機械学習の分野での実験に関するレポートを投稿します。 今回の実験の主題は、モデルカーを制御するAIの作成でした。
スマートサイトで書かれているように、コントロールオブジェクトに特定の評価関数を最大化する主な方法は2つあります。
1)プログラム強化トレーニング(パブロフの犬にこんにちは)
2)戦略分野で直接検索を行う
2番目のオプションを選択することにしました。
AIドライバー
モデルの問題として、1つのAIチャンピオンシップからサブタスクを選択しました(最初に解決したとき、機械学習の方法がわかりませんでした)。
オブジェクトがあります。 左右に曲がり、前後に加速することができます(前方-高速、後方-低速)。 このオブジェクトをポイントAからポイントBに到達させる最速の方法は何ですか?

MATLABシミュレーションコードfunction q = evaluateNN(input,nn) unit.angle=0; unit.x=0; unit.y=0; trg.x=input(1); trg.y=input(2); q=0; rmin=1e100; for i=1:20 % "" 20 % tangle=180*atan2(-unit.y+trg.y,-unit.x+trg.x)/3.141-unit.angle; if(tangle>180) tangle=tangle-360; end; if(tangle<-180) tangle=tangle+360; end; r=sqrt((unit.y-trg.y)^2+(unit.x-trg.x)^2); % answArr=fastSim(nn,[tangle;r]); answArr(1)=(10+(-2))/2+ answArr(1)*(10-(-2))/2; answArr(2)=(30+(-30))/2+ answArr(2)*(30-(-30))/2; % vx=answArr(1)*cos(3.141*unit.angle/180); vy=answArr(1)*sin(3.141*unit.angle/180); unit.x=unit.x+vx; unit.y=unit.y+vy; unit.angle=unit.angle+answArr(2); %, . if(r<rmin) rmin=r; end; end; q=-rmin; if(q>0) q=0; end; end
実際、運動の微分方程式を書き留めて解決することで問題を解決することができます...しかし、私は拡散に強くありません。 したがって、私は定期的にそのような問題に遭遇しました:
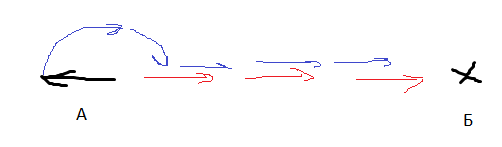
ユニットはターゲットに戻ります。 彼が向きを変えて運転したり、逆に運転したりする方が良いですか?

ユニットは70度でターゲットに向けられます。 加速と旋回を同時に行うか、最初に旋回してから加速する方が良いですか? ある戦略を別の戦略から分離するしきい値を選択する方法は?
効果的な最適化アルゴリズムと高速ニューラルネットワークができたので、戦略を列挙することで問題を解決しました。 つまり、タスクを関数として提示しました。入力量はニューロンの重みとシフトであり、出力量は特定の戦略の有効性の数値推定値です(この数値推定値は品質関数または品質メトリックと呼ばれます)。
ニューラルネットワーク入力:
1)ターゲットへの方向(-180〜180度)
2)ターゲットまでの距離
3)制御オブジェクトの機首速度
4)制御オブジェクトの横速度
ヘディングと横方向の速度は次のとおりです。
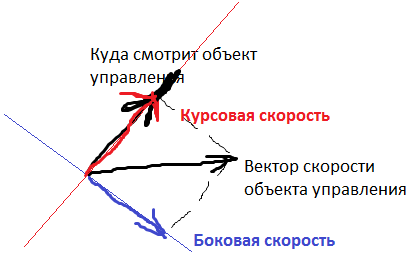
出力値は、舵位置(サイクルごとに-30〜+30度)およびエンジンからの加速度(-2〜+10セル/回転あたりのストローク)です。
1回のテストでの品質の関数として、q =(-ターゲットまでの最小距離)を選択しました。 Qは常に負ですが、Qが大きいほど、アルゴリズムの品質が高く評価されます。 私はいくつかのテストを実施しているため、それらからいくつかの統一された品質メトリックを導き出す必要があります。
すべてのテストで品質の最悪の値をメトリックとして採用しました。つまり、ボットは平均を改善しようとはしませんが、結果の最悪を改善します。 AIが、一部のテストの結果を他のテストの結果を犠牲にして最適化しようとしないようにしました。
私のニューラルネットワークはそれぞれ7ニューロンの2層で構成され、各ニューロンの活性化関数は逆正接です。
数分のトレーニングと...

