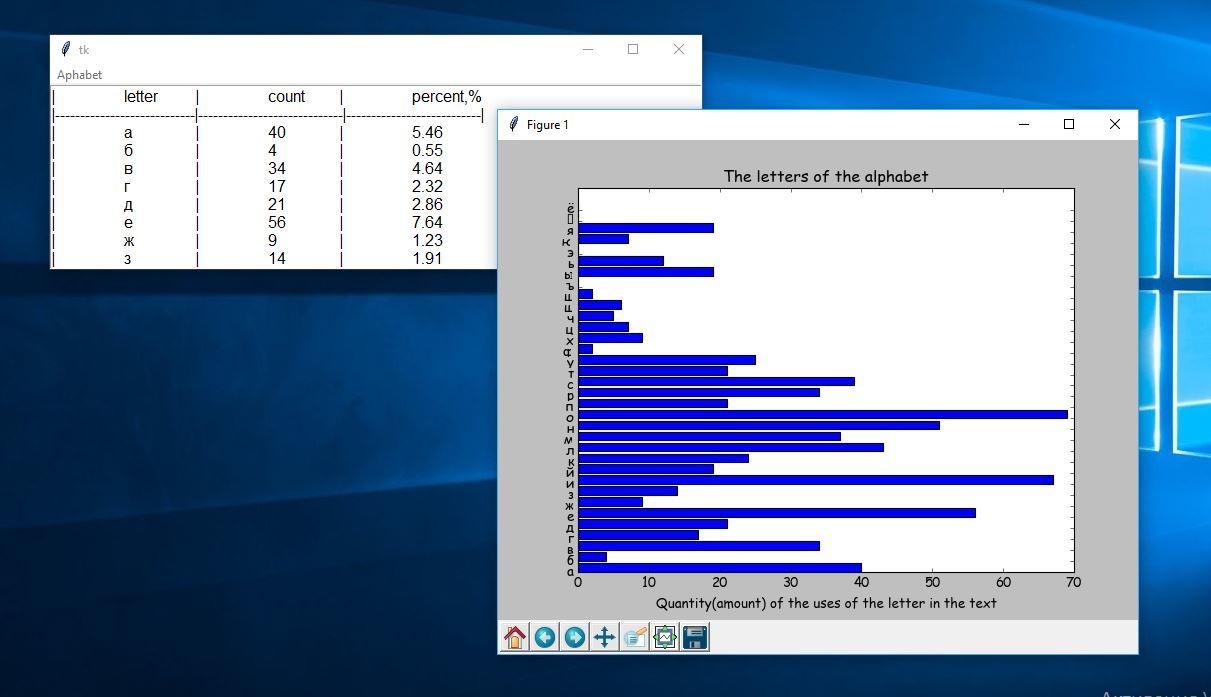
英語とロシア語のテキストの特定の文字の使用頻度を計算するタスクは、言語統計分析の段階の1つです。 この問題を解決するため
のネットワークの言語プログラムとリソースのカタログには Pythonプログラムはありません。
Pythonフォーラムでは、このようなプログラムには別の部分がありますが、1つの言語、主に英語に焦点を当てています。 この状況を考慮して、ロシア語と英語の両方のテキスト用の統計処理プログラムを開発しました。
インポート変数と初期変数
import matplotlib.pyplot as plt; plt.rcdefaults() import numpy as np import matplotlib.pyplot as plt from tkinter import * from tkinter.filedialog import * from tkinter.messagebox import * import fileinput import matplotlib as mpl mpl.rcParams['font.family'] = 'fantasy' mpl.rcParams['font.fantasy'] = 'Comic Sans MS, Arial'
英語のテキストを含むファイルを開く
def w_open_ing(): aa=ord('a') bb=ord('z') op = askopenfilename() main(op,aa,bb)
ロシア語のテキストを含むファイルを開く
def w_open_rus(): aa=ord('') bb=ord('') op = askopenfilename() main(op,aa,bb)
両言語のユニバーサルデータ処理
def main(op,aa,bb): alpha = [chr(w) for w in range(aa,bb+1)]
現場清掃
def clear_text(): txt.delete(1.0, END)
フィールドからファイルへのデータの書き込み
def save_file(): save_as = asksaveasfilename() try: x =txt.get(1.0, END) f = open(save_as, "w") f.writelines(x.encode('utf8')) f.close() except: pass
プログラム終了
def close_win(): if askyesno("Exit", "Do you want to quit?"): tk.destroy()
Tkinter標準インターフェイス
tk= Tk() main_menu = Menu(tk) tk.config(menu=main_menu) file_menu = Menu(main_menu) main_menu.add_cascade(label="Aphabet", menu=file_menu) file_menu.add_command(label="English text", command= w_open_ing) file_menu.add_command(label="Russian text", command= w_open_rus) file_menu.add_command(label="Save file", command=save_file) file_menu.add_command(label="Cleaning", command=clear_text) file_menu.add_command(label="Exit", command=close_win) txt = Text(tk, width=72,height=10,font="Arial 12",wrap=WORD) txt.pack() tk.mainloop()
メリット
- このプログラムはPythonで作成されているため、BigARTMおよびGensimでの使用が簡単になります。
- ロシア語の文字「e」と「e」の違いを考慮します。
- それはグラフィカルなインターフェースを持ち、同時に「自由に配布」します。