AIはこのようなターゲットを目指し始めました。 赤い矢印は車の向きです。 つまり、ボットは反転し、同時に向きを変えてから、反転から順方向に切り替えました。 同時に、彼は「最初に少なくとも部分的に展開してから運転する」戦略や「後方に運転する」戦略よりも早く目標を達成しました。
AIコレクター
問題のステートメントをわずかに変更します。 同じ平面、加速/回転するすべての同じ機会(今回は、-3から7までの加速、および1回転あたり-30から30度までの回転)。 各チャレンジは100動きに制限されています。
しかし、今ではいくつかの目標があります。 各ターゲットは静止しています。 AIはそれらを次のように認識します。

ニューラルネットワークの視野角は200度で、9つの等しいセクター(それぞれ22度)に分割されます。 ターゲットがセクターの1つに該当する場合、ターゲットまでの距離に等しい数がニューラルネットワークの対応するセンサーに該当します。 セクターにターゲットがない場合、数値1000がセンサーにヒットします(シミュレーションのほとんどすべての距離はこの数値より小さくなります)。
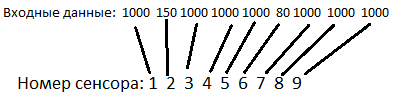
制御対象が10以下の距離でターゲットに近づくと、ターゲットは破壊され、AIは10ポイントを獲得します(ターゲットを食べるなど)。
コントロールオブジェクトの初期座標はゼロ(0,0)です。 最初のテストの目的の座標は
[50,100] [10,30] [100、-120] [60,75]
これらは典型的な座標です。 合計6回の試行があり、座標はこの順序に関するものです。 常に4つの目標があります。
AIをトレーニングに使用します。 AIは数時間学習に失敗します。 平均して、テストごとに1つのターゲットをキャプチャします(少しでも少ない)。 問題は、報酬に対する係数の依存性の関数が区分的に一定であるということだと思います。
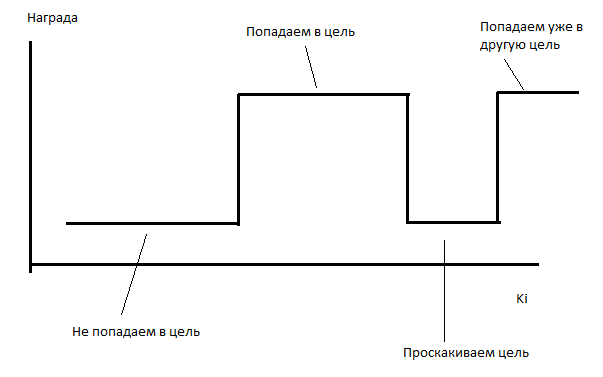
そのような場合、私のオプティマイザーは非常にうまく機能しません(そのような場合、進化はあまり役に立ちません)。
したがって、私は少し不正行為をしています。 各AIの動きが、選択されていない各ターゲットまでの距離に反比例するポイント数を取得するようにします。 彼は各ゴールで0.1 / rポイントを獲得します。 つまり、距離10で彼はゴールに対して0.001ポイントを受け取り、このゴールを「食べる」と10ポイントを獲得します。 AIによって取得されるポイントの数はほとんど変化しませんが、関数は区分的に変数になります。つまり、ゼロ以外の導関数を持ちます。
キーポイントを見つけるドライバーを使用したソースコードシミュレーション function q = evaluateNN(input,nn) unit.angle=0; unit.x=0; unit.y=0; unit.vx=0; unit.vy=0; trg=[]; trg(1).x=input(1); trg(1).y=input(2); trg(1).pickable=1; trg(2).x=input(3); trg(2).y=input(4); trg(2).pickable=1; trg(3).x=input(5); trg(3).y=input(6); trg(3).pickable=1; trg(4).x=input(7); trg(4).y=input(8); trg(4).pickable=1; tsz=size(trg); tangle=[]; r=[]; sensor=[]; sensorMax=5; sensorBound=70; sectorSize=2*sensorBound/sensorMax; q=-100; rmin=1e100; for i=1:200 % for j=1:sensorMax sensor(j)=1e4; end; for j=1:tsz(2) tangle(j)=180*atan2(-unit.y+trg(j).y,-unit.x+trg(j).x)/3.141-unit.angle; if(tangle>180) tangle=tangle-360; end; if(tangle<-180) tangle=tangle+360; end; r(j)=sqrt((unit.y-trg(j).y)^2+(unit.x-trg(j).x)^2); if(tangle(j)>-sensorBound && tangle(j)<sensorBound && trg(j).pickable==1) %target in field of view index=floor((tangle(j)+sensorBound)/sectorSize)+1; if(sensor(index)>r(j)) sensor(index)=r(j); end; end; % if(r(j)<10 && trg(j).pickable==1) %picked up q=q+10; trg(j).pickable=0; end; % if(r(j)<50 && trg(j).pickable==1) q=q+1/r(j); end; end; % : vangle=180*atan2(unit.vy,unit.vx)/3.141; vr=unit.vy*sin(3.141*unit.angle/180)+unit.vx*cos(3.141*unit.angle/180);%v-radial. Scalar multing vb=-unit.vx*sin(3.141*unit.angle/180)+unit.vy*cos(3.141*unit.angle/180);%v-back. vx*(-y)+vy*x % answArr=fastSim(nn,[sensor'';vr;vb]); answArr(1)=(4+(-1))/2+ answArr(1)*(4-(-1))/2; answArr(2)=(30+(-30))/2+ answArr(2)*(30-(-30))/2; % ax=answArr(1)*cos(3.141*unit.angle/180); ay=answArr(1)*sin(3.141*unit.angle/180); unit.vx=unit.vx+ax; unit.vy=unit.vy+ay; unit.x=unit.x+unit.vx; unit.y=unit.y+unit.vy; unit.angle=unit.angle+answArr(2); end; if(q>0) q=0; end; end
同時に、いくつかのテストの結果を次のように組み合わせました。平均の結果と最悪の結果を取り、それらから平均を取りました。
nnlocal=ktonn(nn,k); arr=[1,2,3,4,1,2,3,4]; input=[[50,100,10,30,100,-120,60,75];[-50,50,-100,100,10,0,20,-90];[100,-60,-100,15,20,0,15,4];[-100,-10,-25,15,60,-5,-80,10];[-10,-70,0,-40,0,40,20,22]; [20,-100,-20,22,-30,0,100,-10];]; for (i=1:6) nncopy=nnlocal; val=evaluateNN(input(i,:),nncopy); sum_=sum_+val; arr(i)=val; countOfPoints=countOfPoints+1; end; q=sum_/countOfPoints- sum(abs(k))*0.00001;
作業はより活発に行われました。 数十分-そして出来上がり:
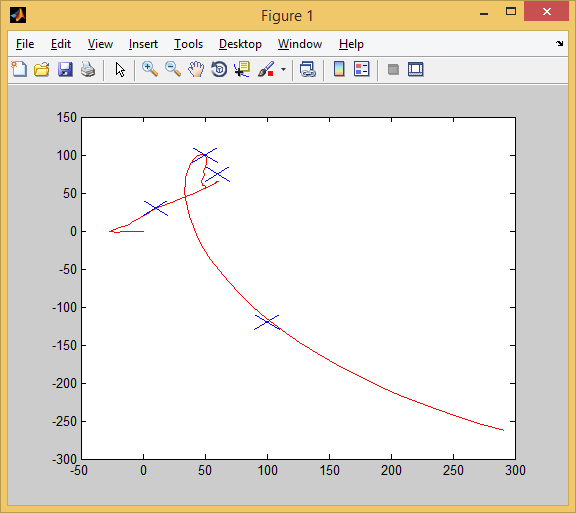
したがって、最初のテストに合格します。 すべてのターゲット(青いX)が正常にキャプチャされます。
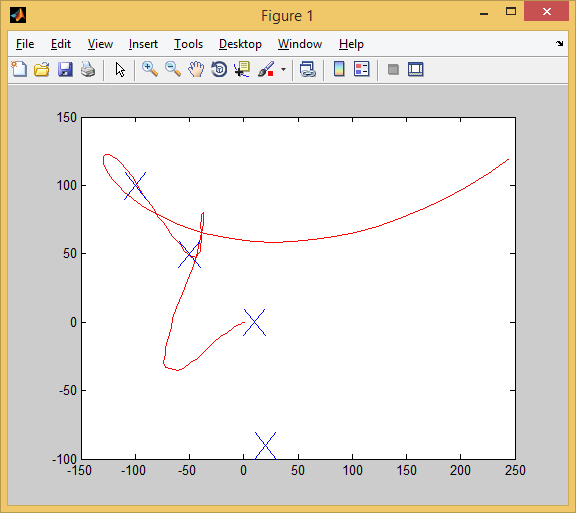
したがって、2番目のテストに合格します。 3つのターゲットがキャプチャされました(最初のターゲットをキャプチャするには、少し前進してから向きを変えなければなりませんでした。クローズアップは次のようになります。
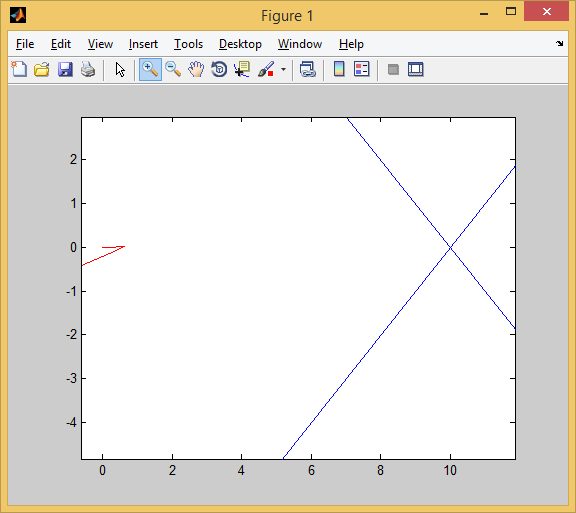
3番目のテストでは、4/4
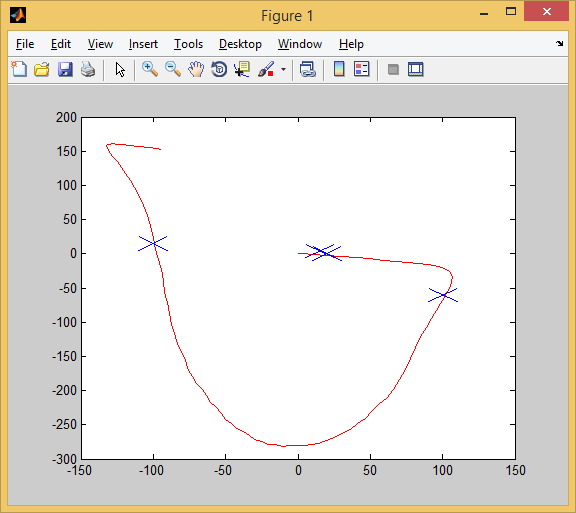
そして4日目:
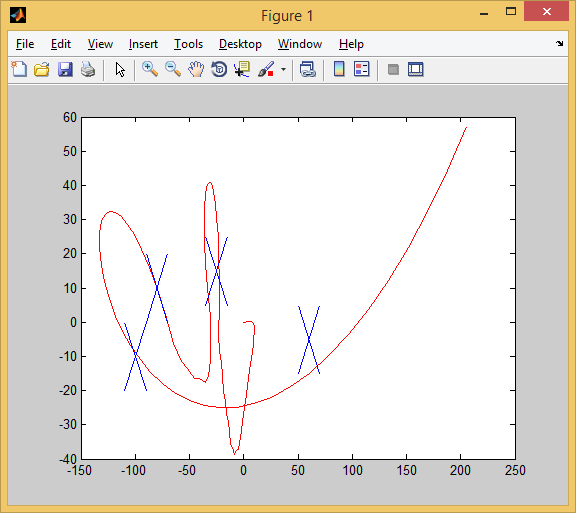
そして5日目:
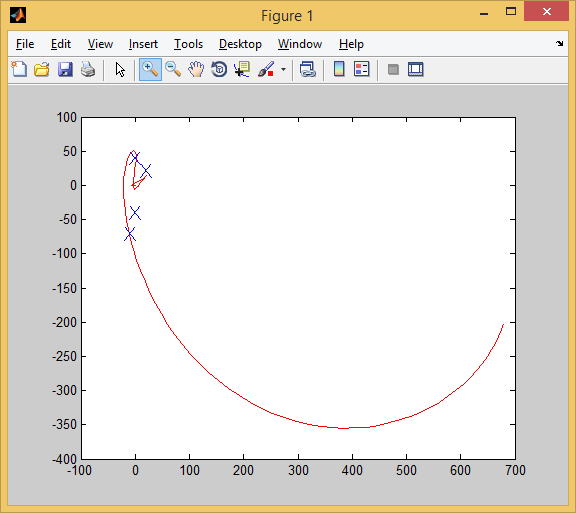
しかし、6日にはすでに4つのうち3つがあります。

ここで、新しいテストを設定します-トレーニングサンプルに含まれていないもの(クロス検証を実行します)。

4のうち3! 私は最近まで、AIがトレーニングサンプルの経験をテストサンプルに転送できることを疑っていました。
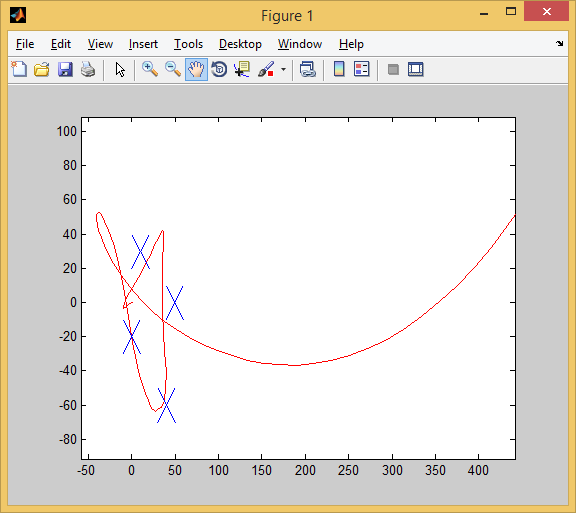
彼は3つの目標を達成し、少しずつ逃しました。
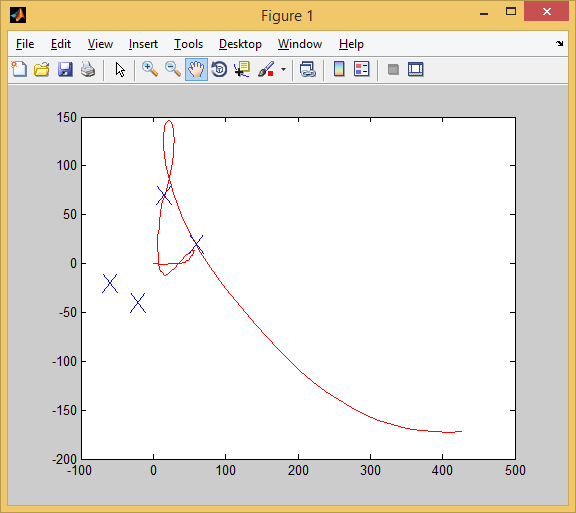
さて、ここでAIは完全に台無しになりました。 4つの目標のうち2つを達成しました。
おわりに
実験報告書は結論で終わるべきです。 結論は次のとおりです。
1)戦略空間を列挙することによる学習は、有望な手法です。 しかし、オプティマイザーに厳しいです-パラメーターを選択するためにかなり混乱したアルゴリズムを使用しました。
2)品質の区分的に一定の機能は悪です。 関数に派生物に似たものさえない場合、最適化するのは非常に困難です。
3)7ニューロンの2層-これは単純な自動操縦を行うのに十分です。 通常、14個のニューロンは、有用な機能を収集できないジルチです。
コメント、同志に感謝します!
この記事が気に入ったら、Mortal Kombatのようなゲームで同様のAIをどのように作成したかを説明します。